Spring: It is a layeredJavaSE/EEfull-stack (one-stop)light Magnitude open source framework, the core is Inversion of Control (IoC) and Aspect Oriented (AOP) . For the three-layer structure of JavaEE, Spring provides different solution technologies for each layer:
- WEB layer: SpringMVC
- Business layer: Spring’s IoC
- Persistence layer: Spring's JDBCTemplate (Spring's JDBC template, ORM template is used to integrate other persistence layer frameworks)
AOP: Aspect-oriented programming lets focus code and Business code separation, AOP is not a technology, it is actually a programming idea. Main functions: logging, performance statistics, security control, transaction processing, exception handling, etc.
Key terms for AOP:
- Points of concern: Repeated code is called points of concern;
- Aspect: The class formed by the focus is called an aspect (class);
- Aspect-oriented programming: It refers to the repeated code extraction for many functions, and then dynamically implants "aspect class code" into the business method at runtime; < /span>
- Pointcut: Execute the target object method and dynamically implant the aspect code. You can use pointcut expressions to specify which methods of which classes are to be intercepted, and implant aspect class code into the specified classes at runtime.
AOP underlying implementation: proxy mode. Agents are divided into:
- Static proxy: The source code of the proxy class is created by the programmer or the tool generates it, and then the proxy class is compiled. The so-called static means that the bytecode file of the proxy class already exists before the program is run, and the relationship between the proxy class and the delegate class is determined before running.
- jdk comes with a dynamic proxy: a proxy class is created based on the class loader and interface (this proxy class is the implementation class of the interface, Therefore, the interface must be used to generate a proxy for the interface, located under the java.lang.reflect package). The disadvantage must be interface-oriented, and the target business class must implement the interface.
- cglib dynamic proxy: Use the asm open source package to load the class file of the proxy object class and generate it by modifying its bytecode subclass to handle.
Usage of AOP programming (notes):
@Aspect 指定一个类为切面类
@Pointcut("execution(* com.ylw.service.UserService.add(..))") 指定切入点表达式
@Before("pointCut_()") 前置通知: 目标方法之前执行
@After("pointCut_()") 后置通知:目标方法之后执行(始终执行)
@AfterReturning("pointCut_()") 返回后通知: 执行方法结束前执行(异常不执行)
@AfterThrowing("pointCut_()") 异常通知: 出现异常时候执行
@Around("pointCut_()") 环绕通知: 环绕目标方法执行
Basic characteristics of transactions (ACID):
- Atomicity: Refers to the fact that all operations included in a transaction either succeed or fail and are rolled back. Therefore, if the operation of the transaction succeeds, it must be fully applied to the database. If the operation fails, It cannot have any impact on the database.
- Consistency: means that the transaction must change the database from one consistency state to another consistency state, that is to say, a transaction must be consistent before and after execution. state.
- Isolation: When multiple users access the database concurrently, such as when operating the same table, the transactions opened by the database for each user cannot be interfered by the operations of other transactions. , multiple concurrent transactions must be isolated from each other.
- Persistence: refers to that once a transaction is submitted, the changes to the data in the database are permanent, even if the database system encounters a failure. Operations that commit transactions are not lost.
Transaction control method:
- Programmatic: Fine-grained transaction control. You can add transaction control to specified methods and certain lines of specified methods. It is more flexible, but it is more cumbersome to develop. It needs to be opened, submitted and rolled back every time (
begin,commit,rollback) . - Declarative: Based on AOP, coarse-grained transaction control, transactions can only be applied to the entire method, and transactions cannot be applied to certain lines of the method, because AOP intercepts method.
Transaction propagation behavior: Transaction propagation behavior refers to the rules for how new transactions interact with existing transactions when one transaction method calls another transaction method. These propagation behaviors can be set through the ** attributes of the **@Transactional annotation. Spring defines seven transaction propagation behaviors, which are:propagation
- REQUIRED (default): If a transaction currently exists, join the transaction; if there is no current transaction, create a new transaction.
- SUPPORTS: If there is currently a transaction, join the transaction; if there is currently no transaction, execute in a non-transactional manner.
- MANDATORY: If there is currently a transaction, join the transaction; if there is currently no transaction, throw an exception.
- REQUIRES_NEW: Create a new transaction each time, and if a transaction currently exists, suspend the current transaction.
- NOT_SUPPORTED: Perform operations in a non-transactional manner. If a transaction currently exists, suspend the current transaction.
- NEVER: Execute in a non-transactional manner. If a transaction currently exists, an exception will be thrown.
- NESTED: If a transaction currently exists, it will be executed within the nested transaction; if there is currently no transaction, a new transaction will be created according to the rules of REQUIRED. Nested transactions are a relatively new feature that allows a new transaction to be nested within an existing transaction.
Notes: It will not and cannot affect the actual logic of the code, it only plays a supporting role.
Annotations are classified as follows:
- Built-in annotations (also called meta-annotations jdk's own annotations): For example,
@SuppressWarnings", "@Deprecated", "@Overricle": - Custom annotation (Spring framework):@Target explains the scope of objects modified by Annotation, @RetentionIndicates at what level the annotation information needs to be saved, used to describe the life cycle of the annotation, @Document Description Annotation should be used as a public API for annotated program members, so it can be documented by tools such as javadoc. @InheritedWhen using @Inherited The Retention of the Annotation of the type annotation is RetentionPolicy.RUNTIME, and the reflection API enhances this inheritance.
XML parsing method:
- Dom4j: Not suitable for parsing large files, because it loads the file into memory all at once, so memory overflow may occur. If you want to perform some flexible (crud) operations on xml files, use dom4j.
- SAX: parses xml based on events, so it can parse xml of large files
- Pull
Spring IOC: Refers to inversion of control. The IOC container is responsible for instantiating, locating, configuring objects in the application and establishing dependencies between these objects, leaving it to Spring. Manage these and achieve decoupling.
Spring IOC principle:XML技术+发射技术. ClassPathXmlApplicationContext uses reading to parse the xml class, and then uses reflection to initialize the object.
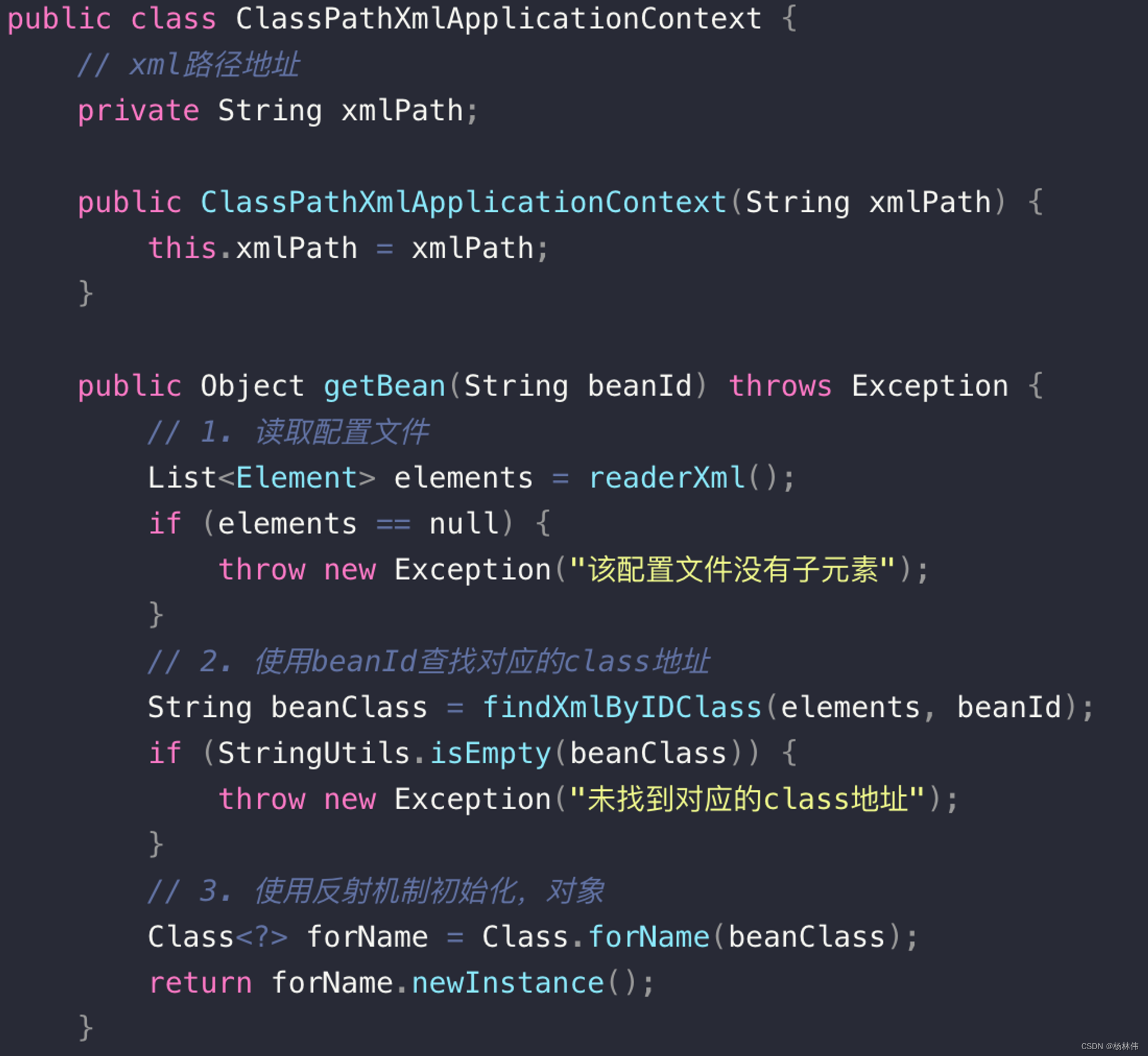
SpringMVC running process:
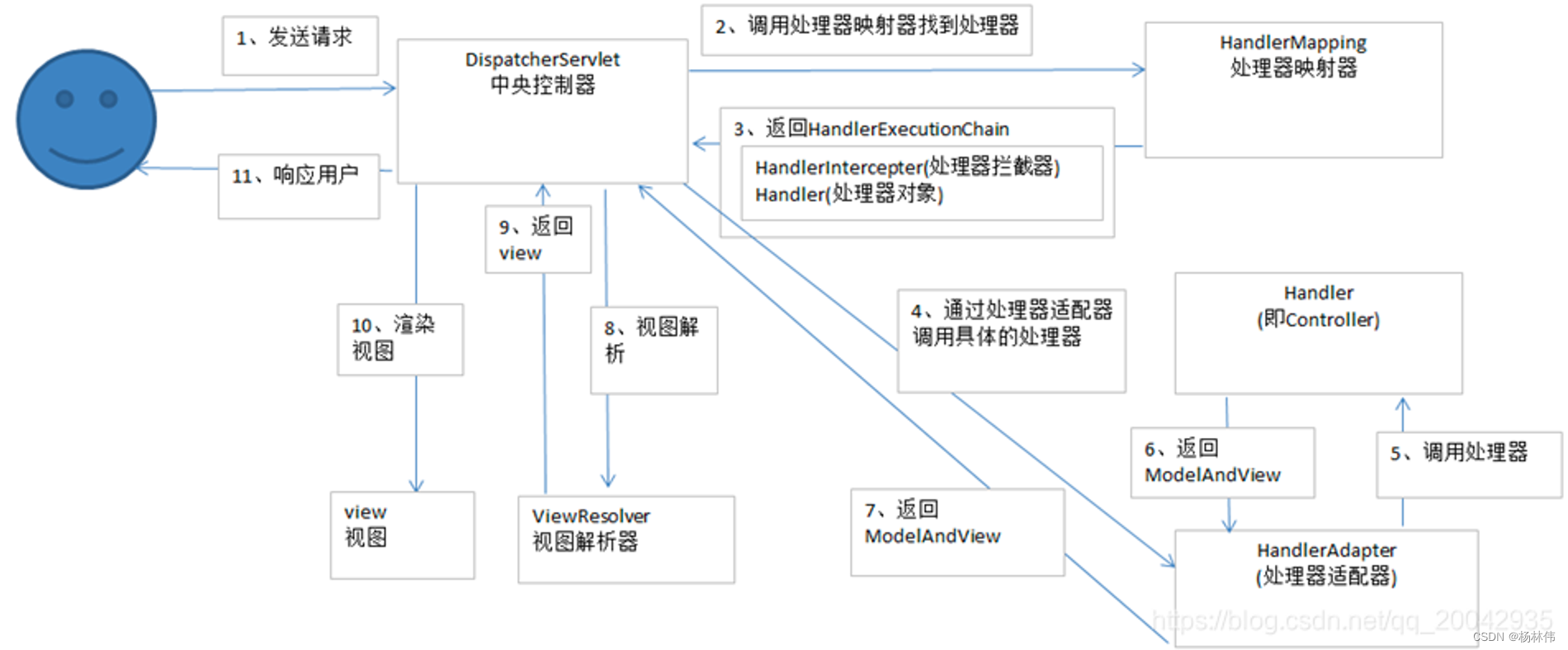
- The user sends a request to the front-end controller DispatcherServlet
- DispatcherServlet receives a request and calls the HandlerMapping processor mapper.
- The processor mapper finds the specific processor according to the request URL, generates the processor object and the processor interceptor (if any) and returns it to the DispatcherServlet.
- DispatcherServlet calls the handler through the HandlerAdapter processor adapter
- Execution processor (Controller, also called back-end controller).
- Controller completes execution and returns to ModelAndView
- HandlerAdapter returns the controller execution result ModelAndView to DispatcherServlet
- DispatcherServlet passes ModelAndView to ViewReslover view resolver
- ViewReslover returns the specific View after parsing
- DispatcherServlet renders the View (that is, fills the model data into the view).
- DispatcherServlet responds to the user.
Serverlet: A program that runs on a Web server or application server as a request from a Web browser or other HTTP client and a database or application on the HTTP server. the middle layer between.
ServerletLife cycle: Servlet loading->instantiation->service->destruction.
- init method: In the life cycle of the Servlet, the init method is only executed once.
- **Service method:** It is the core of Servlet and is responsible for responding to customer requests. Whenever a client requests an HttpServlet object, the object's Service() method is called, and a "request" (ServletRequest) object and a "response" (ServletResponse) object are passed to this method as parameters.
- destroy method: Executed only once, this method is executed when the server stops and the Servlet is uninstalled. When the Servlet object exits the life cycle, it is responsible for releasing the occupied resources.
The underlying principle of SpringMVC: Implemented based on XML technology + reflection + annotations + Servlet.
Initialization phase:
- Load configuration file
- Scan all classes under the user configuration package
- Get the scanned class and instantiate it through the reflection mechanism. And put it in the ioc container (Map key-value pair beanName-bean) beanName has the first letter lowercase by default.
- Initialize HandlerMapping. This is actually to map the url and method in a k-v Map and take them out during the running phase. mvcBeanUrl.put(requestBaseUrl + httpRequestUrl, mvcObject)
Running phase: Match the corresponding Method in HandlerMapping according to the url request, and then use reflectionThe mechanism calls the method corresponding to the url in the Controller and returns the result.

Database connection pool: The principle is to maintain a certain number of database connections in the internal object pool and expose the acquisition and return methods of the database connection to the outside world. The functions areresource reuse, faster system response, new resource allocation means, unified connection management, and avoid database connection leakage.
Database connection pool classification:
- DBCP: An older connection pool implementation. In some cases, performance may be lower, especially in high-concurrency environments;
- C3P0: Another old connection pool, compared to DBCP, C3P0 performs better in some aspects, but it may still perform poorly under extremely high loads;
- HikariCP: is a relatively new connection pool with excellent performance. It is designed to be lightweight and performant, often outperforming other connection pools in terms of throughput and response time.
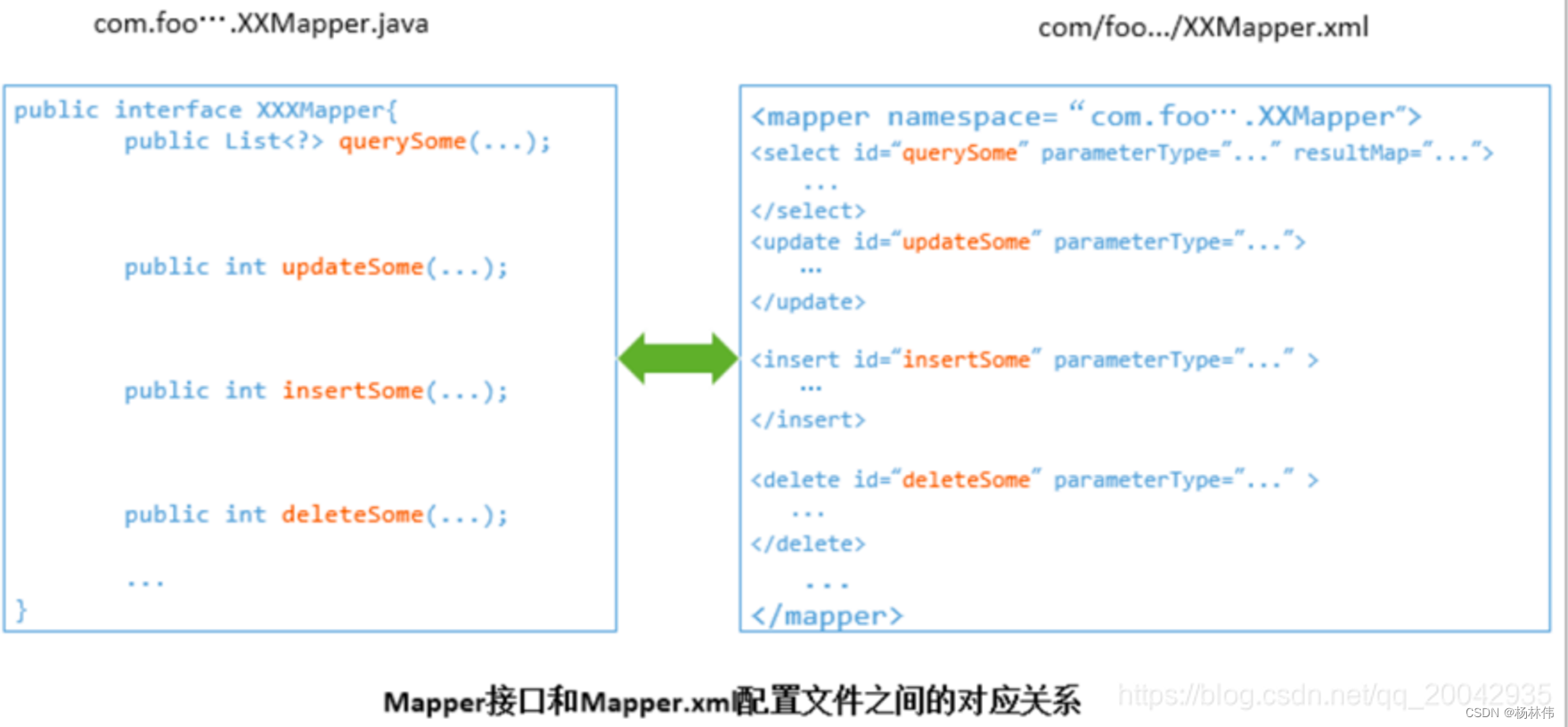
MyBatis: There are two ways to interact with the database, one is to use the API directly, and the other is to use the Mapper interface. The corresponding relationship between the Mappr interface and Mapper.xml is as follows:
MyBatis underlying implementation: MyBatis will generate a Mapper instance through the dynamic proxy mechanism based on the method information declared by the corresponding interface. When we use a method of the Mapper interface, MyBatis will According to the method name and parameter type of this method, the Statement Id is determined. The bottom layer still implements operations on the database through SqlSession.select("statementId", parameterObject), or SqlSession.update("statementId", parameterObject); and so on.
public class MyInvocationHandlerMbatis implements InvocationHandler {
private Object object;
public MyInvocationHandlerMbatis(Object object) {
this.object = object;
}
// proxy 代理对象 method拦截方法 args方法上的参数值
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("使用动态代理技术拦截接口方法开始");
// 使用白话问翻译,@ExtInsert封装过程
// 1. 判断方法上是否存在@ExtInsert
ExtInsert extInsert = method.getDeclaredAnnotation(ExtInsert.class);
if (extInsert != null) {
return extInsert(extInsert, proxy, method, args);
}
// 2.查询的思路
// 1. 判断方法上是否存 在注解
ExtSelect extSelect = method.getDeclaredAnnotation(ExtSelect.class);
if (extSelect != null) {
// 2. 获取注解上查询的SQL语句
String selectSQL = extSelect.value();
// 3. 获取方法上的参数,绑定在一起
ConcurrentHashMap<Object, Object> paramsMap = paramsMap(proxy, method, args);
// 4. 参数替换?传递方式
List<String> sqlSelectParameter = SQLUtils.sqlSelectParameter(selectSQL);
// 5.传递参数
List<Object> sqlParams = new ArrayList<>();
for (String parameterName : sqlSelectParameter) {
Object parameterValue = paramsMap.get(parameterName);
sqlParams.add(parameterValue);
}
// 6.将sql语句替换成?
String newSql = SQLUtils.parameQuestion(selectSQL, sqlSelectParameter);
System.out.println("newSQL:" + newSql + ",sqlParams:" + sqlParams.toString());
// 5.调用jdbc代码底层执行sql语句
// 6.使用反射机制实例对象### 获取方法返回的类型,进行实例化
// 思路:
// 1.使用反射机制获取方法的类型
// 2.判断是否有结果集,如果有结果集,在进行初始化
// 3.使用反射机制,给对象赋值
ResultSet res = JDBCUtils.query(newSql, sqlParams);
// 判断是否存在值
if (!res.next()) {
return null;
}
// 下标往上移动移位
res.previous();
// 使用反射机制获取方法的类型
Class<?> returnType = method.getReturnType();
Object object = returnType.newInstance();
while (res.next()) {
// 获取当前所有的属性
Field[] declaredFields = returnType.getDeclaredFields();
for (Field field : declaredFields) {
String fieldName = field.getName();
Object fieldValue = res.getObject(fieldName);
field.setAccessible(true);
field.set(object, fieldValue);
}
// for (String parameteName : sqlSelectParameter) {
// // 获取参数值
// Object resultValue = res.getObject(parameteName);
// // 使用java的反射值赋值
// Field field = returnType.getDeclaredField(parameteName);
// // 私有方法允许访问
// field.setAccessible(true);
// field.set(object, resultValue);
// }
}
return object;
}
return null;
}
private Object extInsert(ExtInsert extInsert, Object proxy, Method method, Object[] args) {
// 方法上存在@ExtInsert,获取他的SQL语句
// 2. 获取SQL语句,获取注解Insert语句
String insertSql = extInsert.value();
// System.out.println("insertSql:" + insertSql);
// 3. 获取方法的参数和SQL参数进行匹配
// 定一个一个Map集合 KEY为@ExtParamValue,Value 结果为参数值
ConcurrentHashMap<Object, Object> paramsMap = paramsMap(proxy, method, args);
// 存放sql执行的参数---参数绑定过程
String[] sqlInsertParameter = SQLUtils.sqlInsertParameter(insertSql);
List<Object> sqlParams = sqlParams(sqlInsertParameter, paramsMap);
// 4. 根据参数替换参数变为?
String newSQL = SQLUtils.parameQuestion(insertSql, sqlInsertParameter);
System.out.println("newSQL:" + newSQL + ",sqlParams:" + sqlParams.toString());
// 5. 调用jdbc底层代码执行语句
return JDBCUtils.insert(newSQL, false, sqlParams);
}
private List<Object> sqlParams(String[] sqlInsertParameter, ConcurrentHashMap<Object, Object> paramsMap) {
List<Object> sqlParams = new ArrayList<>();
for (String paramName : sqlInsertParameter) {
Object paramValue = paramsMap.get(paramName);
sqlParams.add(paramValue);
}
return sqlParams;
}
private ConcurrentHashMap<Object, Object> paramsMap(Object proxy, Method method, Object[] args) {
ConcurrentHashMap<Object, Object> paramsMap = new ConcurrentHashMap<>();
// 获取方法上的参数
Parameter[] parameters = method.getParameters();
for (int i = 0; i < parameters.length; i++) {
Parameter parameter = parameters[i];
ExtParam extParam = parameter.getDeclaredAnnotation(ExtParam.class);
if (extParam != null) {
// 参数名称
String paramName = extParam.value();
Object paramValue = args[i];
// System.out.println(paramName + "," + paramValue);
paramsMap.put(paramName, paramValue);
}
}
return paramsMap;
}
public Object extInsertSQL() {
return object;
}
}
Hierarchical structure of MyBatis:

ArrayList underlying implementation principle: Based on array implementation, the default array initialization size is 10 object arrays. After adding elements that are greater than the length of the current array, the capacity will be expanded to reduce the length of the array. Increase the original array by half.
The difference between Vector and ArrayList: Vector is thread-safe. Both ArrayList and Vector use linear continuous storage space. When the storage space is insufficient, ArrayList increases to the original 50 by default. %, Vector is doubled by default,
Array copy method:
- Arrays.copyOf: The function is to copy the array and return the copied array. The parameters are the array to be copied and the length of the copy.
- System.arraycopy: If the array is relatively large, then using System.arraycopy will be more advantageous, because it uses memory copying, eliminating a lot of array addressing. Access and wait to copy the specified source array src to the destination array dest.
Implementation process: First generate a temporary array with a length of length, copy the data between srcPos and srcPos+length-1 in the fun array to the temporary array, and then execute System.arraycopy(temporary array,0,fun,3,3).
int[] fun ={
0,1,2,3,4,5,6};
System.arraycopy(fun,0,fun,3,3);
The underlying principle of LinkedList: The underlying data structure is based on a two-way looplinked list, and the header is No data is stored in the point. It is different from an array as follows:
- Array (allocate space from the stack): If the application requires fast access to data and rarely inserts and deletes elements, an array should be used. A fixed length (number of elements) must be defined in advance and cannot adapt to the dynamic increase or decrease of data.
- Linked list (allocate space from heap): You need to use linked list if the application needs to frequently insert and delete elements. Dynamic storage allocation can adapt to the dynamic increase and decrease of data, and data items can be easily inserted and deleted.
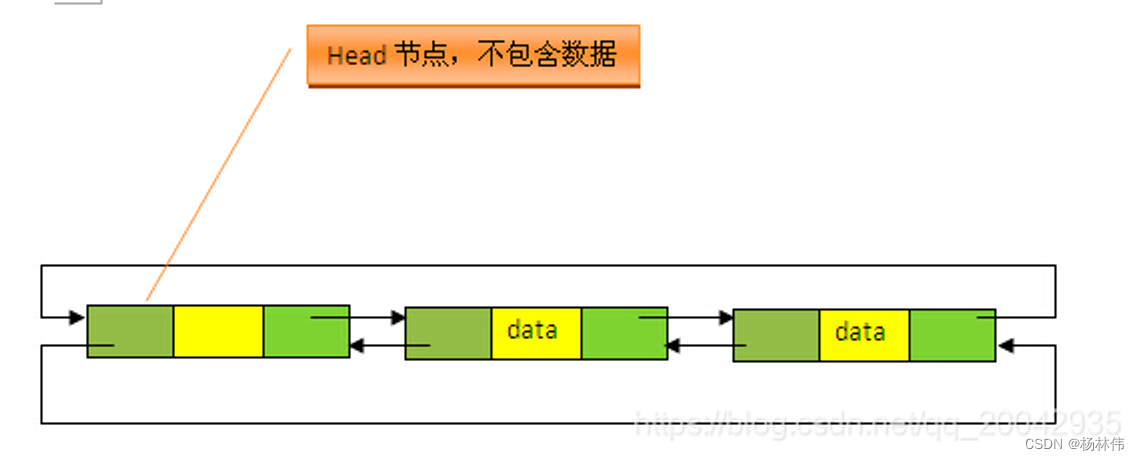
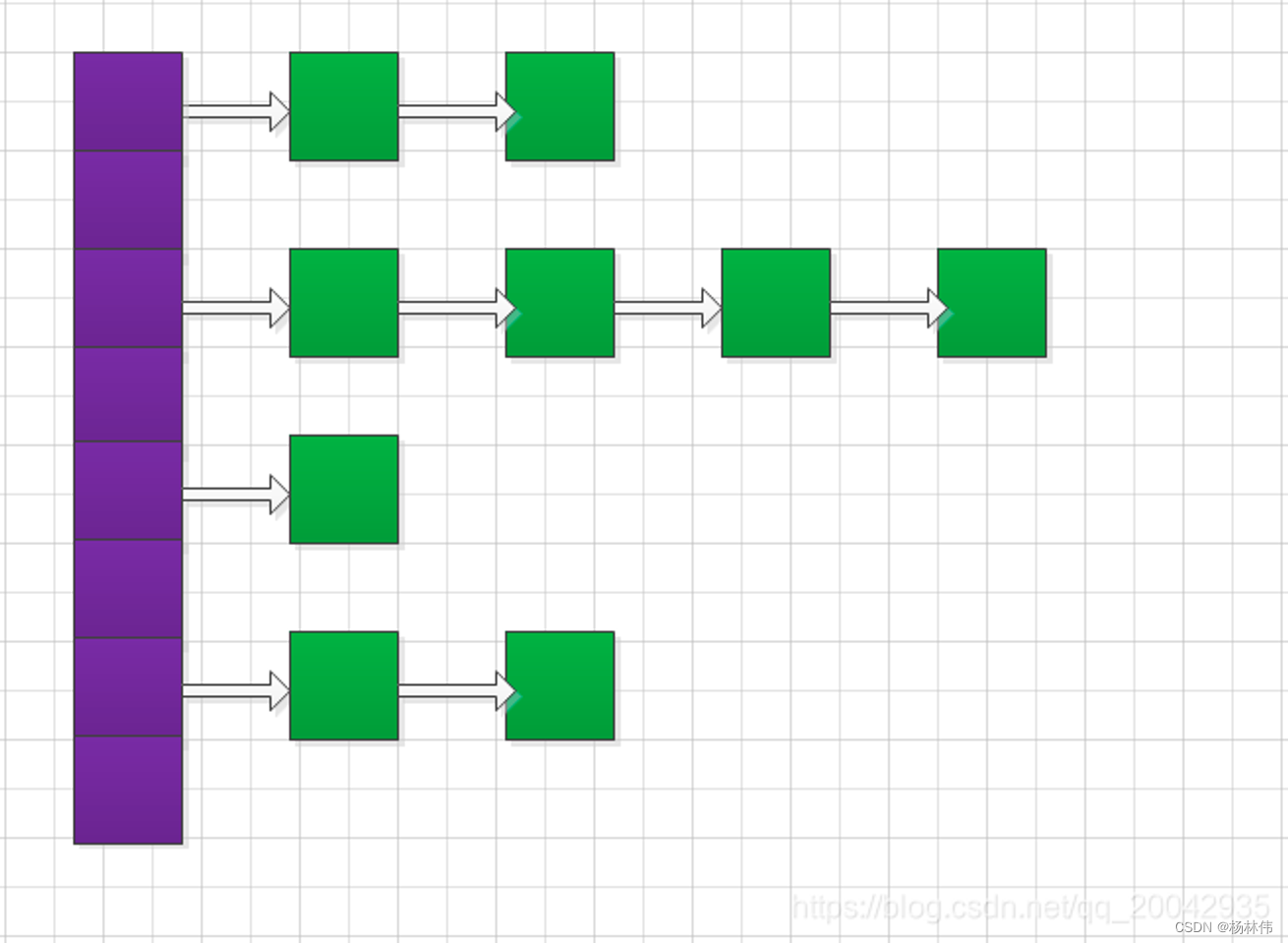
The underlying principle of HashMap: Array + linked list (Array (purple): Hash array (bucket) ), the array element is the head node of each linked list, Linked list (green): resolves hash conflicts, different keys are mapped to the same index of the array)
put method process:
- If the added key value is null, then the key-value pair is added to the linked list with array index 0, which is not necessarily the first node of the linked list.
- If the added key is not null, calculate the position of the array index based on the key:
----- There is a linked list at the array index, then traverse the linked list, if the key is found already exists, then replace the old value with the new value.
----- There is no linked list at the array index. Add the key-value here to become the head node.
get method process:
- If the key is null, then traverse the linked list at the array index table[0] to find the value whose key is null;
- If the key is not null, find the linked list at the array index position based on the key, traverse to find the value of the key, and return the value if found. If not found, return null.
Expansion mechanism: Actual capacity = initial capacity × load factor (for example: 16×0.75=12, that is, when the actual capacity exceeds 12, this HashMap will expand.)
- Initial capacity: When constructing a hashmap, the initial capacity is set to a number not less than the power of 2 of the specified capacity (new HashMap(5), the specified capacity is 5 , then the actual initial capacity is 8, 2^3=8>5), and the maximum value cannot exceed 2 to the 30th power.
- Load Factor : Load factor is a measure of how full a hash array can become before its capacity automatically increases. (Trade of time and space) When the number of entries in the hash array exceeds the product of the loading factor and the initial capacity, the hash array needs to be expanded (ie, resized).
- When HashMap is expanded, the capacity of the new array will be twice the original one. Due to the change in capacity, each original element The array index Index needs to be recalculated and then stored in a new array. This is called rehash.
eqauls method and hashCode method:
- hashCode: Defined in the
Objectclass, but its default implementation returns the hash code of the object's memory address. In actual applications, especially when using hash tables (such as HashMap, HashSet, etc.), we usually need to override thehashCodemethod to better distribute objects and avoid hash conflicts. - eqauls method: Compares whether the references of two objects are equal, that is, whether they point to the same object in memory;
- If two objects are the same, their hashCode values must be the same. It also tells us that when rewriting the equals method, we must rewrite the hashCode method, which means that the hashCode value must be linked to the member variable in the class. The object is the same -> the member variable is the same -> the hashCode value must be the same.
- If the hashCode of two objects is the same, they are not necessarily the same. Here the objects are the same refers to comparison using the eqauls method. If you want to compare the contents of objects rather than their references, you need to override this method.