Table of contents
Examine the internal structure of the model
3.1 Set loss function and optimizer
Edit 3.2 Build a training loop
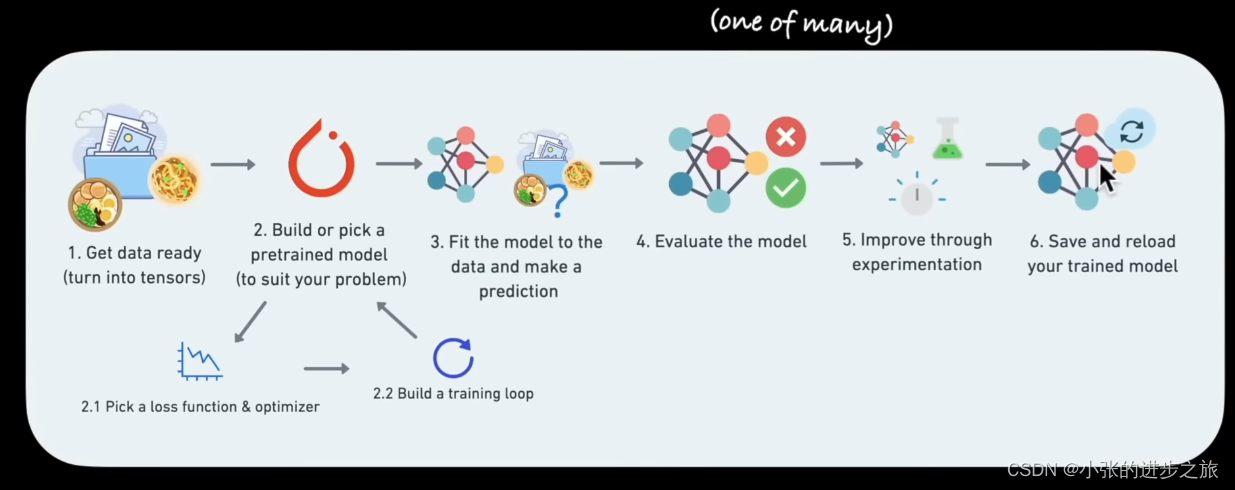
Overall flow chart
 The neural networks in PyTorch are all in torch.nn: torch.nn — PyTorch 2.0 documentation
The neural networks in PyTorch are all in torch.nn: torch.nn — PyTorch 2.0 documentation
The various neural networks inside are built by professional software engineers.
If you have any questions during use, you can actually discuss it with others in the PyTorch Github forum.
#import the package
import torch
from torch import nn
import matplotlib.pyplot as plt
# Data (preparing and loading)
#1.1 Create a train/test split 1.1 对数据进行分割
train_split=int(0.8*len(X))
X_train, y_train=X[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
#1.2 Visualize data 1.2 把数据可视化
def plot_predictions(train_data=X_train, train_labels=y_train,
test_data=X_test, text_labels = y_test,
predictions=None):
plt.figure(figsize=(10,7))
#plot trainning data in blue
plt.scatter(train_data, train_labels, c="b", s=4, label="Training data")
#plot test data in green
plt.scatter(test_data, test_labels, c="g", s=4, label="Testing data")
#if predictions is not None:
#plot the predictions if they exist
plt.scatter(text_data, predictions, c="b", label="Predictions")1. Data acquisition
Data format
Data can be in any form: Excel spreadsheet; images, videos, audio, DNA, text
Data classification:
1) Training set is used to build the model
2) Validation data (Validation set)
3) Test data (test set)
Generally, the proportions of the above data are as shown in the figure:

2. Build the model
When building a model, you must use classes to build the model. If you have no foundation, it is best to learn some OOP-related knowledge on the following website:
Object-Oriented Programming (OOP) in Python 3 – Real Python
I feel that it is also introduced in great detail in this blog post:python - Detailed explanation of the usage of class classes and methods_python class_Irving.Gao's blog-CSDN blog
# Build model
from torch import nn
# 2.1 Creat linear regression model class
class LinearRegressionModel(nn.Module): #nn.module是PyTorch中基础的modules
def_init_(self):
super()._init_()
self.weights = nn.Parameter(torch.randn(1, requires_grad=True,
dtype=torch.float))
self.bias = nn.Parameter(torch.randn(1, requires_grad=True,
dtype=torch.float))
#Forward method to define the computation in the model
def forward(self,x:torch.Tensor)->torch.Tensor:
return self.weight*x+self.bias
Ideas for building a model:
First generate random values (including weight and bias in regression), and then continuously adjust them to get the most appropriate values to build the model. The adjustment algorithm mainly includes the following:
1. Gradient descent 2. Feedback (backpropagation)

Some keys to building models
For model construction:
- torch.nn: contains all of the buildings for computional graphs (a neural network can be considered a computational graph)
- torch.nn.Parameter; what parameters should our model try and learn, often a Pytorch layer from torch.nn will set these for us
- torch.nn.Module: The base class for all neural network modules, if you subclass it, you should overwrite forward()
For model optimization
- torch.optim: this where the optimizers in PyTorch live, they will help with gradient descent
other
- def forward(): all nn.Module subclasses require you to overwrite foward(), this method defines what happens in the forward computation
Examine the internal structure of the model
After building the model, let’s take a look at the internal structure of the model.
Generally use .parameters() to see
# create a random seed
torch.manual_seed(42)
# create an instance of the model (this is a subclass of nn.Module)
model_0 = LinerRegressionModel()
#Check out the parameters
list(model_0.parameters())The results are as follows:

If you want to use a dictionary to view it:
model_0.state_dict() The results obtained are as follows: 
Check model accuracy
Prediction, bring the test set data into the model to see the prediction effect, torch.inference_mode( ) and < a i=3>torch.no_grad( ) Both methods are commonly used, but torch.inference_mode( ) is more commonly used.
#Make predictions with model
with torch.inference_mode():
y_preds = model_0 (X_test) #使用测试集的X来预测Y
#也有另外一个公式可以用于预测
with torch.no_grad():
y_preds = model_0(X_test)3. Training model
The process of training the model is actually to improve the accuracy of the original random parameters, and then make the model more predictive.
Some basic concepts:
- Loss function is used to measure the inaccuracy of your model. Generally, the lower the value, the better.
There are many types of loss functions, for example, nn.L1loss, nn.MSELoss, nn.CrossEntropyLoss, nn.CTCLoss
- Optimizer: Takes into account the loss of a model and adjust the model's parameters
So when training, we need a training set and a test set for training
3.1 Set loss function and optimizer
# Setup a loss function
loss_fn = nn.L1Loss()
# Setup an optimizer (stochastic gradient descent)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
The learning rate is a very important parameter in the optimizer. It is generally obtained based on experience. The larger the value, the greater the change each time. The smaller the value, the smaller the change each time.
So when building a model, how should we choose the loss function and optimizer? The specific choice should be based on the actual problem. For example, for regression problems, you can use nn.L1Loss() or torch.optim.SGD(). It is enough, but for classification, nn.BCELoss() may be better.
For example, the loss function L1Loss is calculated based on MAE.
 3.2 Build a training loop
3.2 Build a training loop
Some matters in building the training loop process
- Loop through the data Loop through the data
- Forward pass (this involves data moving through our model's forward() function) -- also known as forward pass (this involves data moving through our model's 'forward()' function)-also called forward propagation
- Calculate the loss (compare forward pass predictions to ground true labels) Calculate the loss (compare forward pass predictions to ground true labels)
- Optimizer zero grad Optimizer zero grad
- Loss backwards through the network to calculate the gradients of each of the parameters of our model with respect to the loss
- Optimizer step - use the optimizer to adjust our model's parameters to try and improve the loss Optimizer step - use the optimizer to adjust our model's parameters to try and improve the loss
# An epoch is one loop through the data (this is a hyperparameter because we've set it
epochs=100 #根据实际情况来确定数值
### Trainning
# 1. Loop through the data
for epoch in range(epochs):
model_0.train( ) # train the model in PyTorch set all paragrameters that require gradients to require gradients
# 2. Forward pass
y_pred = model_0(X_train)
# 3. calculate the loss
loss = loss_fn(y_pred, y_train)
# 4. Optimizer zero grad
loss.backward()
# 5. Perform backprogation on the loss with respect to the parameters of the model
loss.backward()
# 6. Step the optimizer (perform gradient descent)
optimizer.step() 3.3 Build a Test Loop
### Testing
model_0.eval( ) # turn off different settings in the model not needed for evaluation/testing(dropout/batch norm layer)
with torch.inference_mode(): #turns off gradient tracking & a couple more things behind the scenes 有了这一步所以所以在测试的时候不做任何的学习
#with torch.no_grad(): # 在旧的版本可能是torch.no_grad()
#1. Do the forward pass
test_pred= model_0 (X_test)
#2. Calculate the loss
test_loss = loss_fn (test_pred, y_test)
# print out what's "happening"
if epoch%10 == 0: 每10次进行一次的Loss的确认
print (f"Epoch: {epoch}|Loss: {loss}| Test loss: {test_loss}")
#Print out model state_dict( )
print(model_0.state_dict()) 4. Save the model
There are three main methods for saving models:
- “torch.save( )" allows you save a PyTorch object in Python's pickle format
- "torch.load( )" allows you load a saved PyTorch object
- "torch.nn. Module.load_state_dict( )', allows to load a model's saved state dictionary, that is, the main parameters of the model are saved.
# Saving our PyTorch model
from pathlib import Path
#1. Create models directory
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exit_ok=True)
#2. Create model save path
MODEL_NAME = "01_pytorch_workflow_model_0.pth"
MODEL_SAVE_PATH = MODEL_PATH/MODEL_NAME
#3. Save the model state dict
print(f"Saving model to:{MODEL_SAVE_PATH}")
torch.save (obj=model_0.state_dict(), f=MODEL_SAVE_PATH).pth is a common file type for PyTorch to save models
5 Load model
If you use state_dict() to save the model, because the parameters are saved when saving the model, the parameters are also loaded when loading.
#To load in a saved state_dict we have to instantiate a new instance of our model class
loaded_model_0 = LinearRegressionModel( )
# Load the saved state_dict of model_0 (this will update the new instance with updated parameters)把参数带入模型中
load_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
Referenece Video: https://www.youtube.com/watch?v=Z_ikDlimN6A&t=6412s