Original address: https://blog.csdn.net/anzhsoft/article/details/19563091
1 History
RabbitMQ is an open source implementation of AMQP (Advanced Message Queue) developed by erlang. The emergence of AMQP is actually in response to the needs of the general public. Although there are many open standards in the world of synchronous message communication (such as COBAR's IIOP, or SOAP, etc.), this is not the case in asynchronous message processing. Only large enterprises There are some commercial implementations (such as Microsoft's MSMQ, IBM's Websphere MQ, etc.), therefore, in June 2006, Cisco, Redhat, iMatix, etc. jointly developed an open standard for AMQP.
RabbitMQ is developed and commercially supported by RabbitMQ Technologies Ltd. The company was acquired by SpringSource (a division of VMWare) in April 2010. It was merged into Pivotal in May 2013. In fact, VMWare, Pivotal and EMC are essentially one family. The difference is that VMWare is an independent listed subsidiary, while Pivotal integrates some of EMC's resources and is not listed now.
The official website of RabbitMQ is http://www.rabbitmq.com
2 Application scenarios
Closer to home. RabbitMQ, or what problem does AMQP solve, or what is its application scenario?
For a large software system, it will have many components or modules or subsystems or (subsystem or Component or submodule). So how do these modules communicate? This is very different from traditional IPC. Many traditional IPCs are on a single system, and the modules are highly coupled, which is not suitable for scalability; if sockets are used, different modules can indeed be deployed on different machines, but there are still many problems to be solved. for example:
1) How do the sender and receiver of the information maintain this connection, and if one party's connection is interrupted, how will the data during this period be lost?
2) How to reduce the coupling between sender and receiver?
3) How to let the receiver with high Priority receive the data first?
4) How to achieve load balance? Efficiently balance the load of receivers?
5) How to efficiently send data to the relevant receivers? That is to say, the receiver subscribes to different data, how to do an effective filter.
6) How to make it scalable and even send this communication module to the cluster?
7) How to ensure that the receiver has received complete and correct data?
The AMDQ protocol solves the above problems, while RabbitMQ implements AMQP
3 System Architecture
It may not be appropriate to be a system architecture, and it may be more appropriate to call the system architecture of an application scenario.
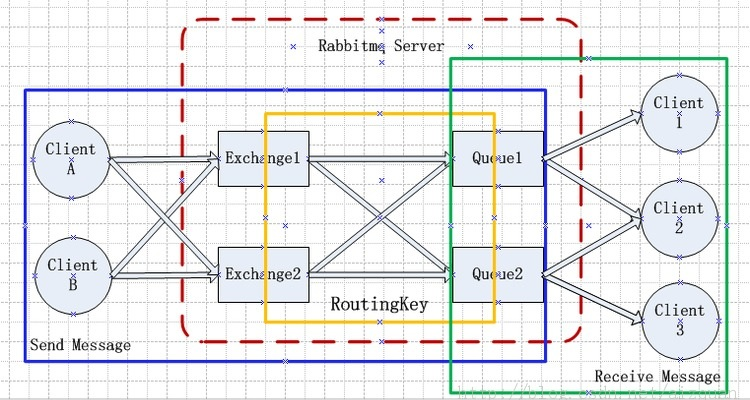
RabbitMQ Server : Also called broker server, it is not a truck that delivers food, but a transport service. The original words are RabbitMQ isn't a food truck, it's a delivery service. His role is to maintain a route from Producer to Consumer to ensure that data can be transmitted in the specified way. But this guarantee is not a 100% guarantee, but it is sufficient for common applications. Of course, for commercial systems, you can do another layer of data consistency guard (protection) to completely ensure the consistency of the system.
Client A & B : Also called Producer, the sender of data. createmessages and publish (send) them to a broker server (RabbitMQ). A Message has two parts: payload and label. The payload, as the name suggests, is the data being transmitted. The label is the name of the exchange or a tag, which describes the payload, and RabbitMQ also uses this label to decide which Consumer to send the message to. AMQP only describes the label, and RabbitMQ determines the rules for how to use the label.
Client 1, 2, 3 : Also called Consumer, the receiver of data. Consumers attach to a broker server (RabbitMQ) and subscribe to a queue. Think of a queue as a mailbox with a name. When a Message arrives at a mailbox, RabbitMQ sends it to one of its subscribers, the Consumer. Of course, the same Message may be sent to many Consumers. In this Message, only the payload, the label has been deleted. For the Consumer, it does not know who sent this information. The protocol itself does not support it. But of course, if the payload sent by the Producer contains the information of the Producer, it is another matter.
For the correct transfer of data from a Producer to a Consumer, there are three more concepts that need to be clarified: exchanges, queues and bindings.
Exchanges are where producers publish their messages.
exchanges are where producers publish messages
Queuesare where the messages end up and are received by consumers
Queues are where messages are finally received by consumers
Bindings are how the messages get routed from the exchange to particular queues.
bindings are how messages are routed from the exchange to specific queues
Connection : It is a TCP connection. Both Producer and Consumer are connected to RabbitMQ Server through TCP. Later we can see that the beginning of the program is to establish this TCP connection.
Channels: Virtual connections. It is established in the above mentioned TCP connection. Data flow is carried out in Channel. That is to say, the general situation is that the program starts to establish a TCP connection, and the second step is to establish this Channel.
So, why use Channel, instead of using TCP connection directly?
For the OS, establishing and closing TCP connections is costly. Frequent establishment and closing of TCP connections has a great impact on the performance of the system, and the number of TCP connections is also limited, which also limits the system's ability to handle high concurrency. However, establishing a Channel in a TCP connection has no such cost. For Producer or Consumer, multiple Channels can be used concurrently for Publish or Receive. Experiments have shown that 1s data can publish 10K data packets. Of course, for different hardware environments, the data of different packet sizes is definitely different, but I just want to explain that for ordinary Consumer or Producer, this is enough. If not enough, you should consider how to refine your split design.
4. Further details clarified
4.1 Use ack to confirm the correct delivery of the Message
1) By default, if the Message has been correctly received by a Consumer, the Message will be removed from the queue. Of course, the same Message can also be sent to many Consumers.
2) If a queue is not subscribed by any Consumer, then if data arrives in this queue, the data will be cached and will not be discarded. When there is a Consumer, the data will be sent to the Consumer immediately, and when the data is correctly received by the Consumer, the data will be deleted from the queue
So what is the correct receipt? by ack. Each Message must be acknowledged (acknowledged, ack). We can display it in the program to ack, or we can automatically ack. If there is data that is not acked, then:
RabbitMQ Server will send this information to the next Consumer.
If the app has a bug and forgets to ack, then RabbitMQ Server will not send data to it, because Server thinks that this Consumer has limited processing capacity.
Moreover, the mechanism of ack can play a role in current limiting ( Benefitto throttling ): sending ack after the Consumer has processed the data, or even sending ack after an additional delay, will effectively balance the load of the Consumer.
Of course, for practical examples, for example, we may merge some data, such as the data within 4s of merge, and then get the data after sleep 4s. Especially when monitoring the state of the system, we don't want all the states to be transmitted in real time, but want a certain delay. This reduces some IO and the end user doesn't feel it.
4.2 Reject a message
There are two ways, the first Reject allows RabbitMQ Server to send the Message to the next Consumer. The second is to immediately delete the Message from the queue.
4.3 Creating a queue
Both Consumer and Procuder can create queue through queue.declare . For a Channel, the Consumer cannot declare a queue, but subscribe to other queues. Of course, you can also create private queues. This way only the app itself can use the queue. The queue can also be deleted automatically. The queue marked as auto-delete will be automatically deleted after the last Consumer unsubscribe. So what if you create an existing queue? Then there will be no impact. It should be noted that there is no impact, that is to say, if the parameters of the second creation are different from the first time, then although the operation is successful, the attributes of the queue will not be modified.
So who should be responsible for creating this queue? Is it Consumer or Producer?
If the queue does not exist, of course the Consumer will not get any Message. But if the queue does not exist, then the Message of the Producer Publish will be discarded. Therefore, in order not to lose data, both Consumer and Producer try to create the queue! Anyway, no matter what, this interface will not be a problem.
Queue's handling of load balance is perfect. For multiple Consumers, RabbitMQ uses a round-robin method to send to different Consumers in a balanced manner.
4.4 Exchanges
As can be seen from the architecture diagram, the Message of Procuder Publish enters the Exchange. Then through the "routing keys", RabbitMQ will find out which queue to put the message in. The queue is also bound by this routing keys.
There are three types of Exchanges: direct, fanout, topic. Each implements a different routing algorithm.
· Direct exchange : If the routing key matches, then the Message will be delivered to the corresponding queue. In fact, when the queue is created, it will automatically bind the exchange with the name of the queue as the routing key.
· Fanout exchange : will broadcast to the responding queue.
· Topic exchange : Pattern matching on keys, such as ab* can be passed to all ab* queues.
4.5 Virtual hosts
Each virtual host is essentially a RabbitMQ Server, with its own queue, exchagne, and bings rules, etc. This ensures that you can use RabbitMQ in multiple different applications.
Next I will use Python to illustrate the use of RabbitMQ.