
This article is compiled from what Xu Bangjiang, the Flink leader of the Flink data channel, the leader of the Flink CDC open source community, and a PMC member of the Apache Flink community, shared at the open source big data session at the Computing Conference. The content of this article is mainly divided into four parts:
- Challenges of real-time integration of CDC data
- Flink CDC core technology interpretation
- Enterprise-level real-time data integration solution based on Flink CDC
- Real-time data integration Demo demonstration
Challenges of real-time integration of CDC data
First, let’s introduce CDC technology. CDC is the abbreviation of Change Data Capture, which means change data capture. If there is data from a data source that changes over time, this technology that can capture the changed data is called CDC. However, in the actual business production practice, CDC usually refers to database-oriented changes, which are used to capture the business of a certain table in the database, constantly writing new data, updated data, and even deleted data. When we talk about the technology for capturing change data, the reason why we mainly focus on databases is mainly because the data in the database is the data with the highest business value, and the change data in the database is also the most timely and valuable data in the business.

CDC technology is widely used, mainly in three aspects.
First, data synchronization, such as data backup and system disaster recovery, will use CDC.
Second, data distribution, such as distributing changed data in the database to Kafka, and then distributing it one-to-many to multiple downstreams.
Third, data integration, whether building a data warehouse or a data lake, requires a necessary task: data integration, that is, putting data into the lake and warehousing it, and at the same time there will be some ETL processing. CDC technology is also indispensable in this work. application scenarios.

From the underlying implementation mechanism of CDC, CDC technology can be divided into two categories: query-based CDC technology and log-based CDC technology.
Query-based CDC technology. Suppose there is a table in the database that is constantly being updated. We can query it every 5 minutes. In the query, for example, we can compare the update time field to see what new data there is, so that we can obtain the CDC data. This technology needs to be based on offline scheduling queries, which is a typical batch process. It cannot guarantee the strong consistency of the data, nor can it guarantee real-time performance. According to industry practice, 5 minutes is already the limit for offline scheduling, and it is difficult to achieve minute-level or even second-level offline scheduling.
Log-based CDC technology. This is the technology for parsing changes based on database change logs. Everyone knows that MySQL database has a Binlog mechanism. CDC technology based on database change logs can consume logs in real time for stream processing. As long as the upstream updates a piece of data, the downstream can immediately perceive this data, which can ensure strong consistency of the entire data and provide real-time data. Log-based CDC technology is usually more complex to implement than query-based methods.
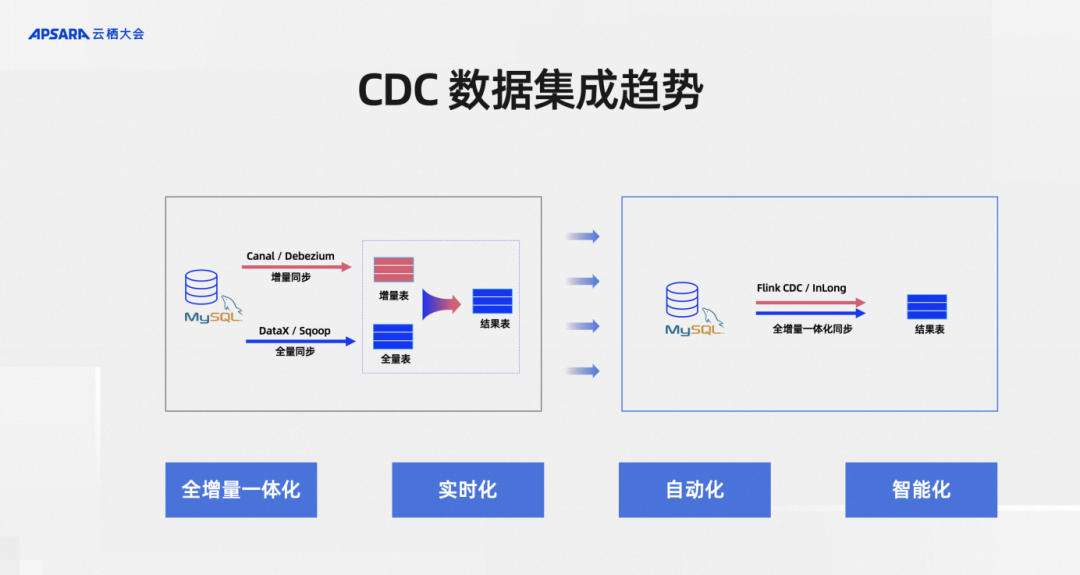
Judging from the development trends in the subdivision of CDC data integration, four general directions are summarized:
First, full incremental integration.
Second, real-time.
Third, automation.
Fourth, intelligence.
Full-incremental integration is data integration compared to full-volume and incremental data integration, so a good example of full-volume is a MySQL table with massive historical data. But at the same time, the upstream business system is constantly updating it in real time. The part updated in real time is incremental data, and the historical part is full data.
Often these two parts of data use different tools in the early stages. For example, the domestic open source DataX is used for full data, and Apache Sqoop is available overseas for full data synchronization. The incremental part includes domestic Alibaba open source projects such as Canal, MySQL, Debezium, InLong, etc. Users generally combine these two types of tools for full data and incremental data integration respectively, at the cost of maintaining many components. Full incremental integration is to reduce these components as much as possible. For example, using methods such as Flink CDC and InLong to achieve full incremental integration to reduce operation and maintenance pressure.
The second is real-time. Everyone knows why we need to promote real-time, because the higher the timeliness of business data, the higher the value. For example, if some risk control business and policy configuration business can be processed in seconds, the business effect will be completely different from the data that can be prepared two days later, so real-time processing is increasingly valued.
Automation means that when we combine full volume and increment, do we need human intervention after the full volume is completed? How to ensure the connection of the increment after the full volume synchronization is completed? Is this the automatic connection capability provided by the CDC framework or does it require manual operation by operation and maintenance personnel? , Automation is to reduce such manual operations. Automation can be said to be the pursuit of reducing operation and maintenance costs and improving product experience.
Intelligence is a business table in MySQL. It is constantly changing as the business changes. Not only the data changes, but the table structure inside also changes. In response to these scenarios, whether the data integration operation can remain robust and whether it can automatically and intelligently handle these changes in the upstream is an intelligent demand, which is also the trend of CDC data integration.
 After analyzing some architectural evolution directions in the entire CDC data integration segment, we also saw many problems. If we want to solve them, what are the technical challenges? It can be roughly divided into four aspects:
After analyzing some architectural evolution directions in the entire CDC data integration segment, we also saw many problems. If we want to solve them, what are the technical challenges? It can be roughly divided into four aspects:
First, the scale of historical data is very large. Some MySQL single tables can reach the level of hundreds of millions or billions. In the scenario of sub-database and sub-table, the scale of historical data is even larger.
Second, the real-time requirements for incremental data are getting higher and higher. For example, the current lake warehouse scene already requires a low latency of 5 minutes. In some more extreme scenarios, such as risk control, CEP rule engine and other application scenarios, even second-level and sub-second-level delays are required.
Third, CDC data has an important order-preserving property. Can full and incremental data provide a consistent snapshot with the original MySQL library? Such order-preserving requirements pose a great challenge to the entire CDC integration framework. .
Fourth, table structure changes include new fields and type changes of existing fields. For example, if the business development length of a field is upgraded, whether the framework can automatically support such changes is a technical challenge for CDC data integration.
In response to these challenges, I selected the existing mainstream open source technology solutions in the industry, which are also common and widely used, for analysis, including Flink CDC, Debezium, Canal, Sqoop, and Kettle. Let’s analyze them from the following dimensions: Analysis, first of all, is the CDC mechanism, which is the underlying mechanism to see whether it is log or query.
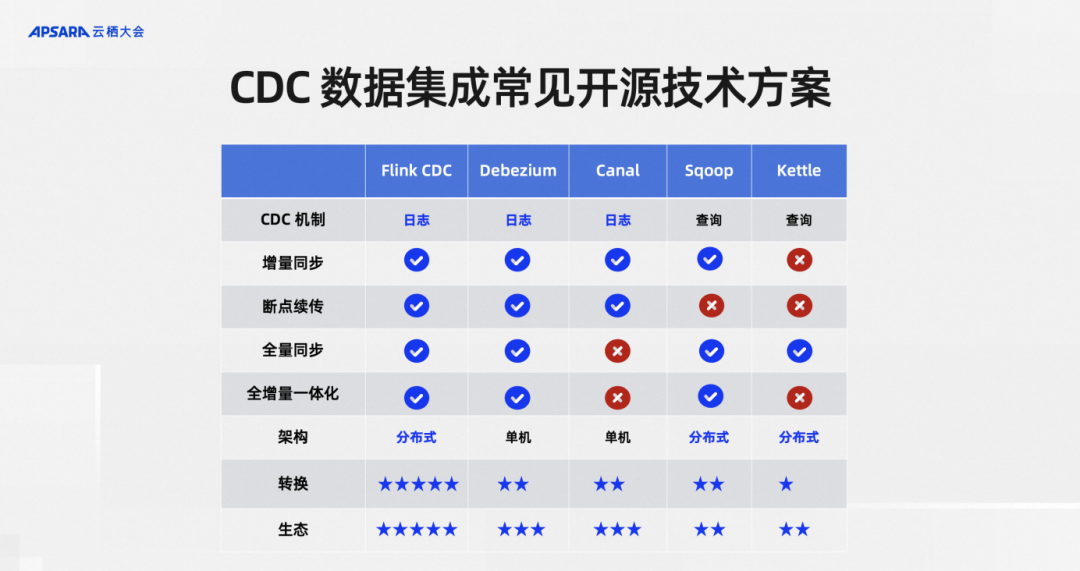
The second is breakpoint resumption. Breakpoint resumption means that the full data history is very large. When the synchronization is halfway done, can it be stopped and resumed again instead of reloading the data from scratch. The full synchronization dimension means that the framework does not support historical data synchronization. The dimension of full incremental integration is whether the full and incremental processes are solved by the framework or require developers to solve them manually. The architectural dimension evaluates whether the CDC framework is a scalable distributed architecture or a stand-alone version. The conversion dimension measures CDC data. When data integration is done for ETL, some data cleaning is often required, such as case conversion. Can the framework support it well? For example, if some data filtering needs to be done, can the framework be very efficient? Good support, and another one is the upstream and downstream ecology of this tool, how many data sources the framework supports upstream, which downstream computing engines can support, and which lake warehouses support writing, because when choosing a CDC data integration framework or tool It must be considered in conjunction with the architectural design of other products of the entire big data team. Analyzing from the above dimensions, Flink CDC performs very well in these dimensions.
Flink CDC core technology interpretation
We just mentioned that the Flink CDC framework has some advantages in the dimensions of full incremental integration and distributed architecture. Next, we will analyze the core technology implementation of the underlying framework and help everyone understand how Flink CDC works. With these advantages, as well as some of the original intentions of our design.
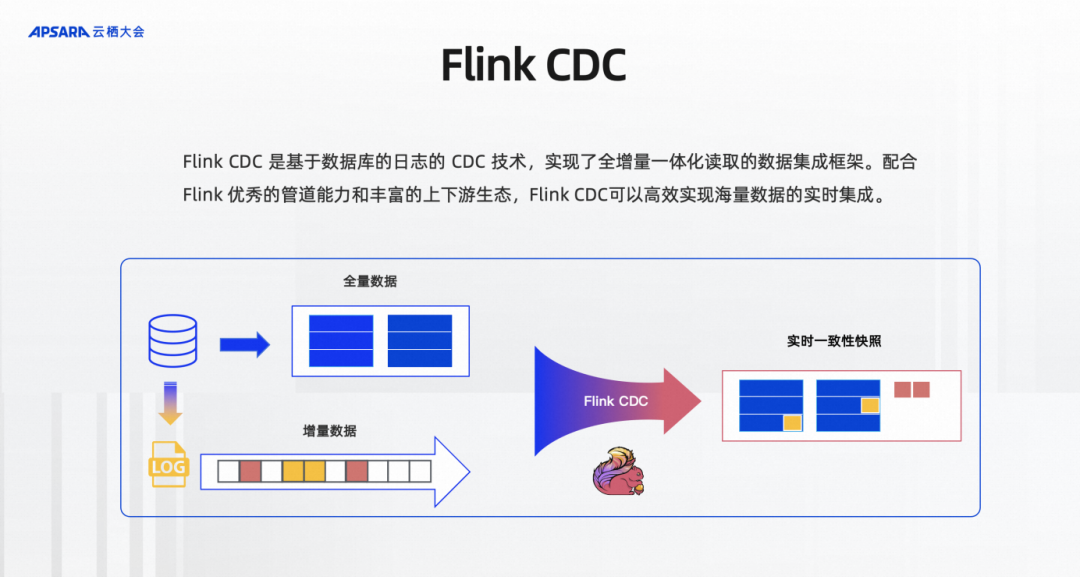
Flink CDC is a CDC technology based on database logs and a data integration framework that implements full incremental integrated reading. With Flink's excellent pipeline capabilities and rich upstream and downstream ecology, Flink CDC can efficiently achieve real-time integration of massive data. As shown in the figure, for example, MySQL has a table with full historical data, as well as incremental data that is continuously written, and incremental data of business updates. MySQL will first store it in its own Log. Flink CDC not only reads the full data, It also reads incremental data through log-based CDC technology and provides real-time consistent snapshots to the downstream. The framework provides automatic docking of full and incremental data, ensuring data transmission semantics without loss or duplication, and developers do not need to care about the underlying layer. details.

Overall, Flink CDC has two core designs;
The first is the incremental snapshot framework. This is an incremental snapshot algorithm I proposed in Flink CDC 2.0, which later evolved into the incremental snapshot framework. The data sources on the left are the incremental snapshot frameworks that the Flink CDC community currently supports or has been connected to. What capabilities does the incremental snapshot framework embody? Parallel reading can be done when reading data from a table to the full amount of data. Even if the historical data of this table is very large, as long as concurrency is increased and resources are expanded, this framework has the ability to expand horizontally, which can be achieved through parallel reading. expansion needs.
The second is that full and incremental are locked-free consistency switching through the lock-free consistency algorithm. This is actually very important in a production environment. In many CDC implementations, MySQL business tables need to be locked to obtain data consistency. This lock alone will directly affect the upstream production business library. Generally, DBAs and business students are I don't agree. If you use the incremental snapshot framework, you can unlock the database. This is a very business-friendly design.
After switching to the incremental phase, combined with the Flink framework, resources can be automatically released. Generally speaking, concurrency in the full phase requires a lot of data because there is a lot of data. In fact, writing to the MySQL upstream in the incremental phase is basically a separate log. File writing, so one concurrency is often enough, and the framework can support automatic release of redundant resources.
In summary, the four red key phrases as shown in the figure highlight the core capabilities provided by the incremental snapshot framework to Flink CDC.
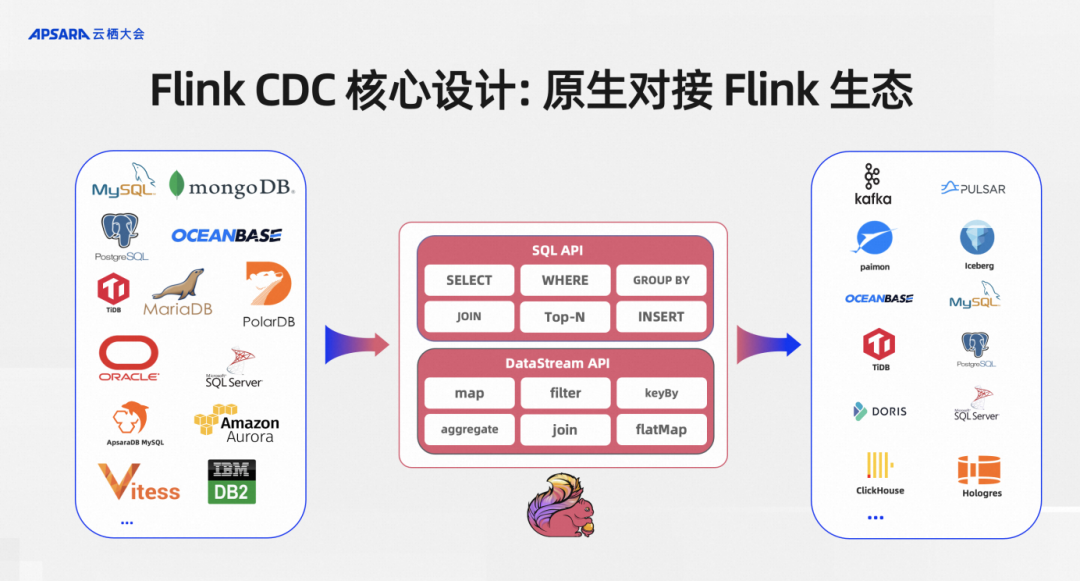
The second core design is to natively connect to the Flink ecosystem. The most important thing to care about when connecting to the Flink ecosystem is whether you can seamlessly use Flink’s SQL API, DataStream API and downstream. When Flink CDC serves as the upstream of Flink jobs, currently all our connections support SQL API and DataStream API.
The advantage of supporting SQL API is that users do not need to have underlying JAVA development foundation. They only need to be able to write SQL. This can actually be done by handing over a very difficult CDC data integration to BI development students. The DataStream API is for more advanced developers who may want to implement some more complex and advanced functions. We also provide the DataStream API, so that lower-level developers can use this DataStream API to implement the entire process through Java programming. Advanced functions such as library synchronization and Schema Evolution.
After being natively connected to the Flink ecosystem, all downstream supported by Flink, such as message queues, Kafka, Pulsar, data lake Paimon or traditional databases, can be directly written to Flink CDC.

With these core designs, in general: Flink CDC has four technical advantages.
First, parallel reading. This framework provides distributed reading capabilities. The Flink CDC framework can support horizontal expansion. As long as resources are sufficient, read throughput can be expanded linearly.
Second, lock-free reading. There is no intrusion into online databases and businesses.
Third, full incremental integration. The consistency guarantee and automatic connection between full volume and incremental volume are solved by the framework without manual intervention.
Fourth, ecological support. We can natively support Flink’s existing ecosystem, and user development and deployment costs are low. If the developer is already a Flink user, he does not need to install additional components, nor does he need to deploy a Kafka cluster. If he is a SQL user, he only needs to place a connector jar package in the Flink lib directory.
Another point that may be of interest to the audience is that the Flink CDC project is completely open source, and it came out of the open source community from the first day of its birth. It has been released from version 0.x to the latest version 2.4.2. , has been maintained for three years by all community contributors. As an open source project that has been gradually polished as a personal interest project, the community has developed very rapidly in three years. The development I'm talking about here doesn't just mean the very rapid development of Github Star 4500+. In fact, what we value more is the number of code forks and the number of community contributors. The Fork count indicator indicates how many organizations and open source community contributors are using the Flink CDC warehouse. For example, top projects such as Apache InLong have integrated Flink CDC.
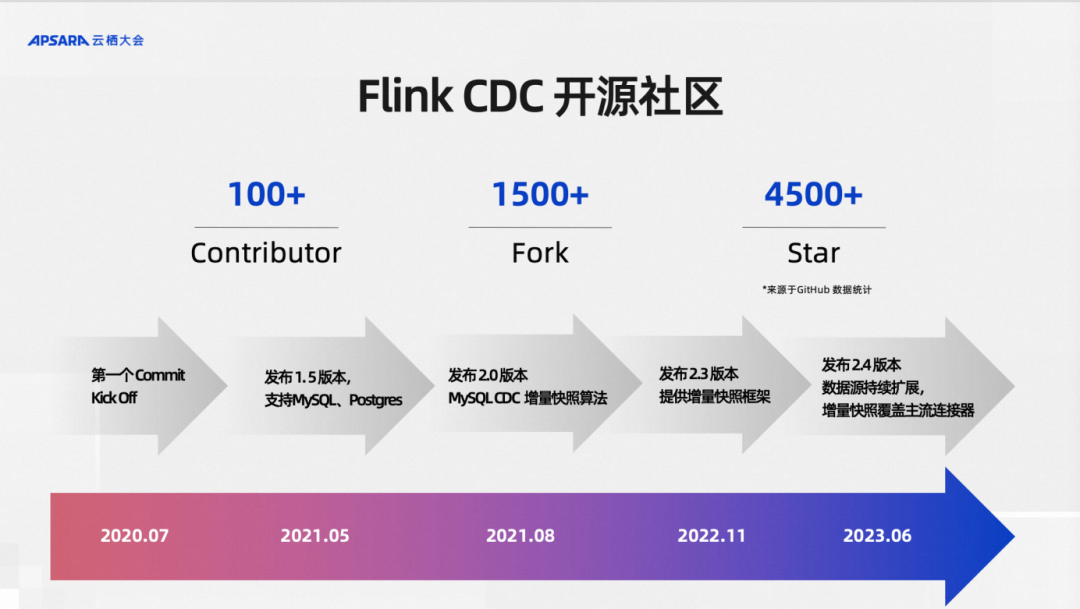
At the same time, many top overseas and domestic companies are also using our projects. Recently, the number of contributors to our open source community from domestic and overseas has exceeded 100+, which shows that the development of our open source community is still very healthy.
After talking about the open source community of Flink CDC, one point that everyone will pay attention to is that the capabilities it provides are still biased toward the underlying engine, which is more oriented to underlying developers. There is still a gap between us and our final data integration users, and this gap is the engine. How to form a product to the end user. There is a fact that needs to be noted. Users of data integration may not necessarily understand Flink, Java, or even SQL. So how can we get them to use this framework? How to provide user-oriented products to serve these users well? In fact, many companies and organizations involved in open source have some best practices.
Alibaba Cloud's enterprise-level real-time data integration solution based on Flink CDC
The third part of today’s sharing is what I want to introduce today. Within Alibaba Cloud, how we provide our real-time data integration solution based on the open source Flink CDC data integration framework, that is, we will share with you some of Alibaba Cloud’s practical solutions. .
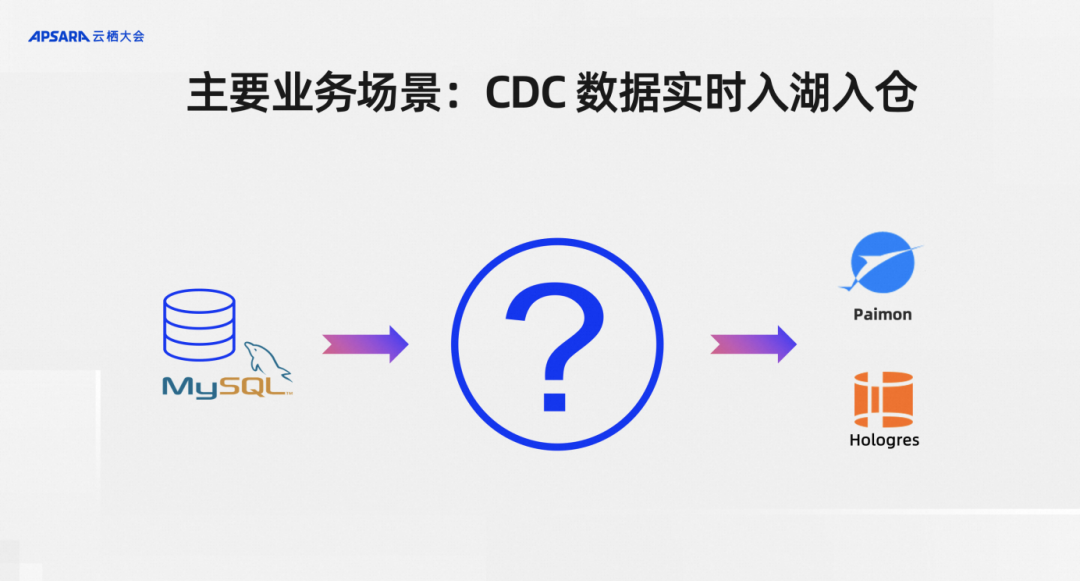
On Alibaba Cloud, the main business scenario of our Flink CDC is to store CDC data into the lake and warehouse in real time. For example, my business database is MySQL, and of course other databases are the same. I actually want to synchronize the data in MySQL to the lake warehouse with one click, such as Paimon and Hologres. The business scenario is that CDC data is entered into the lake and warehouse in real time. This What are the core demands of users in this scenario?
We have roughly sorted out four key points: automatic discovery of table structure is required, automatic synchronization of changes in table structure is required, synchronization of the entire database is required, and dynamic addition of tables is required.
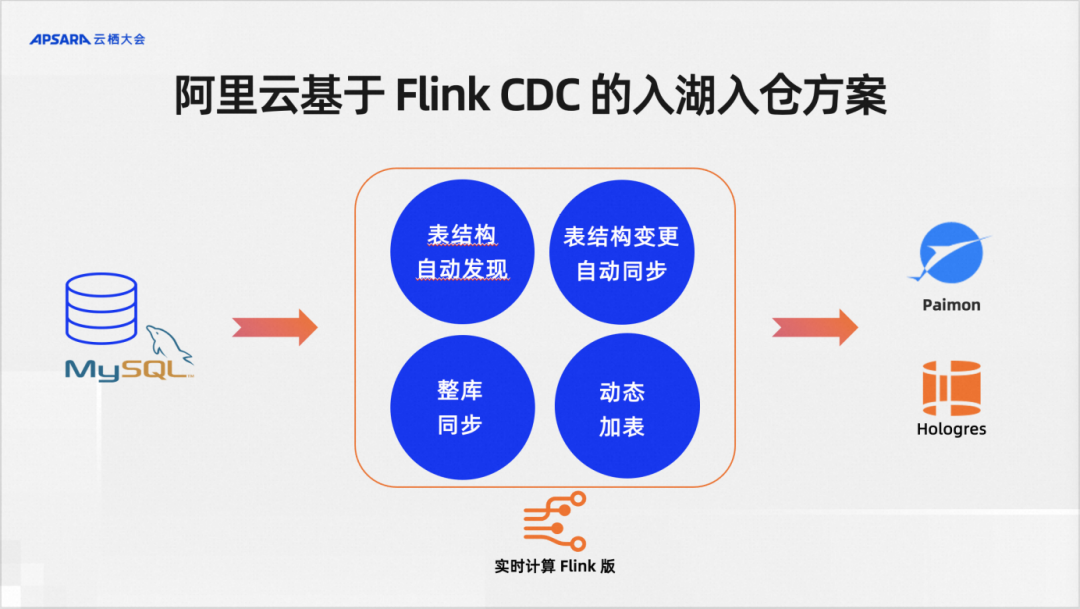
Flink CDC is a data integration framework. There is no separate Flink CDC product on Alibaba Cloud. It is our serverless Flink, which is the Alibaba Cloud real-time computing Flink version that provides the above capabilities. In addition to the real-time computing Flink version, another Alibaba Cloud product, Dataworks, also provides a Flink-based CDC data integration solution.
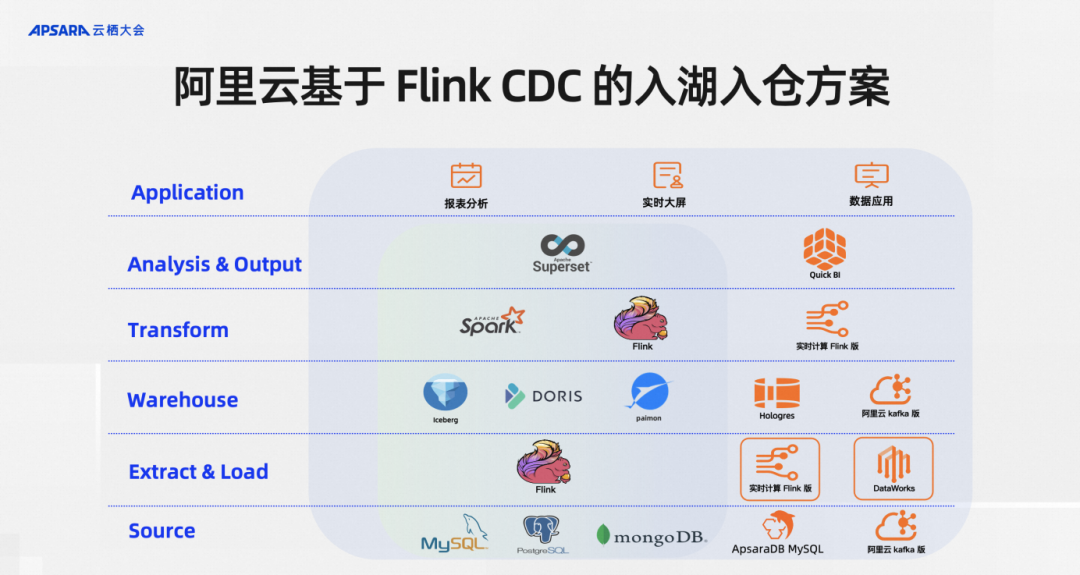
According to the layered concept of modern data stacks, Flink CDC is located in the EL layer, and the division of labor is particularly clear. The bottom layer is the data source. Flink CDC focuses on data integration and is responsible for E and L in the ELT data integration model. Of course, in practice, it will also support some lightweight T, which is the Transform operation.

In the Alibaba Cloud real-time computing Flink version, we designed two syntactic sugars, namely CDAS (Create Database As Database) and CTAS (Create Table As Table). CDAS achieves synchronization of the entire database through one line of SQL. For example, if there is a TPS DS database in MySQL, it can be synchronized to Paimon's ODS database. At the same time, I also provide CTAS. For example, when dealing with the key business of sub-database and sub-table, a single table may be merged into some sub-databases and sub-tables, merged into Paimon to make a large wide table, etc., multiple tables can be combined into one table logic. This table will also do some things, such as deriving the widest table structure, and after the table structure of the sub-table changes, the corresponding table structure must also be synchronized in the widest downstream table. These are implemented through CTAS .

The final effect is that users only need to write a line of SQL in real-time calculation Flink. A lot of work is actually done under this line of SQL. The final effect is to pull up a Flink data integration job. As you can see in the picture above, there are four nodes in the job topology. The first node is the source node that reads MySQL. The next three nodes correspond to the three tables in our red box, and three are automatically generated. sink node. For users, just writing a line of SQL can achieve fully incremental and integrated CDC data integration.
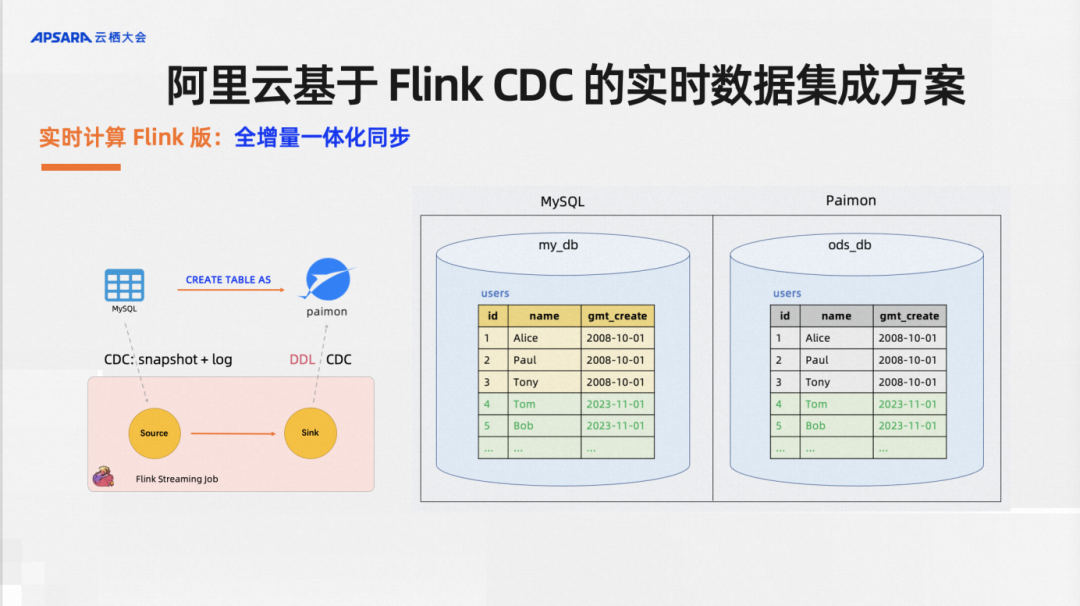
The real-time computing Flink version provides default support for full incremental integrated synchronization. For example, I have some historical full data and incremental data. A CTAS syntax supports full and incremental data synchronization by default. Of course, you can also choose to synchronize only full or only all incremental data by configuring different parameters.
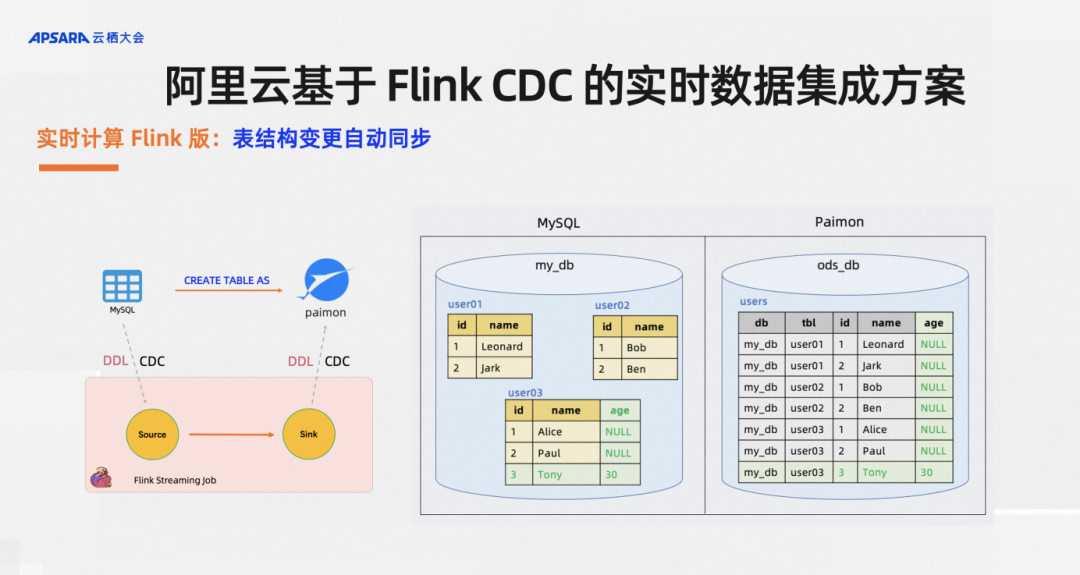
The real-time computing Flink version also supports table synchronization changes. For example, there is a scenario of sub-database and sub-table. There is a table named user03 in the library. The business classmate adds a new field age, and there is an additional field in the records inserted later. For the age field, the effect the user wants is to automatically add columns to the downstream lake warehouse, and new data can be automatically written. For such requirements, CTAS/CDAS syntax is supported by default.
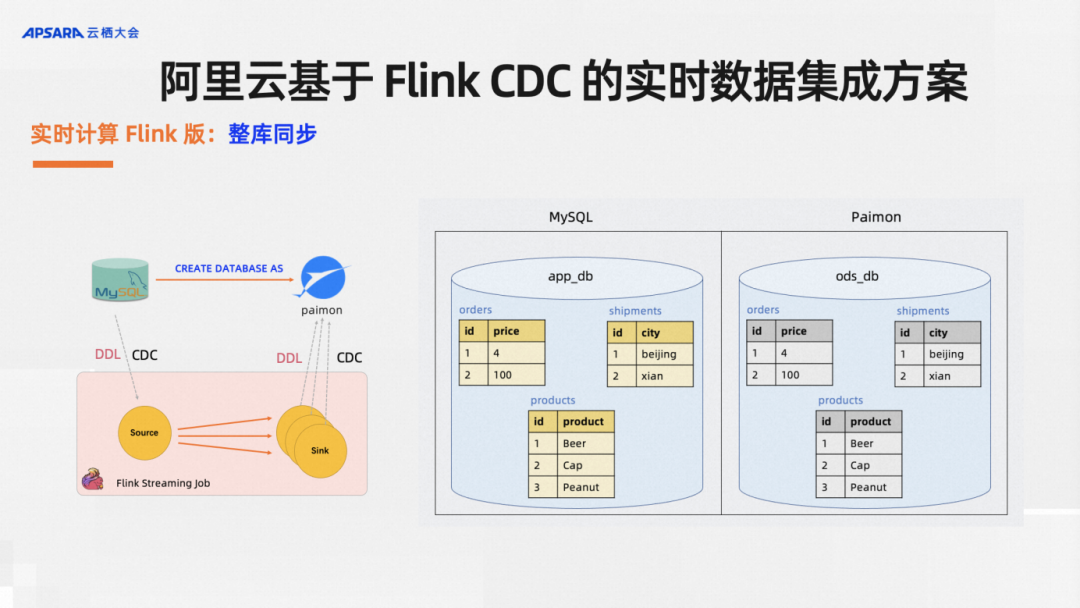
The real-time computing Flink version supports synchronization of the entire database. For single-table synchronization, each table synchronization requires writing a line of SQL, which is still too laborious for users. What users want is to be as simple as possible and as powerful as possible. CDAS syntax sugar is here to help. Users do this. For example, if there are several tables in the original database, and only one line of SQL needs to be written, I can automatically rewrite multiple CTAS statements by capturing all the tables in the database, and then synchronize them to the downstream, and each table supports automatic synchronization of table structure changes. The three source tables can add and delete columns respectively, and the data in the downstream Paimon can automatically add and delete columns and synchronize them.

The real-time computing Flink version also supports dynamic addition of tables for synchronous jobs. In the current context of cost reduction and efficiency improvement in the IT industry, saving resources as much as possible can significantly reduce business costs. In the CDC data integration scenario, for example, in one of my previous jobs, there were 1,000 tables in the business database. I used a 5CU resource job to synchronize the data. If two tables are added to the business database, should I start a new job or add the tables to the original job? This is the dynamic table addition function we developed. It can directly reuse the state and resources of the original job without opening the resources of a new job, and dynamically add tables to historical jobs. The effect of this function is shown in the figure above: There were three tables in the MySQL database before, and now one table has been added. This historical synchronization job supports the synchronization of the newly added table. This is the dynamic table addition of the synchronization job.
The above-mentioned functions are some real-time integration solutions for enterprise-level CDC data that we have implemented within Alibaba Cloud and have achieved good business results. User feedback on data integration has also been relatively good. We share this solution in the hope that we can communicate with colleagues and friends, and hope that everyone can gain something from it.
Real-time data integration Demo demonstration
Demo viewing address:
https://yunqi.aliyun.com/2023/subforum/YQ-Club-0044 Open source big data special replay video 02:28:30 - 02:34:00 time period
Here, I recorded a Demo to demonstrate the above functions. This Demo shows the CDC data integration from MySQL to the Streaming Lakehouse Paimon just introduced. I will show you how to efficiently implement the entire database synchronization and Schema in the real-time computing Flink version. evolution, and reuse historical jobs to implement dynamic table addition.
First, we create a MySQL Catalog, which can be created by clicking on the page, and then create a Paimon Catalog. After creating this Catalog, you can write SQL. In fact, there are several parameter settings that can be left unset. The setting here is for faster demonstration. Let’s write a CDAS statement first. The first statement is to synchronize two tables, the order table and the product table. Submit the job. I just want to synchronize the orders and products in the library to Paimon. After submitting this job, wait a moment and synchronize the Flink job of the two tables. It is generated. We can start another job on the console. This job can pull out the data in Paimon for everyone to see. For example, the data in the order table is the same as the data in our upstream MySQL, and is synchronized in real time. A row of data is immediately inserted into MySQL. Now I go to Paimon to look at the inserted data, and I can actually see it. This end-to-end delay is very low. At the same time, it can demonstrate a table structure change function. Add a new column from the source table. The user does not need to do any operations. In the downstream Paimon, the corresponding table structure changes in the data lake will be automatically to the Paimon target table. A column was created upstream, and now another column is inserted. For example, a piece of data is inserted, and there is a column with a new value. I insert this row of data. Next, let's take a look at the corresponding table in our Paimon. You can see that the data in the last row with the new column has been inserted.
Next, I will demonstrate to you our function of dynamically adding tables. This is a major feature that we have recently launched on Alibaba Cloud. In a job, only the order table and product table were synchronized before. Now the user wants to add a logistics table. For the user, he only needs to change the previous SQL and add an additional table name. Let's first take a look at the data in the logistics table upstream of MySQL. Users only need to make a Savepoint for the job, add the name of the logistics table, and restart the job. Why we restart from Savepoint is because Savepoint retains some necessary metadata information. Before synchronizing two tables, and now adding a table, the framework will do some verification and add the new table to make an automatic Synchronization, it is worth noting that in this function, we can ensure that the synchronization data of the original two tables continues to flow and continue to be synchronized, and the new table supports full incremental integrated synchronization. The current job has a third table, which is the synchronization of the new logistics table. We can also check it through Flink in Paimon. We can see that the data in the table has been synchronized. Not only the full data, but also the incremental data of the newly added table can be synchronized in real time. The delay is also very low. This is due to the end-to-end low latency provided by the CDC framework and the Flink overall framework.
That’s it for the overall demo. From this demo, you can see that our practical solution for data integration in Alibaba Cloud is more user-oriented. Starting from the end-end data integration users, we try to shield Flink, DataStream or Java API for users. Even the concept of SQL makes the user's operation as simple as possible. For example, he can click on the page to create a Catalog, and then write a few simple lines of SQL to achieve CDC data integration. In addition, we also have some synchronization job templates. For synchronization templates, users do not need to write SQL. They can edit a CDC data integration job by clicking directly on the page. Overall, one of our core concepts in product design is to be oriented to end users of data integration, rather than to community contributors and developers. This will be more conducive to promoting our solution to more users.
Microsoft launches new "Windows App" Xiaomi officially announces that Xiaomi Vela is fully open source, and the underlying kernel is NuttX Vite 5. Alibaba Cloud 11.12 is officially released. The cause of the failure is exposed: Access Key service (Access Key) anomaly. GitHub report: TypeScript replaces Java and becomes the third most popular. The language operator’s miraculous operation: disconnecting the network in the background, deactivating broadband accounts, forcing users to change optical modems ByteDance: using AI to automatically tune Linux kernel parameters Microsoft open source Terminal Chat Spring Framework 6.1 officially GA OpenAI former CEO and president Sam Altman & Greg Brockman joins Microsoft