If you want to get started with pytorch reinforcement learning, go find a pytorch course. The most played course on site B is Xiaotudu's course . Overall, I feel that the content is very detailed, but it is different from my expectations. This is a DL course, not an RL course, but it is also an early understanding of the use of pytorch. Very good, this blog will summarize the entire learning process.
Note: The data sets used in this note are all CIFAR10, and downloading is relatively simple~, starting below
Data reading
Before reading, you need to prepare the data. For CIFAR10, you can download it offline (URL: https://download.pytorch.org/tutorial/hymenoptera_data.zip ). After downloading, save it to the dataset folder. The directory structure is as follows:
The following is the reading of images. The initial reading is through PIL, and will be replaced by dataloader later. The main thing is to define a class and pass two parameters. The example is as follows:
read_data.py
# function:使用PIL完成数据的读取,可查看
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
img.show()
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
ants_datasets = MyData(root_dir, ants_label_dir)
ants_datasets.__getitem__(0) # 输入查看图片编号即可
print(len(ants_datasets))
tensorboard use
Tensorboard is a visualization tool that can be used to view pictures or analyze data.
Let’s talk about the installation first. Two errors were reported during the installation:
报错:ModuleNotFoundError: No module named 'tensorboard'
解决:pip install tensorboard -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
报错:ModuleNotFoundError: No module named 'six'
解决:pip install six -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
Instructions:
1. Write the framework according to the main template:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") # 这个logs是生成日志文件的文件夹名,可随意更换
writer.add_image() # 添加一张图像,第一个参数是tag,第二个是数据本身,第三个是编号
wirter.add_images() # 添加多张图像,第一个是tag,第二个是数据本身,第三个是编号
writer.add_scalar() # 添加数值 第一个参数是tag, 再后是先y后x, 例如:writer.add_scalar("y=2x", 2*i, i)
writer.add_graph(tudui, input) # 查看网络结构,tudui是模型,input是模型输入
writer.close()
After executing the code, the event file will be generated in the logs folder:
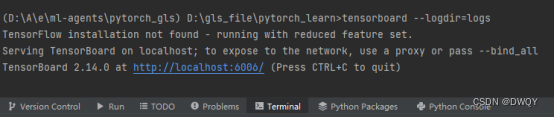
2. Use tensorboard --logdir=logs in the terminal:
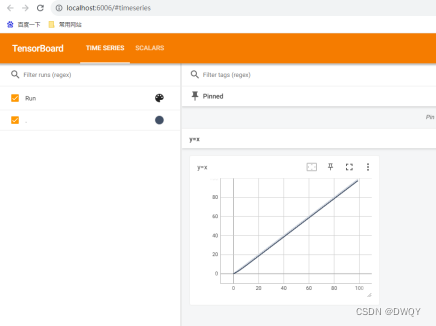
3. Click on the localhost link to view:
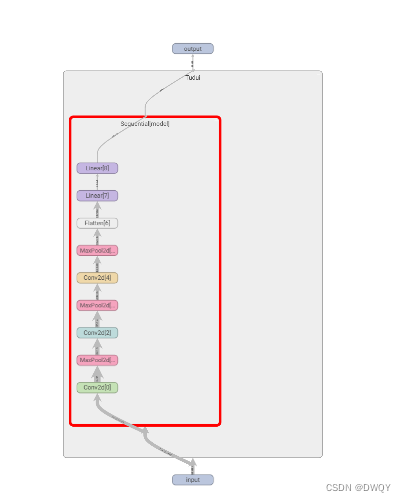
You can also look at the network structure:
test_tb.py
# function:展示tensorboard的使用
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
# add_image使用
image_path = "dataset/train/ants/5650366_e22b7e1065.jpg"
image_path1 = "dataset/train/ants/6240329_72c01e663e.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
img_PIL1 = Image.open(image_path1)
img_array1 = np.array(img_PIL1)
writer.add_image("image", img_array, 1, dataformats='HWC') # 这个通道顺序需要改,tensorboard默认使用的是tensor结构,但这个读的是PIL结构
writer.add_image("image", img_array1, 2, dataformats='HWC')
# add_scalar使用
# for i in range(100):
# writer.add_scalar("y=2x", 2*i, i)
writer.close()
transforms use
Transforms are used to convert data types. Most of the data formats used in pytorch are Tensor. Transfroms directly provides tools.
transforms_learn.py
# function:展示transforms的基本使用格式
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import numpy as np
writer = SummaryWriter("logs")
# python用法 → tensor数据类型
# 通过transform.ToTensor看两个问题
# 1. transform如何使用
# 2. 为什么需要Tensor
image_path = "dataset/train/ants/522163566_fec115ca66.jpg"
# PIL → Tensor()
img = Image.open(image_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("image", tensor_img, 1)
writer.close()
useful_transforms.py
There are several common transforms. You can remember how to use them: ToTensor (convert to Tensor type), Normalize (regularize), Resize (adjust data shape), Compose (integrate multiple transfroms together), RandomCrop (random cropping) data), use it as follows:
# function:展示部分常见transfroms,包括:ToTensor(转换为Tensor类型),Normalize(做正则化),Resize(调整数据shape),Compose(将多个transfroms整合在一起),RandomCrop(随机裁剪数据)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/5650366_e22b7e1065.jpg")
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
# Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
# Resize
# 输入序列(512, 512)或者数值(512, 会生成方阵)
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize)
# Compose
# PIL → PIL → tensor
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
# RandomCrop——随机裁剪
trans_ramdom = transforms.RandomCrop(128)
trans_compose_2 = transforms.Compose([trans_ramdom, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.add_image("ToTensor", img_tensor, 1)
writer.add_image("Norm", img_norm, 2)
writer.add_image("Resize", img_resize, 3)
writer.add_image("Compose", img_resize_2, 4)
writer.close()
dataset_transforms.py
This mainly starts using dataLoader for data extraction. Because the image data is directly of PIL type, transformations must be performed during the dataloader. Datasets come from torchversion:
torchversion: You can download the default dataset
torchvision: dataset. Download the dataset
torchvision: dataloader. Select specific data to download
and use as follows:
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
# # ====torchvision.datasets使用====
# dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
# train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
# test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
#
# writer = SummaryWriter("dataset_transformer")
# for i in range(10):
# img, target = train_set[i]
# writer.add_image("test_set", img, i)
# writer.close()
# # ====torchvision.DataLoader使用====
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()]))
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
img, target = test_data[0]
print(img.shape)
print(target)
step = 0
writer = SummaryWriter("dataloader")
for data in test_loader:
imgs, targets = data
writer.add_images("dataloader", imgs, step) # 注意:批量添加的时候使用add_images函数
step = step + 1
writer.close()
torch.nn uses
torch.nn is the relevant operation support provided by pytorch for neural network (neural network). There are many specific things, and only some commonly used ones are explained.
conv2d
For the implementation of convolution operation (specifically, what is convolution, the video explains it in detail), I will leave a template here:
nn_conv2d.py
# torch.nn 的卷积conv2d 实例
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataLoader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
step = 0
writter = SummaryWriter("logs_conv2d")
for data in dataLoader:
imgs, targets = data
output = tudui(imgs)
writter.add_images("input", imgs, step)
output = torch.reshape(output, [-1, 3, 30, 30])
writter.add_images("output", output, step)
step = step + 1
Basic use of nn.module
The Tudui class above inherits nn.module. In fact, this is the parent class of the neural network in pytorch as a whole. Just inherit it when using it, leaving a simple template:
nn_module.py
# function:nn.module的基本使用
import torch
from torch import nn
class Tudui(nn.Module):
# 注意父类写的格式
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
maxpool.py
The difference between maximum pooling and convolution
is that convolution uses a convolution kernel to perform calculations, and dimension-invariant
convolution uses a convolution kernel to calculate the maximum value. Dimension-invariant
maximum pooling is implemented:
# function:torch.nn 最大池化maxpool示例
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", download=True, train=False, transform=torchvision.transforms.ToTensor())
dataLoader = DataLoader(dataset, batch_size=64)
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 5, 1, 1],
[2, 1, 0, 1, 2]
], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# ceil_mode为True,保留边框部分(多)
# ceil_mode为False,不保留边框部分(少)
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool(input)
return output
writer = SummaryWriter("log_maxpool")
tudui = Tudui()
output = tudui(input)
step = 0
for data in dataLoader:
imgs, targets = data
writer.add_images("intput", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
linear.py
Implementation of linearization:
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", download=True, train=False, transform=torchvision.transforms.ToTensor())
dataLoader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.Linear = Linear(196608, 10)
def forward(self, input):
output = self.Linear(input)
return output
tudui = Tudui()
for data in dataLoader:
imgs, targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = tudui(output)
print(output.shape)
loss
Loss is a loss function. Pytorch provides several that can be used directly. I will give an example here:
nn_loss.py
# function:损失函数使用示例
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# L1直接损失
loss = L1Loss()
result = loss(inputs, targets)
# 均方差损失
loss_mse = nn.MSELoss()
result_mes = loss_mse(inputs, targets)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result)
print(result_mes)
print(result_cross)
optimal
There is a template for the use of the optimizer:
optim.zero_grad() # 1.设置梯度为0
result_loss.backward() # 2.计算梯度,进行反向传播
optim.step() # 3.进行梯度更新,调整权重参数(降低loss)
Examples are as follows:
nn_optimal.py
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, Linear, Sequential
from torch.nn import MaxPool2d
from torch.nn import Flatten
from torch.utils.data import DataLoader, dataloader
from nn_loss import loss
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
x = self.model(input)
return x
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataLoader = DataLoader(dataset, batch_size=1)
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataLoader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 1.设置梯度为0
result_loss.backward() # 2.计算梯度,进行反向传播
optim.step() # 3.进行梯度更新,调整权重参数(降低loss)
running_loss = running_loss + result_loss
print(running_loss)
relu.py
Introduce nonlinearity (linearity is not good), examples are as follows:
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, 0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input)
dataset = torchvision.datasets.CIFAR10("./dataset", download=True, train=False, transform=torchvision.transforms.ToTensor())
dataLoader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu = ReLU()
def forward(self, input):
output = self.relu(input)
return output
writer = SummaryWriter("logs_relu")
tudui = Tudui()
output = tudui(input)
step = 0
for data in dataLoader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
print(output)
sequential.py
To write a model in the traditional way, you need to write the structure layer by layer in forward. Sequential can be defined directly in the model. The example is as follows:
## 传统方式:自己写模型
# import torch
# from torch import nn
# from torch.nn import Conv2d, Linear, Sequential
# from torch.nn import MaxPool2d
# from torch.nn import Flatten
#
# class Tudui(nn.Module):
# def __init__(self):
# super(Tudui, self).__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
#
# def forward(self, input):
# x = self.conv1(input)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
# return x
#
# tudui = Tudui()
# input = torch.ones((64, 3, 32, 32))
# output = tudui(input)
# print(output.shape)
## 使用Sequential写模型
import torch
from torch import nn
from torch.nn import Conv2d, Linear, Sequential
from torch.nn import MaxPool2d
from torch.nn import Flatten
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
x = self.model(input)
return x
writer = SummaryWriter("logs_sequential")
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
writer.add_graph(tudui, input)
writer.close()
print(output.shape)
Overall model training
train_cpu.py
Examples are as follows:
import torchvision
from torch.utils.data import DataLoader
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, download=True, transform=torchvision.transforms.ToTensor())
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集长度为:{}".format(train_data_size))
print("测试数据集长度为:{}".format(test_data_size))
# 利用dataloader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10))
def forward(self, input):
x = self.model(input)
return x
### 测试模型正确性
# if __name__ == '__main__':
# tudui = Tudui()
# input = torch.ones((64, 3, 32, 32))
# output = tudui(input)
# print(output.shape)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
# 训练轮数
epoch = 10
# 添加tensorboard
writter = SummaryWriter("logs_train")
total_test_step = 0
for i in range(10):
print("-----第{}轮训练开始----".format(i+1))
# 训练步骤开始
tudui.train() #特定层:Dropout
for data in train_dataloader:
# 1. 数据导入
imgs, targets = data
# 2. 模型导入
outputs = tudui(imgs)
# 3. loss计算
loss = loss_fn(outputs, targets)
# 4. 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step, loss.item())) #loss.item()相当于取值
writter.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writter.add_scalar("test_loss", loss.item(), total_test_step)
writter.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存训练模型
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存!")
writter.close()
train_gpu.py
Examples are as follows:
# 与CPU的区别:在网络模型、数据、损失函数上增加cuda()
import torchvision
from torch.utils.data import DataLoader
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, download=True, transform=torchvision.transforms.ToTensor())
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集长度为:{}".format(train_data_size))
print("测试数据集长度为:{}".format(test_data_size))
# 利用dataloader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10))
def forward(self, input):
x = self.model(input)
return x
### 测试模型正确性
# if __name__ == '__main__':
# tudui = Tudui()
# input = torch.ones((64, 3, 32, 32))
# output = tudui(input)
# print(output.shape)
# 创建网络模型
tudui = Tudui()
tudui = Tudui().cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
# 训练轮数
epoch = 10
# 添加tensorboard
writter = SummaryWriter("logs_train")
total_test_step = 0
for i in range(10):
print("-----第{}轮训练开始----".format(i+1))
# 训练步骤开始
tudui.train() #特定层:Dropout
for data in train_dataloader:
# 1. 数据导入
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
# 2. 模型导入
outputs = tudui(imgs)
# 3. loss计算
loss = loss_fn(outputs, targets)
# 4. 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step, loss.item())) #loss.item()相当于取值
writter.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writter.add_scalar("test_loss", loss.item(), total_test_step)
writter.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存训练模型
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存!")
writter.close()
Model save
model_save.py
Examples are as follows:
# function:训练模型的保存
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
Model loading
model_loader
Examples are as follows:
# function:现有模型加载
import torch
import torchvision
model = torch.load("vgg16_method1.pth")
print(model)
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model = torch.load("vgg16_method2.pth") # 直接是字典权重
print(model)
Model usage
model_use.py
Examples are as follows:
# function:自找图片,验证train.py训练的模型准确性
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "dog.png"
image = Image.open(image_path)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
image = transform(image)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10))
def forward(self, input):
x = self.model(input)
return x
model = torch.load("tudui_9.pth")
image = torch.reshape(image, (1, 3, 32, 32))
image = image.cuda()
model.eval()
with torch.no_grad():
output = model(image)
print(output.argmax(1))
Pre-model usage
premodel_use.py
Examples are as follows:
# function:使用现有网络对现有数据集进行训练
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, download=True, transform=torchvision.transforms.ToTensor())
# CIFAR10最终的输出结果是10类,所以必须按照原来的增加一层
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
# CIFAR10最终的输出结果是10类,也可以在原来基础上做改动
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
The above is a brief understanding of the basics of pytorch. The learning is still going on, keep up the good work~