Summary of questions and answers (continuously updated):
(1) What is the impact of the fully connected layer on the model?
First, we understand that the composition of the fully connected layer is as follows:
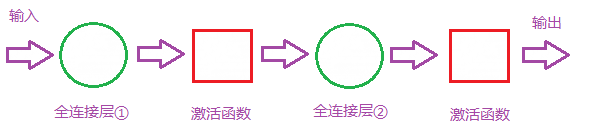
Two-layer fully connected layer structure
Then the parameters that the fully connected layer affects the model are three:
- The total number of layers (length) of fully connected solution layers
- Number of neurons (width) in a single fully connected layer
- activation function
First we need to understand the role of the activation function:
Increase the nonlinear expression ability of the model
For more details please go to:
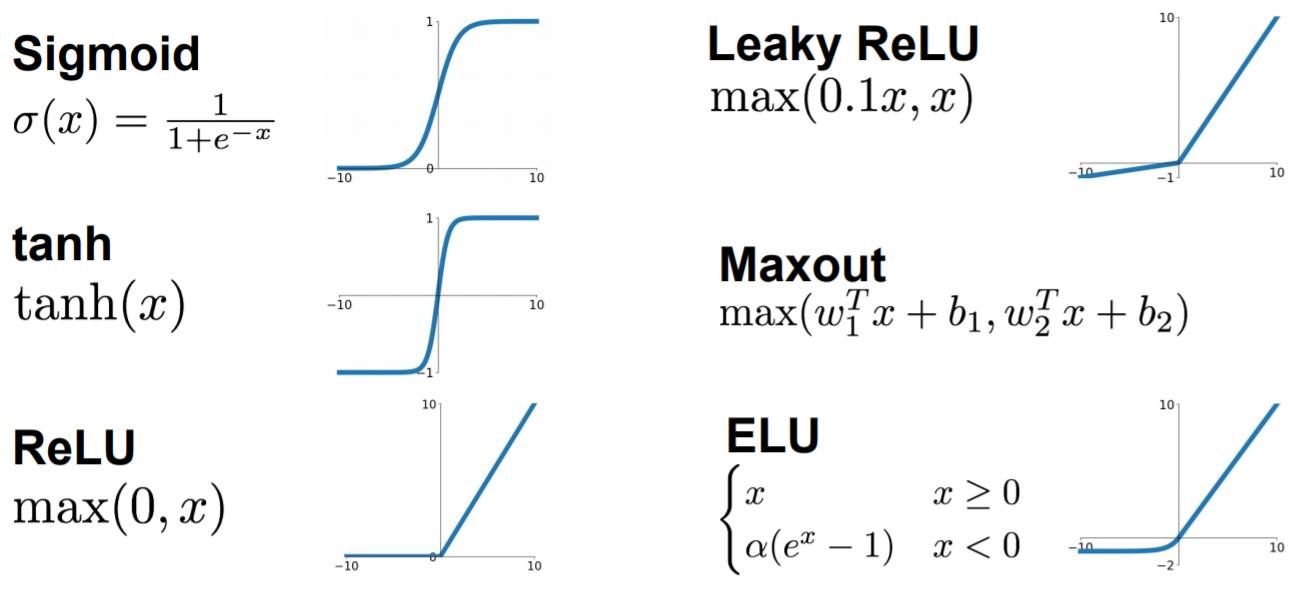
If the width of the fully connected layer remains unchanged, increase the length:
Advantages: The number of neurons increases, and the complexity of the model increases; the number of fully connected layers deepens, and the nonlinear expression ability of the model improves. In theory, it can improve the learning ability of the model.
If the length of the fully connected layer remains unchanged, increase the width:
Advantages: The number of neurons increases and the model complexity increases. In theory, it can improve the learning ability of the model.
The more difficulty length and width the better?
Certainly not
(1)Disadvantages: Too good learning ability can easily lead to overfitting.
(2)Disadvantages: The calculation time increases and the efficiency becomes lower.
So how to judge the learning ability of the model?
Look at the Training Curve and Validation Curve. Under other ideal conditions, if the Training Accuracy is high and the Validation Accuracy is low, it means overfitting. You can try to reduce the number of layers or parameters. If the Training Accuracy is low, it means that the model is not learning well. You can try to increase the parameters or the number of layers. As for increasing the length and width, this should be considered based on the actual situation.
PS: Many times when we design a network model, we not only consider accuracy, but also often have to find a good balance between Accuracy/Efficiency.
-------------------
Fully connected layer:
The fully connected layer is generally placed at the end of the network and is used to synthesize all information. For CNN, the range of feature extraction is the entire image, and the image is directly reduced in dimension into a bunch of sequences.
The convolutional layer is a local connection. The range of features it can extract depends on the receptive field of the convolution kernel. When the receptive field of the convolution kernel covers the entire image, its role is similar to that of a fully connected layer. . (So using a convolution kernel with the same size as the feature map for convolution, extracting full-image range features, and connecting a fully connected layer, the calculation process is equivalent, and the input and output parameters are exactly the same)
Why full connectivity fell out of favor:
Some people say it is because of the large number of parameters. In fact, if the feature map is compressed small enough and then fully connected, the amount of parameters and calculations will not be large.
I think the main reason is that most current tasks, such as target detection or segmentation, do not require the extraction of full-image features. They only need to extract features within the receptive field that can cover the size of the target object. Especially for small object detection problems, the receptive field is very small. If we also use full connection to extract full image features, the target we want to detect will be submerged in the average features of other backgrounds and become unrecognizable.
Full convolution also has a big advantage:
The input size is no longer required to be a fixed size. It is only required that the input image is not too small to be downsampled by the network until the size is insufficient.
The input image is downsampled exactly to 1*1, which is the same effect as being fully connected; after downsampling, it is larger than 1*1, and it does not affect the calculation process of the network at all.
The fully connected calculation form cannot be so versatile, so it can be completely replaced by the fully convolutional form.
Author: Xuanyun
Link: https://zhuanlan.zhihu.com/p/136786896
Source: Zhihu
Copyright belongs to the author. For commercial reprinting, please contact the author for authorization. For non-commercial reprinting, please indicate the source.
Activation Function, assuming that our output after passing a Relu is as follows
Replay:


Then start to reach the fully connected layer

Fully connected layer
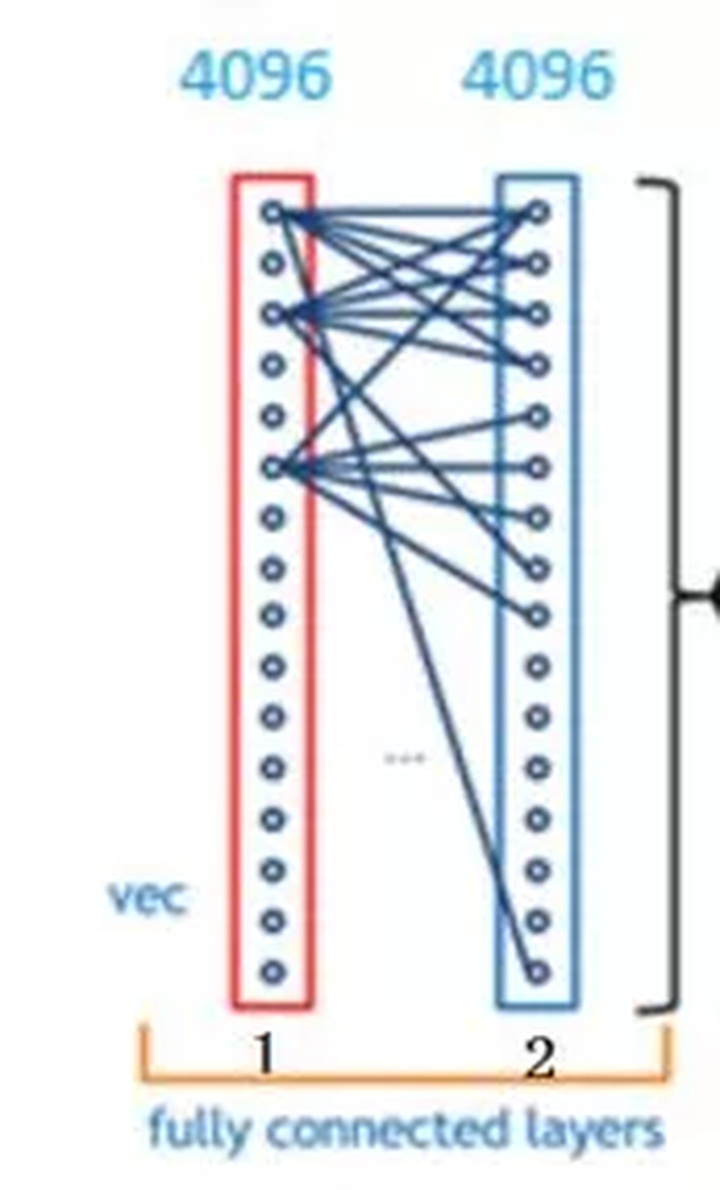
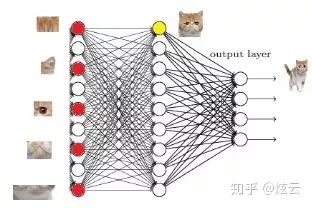
Take the above picture as an example. Let's carefully look at the structure of the fully connected layer in the above picture. Each layer in the fully connected layer is a tiled structure composed of many neurons (1x 4096). The above picture is not obvious. Let's look at the following picture.
How does it convert the 3x3x5 output into 1x4096 format?
It's very simple. It can be understood as doing a convolution in the middle.

From the picture above, we can see that we use a 3x3x5 filter to deconvolve the output of the activation function. The result is the output of a neuron of a fully connected layer. This output is a value.
Because we have 4096 neurons
We actually use a 3x3x5x4096 convolutional layer to deconvolve the output of the activation function.
The fully connected layer has two layers of 1x4096 fully connected layer tile structure (some network structures have one layer, or two or more layers)
But most of them have more than two layers. You all know Taylor's formula, which means using a polynomial function to fit a smooth function. A neuron in one layer of our fully connected layer here can be regarded as a polynomial, and many neurons are used to fit it. Fitting data distribution, but using only one fully connected layer sometimes cannot solve nonlinear problems, but if there are two or more fully connected layers, nonlinear problems can be solved well.
The previous function of the fully connected layer was to extract features, and the function of the fully connected layer was to classify
Assume that this neural network model has been trained
The fully connected layer is already known
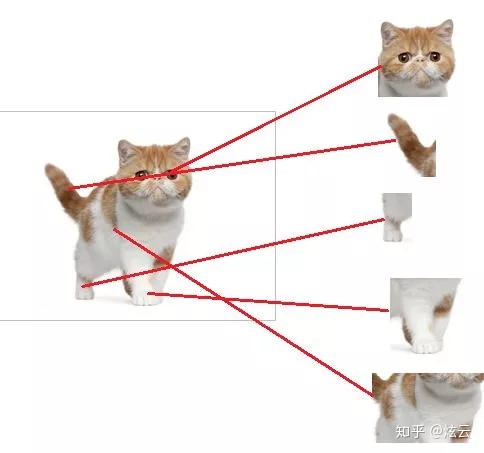
When we get the above features, I can judge that this thing is a cat, because the main function of the fully connected layer is to achieve classification. From the figure below, we can see
The red neurons indicate that this feature has been found (activated). Other neurons in the same layer either have unclear features of cats or have not been found. When we combine these found features, we find that the one that best meets the requirements is Cat, ok, I think this is a cat, so let’s go one level forward now, and now we need to classify the sub-features, that is, classify cat heads, cat tails, cat legs, etc. For example, we now need to classify cats Find out the head

The cat head has so many features, so our next task is to find these sub-features of the cat head, such as eyes and ears.

The principle is the same as distinguishing cats. When we find these features, the neurons are activated (red circles in the picture above). Where do these detailed features come from? , which comes from the previous convolutional layer and downsampling layer.
What exactly is the fully connected layer used for? Let me talk about three points.
- Fully connected layers (FC) play the role of "classifier" in the entire convolutional neural network. If the operations such as convolution layer, pooling layer and activation function layer map the original data to the hidden layer feature space, the fully connected layer plays the role of "distributed features" that will be learned. Represents the role of mapping to sample tag space. In actual use, a fully connected layer can be implemented by a convolution operation: a fully connected layer whose front layer is fully connected can be converted into a convolution with a convolution kernel of 1x1; and a fully connected layer whose front layer is a convolution layer can be converted into The convolution kernel is the global convolution of hxw, and h and w are the height and width of the previous layer convolution result respectively (Note 1).
- Currently, due to the redundancy of fully connected layer parameters (the fully connected layer parameters alone can account for about 80% of the entire network parameters), some recent network models with excellent performance such as ResNet and GoogLeNet use global average pooling (global average pooling (GAP) replaces FC to fuse the learned deep features, and finally uses loss functions such as softmax as the network objective function to guide the learning process. It should be pointed out that networks using GAP instead of FC usually have better prediction performance. For specific cases, please refer to our approach to winning the championship in the ECCV'16 (Video) Apparent Personality Analysis Competition:"The Way of the Champion" Apparent Personality Analysis Competition Experience Sharing - Zhihu Column a>, project:Deep Bimodal Regression for Apparent Personality Analysis
- At a time when FC is becoming less and less optimistic,our recent research (In Defense of Fully Connected Layers in Visual Representation Transfer< /span>, ImageNet can be regarded as the source domain (source domain in transfer learning). Fine tuning is the most commonly used transfer learning technique in the field of deep learning. For fine-tuning, if the image in the target domain is very different from the image in the source domain (for example, compared with ImageNet, the target domain image is not an object-centered image, but a landscape photo, see the figure below), without FC The results after network fine-tuning are worse than those of networks containing FC. Therefore, FC can be regarded as a "firewall" for model representation capabilities. Especially when there is a large difference between the source domain and the target domain, FC can maintain a large model capacity to ensure model representation capabilities. migration. (Redundant parameters are not useless.). Specifically, assuming that the model pre-trained on ImageNet is ) found that FC can act as a “firewall” in the process of migrating model representation capabilities

Note 1: It is necessary to say a few words about the convolution operation to "implement" the fully connected layer.
Taking VGG-16 as an example, for an input of 224x224x3, the output of the last layer of convolution is 7x7x512. If the latter layer is a layer of FC containing 4096 neurons, convolution can be used A global convolution with a kernel of 7x7x512x4096 is used to implement this fully connected operation process. The convolution kernel parameters are as follows:
“filter size = 7, padding = 0, stride = 1, D_in = 512 , D_out = 4096”
After this convolution operation, the output is 1x1x4096.
If you want to superimpose a FC of 2048 again, you can set the convolution layer with parameters of "filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048" operate.