Paper title: Scalable diffusion models with transformers
Paper link: https://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.html
Code: https://github.com/facebookresearch/DiT/blob/main/README.md

引用:Peebles W, Xie S. Scalable diffusion models with transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 4195-4205.
Introduction
This paper explores a novel diffusion model based on transformer architecture. The author uses Transformer to train the latent diffusion model of the image, replacing the commonly used U-Net backbone network. This Transformer operates on latent image patches. The study also analyzed the scalability of this new model, measuring forward propagation complexity in terms of Gflops (giga floating-point operations per second). Research has found that Diffusion Transformers (DiTs) with higher Gflops - by increasing the depth/width of the Transformer or increasing the number of input tokens - generally have lower FID (Frechet Inception Distance). Furthermore, the largest DiT-XL/2 model in the study performed well on the category-conditioned ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID score of 2.27 on the latter.
Contributions to this article
A new diffusion model architecture called Diffusion Transformers (DiTs) is proposed. This architecture is based on Transformers and is used for image generation tasks.
Research shows that the U-Net backbone commonly used in traditional diffusion model architectures is not a critical factor in performance. They successfully replaced U-Net with the standard Transformer architecture, which means that diffusion models can adopt more general designs such as Transformers without being restricted to a specific architecture.
By using the DiTs architecture, the researchers achieved significant performance improvements on the ImageNet generation benchmark, reducing the FID (Frechet Inception Distance) to 2.27, reaching the latest state-of-the-art level.
Preliminary knowledge
Basic theory of diffusion model
The Gaussian diffusion model assumes a forward noise process and gradually applies noise to real data:
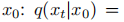
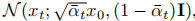
By applying the reparameterization trick we can sample:
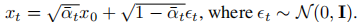
The diffusion model is trained to learn the reverse process, that is, the process of restoring the damage in the forward process to the original data:
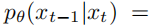
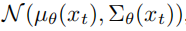
When training the inverse process model, a variational lower bound is used to estimate the log-likelihood of x0:
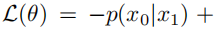
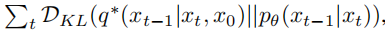
By reparameterizing µθ into a noise prediction network εθ, the model can predict noise using
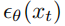
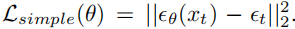
However, in order to use the learned reverse process covariance
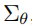
No classifier bootstrapping
Conditional diffusion models take additional information as input, such as class labels c. In this case, the reverse process becomes:
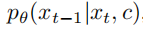
In this case, classifier-free guidance can be used to encourage the sampling program to find x such that log p(c|x) becomes high. According to Bayes' rule:
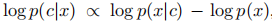
therefore,
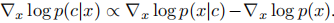
Therefore, when the probability of the desired condition is relatively high, the gradient of the condition can be added to the optimization goal, and finally it can be expressed in the following form:
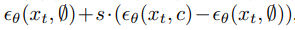
Classifier-free bootstrapping has been widely recognized to significantly improve the quality of sample generation, and this trend is equally valid in DiTs models.
Latent diffusion models
Training diffusion models directly in high-resolution pixel space is computationally expensive. Latent diffusion models (LDMs) solve this problem through a two-stage approach: first, learn an autoencoder to compress the image into a smaller spatial representation with a learned encoder E; second, train the representation z = E(x ) rather than the diffusion model of image x (E is frozen). A new image x = D(z) can then be generated by sampling the representation z from the diffusion model and decoding it using the learned decoder. As shown in Figure 2, the latent diffusion model achieves good performance at a fraction of the Gflops using a pixel-space diffusion model like ADM. Because the authors focus on computational efficiency, this makes them an attractive starting point for architectural exploration.

Methods of this article
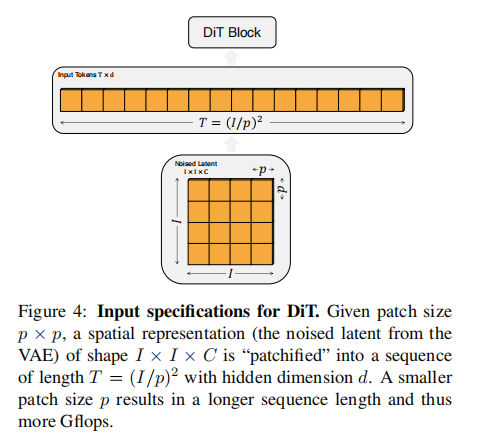
Patchify: The input to DiT is a spatial representation z (for a 256x256x3 image, the shape of z is 32x32x4). The first layer of DiT is “patchify”, which transforms the spatial input into T labeled sequences of dimension d by linearly embedding each image patch in the input. Subsequently, we apply standard ViT frequency-based positional embedding (sine-cosine version) to all input tokens. The number of markers T created by patchify is determined by the patch size hyperparameter p.
As shown in Figure 4, halving p increases T by a factor of four, thus at least quadrupling the total Transformer Gflops. Despite the significant impact on Gflops, it is important to note that changing p has no real impact on the number of downstream parameters.
The authors set p to 2, 4 and 8.
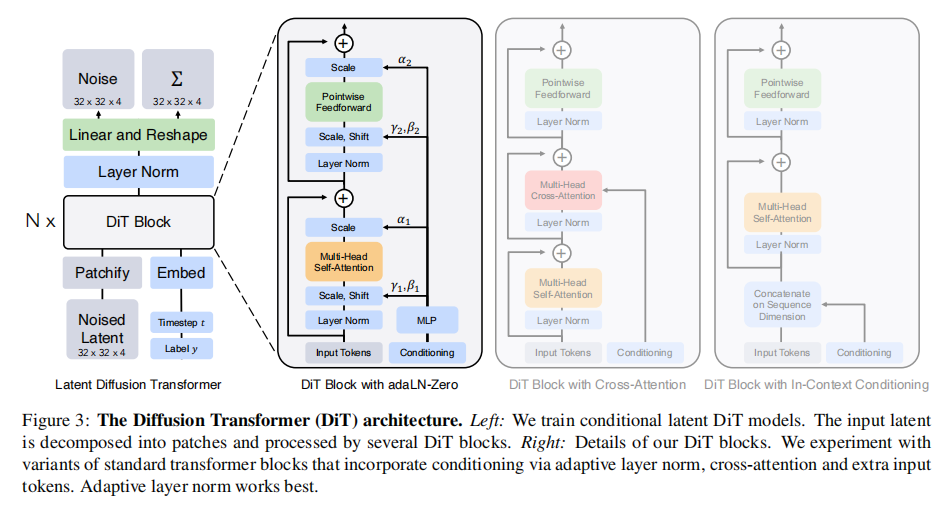
DiT block design:After patchify, the input tokens are processed by a series of Transformer blocks. In addition to the noisy image input, the diffusion model sometimes also handles additional conditional information, such as noise time step t, category label c, natural language, etc. The researchers explored four Transformer block variants that handle conditional input differently. These designs make small but important modifications to the standard ViT block design. The designs of all blocks are shown in Figure 3 (the authors finally selected the adaLN block after experimental analysis). These four blocks are introduced below.
In-context Conditioning: This method simply appends the vector embeddings of t and c to the input sequence as two extra tags, treating them no differently than image tags. This is similar to the cls tag in ViTs, which allows us to use standard ViT blocks without modification. After the last block, remove the conditional marker from the sequence. This approach introduces an almost negligible overhead of new Gflops to the model.
Cross-Attention Block: This method concatenates the embeddings of t and c into a sequence of length 2, separate from the image label sequence. The Transformer block has been modified to include a multi-head cross-attention layer after the multi-head self-attention block. The cross-attention block adds the most Gflops to the model, increasing the overhead by approximately 15%.
Adaptive Layer Norm (adaLN) Block: This approach is based on the adaptive normalization layer widely used in GANs and diffusion models with UNet backbone, replacing the standard norm layer in the Transformer block with an adaptive norm (adaLN). Instead of directly learning parameters such as γ and β, they are regressed from the sum of the embedding vectors of t and c. Of the three block designs studied by the authors, adaLN adds the fewest Gflops and is therefore the most computationally efficient. This is also the only conditionalization mechanism that applies the same function to all tags.
adaLN-Zero Block: Previous research found that it is beneficial to initialize each residual block to an identity function. To achieve this goal, the authors explored a modified version of the adaLN DiT block, which was similar to the previous one. In addition to regressing γ and β, they also regress the dimension scaling parameter α before applying any residual connections within the DiT block. They initialize the MLP to output zero vectors for all α, thereby initializing the entire DiT block to the identity function. Like regular adaLN blocks, adaLN-Zero adds almost negligible Gflops to the model.
Transformer decoder: After the last DiT block of the DiT architecture, the image marker sequence needs to be decoded into the noise prediction and diagonal covariance prediction of the output. Both outputs have the same shape as the original spatial input. To achieve this, the authors used a standard linear decoder, applying the last layer specification (adaptive if using adaLN) to each token and linearly decoding to a p x p x 2C tensor, where C is the DiT Number of channels in the input. Finally, the decoded markers are rearranged into the original spatial layout, resulting in predictions of noise and covariance.
experiment
Experimental results
The effects of different diffusion models are compared as follows:
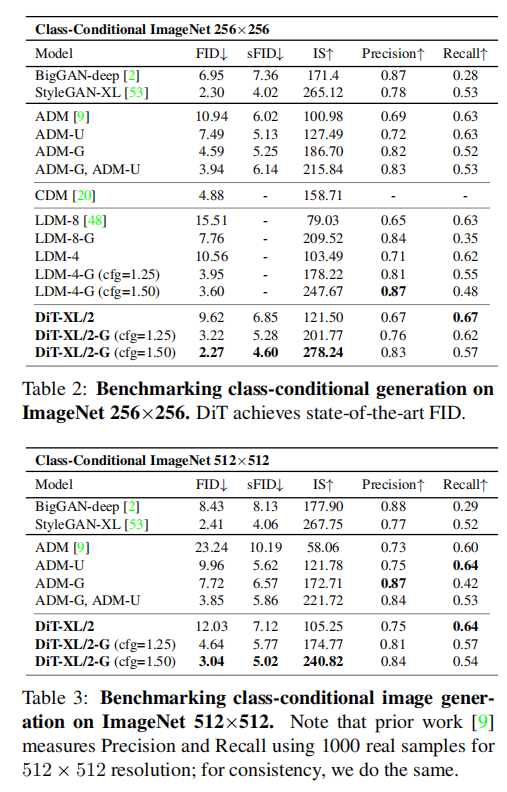
As can be seen from the figure below, the adaLN-Zero method is significantly better than cross-attention and in-contenxt, so the adaLN-Zero method is used in the experiments for context interaction:
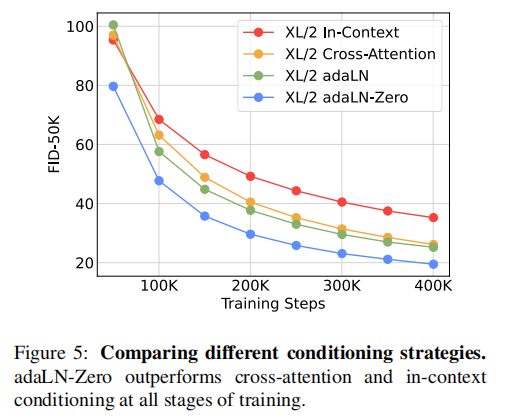
Scaling the DiT model improves FID at all stages of training:
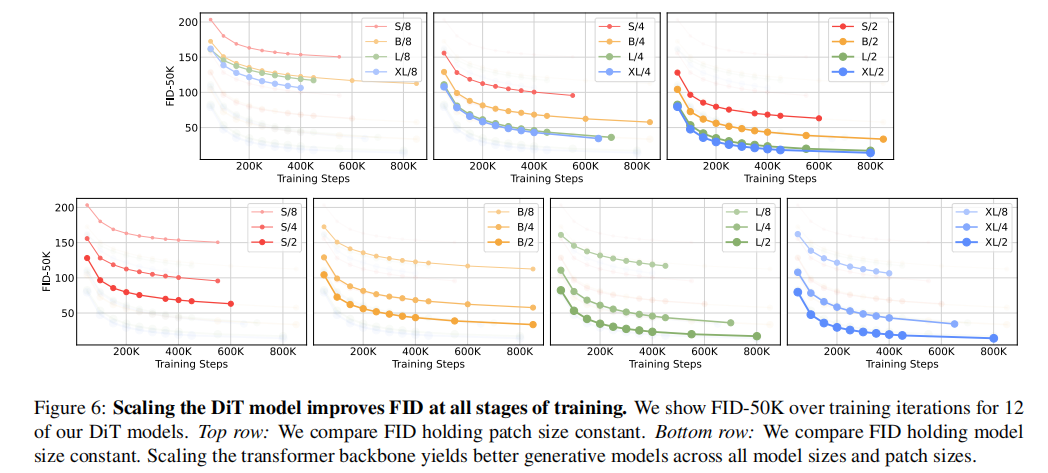
The larger the model and the smaller the patch size, the better the image quality generated:

in conclusion
The article proposes a DiTs structure for diffusion model image generation. Based on the DiTs-XL/2 structure, which is equivalent to Gflops and Stable Diffusion, the FID index on the ImageNet 256×256 data set is optimized to 2.27, reaching the SOTA level. Larger DiTs models and token numbers will be further explored in the future.
☆ END ☆
If you see this, it means you like this article, please forward it and like it. Search "uncle_pn" on WeChat. Welcome to add the editor's WeChat "woshicver". A high-quality blog post will be updated in the circle of friends every day.
↓Scan the QR code to add the editor↓
