
1. Background introduction
GoldenEye PAAS data service is a series of data services that implement the same indicator service agreement. Each service is divided according to the theme of the indicators produced. For example, the real-time transaction service provides the query of real-time transaction indicators, and the financial offline service provides the query of offline financial indicators. GoldenEye PAAS data service supports the data query needs of GoldenEye APP, GoldenEye PC and various internal large screens. In order for the business to conduct correct data insights and decisions, it is necessary to ensure the accuracy of the data provided by PAAS-based data services .
With the rapid iteration of business requirements, data services often need to adjust query caliber, query dimensions, and query indicators. Therefore, efficient automated regression testing methods are needed to ensure the quality of each requirement iteration. Automated testing of PAAS data services faces some problems:
In response to the diversity of request scenarios and the particularity of the indicator service protocol, we implemented a dedicated DIFF tool for GoldenEye PAAS data services. By recording online traffic, then playing it back in the test and online environments, comparing the returned results, and Request playback efficiency and comparison result false positive issues have been specifically optimized. This method can ensure full coverage of online query scenarios, reduce manual intervention in manually constructing request scenarios, and provide sufficiently efficient automated regression testing capabilities to empower R&D self-testing.
After a period of construction and iteration, GoldenEye's PAAS-based data service DIFF tool has achieved coverage of GoldenEye's three services: real-time trading, offline trading, and offline finance, with an average monthly DIFF execution count of more than 40 times.
The following article will introduce the challenges and practical experiences encountered in the construction of GoldenEye PAAS-based data service DIFF tools.
2. Problems and ideas
2.1 Difficulties in calling PAAS protocols
GoldenEye PAAS services all implement the same indicator service protocol. The request parameter is a complex nested object, and each filter condition object in the criteria collection uses Jackson's @JsonSubTypes annotation to implement polymorphic parsing. According to the JSF team's http call document, calling an interface with complex nested objects requires adding "@type": "package path + class name" to each nested object, and it is recommended to use JSON.toJSONString (instance, SerializerFeature.WriteClassName ) generates a JSON string with type characteristics, as shown in the figure below. Before generation, Jackson must be used to deserialize the request parameters into instance objects. If you insist on using http method to call this kind of JSF interface in a python script, you need to identify the implementation class of each filter condition yourself . In order to realize the convenient calling of PAAS data service JSF interface, the DIFF tool written in java was born.

2.2 Main challenges
The DIFF tool written in Java can solve the problem of PAAS-based data service interface calling, but in the actual use of existing DIFF scripts, it faces the following two challenges:
2.2.1 Request playback efficiency issues
Single thread playback
The interface call and result comparison of the recorded requests are implemented by a single thread traversing the request list. After a single request successfully calls the interface of the online and test environments, the returned results are compared. Only after the comparison is completed Just go back to the next request. But in fact, there is no calling sequence between the playback of the previous request and the next request. This method of using a single thread for request playback will greatly reduce the execution efficiency and cause the diff execution time to be too long.
Synchronous call interface
In addition, the calls to the online and test environment interfaces are synchronized. After the interface of one environment returns a result, the next interface is called. In the same way, there is no dependency between the interface calls of the two environments. The return value of one environment interface will not affect the call of the next interface. You only need to ensure that both environment interface calls have return values, and then compare the results. Can.
2.2.2 The problem of false positives in comparison results
Indexes are inconsistent
The return parameter structure of the PAAS protocol is as follows. It can be seen that the body.data data set has the most information elements and is the main comparison target. The meteData.metaIndex data index defines the specific fields represented by each value in the data set sub-elements. Name, for example, the three values in [1234,12345.41,"11068"] respectively represent the transaction parent order volume, transaction amount and main brand ID. If the return value field name indexes of the two environment interfaces are not consistent, but the values corresponding to the field names actually obtained according to the index are the same, in this case, directly traversing the data collection sub-collection for comparison, you will get a different conclusion. But in fact, the two return values are consistent, which leads to false positives in the comparison results, as shown in the figure below.
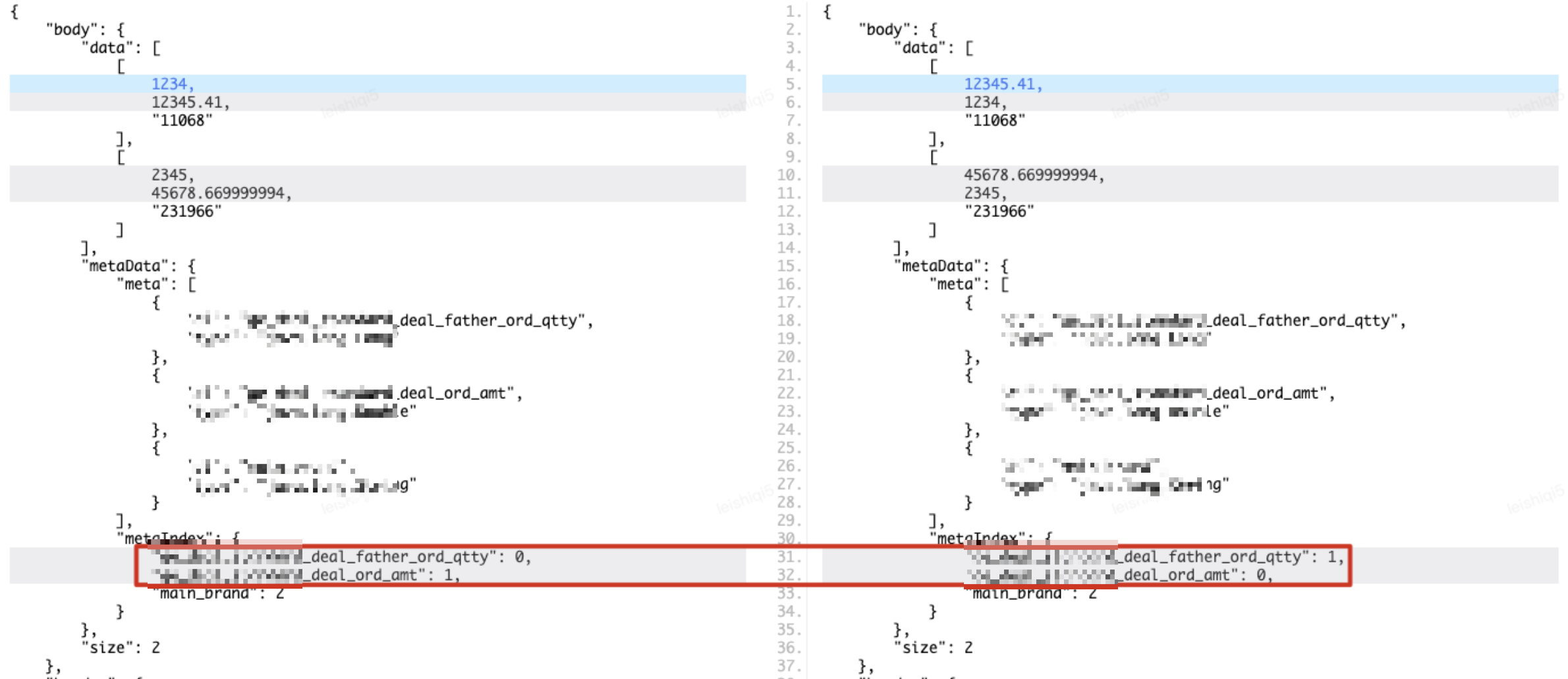
unordered array
In addition to inconsistent field name indexes, which can lead to false positives in comparison, each sub-collection of the data set data may be out of order. In the return parameter data of the example, the first sub-collection contains two indicators of the main brand "11068", and the second sub-collection contains two indicators of the main brand "231966". If the return parameter data of another environment interface, the The main brand of one sub-collection is "231966", and the main brand of the second sub-collection is "11068". Direct traversal and comparison in this case will lead to differences in the comparison results, but in fact it is also a false positive.

2.3. Solution ideas
2.3.1 Concurrency during traversal requests and asynchronous during traffic playback to solve the problem of request playback efficiency
From the analysis in the main challenge, it can be seen that the time consumption of a DIFF execution = the number of requests that need to be played back * (the time consumption of interface calls in the two environments + the time consumption of comparison). It can be seen from the time-consuming splitting formula that optimizing the efficiency of DIFF execution can be achieved in two directions: requesting parallel playback and asynchronous interface calling.
2.3.2 Field index unification and secondary sorting are implemented to solve the problem of false positives in comparison results
For the structure of PAAS protocol return parameters, in order to achieve zero false positives in the comparison results, it is necessary to ensure the unification of the return value field indexes of the two environments and the ordering of the sub-collections within the data set, so that when comparing the return value results, There will be no contrast abnormalities.
The unified implementation of field index is relatively simple. Based on the field index metaIndex of the return value of one environment interface, re-arrange the position of each value in the data sub-collection in the return value of another environment interface to ensure that each value in the data sub-collection is traversed. , the corresponding field names are consistent.
Secondary sorting is to solve the order problem between data sub-sets. The reason why the emphasis is on "secondary" is because the sub-set may contain multiple values. If only one value is sorted, the sub-set cannot be completely guaranteed. Therefore, it is necessary to implement a secondary sorter to select multiple values in the sub-set as the basis for sorting , so as to make the order between sub-sets stable and ensure the reliability of the comparison results.
3. Overall structure

4. Core design points
4.1 Request playback efficiency optimization
4.1.1 Request deduplication before playback
Before building the data service DIFF tool, one goal was to " make every playback request meaningful ." For read-only data query services, there will be a large number of repeated requests every day. If the requests are not deduplicated, a large part of the playback requests will be repeated. Such requests will be used for playback and DIFF, which not only wastes resources , interfering with the summary of final comparison results, has no meaning yet. Therefore, deduplication processing before requesting playback is necessary.
Initially, the request parameter deduplication method adopted by the DIFF tool is the HashSet method. Before calling the interface to play back the traffic, the request deduplication is saved in a HashSet. After the deduplication is completed, the HashSet is traversed for traffic playback and DIFF execution. Although this method can effectively remove duplicates, in actual use, if the number of requests that require diff is too large or the request parameters are too large (such as querying the financial indicators of a specified 2000 SKUs), then the HashSet deduplication efficiency is relatively low, and the traversal Deduplication of 50,000 large requests takes more than 10 minutes and takes up a lot of memory. If the memory of the pipeline container that executes DIFF is small, the DIFF execution will fail directly.
In order to improve the deduplication efficiency of requests, the Bloom filter method is used to achieve deduplication. The memory occupied is smaller than the HashSet method, and the efficiency of determining whether there are duplicates is also relatively high. It is suitable for deduplication operations of large amounts of data .
for (int i = 0; i < maxLogSize; i++) {
String reqParam = fileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//请求重复,跳过此请求
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//请求不重复,执行接口调用和DIFF
}4.1.2 Concurrency when traversing requests
When traversing requests, use the execute() method to submit request playback and DIFF execution tasks to the thread pool. Each request will generate an independent task, and tasks will be executed in parallel, improving the execution efficiency of the entire DIFF process. Since DIFF needs to perform the summary and display of comparison differences after each request for playback and result comparison is completed, the main thread needs to be blocked and wait for all playback comparison task sub-threads to end before starting the main thread to perform summary analysis of difference results.
In order to meet the calling timing requirements between the main and sub-threads , the CountDownLatch counter is used. The maximum number of requests n is set during initialization. Whenever a sub-thread ends, the counter is decremented by one. When the counter becomes 0, the main thread that has been awaiting wakes up and summarizes the difference results. .
This again involves the issue of thread pool rejection policy. If you use the thread pool's default AbortPolicy policy, but do not catch exceptions and decrement the counter by one during exception handling, then when the thread pool cannot accept new tasks, the CountDownLatch counter will never be 0, the main thread is always blocked, and the DIFF process will never end. In order to enable DIFF to execute smoothly and output comparison results under abnormal circumstances, and to ensure that every request can be played back and compared, CallerRunsPolicy is used here to return rejected tasks to the caller for execution.
//初始化计数器
CountDownLatch countDownLatch = new CountDownLatch(maxLogSize);
log.info("开始读取日志");
for (int i = 0; i < maxLogSize; i++) {
String reqParam = asciiFileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//有重复请求,跳出本次循环,计数器减一
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//向线程池提交回放和对比任务
threadPoolTaskExecutor.execute(() -> {
try {
//执行接口调用和返回结果对比
}
} catch (Exception e) {
} finally {
//子线程一次执行完成,计数器减一
countDownLatch.countDown();
}
});
}
//阻塞主线程
countDownLatch.await();
//等待计数器为0后,开始汇总对比结果4.1.3 Asynchronous when requesting playback
JSF provides an interface asynchronous calling method, returning a CompletableFuture<T> object. You can easily use the thenCombine method to combine the test environment interface and the return value of the test environment interface call, perform comparison of the return values, and return the comparison result.
//测试环境接口异步请求
CompletableFuture<UResData> futureTest = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceTest.fetchBizData(param)
);
//线上环境接口异步请求
CompletableFuture<UResData> future = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceOnline.fetchBizData(param)
);
//使用thenCombine对futureTest和future执行结果合并处理
CompletableFuture<ResCompareData> resultFuture = futureTest.thenCombine(future, (res1, res2) -> {
//执行对比,返回对比结果
return resCompareData;
});
//获取对比结果的值
return resultFuture.join();4.2 False alarm rate optimization
4.2.1 Field index unification
The core of field index unification is to find the mapping relationship between the same field name index between two return values . For example, the index index1 of field name a in return value A corresponds to the index index2 of field name a in return value B. After all mapping relationships are found, the order of the fields in the return value array B is rearranged.
List<List<Object>> tmp = new ArrayList<>();
int elementNum = metaIndex1.size();
HashMap<Integer, Integer> indexToIndex = new HashMap<>(elementNum);
//获取索引映射关系
for (int i = 0; i < elementNum; i++) {
String indicator = getIndicatorFromIndex(i, metaIndex2);
Integer index = metaIndex1.get(indicator);
indexToIndex.put(i, index);
}
//根据映射关系重新排放字段,生成新的数据集合
for (List<Object> dataElement : data2) {
List<Object> tmpList = new ArrayList<>();
Object[] objects = new Object[elementNum];
for (int i = 0; i < dataElement.size(); i++) {
objects[indexToIndex.get(i)] = dataElement.get(i);
}
Collections.addAll(tmpList, objects);
tmp.add(tmpList);
}4.2.2 Secondary sorting of data sets
The data set data contains multiple sub-sets, and each sub-set is a combination of attribute values and indicators. In order to achieve ordering between sub-collections, it is necessary to find the indexes of all attribute fields and implement a secondary sorter that uses the values of all attribute fields as the sorting criterion.
Generally speaking, the data type of attribute fields is String type, but there are also special cases. For example, if sku_id is used as the attribute value, then the data type returned by sku_id is Long type. In order to realize the universality and reliability of the secondary sorter, first use all String type fields to sort, and then use Long type fields to sort. If there is no String type field, then all Long type fields are sorted.
List<Integer> strIndexList = new ArrayList<>();
List<Integer> longIndexList = new ArrayList<>();
// 保存所有String和Long类型字段的索引
for (int i = 0; i < size; i++) {
if (data.get(0).get(i) instanceof String) {
strIndexList.add(i);
}
if (data.get(0).get(i) instanceof Long || data.get(0).get(i) instanceof Integer) {
longIndexList.add(i);
}
}
//首选依据String类型字段排序
if (!strIndexList.isEmpty()) {
//初始化排序器
Comparator<List<Object>> comparing = Comparator.comparing(o -> ((String) o.get(strIndexList.get(0))));
for (int i = 1; i < strIndexList.size(); i++) {
int finalI = i;
//遍历剩余String字段,实现任意长度次级排序器
comparing = comparing.thenComparing(n -> ((String) n.get(strIndexList.get(finalI))));
}
for (int i = 0; i < longIndexList.size(); i++) {
int finalI = i;
comparing = comparing.thenComparingLong(n -> Long.parseLong(n.get(longIndexList.get(finalI)).toString()));
}
sortedList = data.stream().sorted(comparing).collect(Collectors.toList());
}4.3 PAAS data service DIFF effect
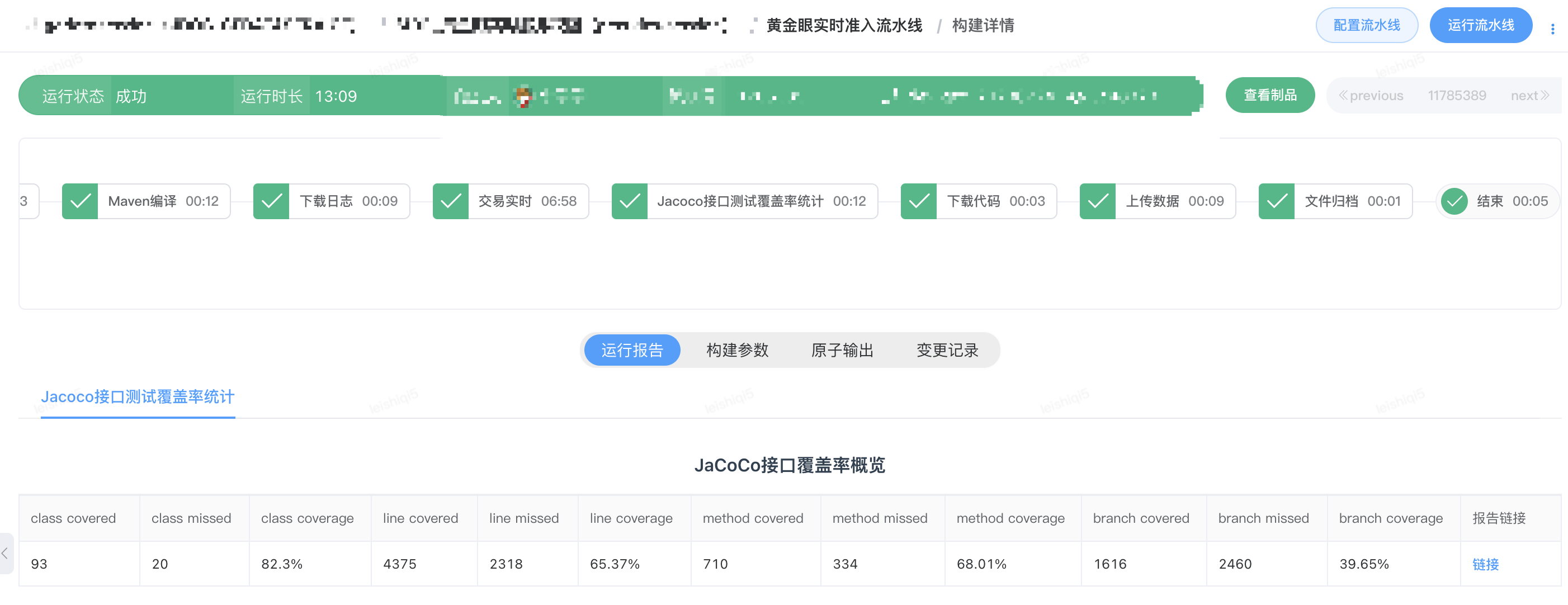
After optimizing the request playback efficiency and false alarm rate, the time consumption and comparison results of a DIFF execution of the data service can meet the needs of existing R&D self-tests and regression before going online. The figure below shows a DIFF report of the GoldenEye trading real-time service. Under the configuration of four working threads, after 40,000 requests were deduplicated, the request playback took 570 seconds. The comparison results can also clearly show the data differences. In order to facilitate the investigation of data differences, when displaying the difference comparison results, the field names are spliced before the values to avoid manually searching for the field names corresponding to the difference values based on the index.

5. Implementation
5.1 Data service test access pipeline
The pipeline provides download code atoms, compilation atoms, and Shell custom script atoms. These three atoms can trigger the execution of DIFF tasks. With the help of this ability of the pipeline, the ability of DIFF tools has been introduced into the test access pipeline of GoldenEye GoldenEye trading real-time and trading offline data services. The test access pipeline includes the compilation and JDOS deployment of test branch codes, traffic playback and execution result comparison, and interface test coverage statistics during the DIFF process. Through online traffic playback for DIFF testing, the line coverage of transaction offline service and real-time service code reached 51% and 65% respectively .

Transaction offline service test access pipeline
Transaction real-time service test access pipeline
5.2 Service R&D self-test to improve efficiency
In addition to the DIFF tool playing a role in the test admission pipeline, we have also set up a pipeline that can manually trigger DIFF to empower R&D self-tests and improve efficiency. At present, the DIFF pipeline has been implemented in multiple data services of GoldenEye PAAS, including transaction offline service, real-time transaction service and financial offline service. The figure below shows the monthly execution times of the DIFF pipeline of these three data services. The cumulative execution times in September are : 66 times DIFF .

*Data source: Pipeline execution trend statistics
At present, the DIFF tool already has the ability to customize the difference rate threshold, filter and exclude keywords, and customize filter conditions and request indicators for PAAS requests of indicator services. This customization capability for PAAS-based requests for indicator services plays a certain role in daily demand iteration and technical transformation.
For example, the GoldenEye trading real-time service query engine was switched from Elasticsearch to Doris. This transformation involved a lot of DIFF regression testing work. During this process, R&D found that there are some differences in the calculation methods of Elasticsearch and Doris for deduplication indicators (such as sub-item quantities). As a result, the difference rate of deduplication indicators queried using the two engines will be higher than that of other non-deduplication indicators. Indicators (such as amount), this will interfere with the display of the final comparison results and is not conducive to discovering truly different requests. In order to solve this problem, we provide the ability to customize the indicator service PAAS-based request indicators . You can set the playback request to query only non-deduplication indicators, avoiding the interference of deduplication indicators, and promoting the progress of regression testing.
6. Summary
This article introduces the two major problems of DIFF efficiency and comparison result reliability faced by the GoldenEye data quality team during the construction of the data service DIFF tool. It also elaborates on the solutions and practical experience in implementing the above two types of problems and corresponding challenges respectively.
6.1 Advantages of customized DIFF tools
Compared with JD.com’s internal professional recording and playback platform R2, our DIFF tool is far insufficient or missing in terms of traffic recording, link tracking, versatility and other capabilities. However, from the perspective of PAAS data service DIFF customization, the optimization made by our DIFF tool in the request customization and comparison process is currently not supported by this universal platform.
6.2 Future prospects
At present, the DIFF tool is used for automated regression testing. The code line coverage rate of the interface test of GoldenEye trading offline service and real-time service is about 50% , which shows that daily online query scenarios cannot cover all code branches. In order to improve the code line coverage of the DIFF test, we will consider analyzing the coverage report later to find out the scenarios not covered by the online query and form a fixed set of request use cases. During the DIFF test, we will play back both the online traffic and the fixed request use cases. Set to improve the row coverage of DIFF testing.
Lei Jun: The official version of Xiaomi's new operating system ThePaper OS has been packaged. The pop-up window on the lottery page of Gome App insults its founder. Ubuntu 23.10 is officially released. You might as well take advantage of Friday to upgrade! Ubuntu 23.10 release episode: The ISO image was urgently "recalled" due to containing hate speech. A 23-year-old PhD student fixed the 22-year-old "ghost bug" in Firefox. RustDesk remote desktop 1.2.3 was released, enhanced Wayland to support TiDB 7.4 Release: Official Compatible with MySQL 8.0. After unplugging the Logitech USB receiver, the Linux kernel crashed. The master used Scratch to rub the RISC-V simulator and successfully ran the Linux kernel. JetBrains launched Writerside, a tool for creating technical documents.Author: JD Retail Lei Shiqi
Source: JD Cloud Developer Community Please indicate the source when reprinting