Table of contents
What memory data should be snapshotted?
Will the generation of RDB files block the main thread?
Advantages and Disadvantages of RDB
Data loss problem caused by RDB in Redis
Issues related to Redis persistence
Are there any other potential blocking risks in the Redis persistence process?
Why doesn't AOF be used for replication between master and slave libraries?
The simplest implementation of Redis distributed lock
What should I do if the lock is released by someone else?
Java code implements distributed lock
What should I do if the lock expiration time is difficult to evaluate?
Distributed lock joins watchdog
Distributed lock is implemented by adding watchdog code
Are the locks in the cluster still safe?
Redlock implements the overall process
The rights and wrongs of RedLock
Endurance
Although Redis is an in-memory database, Redis supports two persistence mechanisms: RDB and AOF. Writing data to disk can effectively avoid data loss caused by process exit. This can be achieved by using the previously persisted files when restarting next time. Data Recovery.
RDB
RDB persistence is the process of generating a snapshot of the current process data and saving it to the hard disk. The so-called memory snapshot refers to the state record of the data in the memory at a certain moment. This is similar to a photo. When you take a photo of a friend, a photo can completely record the image of your friend in that moment. RDB is the abbreviation of Redis DataBase.
What memory data should be snapshotted?
Redis data is all in memory. In order to ensure the reliability of all data, it performs a full snapshot, that is, all data in memory is recorded to disk. However, the larger the RDB file, the greater the time overhead of writing data to disk.
Will the generation of RDB files block the main thread?
Redis provides two manual commands to generate RDB files, namely save and bgsave.
save: Executed in the main thread, it will cause blocking; for instances with relatively large memory, it will cause long-term blocking, and is not recommended for online environments. bgsave: Create a sub-process specifically for writing RDB files, avoiding blocking of the main thread. This is also the default configuration for Redis RDB file generation.
Command practical demonstration

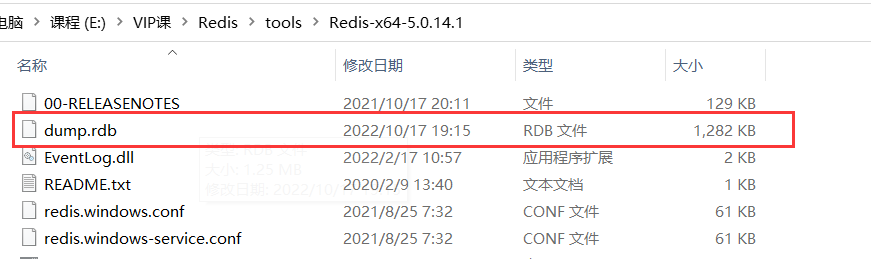

![]()
In addition to manual triggering by executing commands, there is also a persistence mechanism inside Redis that automatically triggers RDB, such as the following scenarios:
1) Use save related configuration, such as "save mn". Indicates that bgsave is automatically triggered when the data set is modified n times within m seconds.

2) If the slave node performs a full copy operation, the master node automatically executes bgsave to generate an RDB file and sends it to the slave node.
3) When executing the debug reload command to reload Redis, the save operation will also be automatically triggered.

4) By default, when executing the shutdown command, if the AOF persistence function is not enabled, bgsave will be automatically executed.
To turn off RDB persistence, on the Redis version (6.2.4) described in the course, change the save configuration in the configuration file to save ""

bgsave execution process
Pausing write operations for the sake of snapshots is certainly unacceptable. So at this time, Redis will use the copy-on-write (COW) technology provided by the operating system to process write operations normally while performing snapshots.
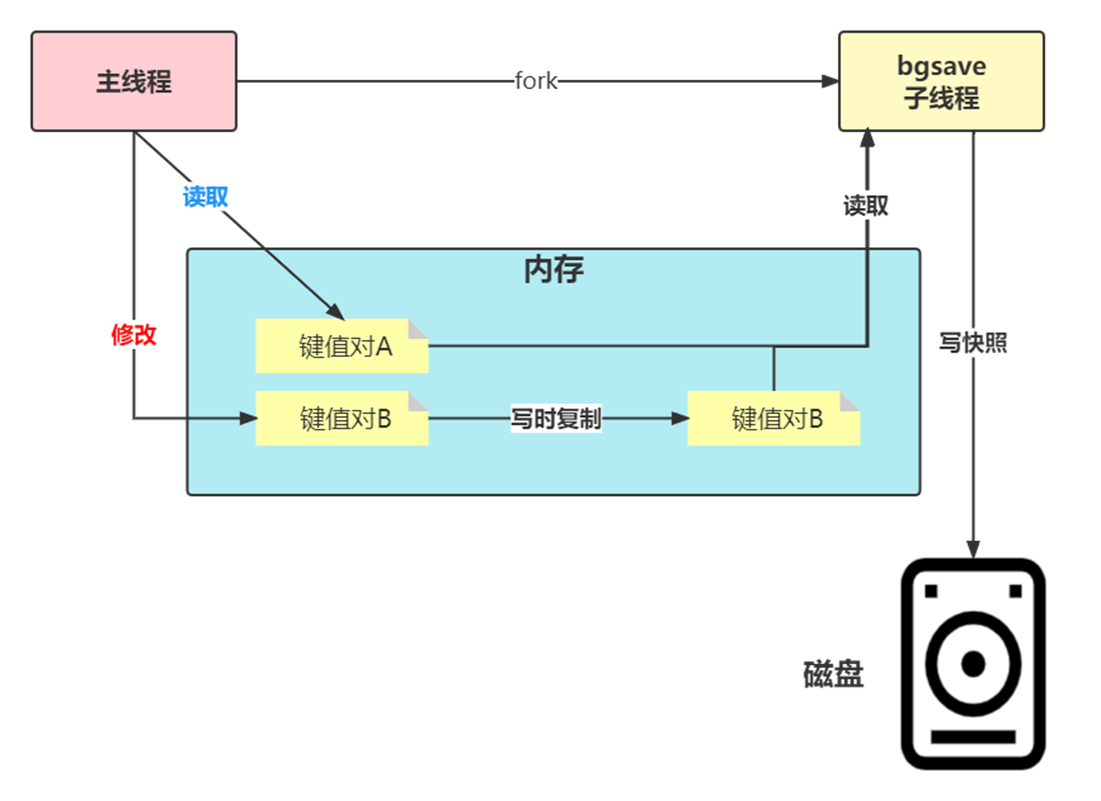
The bgsave sub-process is generated by fork of the main thread and can share all memory data of the main thread. After the bgsave sub-process runs, it starts to read the memory data of the main thread and writes them to the RDB file.
If the main thread also performs read operations on these data (such as key-value pair A in the figure), then the main thread and the bgsave sub-process will not affect each other. However, if the main thread wants to modify a piece of data (such as the key-value pair B in the figure)