1. Message queue model
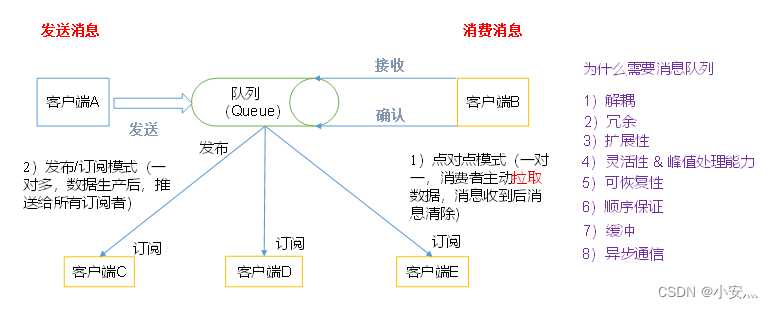
- Point-to-point mode
(one-to-one, consumers actively pull data, and the message is cleared after the message is received). The point-to-point model is usually a messaging model based on pull or polling. This model requests information from the queue instead of sending messages Push to the client. The characteristic of this model is that the message sent to the queue is received and processed by one and only one receiver, even if there are multiple message listeners. - The publish/subscribe model
(one-to-many, after data production, pushes to all subscribers)
publish-subscribe model is a push-based messaging model. The publish-subscribe model can have many different subscribers. Temporary subscribers only receive messages when they are actively listening to the topic, while durable subscribers listen to all messages of the topic, even if the current subscriber is unavailable and offline.
2. Message queue usage scenarios
-
Decoupling:
Allows you to extend or modify the processing on both sides independently, as long as they adhere to the same interface constraints. -
Redundancy:
Message queues persist data until they have been fully processed, avoiding the risk of data loss in this way. In the "insert-get-delete" paradigm adopted by many message queues, before deleting a message from the queue, you need your processing system to clearly indicate that the message has been processed, so as to ensure that your data is safely saved. until you are done using it. -
Scalability:
Because the message queue decouples your processing, it is easy to increase the frequency of message enqueuing and processing, as long as additional processing is added. -
Flexibility & peak processing capacity:
In the case of a sharp increase in traffic, the application still needs to continue to function, but such burst traffic is not common. It is undoubtedly a huge waste to invest resources on standby at all times to handle such peak access. The use of message queues can enable key components to withstand sudden access pressure without completely crashing due to sudden overload requests. -
Recoverability:
Failure of a part of the system does not affect the entire system. The message queue reduces the coupling between processes, so even if a process that processes messages hangs up, the messages added to the queue can still be processed after the system recovers. -
Order guarantee:
In most usage scenarios, the order of data processing is important. Most message queues are inherently sorted and can guarantee that data will be processed in a specific order. (Kafka guarantees the order of messages in a Partition) -
Buffering:
helps to control and optimize the speed of data flow through the system, and solve the inconsistency in the processing speed of production messages and consumption messages. -
Asynchronous communication:
Many times, users do not want or need to process messages immediately. Message queues provide an asynchronous processing mechanism that allows users to put a message into a queue without processing it immediately. Put as many messages on the queue as you want, and process them when needed.
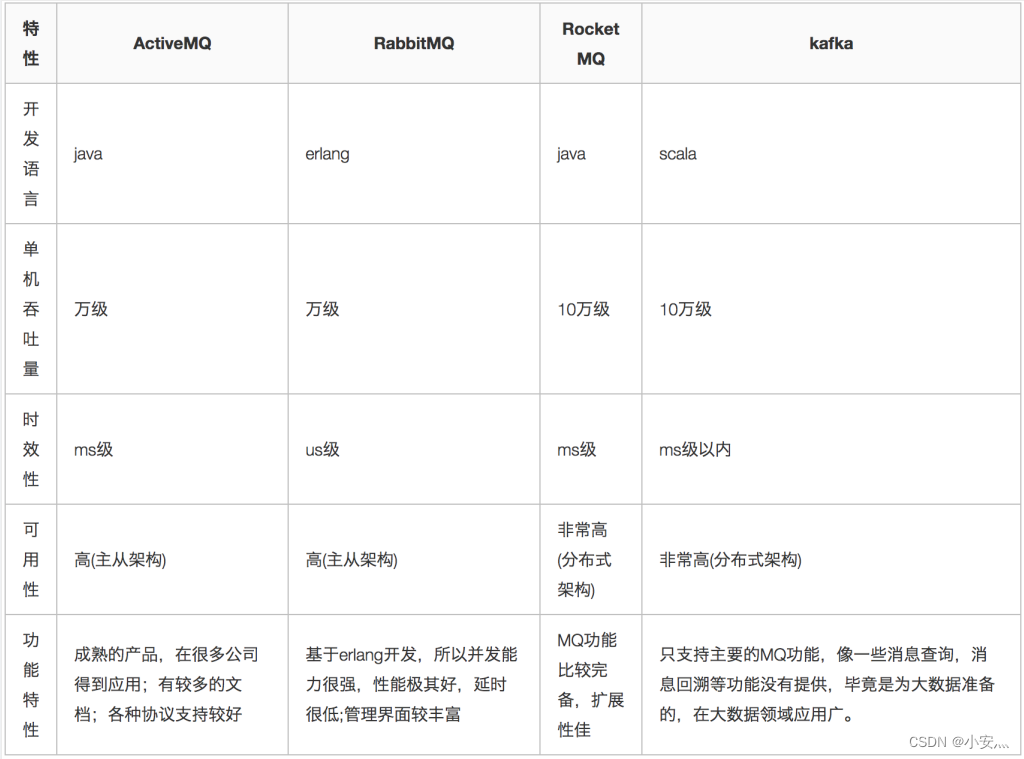
3. Message queue comparison
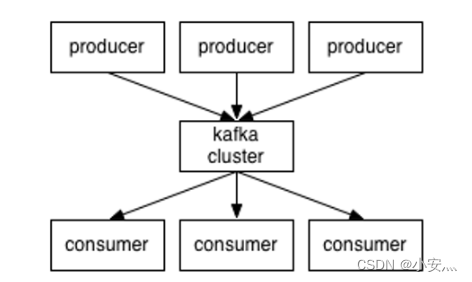
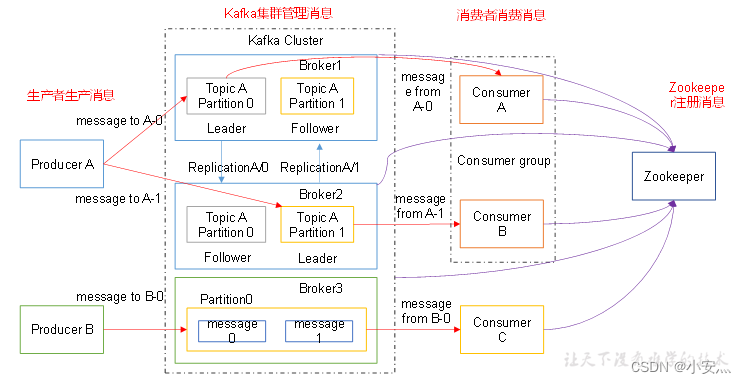
4. Message queue architecture
4.1、Kafka
-
Producer : The message producer is the client that sends messages to the kafka broker;
-
Consumer : message consumer, the client that fetches messages from kafka broker;
-
Topic : It can be understood as a queue;
-
Consumer Group (CG) : This is the method used by Kafka to broadcast (send to all consumers) and unicast (send to any consumer) a topic message. A topic can have multiple CGs. The topic's message will be copied (not really copied, but conceptually) to all CGs, but each partion will only send the message to one consumer in the CG. If you need to implement broadcasting, as long as each consumer has an independent CG. To achieve unicast as long as all consumers are in the same CG. With CG, consumers can also be freely grouped without sending messages to different topics multiple times;
-
Broker : A kafka server is a broker. A cluster consists of multiple brokers. A broker can accommodate multiple topics;
-
Partition : In order to achieve scalability, a very large topic can be distributed to multiple brokers (ie servers), a topic can be divided into multiple partitions, and each partition is an ordered queue. Each message in the partition will be assigned an ordered id (offset). Kafka only guarantees to send messages to consumers in the order of a partition, and does not guarantee the order of a topic as a whole (among multiple partitions);
-
Offset : Kafka's storage files are named according to offset.kafka. The advantage of using offset as a name is that it is easy to find. For example, if you want to find the location at 2049, you only need to find the file 2048.kafka. Of course the first offset is 00000000000.kafka.
4.、RocketMQ
-
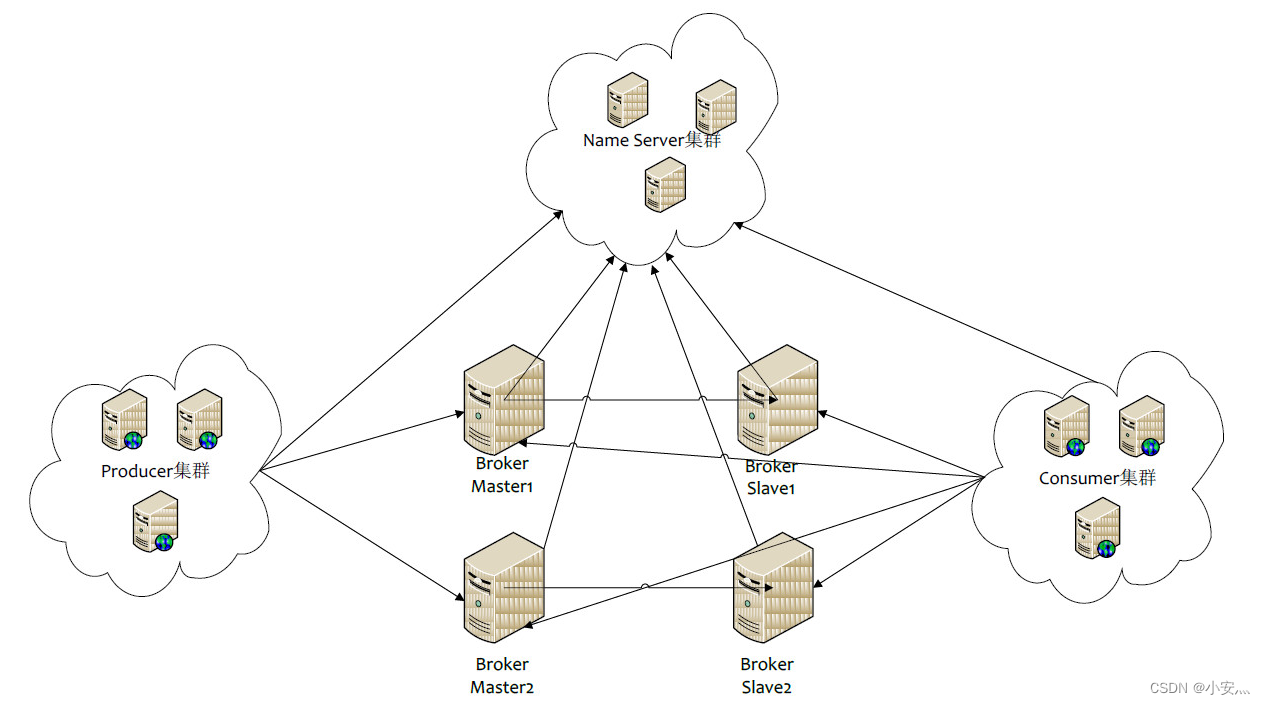
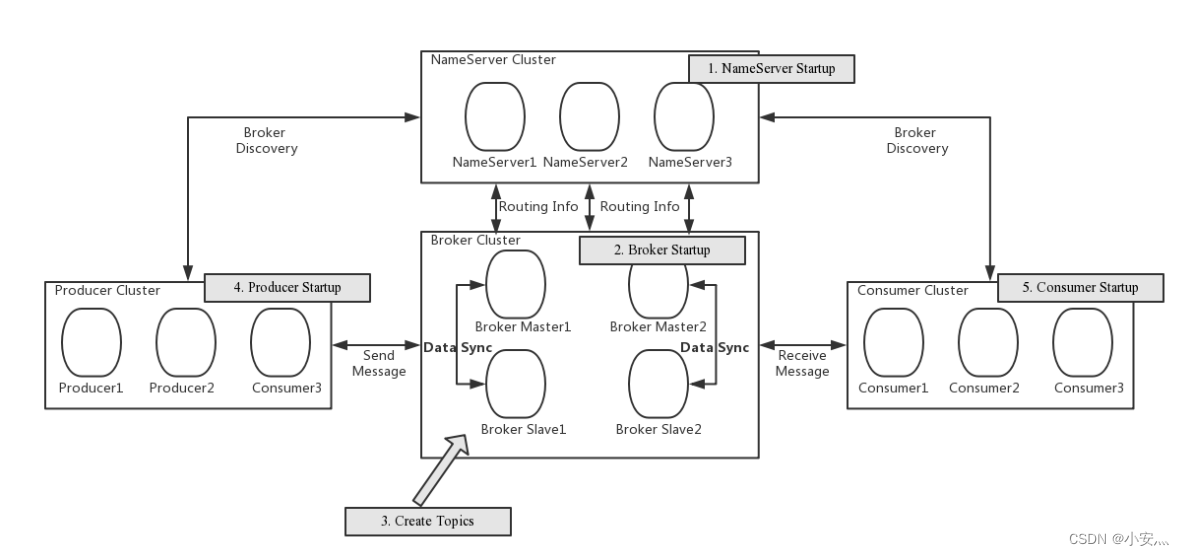
NameServer : It is an almost stateless node that can be deployed in a cluster without any information synchronization between nodes.
-
Broker : Broker deployment is relatively complicated. Broker is divided into Master and Slave. One Master can correspond to multiple Slaves, but one Slave can only correspond to one Master. The corresponding relationship between Master and Slave is defined by specifying the same BrokerName and different BrokerId. BrokerId 0 means Master, non-zero means Slave. Master can also deploy multiple. Each Broker establishes a persistent connection with all nodes in the NameServer cluster, and regularly registers Topic information to all NameServers.
-
Producer : The Producer establishes a long connection with one of the nodes in the NameServer cluster (selected at random), periodically fetches Topic routing information from the NameServer, establishes a long connection to the Master that provides Topic services, and sends heartbeats to the Master regularly. Producer is completely stateless and can be deployed in clusters.
-
Consumer : Consumer establishes a long-term connection with one of the nodes in the NameServer cluster (selected at random), regularly fetches Topic routing information from NameServer, establishes a long-term connection to Master and Slave that provide Topic services, and sends heartbeats to Master and Slave regularly. Consumers can subscribe to messages from the Master or from the Slave, and the subscription rules are determined by the Broker configuration.
5. Data writing process
5.1、Kafka
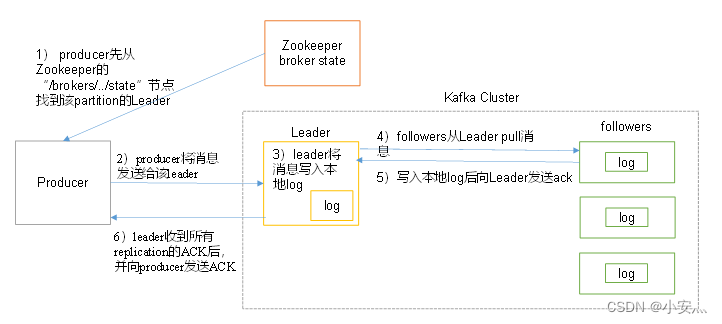
- The producer first finds the leader of the partition from the "/brokers/.../state" node of zookeeper
- The producer sends the message to the leader
- The leader writes the message to the local log
- Followers pull messages from the leader, write to the local log and send ACK to the leader
- After the leader receives the ACK of all replications in the ISR , it increases HW (high watermark, offset of the last commit) and sends ACK to the producer
6. Data storage structure
6.1、Kafka
6.1.1、broker
- Physically divide the topic into one or more patitions
- patition: corresponding to the num.partitions=3 configuration in server.properties
- Each patition physically corresponds to a folder (the folder stores all messages and index files of the patition), as follows:
[root@hadoop102 logs]$ ll
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-0
drwxrwxr-x. 2 root root 4096 8月 6 14:35 first-1
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-2
[root@hadoop102 logs]$ cd first-0
[root@hadoop102 first-0]$ ll
-rw-rw-r--. 1 root root 10485760 8月 6 14:33 00000000000000000000.index
-rw-rw-r--. 1 root root 219 8月 6 15:07 00000000000000000000.log
-rw-rw-r--. 1 root root 10485756 8月 6 14:33 00000000000000000000.timeindex
-rw-rw-r--. 1 root root 8 8月 6 14:37 leader-epoch-checkpoint
storage policy
Kafka keeps all messages regardless of whether they are consumed or not. There are two strategies for removing old data:
- Time-based: log.retention.hours=168
- Based on size: log.retention.bytes=1073741824
It should be noted that because the time complexity of Kafka reading a specific message is O(1), that is, it has nothing to do with the file size, so deleting expired files here has nothing to do with improving Kafka performance.
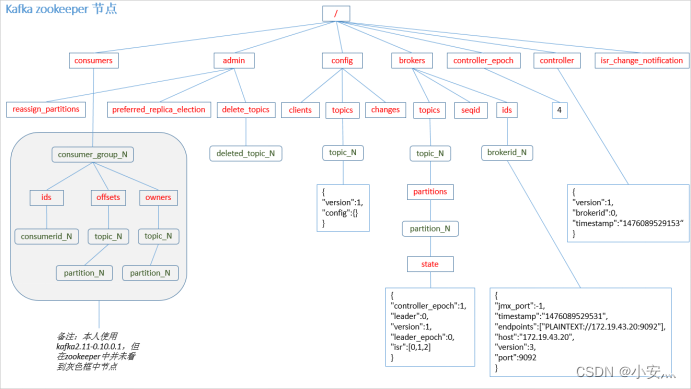
6.1.2、zookeeper
PS: The producer is not registered in zk, and the consumer is registered in zk.
6.2、RocketMQ
- The storage of RocketMQ messages is completed by the cooperation of ConsumeQueue and CommitLog.
- CommitLog : is the real physical storage file of the message
- ConsumeQueue : It is a logical queue of messages, similar to an index file of a database, which stores addresses pointing to physical storage.
- Each Message Queue under each Topic has a corresponding ConsumeQueue file.

- CommitLog : store metadata of messages
- ConsumerQueue : Store the index of the message in the CommitLog
- IndexFile : Provides a method of querying messages by key or time interval for message query. This method of searching for messages through IndexFile does not affect the main process of sending and consuming messages
Brush mechanism:
- RocketMQ messages are stored on the disk, which not only ensures recovery after power failure, but also allows the amount of stored messages to exceed the memory limit.
- In order to improve performance, RocketMQ will try to ensure the sequential writing of the disk as much as possible.
- When the message is written to RocketMQ through the Producer, there are two ways to write to the disk, which are synchronous and asynchronous.
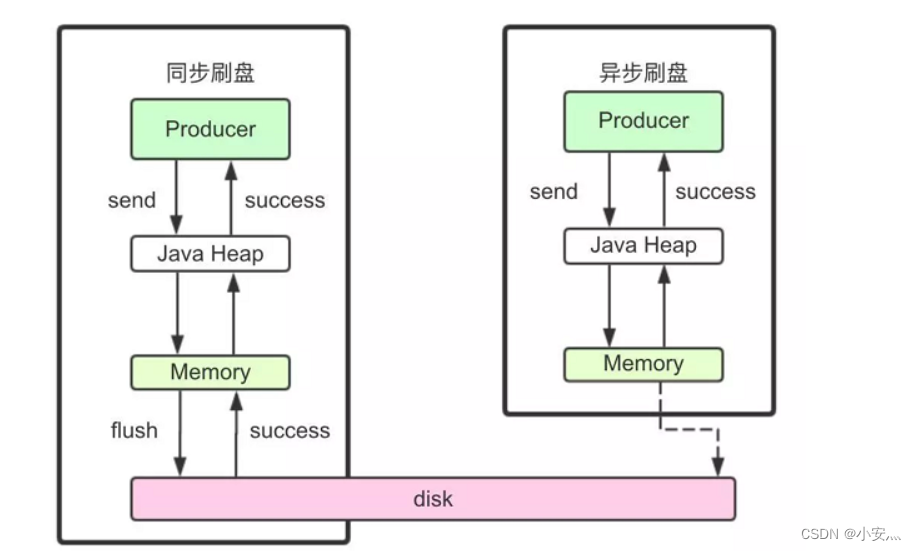
1) Synchronous brushing
When returning a write-success status, the message has been written to disk. The specific process is that after the message is written into the PAGECACHE of the memory, the thread for flashing the disk is immediately notified to flush the disk, and then waits for the completion of the disk flushing. After the execution of the flushing thread is completed, the waiting thread is awakened, and the status of writing the message is returned successfully.
2) Asynchronous brushing
When the write success status is returned, the message may only be written into the PAGECACHE of the memory. The return of the write operation is fast and the throughput is large; when the amount of messages in the memory accumulates to a certain level, the write to disk action is uniformly triggered and written quickly.
3) Configuration
Whether to flush disk synchronously or asynchronously is set through the flushDiskType parameter in the Broker configuration file. This parameter is configured as one of SYNC_FLUSH and ASYNC_FLUSH.
Message master-slave replication
If a Broker group has a Master and a Slave, messages need to be copied from the Master to the Slave, and there are two replication methods: synchronous and asynchronous.
1) Synchronous replication
The synchronous replication method is to wait for both Master and Slave to write successfully before feeding back the successful writing status to the client;
In the synchronous replication mode, if the Master fails, all the backup data on the Slave is easy to restore, but synchronous replication will increase the data writing delay and reduce the system throughput.
2) Asynchronous replication
The asynchronous replication method is that as long as the master writes successfully, it can feedback the write success status to the client.
In the asynchronous replication mode, the system has lower latency and higher throughput, but if the Master fails, some data may be lost because it has not been written to the Slave;
3) Configuration
Synchronous replication and asynchronous replication are set through the brokerRole parameter in the Broker configuration file. This parameter can be set to one of the three values of ASYNC_MASTER, SYNC_MASTER, and SLAVE.
4) Summary
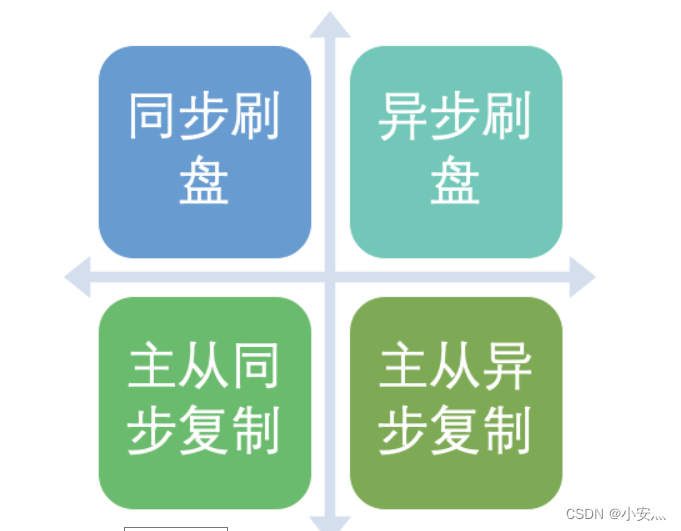
- In practical applications, it is necessary to combine the business scenarios and reasonably set the disk flushing mode and master-slave replication mode, especially the SYNC_FLUSH mode, which will significantly reduce performance due to frequent triggering of disk write actions.
- Normally, the Master and Slave should be configured as ASYNC_FLUSH, and the master-slave should be configured as SYNC_MASTER, so that even if one machine fails, data will not be lost, which is a good choice.