This chapter continues to learn how to implement data parallelism. This article mainly introduces the task parallelism and custom partitioning strategies.
This tutorial corresponds to Learning Engineering: Magician Dix / HandsOnParallelProgramming · GitCode
2. Task parallelism
Data-parallel design takes advantage of running loops in parallel on multiple cores in the system, making efficient use of available CPU resources. We can use another important concept to control how many tasks are created in the loop: the Degree of Parallelism (Degress of Parallelism).
Degree of Parallelism (Degress of Parallelism)
Integer specifying the maximum number of tasks that a parallel loop can create. The default value is 64.
Here is an example to demonstrate:
private void RunByMaxDegreedOfParallelism()
{
int length = 10;
var L = TestFunction.GetTestList(length);
var options = new ParallelOptions { MaxDegreeOfParallelism = 2 };
var result = Parallel.For(0, length, options, (i, state) =>
{
Debug.Log($"Log [{i}] => {L[i]} : In Task : {Task.CurrentId}");
});
Debug.Log($"ParallelFor Result : {result.IsCompleted} | {result.LowestBreakIteration}");
}When we set the maximum parallelism to 2, the printed results are as follows:
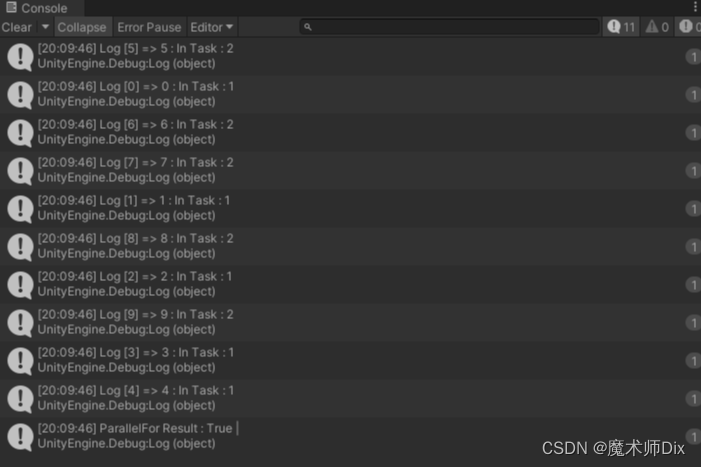
It can be seen that it is divided into 2 tasks and executed very regularly: Task 1 prints 0 ~ 4, and Task 2 prints 5 ~ 9. The same task is executed sequentially, and it is obvious that it is divided into two tasks. If the maximum parallelism is set to 1, the result is as follows:
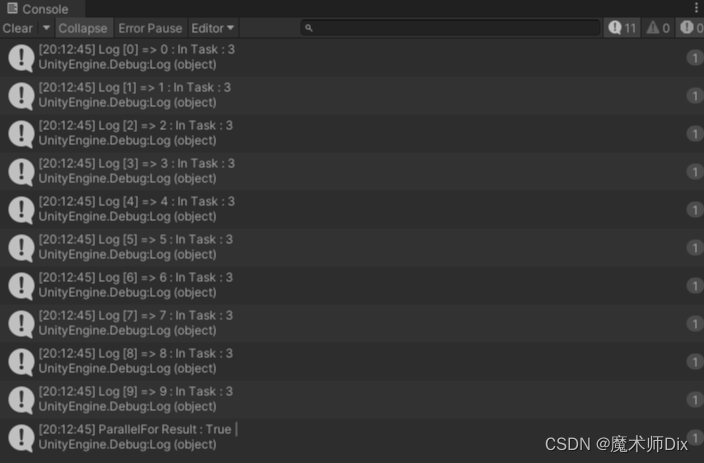
It can be seen that it is executed sequentially in a Task.
For some advanced application scenarios, the running algorithm cannot span a certain number of processors, and it is necessary to limit each algorithm to only use a certain number of processors, so this setting should be modified.
3. Create a custom partition strategy in a parallel loop
Partitioning is another important concept in data parallelism. To achieve parallelism in a source collection, it needs to be divided into smaller parts, called Ranges or Chunks, which can be accessed simultaneously by different threads. Without partitioning, the loop will execute serially.
Partitioners can be divided into the following two categories (it is also possible to create custom partitioners):
-
range partition
-
block partition
3.1, range partition
-
It is mainly suitable for collections whose length is known in advance.
-
Each thread has a start and end index of a range of elements or source collection to process.
-
There is some performance penalty when creating ranges, but there is no synchronization overhead.
3.2, block partition
When using block partitioning, each thread picks up a block of elements, processes it, and returns to pick up another element that hasn't been picked up by another thread.
-
It is mainly used for collections such as linked lists (LinkedList), whose length is unknown in advance.
-
Provides better load balancing capabilities in case the collection is not balanced.
-
The block size depends on the partitioner implementation, and there is a synchronization overhead (need to ensure that blocks allocated to two threads do not contain duplicates).
/// <summary>
/// 使用块分区进行并行
/// </summary>
private void RunByChunkPartitioning()
{
int length = 10;
OrderablePartitioner<Tuple<int, int>> orderablePartitioner = Partitioner.Create(0, length);
var result = Parallel.ForEach(orderablePartitioner, (range, state) =>
{
var startIndex = range.Item1;
var endIndex = range.Item2;
Debug.Log($"{Task.CurrentId} 分区:{startIndex} ~ {endIndex}");
});
Debug.Log($"Parallel.ForEach Result : {result.IsCompleted} | {result.LowestBreakIteration}");
}
The partition results are as follows:
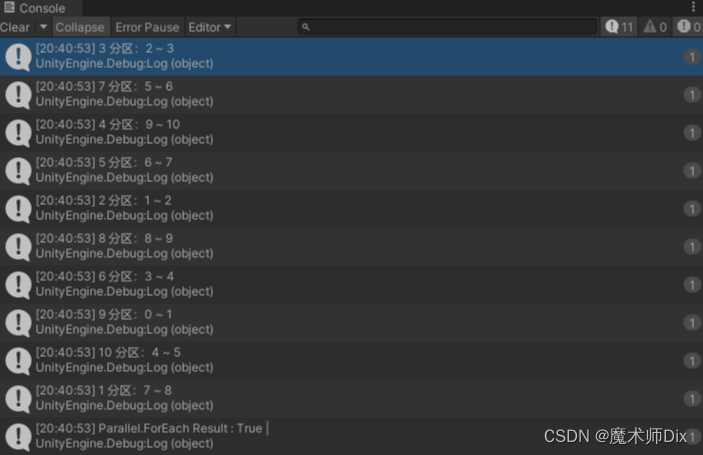
For the introduction of Partitioner.Create, refer to the following document, which will automatically create a partitioner and pass in the lower limit and upper limit of the partition.
(to be continued)
This tutorial corresponds to Learning Engineering: Magician Dix / HandsOnParallelProgramming · GitCode