1. Background introduction
In the OLTP system, in order to solve the problem of a large amount of data in a single table, the method of sub-database and table is usually used to split a single large table to improve the throughput of the system.
However, in order to facilitate data analysis, it is usually necessary to merge the tables split from the sub-database and sub-tables into a large table when synchronizing to the data warehouse or data lake.
This tutorial will show how to use Flink CDC to build a real-time data lake to deal with this scenario. The demonstration in this tutorial is based on Docker and only involves SQL. There is no need for a line of Java/Scala code, and no need to install an IDE. Complete the entire content of this tutorial on the computer.
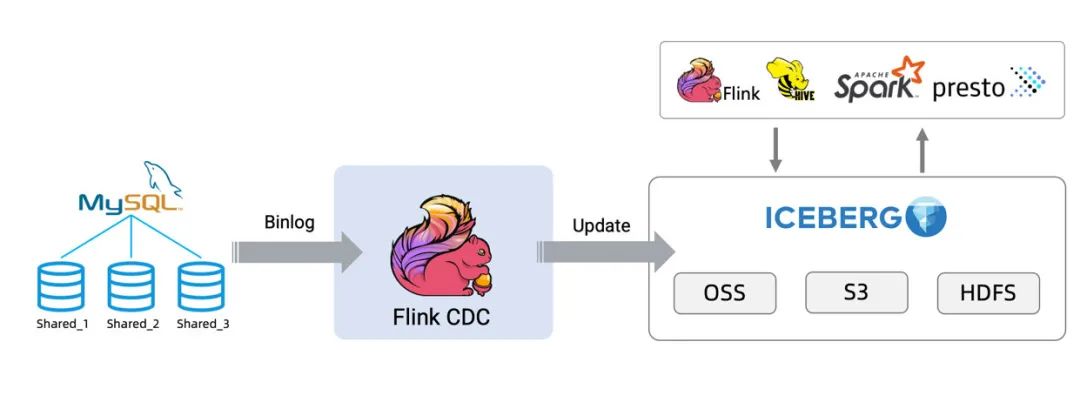
Next, the whole process will be shown by synchronizing data from MySQL to Iceberg[1] as an example. The architecture diagram is as follows:
1. MySQL data in the preparation stage
1.2 Prepare data
Enter the MySQL container:
Create two different databases, and create two tables in each database as usertables split under table sub-database sub-table.
CREATE DATABASE db_1;
USE db_1;
CREATE TABLE user_1 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234","[email protected]");
CREATE TABLE user_2 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_2 VALUES (120,"user_120","Shanghai","123567891234","[email protected]");CREATE DATABASE db_2;
USE db_2;
CREATE TABLE user_1 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234", NULL);
CREATE TABLE user_2 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_2 VALUES (220,"user_220","Shanghai","123567891234","[email protected]");2. In the Flink SQL CLI
Create tables using Flink DDL
1. Flink sql enable checkpoint
Checkpoint is not enabled by default, we need to enable Checkpoint to allow Iceberg to submit transactions . Moreover, mysql-cdc needs to wait for a complete checkpoint before the binlog reading phase starts to avoid out-of-order binlog records.
-- 每隔 3 秒做一次 checkpointFlink SQL> SET execution.checkpointing.interval = 3s;
2. Flink sql creates MySQL sub-database and sub-table source table
Create a source table user_sourceto capture the data of all tables in MySQL , and use regular expressions to match these tables in userthe configuration items of the table . Moreover, the table also defines a metadata column to distinguish which database and table the data comes from.database-nametable-nameuser_source
Flink SQL> CREATE TABLE user_source (
database_name STRING METADATA VIRTUAL,
table_name STRING METADATA VIRTUAL,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'db_[0-9]+',
'table-name' = 'user_[0-9]+'
);3. Flink sql creates Iceberg sink table
Create a sink table all_users_sinkto load data into Iceberg. In this sink table, considering that the values of fields in different MySQL database tables idmay be the same, we define a composite primary key ( database_name, table_name, id).
Flink SQL> CREATE TABLE all_users_sink (
database_name STRING,
table_name STRING,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED
) WITH (
'connector'='iceberg',
'catalog-name'='iceberg_catalog',
'catalog-type'='hadoop',
'warehouse'='file:///tmp/iceberg/warehouse',
'format-version'='2'
);
3. Streaming to Iceberg
1. Use the following Flink SQL statement to write data from MySQL to Iceberg:
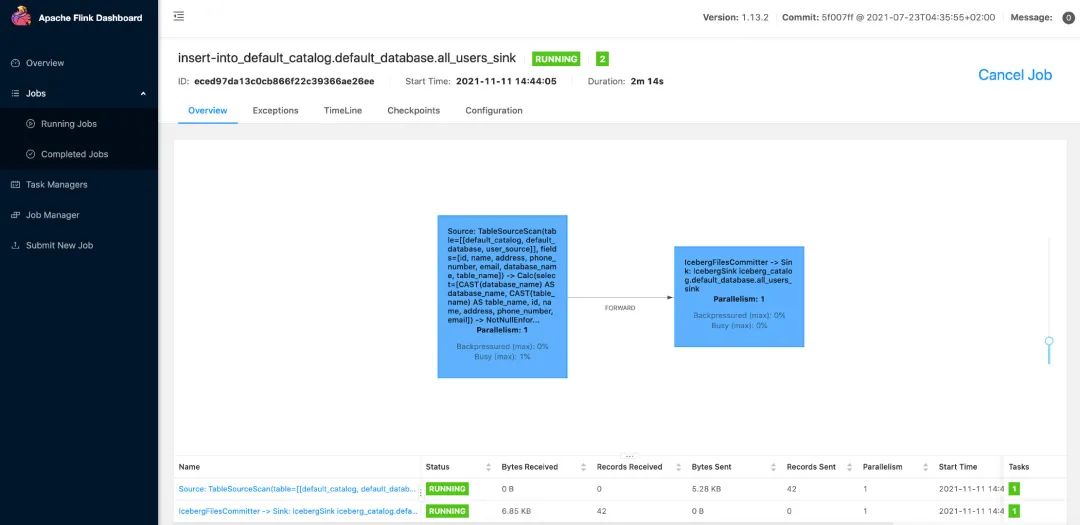
Flink SQL> INSERT INTO all_users_sink select * from user_source;
The above command will start a streaming job to continuously synchronize the full and incremental data in the MySQL database to Iceberg. This running job can be seen on the Flink UI (http://localhost:8081/#/job/running):
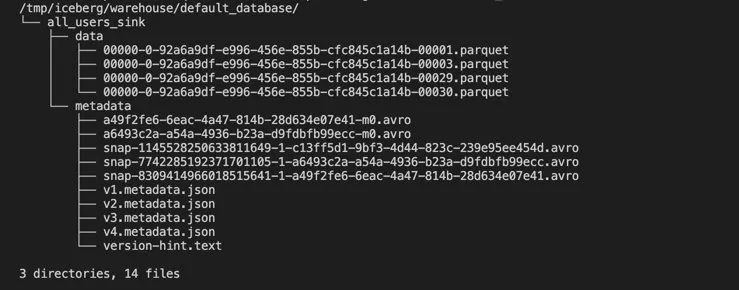
Then we can use the following command to see the written files in Iceberg:
docker-compose exec sql-client tree /tmp/iceberg/warehouse/default_database/As follows:
. Use the following Flink SQL statement to query all_users_sinkthe data in the table:
Flink SQL> SELECT * FROM all_users_sink;In the Flink SQL CLI, we can see the following query results:

all_users_sinkModify the data in the table in MySQL, and the data in the table in Iceberg will also be updated in real time:
In this article, we show how to use Flink CDC to synchronize the data of MySQL sub-database and sub-table, and quickly build an Icberg real-time data lake. Users can also synchronize data from other databases (Postgres/Oracle) to data lakes such as Hudi. Finally, I hope that this article can help readers get started with Flink CDC quickly.