Article directory
Parallel and Distributed Computing Chapter 2 Thread-Level Parallelism: OpenMP Programming
2.1 Basic concepts of thread-level parallelism
When one processor is not enough to meet the computing needs, in addition to enhancing the computing performance of a single core (but this is difficult), the most intuitive way is to increase the number of cores (thread-level parallelism, TLP). We call this kind of multi-processor The structure is a multi-processor, which is characterized by multiple processors sharing a common memory, also called a shared memory model.
2.1.1 Memory access model (shared memory)
- UMA: Uniform Memory Access, consistent access to memory, all processors have consistent access to memory, and can have private caches
- NUMA: Non uniform Memory Access, non-uniform memory access, the processor has its own memory
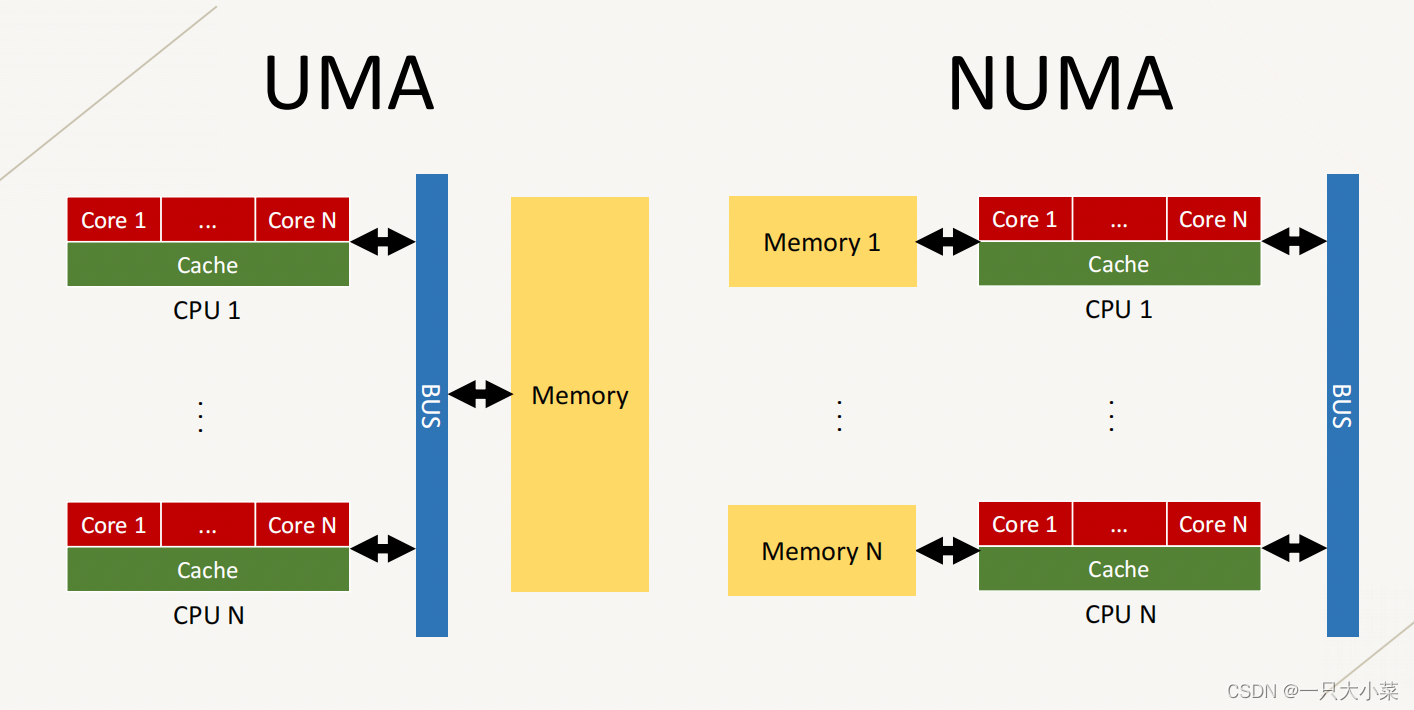
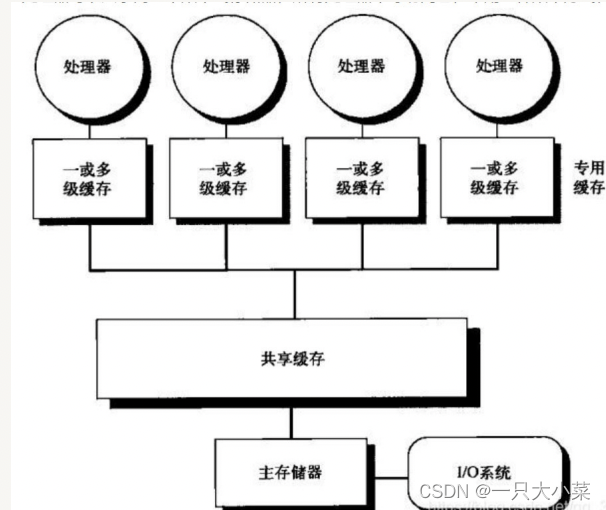
Typical UMA: centralized shared memory SMP
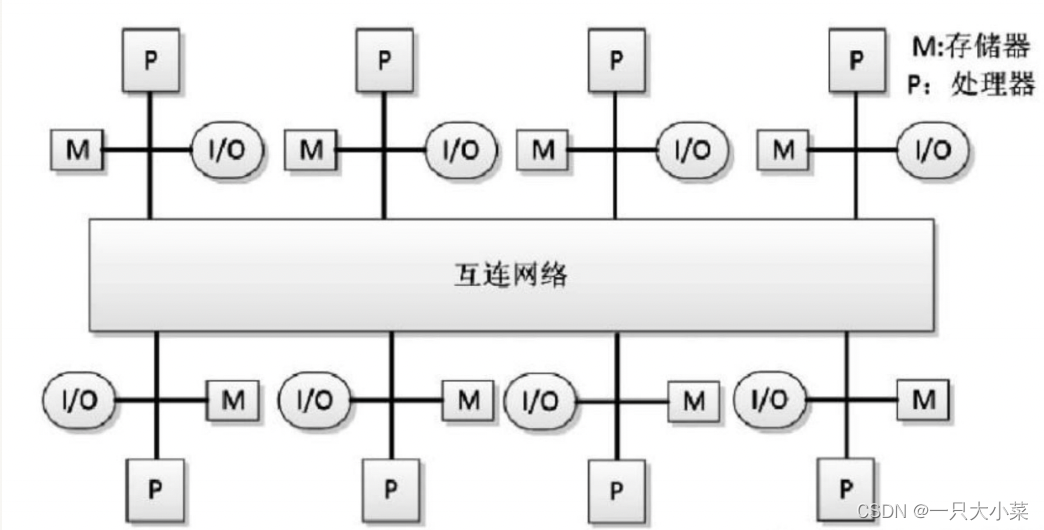
Typical NUMA: Distributed Shared Memory DSM
for example
- There is often only one CPU (package) on a consumer-grade motherboard, which may contain multiple cores and share the main memory, so it belongs to UMA.
- On some enterprise-level motherboards, multiple CPUs can be installed at the same time. Each CPU has its own memory controller, and the CPUs are connected using an external bus. All CPUs share a memory address space, but each manages its own memory. Therefore it belongs to NUMA
Threads and processes
- Process: An instance of an executing program, including the current values of the program counter, registers, and variables (more independent, with its own address space)
- Thread: lightweight process, shared address space, but each has its own stack
The term "thread-level parallelism" described in this chapter refers more to hardware-level thread parallelism on multiprocessors than to software-controlled concurrency implemented in operating systems.
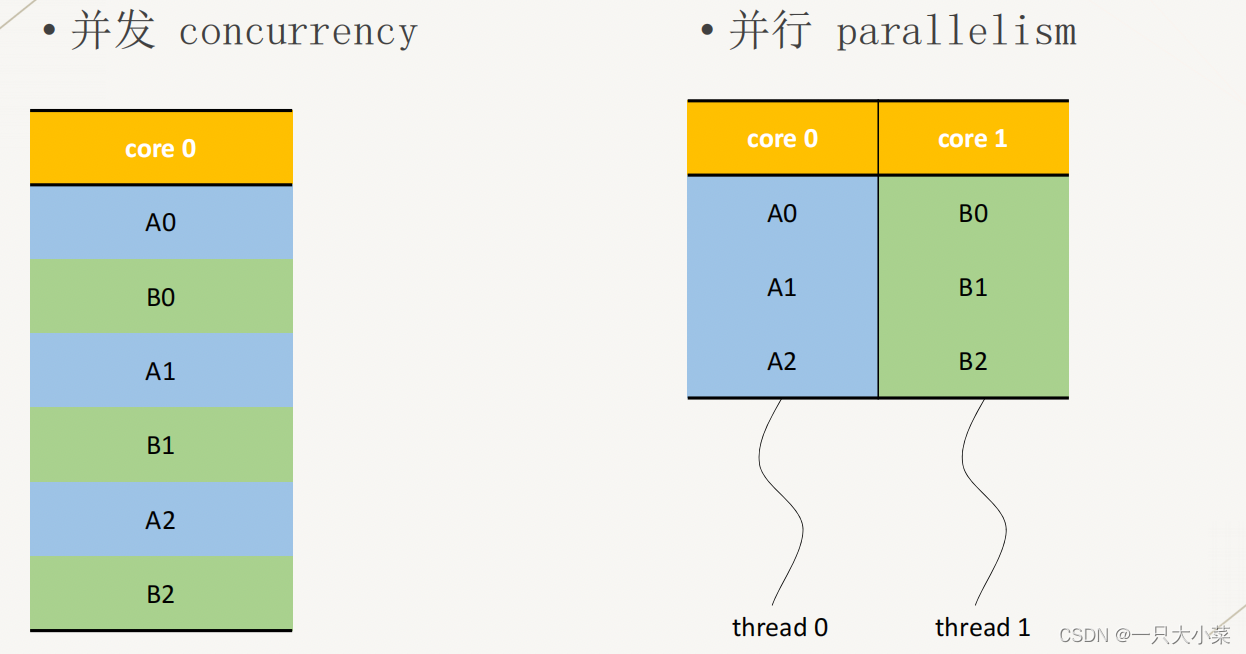
2.1.2 Parallel computing programming model
According to the process interaction mode, we have the following types of parallel programming models:
• Implicit interaction (completely implemented by the compiler, not expanded here)
• Shared variables (Intel Cilk, OpenMP)
• Message passing (MPI)
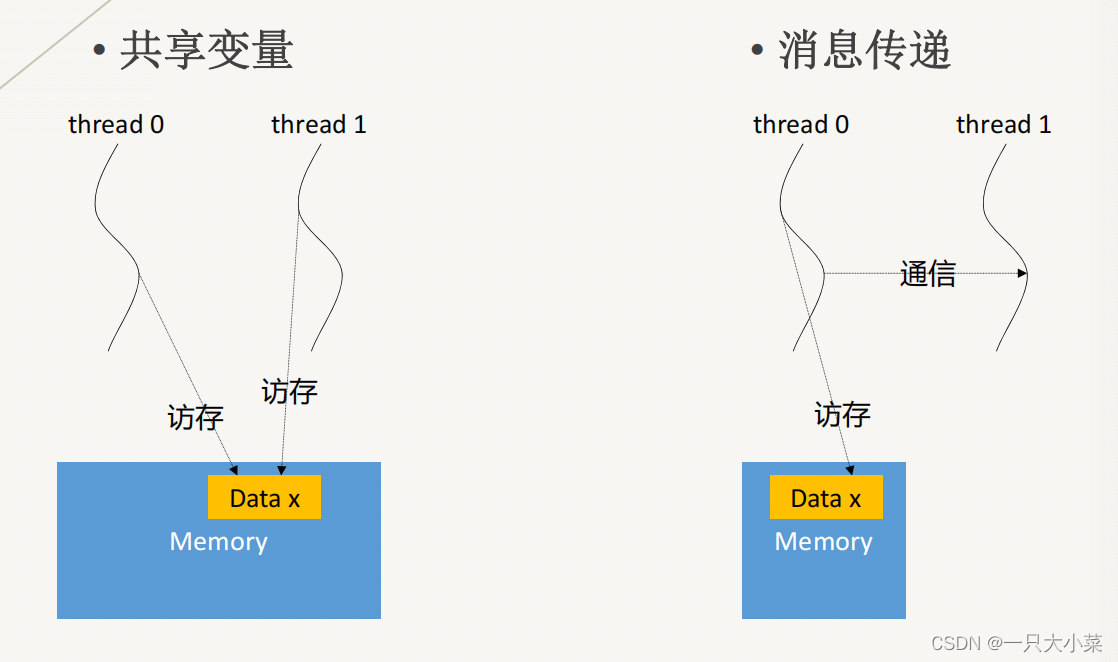
| shared variables | messaging |
|---|---|
| Suitable for SMP, DSM | Suitable for MPP, COW |
| single address space | Multiple address spaces |
| implicit communication | explicit communication |
| In a cluster, it is generally used on multiple cores of a node. | Generally used on multiple nodes in a cluster |
Hidden problems in shared variable programming
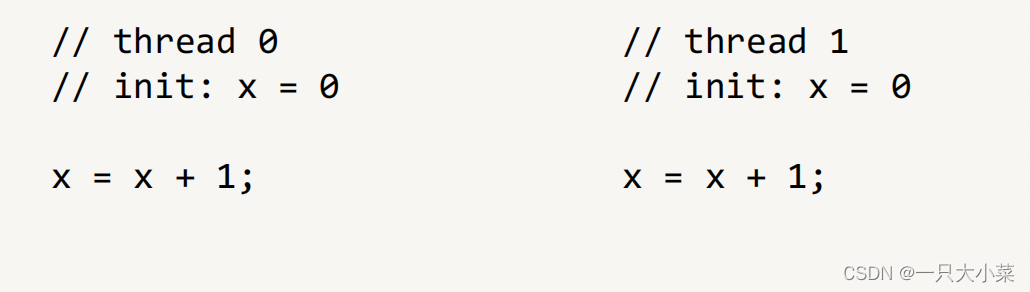
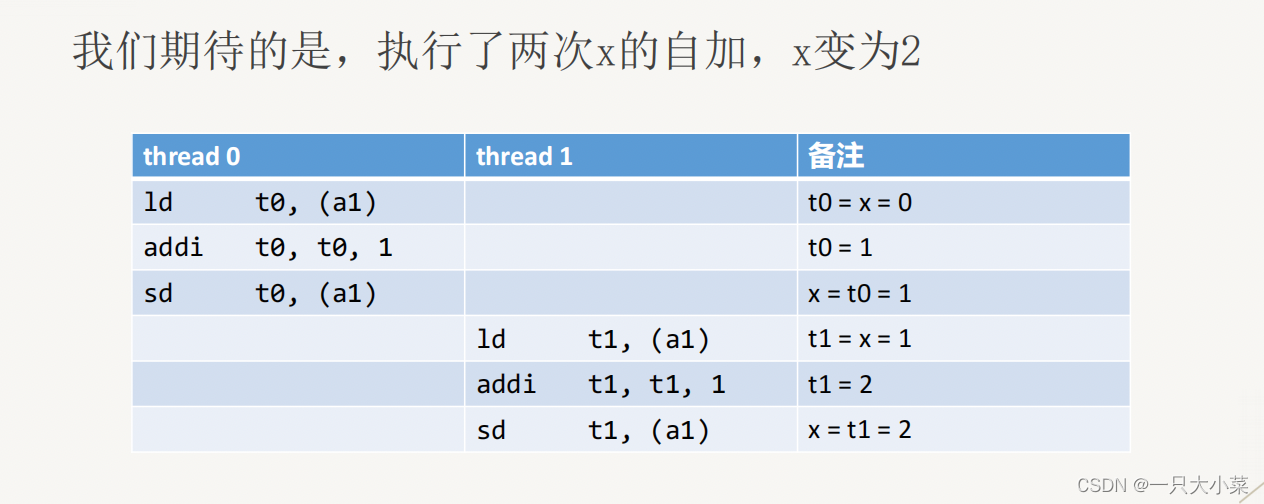

The above problem is called: race condition. When the correct operation of the program depends on the specific timing of each thread in the program (different execution orders will produce different results), a race condition will occur. This dependency often occurs when multiple threads compete for the same resource, especially when there are operations (write operations) that modify the resource state. In memory, this is called a data race
Solution to data competition: Use synchronization to ensure that operations are atomic, order operations, and "protect" resources and operations
Note: "Sort" does not mean that the order is deterministic, so resolving the data race does not mean that the race condition is completely resolved.
Instruction reordering
Instructions may be executed out of order due to cache misses, resulting in errors
memory reordering
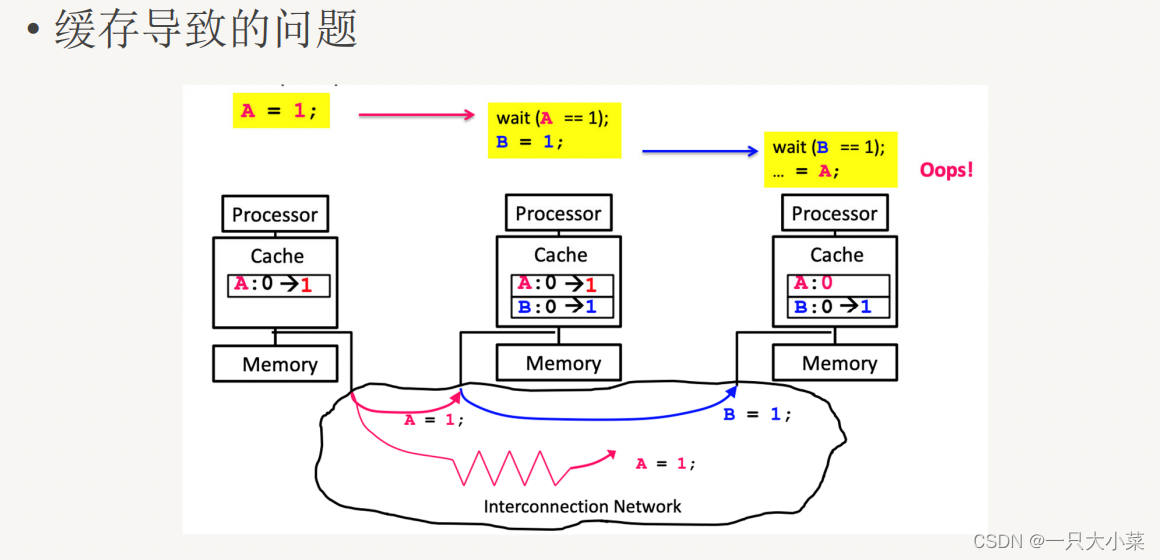
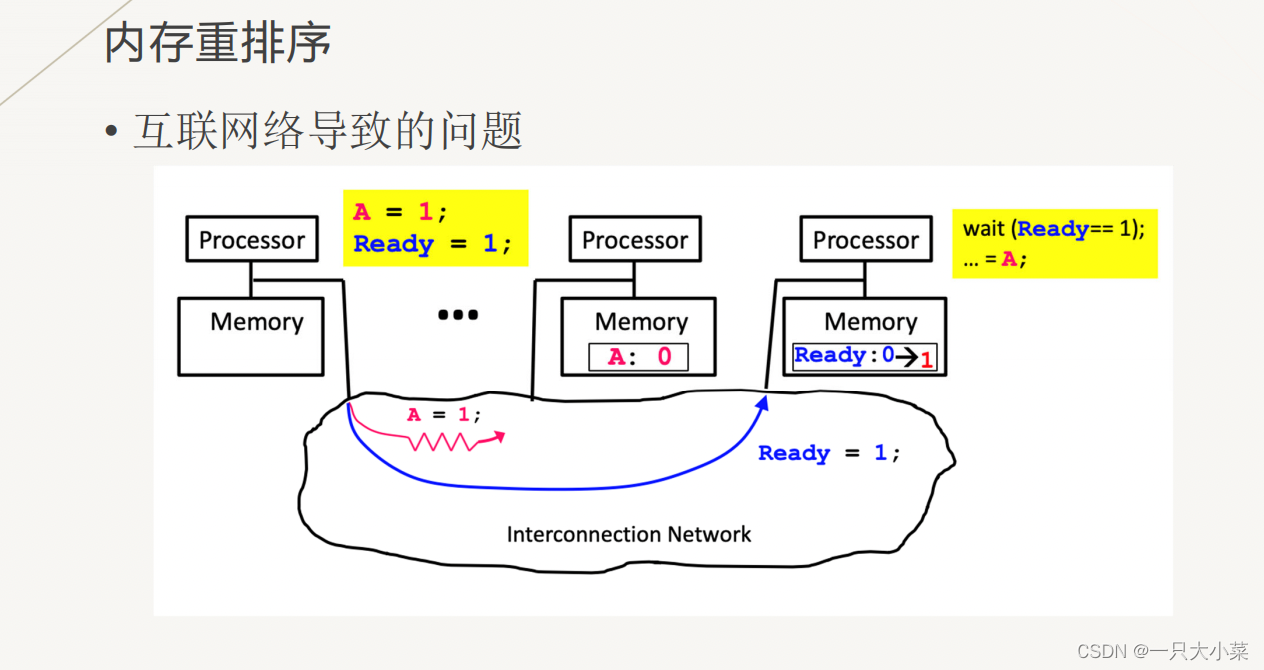
•It can be seen that there is an unforeseen reordering situation between several instructions in one thread (in terms of visibility to another thread)
• This kind of Reordering has no effect on single threads, but it causes problems for multi-threads
• The solution is also through synchronization (locks, fences, etc. technologies)
To sum up, when writing multi-threaded code, please always pay attention to the above issues and make reasonable use of synchronization technology
2.2 Thread-level parallel programming model: OpenMP
2.2.1 openmp architecture
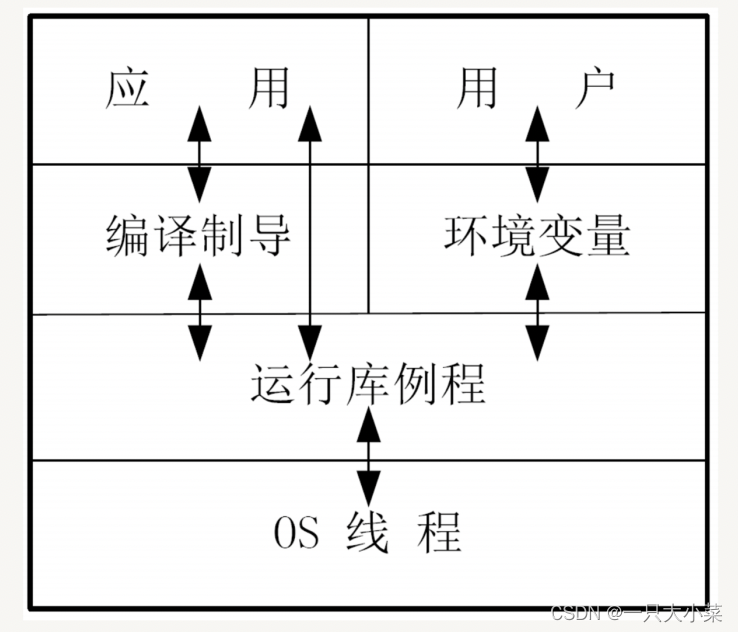
OPENMP parallel programming model: OPENMP is a thread-based parallel programming model. A shared process consists of multiple threads. Using the FORK-JOIN parallel model, the main thread (MASTER THREAD) executes serially until the compilation-guided parallel domain (PARALLEL REGION) appears.
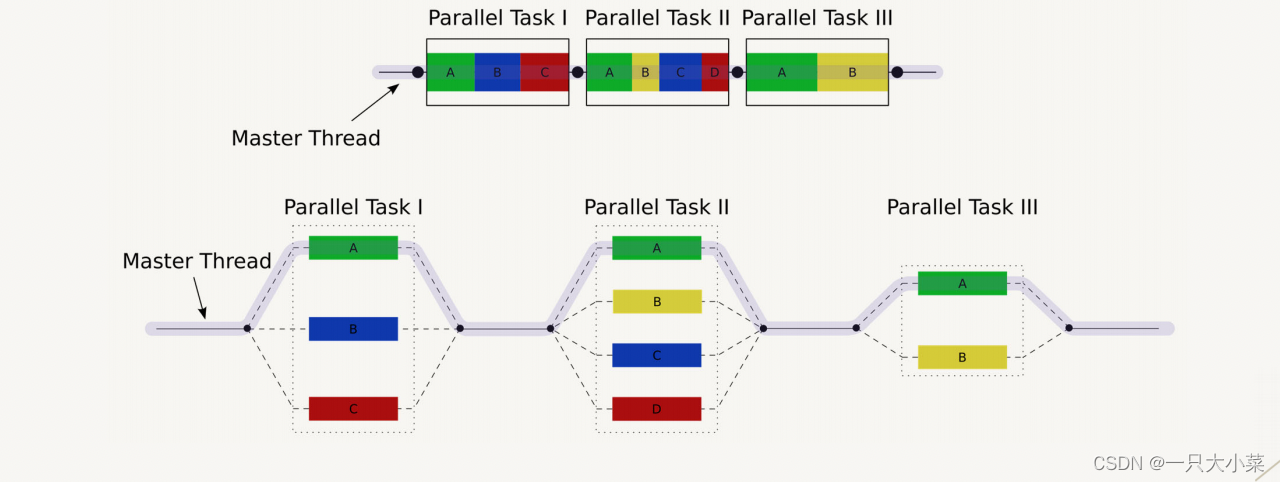
2.2.2 FORK-JOIN model
- Divide a program into serial or parallel parts of many segments
- The serial part is processed using a single thread
- Each sub-task of the parallel part uses multiple threads to divide and conquer
- Subtasks split from parallel tasks can continue to be split
- Use fork to enter the parallel (subtask) part, and use join to return to the serial (parent
task) part
2.2.3 Detailed introduction to OPENMP
- A multi-threaded parallel programming API based on the fork-join model
- Provide interfaces in C, C++, Fortran and other languages
- Mainly suitable for multiprocessors with shared memory structures
OpenMP storage model
- OpenMP divides storage into two categories: shared and private.
- shared variables will be shared between threads (so when operating on them
, please be aware of race conditions and reordering issues, and use synchronization wisely) - Private variables are unique to each thread and do not affect each other.
OPENMP syntax
OPENMP syntax environment variables
| environment variables | describe |
|---|---|
| OMP_SCHEDULE | It can only be used for parallel for and for, which determines the scheduling method of each iteration in the loop. |
| OMP_NUM_THREADS | The maximum number of threads that can be used |
| OMP_DYNAMIC | Boolean type that determines whether to allow dynamically setting the number of threads in a parallel domain |
| OMP_NESTED | Boolean type that determines whether nested parallelism is allowed |
OPENMP syntax runtime library functions
| function | describe |
|---|---|
| omp_get_num_procs | Returns the number of processors in the multiprocessor running the current thread |
| omp_get_num_threads | Returns the number of active threads in the current parallel region |
| omp_get_thread_num | Returns the thread number of the current thread |
| omp_set_num_threads | Set the number of threads to execute code in parallel |
| omp_init_lock | Initialize a simple lock |
| omp_set_lock | lock operation |
| omp_unset_lock | The unlocking operation needs to be paired with the omp_set_lock function. |
| omp_destroy_lock omp_init_lock | Function pairing operation function, closing a lock |
OPENMP syntax compilation guidance
Compilation guidance is an extension of the programming language. OpenMP achieves parallelization by adding guidance statements to serial programs

| guidance command | describe |
|---|---|
| parallel | Used before a code segment to indicate that this code will be executed in parallel by multiple threads |
| for | Before using it in a for loop, allocate the loop to multiple threads for parallel execution. It must be ensured that there is no correlation between each loop. |
| sections | Used before code segments that may be executed in parallel |
| single | Used before a section of code that is only executed by a single thread, indicating that the following section of code will be executed by a single thread. |
| critical | Used before a critical section of code |
| barrier | Used for thread synchronization of code in the parallel zone. When all threads reach the barrier, they must stop until all threads have reached the barrier. |
| atomic | Used to specify a memory area to be updated atomically |
| master | Used to specify a block of code to be executed by the main thread |
| ordered | Loops used to specify parallel regions are executed sequentially |
| threadprivate | Used to specify that a variable is thread private |
parallel domain structure

Parallel domain structure: REDUCTION clause

Task division structure
is used to indicate how tasks are distributed among multiple threads. The task division structure divides the code it contains
into threads performed by each member of the group. It does not spawn new threads, there is no roadblock at the
entry point of the task division structure, but there is an implicit roadblock at its end. A shared task structure
must be dynamically encapsulated in a parallel domain so that directed statements can be executed in parallel.
• Parallel DO/for loop guidance for data parallelism
• Parallel SECTIONS guidance for functional parallelism
• SINGLE Guidance, for serial execution
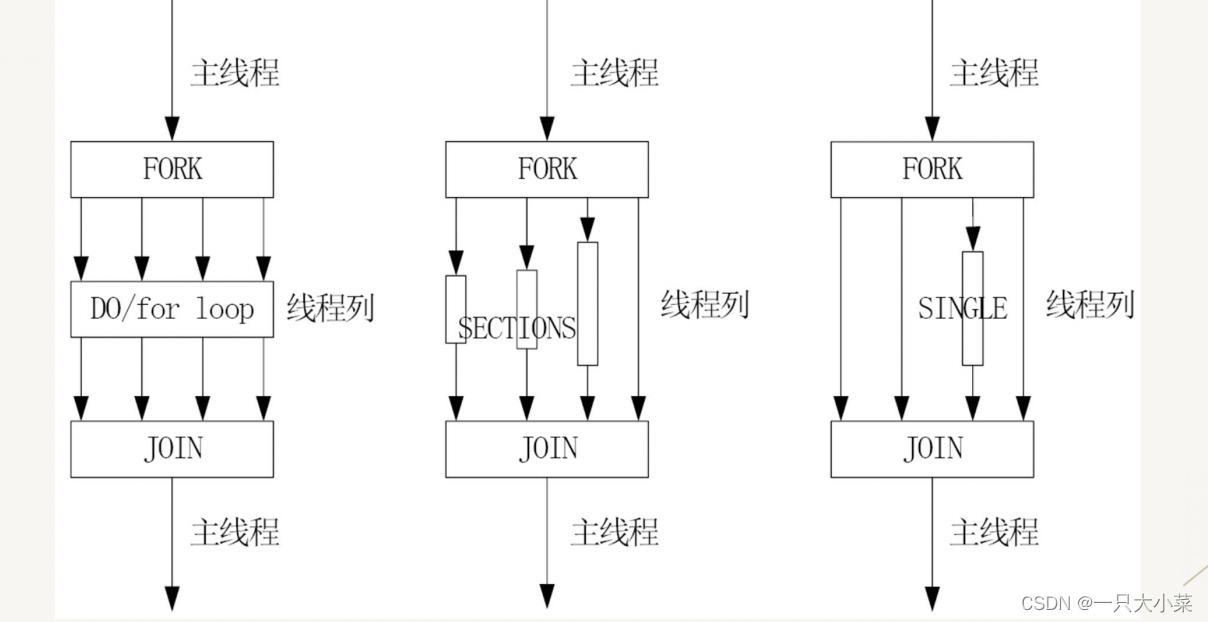
DO/FOR loop guidance
is used to divide the loop into multiple blocks and assign them to each thread for parallel execution, in the C
language The for loop guidance is used
#pragma omp for [clauses]
for loop
• DO/for loop can have Clauses such as PRIVATE and FIRSTPRIVARE
• Loop variables are private
Scheduling clause SCHEDULE
Controls the task scheduling method (blocking method) of for loop parallelization
• schedule(kind[, chunksize])
• kind: static, dynamic, guided, runtime
• chunksize is an integer expression
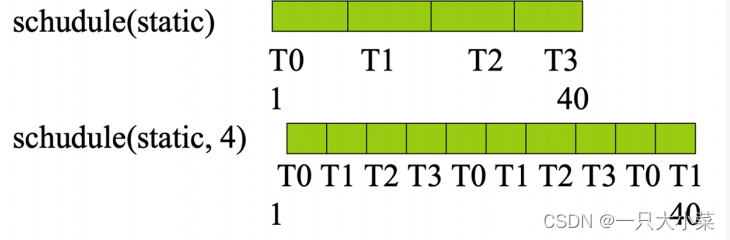
SCHEDULE (STATIC [, CHUNKSIZE])
•Omit chunksize, the iteration space is divided into (approximately) equally sized regions, and each
thread is allocated a region;
• If The chunksize is specified, the iteration space is divided into chunksize sizes, and then
is allocated to each thread in turn
SCHEDULE(DYNAMIC [,CHUNKSIZE])
• Divide the iteration space into chunksize-sized intervals, and then allocate them to each thread on a first-come, first-served basis;
• When chunksize is omitted, its default value is 1.
SCHEDULE(GUIDED[,CHUNKSIZE])
• Similar to DYNAMIC scheduling, but the interval is large at first, and then the iteration interval becomes smaller and smaller
• chunksize specifies the minimum interval size. When chunksize is omitted,
its default value is 1
SCHEDULE(RUNTIME)
• Scheduling selection is delayed until runtime, scheduling The method depends on the value of the environment variable
OMP_SCHEDULE, for example:
export OMP_SCHEDULE="DYNAMIC, 4"
• When using RUNTIME , indicating that chunksize is illegal;


SECTIONS guidance

SINGLE guidance
The structure code is executed by only one thread; and is executed by the thread that first executes the code; other threads wait Until the structure block is executed.

Synchronization structure
| Synchronization structure | describe |
|---|---|
| master | The specified code segment will only be executed by the main thread, and other threads will ignore the code segment |
| critical | The specified code segment is a thread mutually exclusive critical section, which can only be executed by one thread at the same time. |
| barrier | Used to synchronize all threads in a thread group. The thread that reaches the statement is blocked first. |
| atomic | Specifies that a specific memory location is updated atomically |
| flush | Used to identify a synchronization point to ensure that all threads see a consistent view of memory |
| ordered | Specifies that the loops contained in the code are executed in a serial manner, and only one thread can execute at any time. |
| threadprivate | Make a global file scope variable private to each thread in the parallel domain, and each thread makes a private copy of the variable. |
CRITICAL guidance
- The code area (critical section) specified by the critical instruction can only be executed by one thread at a time.
- If a thread is currently executing within a critical region and another thread reaches that region and attempts to execute it, it will block until the first thread exits the region.

• If a name is specified for a critical section, the name acts as a critical region global identifier, and different critical regions with the same name are considered the same region
• All unnamed critical regions are considered the same region
BARRIER guidance
• The barrier instruction synchronizes all threads. When any thread in the group reaches the barrier instruction, it will wait at that point until all other threads have reached the barrier. Then all threads continue to execute subsequent code in parallel
• After guidance such as DO/FOR, SECTIONS and SINGLE, there is an implicit barrier
ATOMIC guidance
• ATOMIC compilation guidance indicates that a special storage unit can only be updated atomically and does not allow multiple threads to write at the same time. It is generally used for shared variables. Operation
• Provides a minimum critical section (critical), which is more efficient than the critical section
FLUSH guidance
• flush The instruction identifies a synchronization point at which the variables in the list are written back to the memory instead of being temporarily stored in the register to ensure the latest value of the shared variable read by the thread, thus ensuring the consistency of multi-threaded data.
#pragma omp flush
The following instructions imply flush operations:
• barrier, parallel, critical, ordered
• for, sections, single
• atomic modified statements
ORDERED guidance
• In a parallelized for loop, specify that a part of the code should be executed in the loop iteration order
• Can only be used with In the for or parallel for structure of the ordered clause, the ordered guide can only appear once in a loop