The advantages of setting an extra layer between the application and the hardware:
1. Makes programming easier and frees users from learning the low-level programming features of hardware devices
2. Greatly improves the security of the system, the kernel is trying to satisfy a request The correctness of such requests can be checked at the interface level.
3. The interface makes the program more portable
Unix systems implement most of the interfaces between user-mode processes and hardware devices by issuing system calls to the kernel.
POSIX APIs and system calls
API: a function definition that describes how to obtain a given service
System call: an explicit request to kernel mode through a softirq
Unix systems provide programmers with many API library functions. Some APIs defined by libc's standard C library refer to wrapper routines. Typically, each system call should correspond to a wrapper routine, and the wrapper routine defines the API used by the application.
An API does not necessarily correspond to a specific system call. First, the API may directly provide user-mode services. Secondly, a single API function may make several system calls. The Posix standard targets APIs rather than system calls. To determine whether a system is POSIX-compliant depends on whether it provides a suitable set of application programming interfaces, regardless of how the corresponding functions are implemented. In fact, some non-Unix systems are considered POSIX-compliant. Because they provide all the services that traditional Unix can provide in user-space library functions
From a programmer's perspective, the difference between APIs and system calls doesn't matter: the only relevant things are the function name, parameter types, and the meaning of the return code. From a kernel designer's point of view, this difference does matter, because system calls belong to the kernel, and user-mode library functions do not.
Most wrapper routines return an integer, the meaning of which depends on the corresponding system call. A return value of -1 usually indicates that the kernel cannot meet the process's requirements. The errno variable defined in the libc library contains specific error codes.
System call handlers and service routines
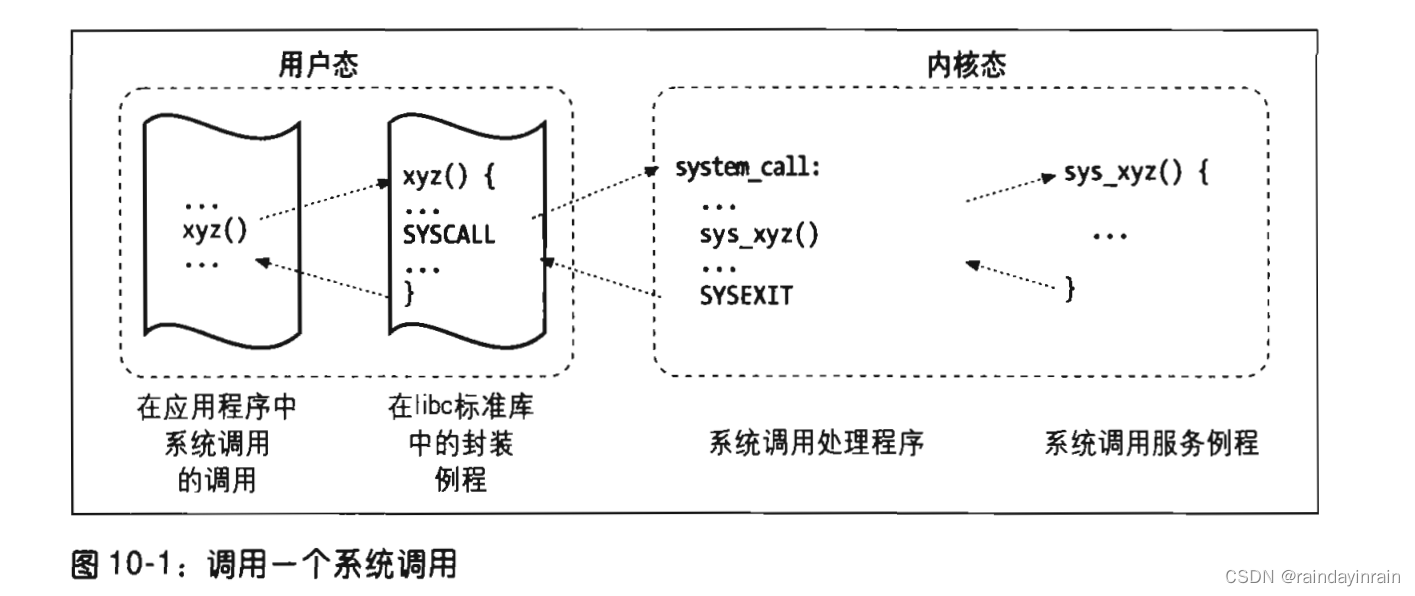
When a user-mode process makes a system call, the CPU switches to kernel mode and starts executing a kernel function. In the 80x86 architecture, Linux system calls can be called in two different ways. The end result of both methods is to jump to an assembly language function called a system call handler
Because the kernel implements many different system calls, the process must pass a parameter called the system call number to identify the required system call. The eax register is used for this purpose. When calling a system call, additional parameters are usually passed
All system calls return an integer value. These return values are different from the conventions of wrapper routine return values. In the kernel, a positive number or 0 indicates that the system call ended successfully, and a negative number indicates an error condition. In the latter case, this value is the negative error code stored in errno that must be returned to the application. The kernel does not set or use the errno variable, but the wrapper routine sets this variable after returning from the system call.
The system call handler has a similar structure to other exception handlers and executes:
1. Save the contents of most registers in kernel mode
2. Call the corresponding C function named the system call service routine to handle the system call
3. Exit the system call handler : Load the register with the value saved in the kernel stack, and the CPU switches from kernel mode back to user mode
To associate system call numbers with corresponding service routines, the kernel utilizes a system call dispatch table. This table is stored in the sys_call_table array and has NR_syscalls entries. The nth entry contains the address of the service routine with system call number n.
NR_syscalls is only a static limit on the maximum number of system calls that can be implemented, and does not represent the actual number of system calls that have been implemented. In fact, any entry in the dispatch table can also contain the address of the sys_ni_syscall function. This function is a service routine for the "unimplemented" system call, which simply returns the error code -ENOSYS
Entry and exit system calls
Local applications can adjust system calls in two different ways:
1. Execute int $0x80. In old versions of the Linux kernel, this is the only way to switch from user mode to kernel mode.
2. Execute sysenter. This instruction was introduced in Intel Pentium 2 and is supported by the Linux 2 and 6 kernels.
Similarly, the kernel can exit from the system call in two ways, thereby switching the CPU back to user mode:
1. Execute iret; 2. Execute sysexit.
But supporting two different ways of entering the kernel is not as simple as it seems.
1. The kernel must support both using only int $0x80; and sysenter.
2. The standard library using sysenter must be able to handle old kernels that only support int $0x80.
3. The kernel and standard library must run both on older processors that do not include the sysenter instruction and on newer processors that include it
Make a system call via int $0x80
Vector 128 corresponds to the kernel entry point. The function trap_init called during kernel initialization uses the following method to establish the interrupt descriptor table entry corresponding to vector 128:
set_system_gate(0x80, &system_call);
This call stores the following values into the corresponding fields of this gate descriptor:
Segment Selector
内核代码段__KERNEL_CS的段选择符
Offset
指向system_call系统调用处理程序的指针
Type
15,表示这个异常是一个陷阱。相应的处理程序不禁止可屏蔽中断
DPL
3,允许用户态进程调这个异常处理程序
When the user mode process issues int $0x80, the CPU switches to the kernel mode and starts executing instructions from the address system_call.
system_call
First, the system call number and all CPU registers available to this exception handler are saved to the corresponding stack, excluding eflags, cs, eip, ss and esp that have been automatically saved by the control unit. SAVE_ALL, discussed in Chapter 4, also loads the segment selectors for the kernel data segments in ds and es.
system_call:
pushl %eax
SAVE_ALL
movl $0xffffe000, %ebx
andl %esp, %ebx
Subsequently, this function stores the address of the thread_info of the current process in ebx. This is done by taking the value of the kernel stack pointer and rounding it to a multiple of 4KB or 8KB
Next, system_call checks whether one of TIF_SYSCALL_TRACE and TIF_SYSCALL_AUDIT in the flag field of the thread_info structure is set to 1, that is, it checks whether a debugger is tracking the execution program's call to the system call. If so, system_call calls do_syscall_trace twice: once just before the system call service routine is executed, and once after it. This function stops current and thus allows the debugger process to collect information about current.
Then, check the validity of the system call number passed by the user process. If this number is greater than or equal to the number of entries in the system call dispatch table, the system call handler terminates
cmpl $NR_syscalls, %eax
jb nobadsys
movl $(-ENOSYS), 24(%esp)
jmp resume_userspace
nobadsys:
If the system call number is invalid, this function stores the -ENOSYS value in the unit where the eax register was stored in the stack (the unit at offset 24 from the top of the current stack), and then jumps to resume_userspace. Thus, when the process resumes its execution in user mode, a negative return code will be found in eax. Finally, call the specific service routine corresponding to the system call number contained in eax
call *sys_call_table(0, %eax, 4)
Because each entry in the dispatch table occupies 4 bytes, the system call number is first multiplied by 4, and then added to the starting address of the sys_call_table dispatch table. Then the pointer to the service routine is obtained from this address unit, and the kernel finds the service routine to be called.
Exit from system call
When the system call service routine ends, system_call obtains its return value from eax and stores the return value in the stack location where the user mode eax register value was saved.
movl %eax, 24(%esp)
Therefore, the user mode process will find the return code of the system call in eax. System_call then turns off local interrupts and checks the flags in the thread_info structure of the current process
cli
movl 8(%ebp), %ecx
testw $0xffff, %cx
je restore_all
The offset of the flags field in the thread_info structure is 8. All flags are not set, and the function jumps to restore_all. restore_all restores the values of registers saved in the kernel stack and executes iret to restart the user mode process
As long as any of the flags are set, some work must be completed before returning to user mode. If TIF_SYSCALL_TRACE is set, system_call calls do_syscall_trace for the second time and then jumps to resume_userspace; otherwise, if TIF_SYSCALL_TRACE is not set, it jumps to work_pending. The code at resume_userspace and work_pending checks for rescheduling requests, virtual 8086 mode, suspend signals, single-step execution, and finally jumps to restore_all to resume the operation of the user mode process
Make system calls through sysenter
int is slow because it has to perform several consistency checks and security checks. The sysenter instruction, called "fast system call" in Intel documentation, provides a quick switching method from user mode to kernel mode.
sewing center
Three special registers are used, which need to be loaded with the following information
SYSENTER_CS_MSR
内核代码段的段选择符
SYSENTER_EIP_MSR
内核入口点的线性地址
SYSENTER_ESP_MSR
内核堆栈指针
When executing the sysenter instruction, the CPU control unit:
1. Copy the SYSENTER_CS_MSR content to cs
2. Copy the SYSENTER_EIP_MSR content to eip
3. Copy the SYSENTER_ESP_MSR content to esp
4. Load SYSENTER_CS_MSR plus 8 into ss
. Therefore, the CPU switches to the kernel state and start executing the first instruction of the kernel entry point
During kernel initialization, three model-specific registers are initialized by this function once each CPU in the system executes enable_sep_cpu. enable_sep_cpu execution:
1. Write the segment selector of the kernel code __KERNEL_CS into SYSENTER_CS_MSR
2. Write the linear address of the function sysenter_entry to be explained below into SYSENTER_CS_EIP
3. Calculate the linear address at the end of the local TSS and write this value into SYSENTER_CS_ESP. The setting of SYSENTER_CS_ESP requires some explanation. When the system call starts, the kernel stack is empty. Therefore, the esp register should point to the end of the 4KB or 8KB memory area. This memory area includes the kernel stack and the descriptor of the current process. Because the user-mode wrapper routine does not know the address of this memory area, it cannot set this register correctly. On the other hand, the value of this register must be set before switching to kernel mode. Therefore, the kernel initializes this register to address the local CPU's task status segment.
Each time the process switches, the kernel saves the kernel stack pointer of the current process to esp0 of the local TSS. In this way, the system call handler reads esp, calculates esp0 of the local TSS, and loads the correct kernel stack pointer into esp
vsyscall page
As long as both the CPU and Linux support sysenter, the wrapper functions in the standard library libc can be used. This compatibility issue requires a complex solution. Essentially, the initialization phase sysenter_setup creates a page frame called the vsyscall page. It includes a small EFL shared object (a small EFL dynamic link library). When the process issues execve to start executing an ELF program, the code in the vsyscall page will automatically be linked to the address space of the process. The code in the vsyscall page is used The most useful instructions make system calls
sysenter_setup allocates a new page frame for the vsyscall page and associates its physical address with the linear address of the FIX_VSYSCALL fixed mapping. The function sysenter_setup copies one or two predefined EFL shared objects to this page
1. If the CPU does not support sysenter, sysenter_setup creates a vsyscall page containing the following code
__kernel_vsyscall:
int $0x80
ret
2. Otherwise, if the CPU does support sysenter, sysenter_setup creates a vsyscall page including the following code
__kernel_vsyscall:
pushl %ecx
pushl %edx
pushl %ebp
movl %esp, %ebp
sysenter
When a package routine in the standard library must call a system call, it calls __kernel_vsyscall, regardless of its implementation code. The last compatibility issue is that older versions of the Linux kernel do not support sysenter. In this case, the kernel will certainly not create the vsyscall page, and the function __kernel_vsyscall will not be linked to the address space of the user mode process. When the new standard library recognizes this situation, it simply executes int $0x80 to adjust the system call.
Enter system call
When sysenter is used to issue a system call, the following is executed in sequence:
1. The package routine of the standard library loads the system call number into the eax register and calls __kernel_vsyscall
2. __kernel_vsyscall saves the contents of ebp, edx, and ecx to the user mode stack (system The call handler will use these registers), copy the user stack pointer to ebp, and execute sysenter
3. The CPU switches from user mode to kernel mode, and the kernel starts executing sysenter_entry (pointed to by SYSENTER_EIP_MSR)
4. sysenter_enter executes the following:
4.1. Establish the kernel Stack pointer, movl -508(%esp), %esp, initially, the esp register points to the first location of the local TSS, and the size of the local TSS is 512 bytes. Therefore, sysenter loads the contents of the field at offset 4 (esp0) in the local TSS into esp. esp0 always stores the kernel stack pointer of the current process.
4.2. Turn on local interrupt, sti.
4.3. Save the segment selector of the user data segment, the current user stack pointer, eflags, the segment selector of the user code segment and the address of the instruction to be executed when exiting from the system call to the kernel stack
pushl $(__USER_DS)
pushl %ebp
pushfl
pushl $(__USER_CS)
pushl $SYSENTER_RETURN
These instructions imitate some operations performed by int.
4.4. Restore the value of the register originally passed by the packaging routine to ebp, movl (%ebp), %ebp. The above instruction completes the restoration work, because __kernel_vsyscall stores the original value of ebp. Enter the user mode stack, and then load the current value of the user stack pointer into ebp
4.5. The system call handler is called by executing a series of instructions. These instructions are the same as the previous system call issued through the int $0x80 instruction. The instructions starting at system_call described in section 1 are the same.
exit system call
When the system call service routine ends, sysenter_entry essentially performs the same operation as system_call.
First, it obtains the return code of the system call service routine from eax and stores the return code in the kernel stack where the user mode eax register value is saved. The function then disables local interrupts and checks the flags in the current thread_info structure
If any flag is set, some work needs to be completed before returning to user mode. To avoid code duplication, the function jumps to resume_userspace or work_pending. Finally, the assembly language instruction iret takes five parameters from the kernel stack, so that the CPU switches to Anton user mode and starts executing the code at the SYSENTER_RETURN mark
If the sysenter_entry determination flag is cleared to 0, it quickly returns to user mode.
movl 40(%esp), %edx
movl 52(%esp), %ecx
xorl %ebp, %ebp
sti
sysexit
Load the pair of stack values saved by the sysenter_entry function in step 4c in the previous section to edx and ecx. edx gets the address of the SYSENTER_RETURN mark, and ecx gets the pointer of the current user data stack.
sysexit
sysexit is an instruction paired with sysenter. It allows quick switching from kernel mode to user mode. When executing this instruction, the CPU control unit performs the following: 1. Add 16 to the
value of SYSENTER_CS_MSR and load the result into cs
2. Load the contents of the edx register Copy to eip
3. Add 24 to the value in SYSENTER_CS_MSR and load the result into ss
4. Copy the contents of ecx to esp, because SYSENTER_CS_MSR loads the selector of the kernel code, and cs loads the selector of the user code, ss Selector for the loaded user data segment. As a result, the CPU switches from kernel mode to user mode and starts executing the instruction whose address is stored in edx.
SYSENTER_RETURN
Stored in the vsyscall page, when the system call entered through sysenter is terminated by iret or sysexit, the code in this page frame is executed. This code restores the original contents of the ebp, edx, and ecx registers saved in the user mode stack and returns control to the wrapper routine in the standard library.
SYSENTER_RETURN:
popl %ebp
popl %edx
popl %ecx
ret
Parameter passing
System calls usually may have input/output parameters, which may be actual values. It may also be a variable in the address space of the user-mode process, or even the data structure address of a pointer to a user-mode function, because system_call and sysenter_entry are the common entry points for all system calls in Linux. Therefore, each system call has at least one parameter, which is the system call number passed through the eax register. For example, if an application calls fork, eax is set to 2 before executing int $0x80 or sysenter. Because the value of this register is handled by a wrapper routine in libc, programmers usually do not care about the system call number. The fork system call requires no other parameters. However, many system calls do require additional parameters to be explicitly passed by the application. For example, mmap may require up to 6 additional parameters.
Ordinary C function parameter passing is done by writing parameter values to the active program stack. System calls are special functions that span the user and the kernel. Therefore, neither the user mode stack nor the kernel mode stack can be used. Before issuing a system call, the parameters of the system call are written to the CPU registers. Before calling the system call service routine, the kernel copies the parameters stored in the CPU to the kernel state stack. Because the system call service routine is an ordinary C function.
Why doesn't the kernel directly copy the user-mode stack to the kernel-mode stack?
1. It is complicated to operate two stacks at the same time.
2. The use of registers makes the structure of the system call handler similar to that of other exception handlers.
However, in order to pass parameters using registers, it must be satisfied:
1. The length of each parameter cannot exceed the register. The length of , that is, 32 bits
2. The number of parameters cannot exceed 6 (except the system call number passed in eax), because the number of registers of the 80x86 processor is limited
There do exist system calls with more than 6 parameters. In this case, a separate register points to a memory area in the process address space where these parameter values are located, and the programmer does not need to worry about this work area. When calling the wrapped routine, the parameters are automatically saved on the stack. The wrapper routine will find a suitable way to pass parameters to the kernel. The registers used to store system call numbers and system call parameters are: eax
: system call number, ebx, ecx, edx, esi, edi, ebp
system_call and sysenter_entry use SAVE_ALL Save these registers on the kernel mode stack. Therefore, when the system call service routine goes to the kernel stack, it will find the return address of system_call or sysenter_entry, followed by the parameters stored in ebx, the parameters stored in ecx, etc. A system call service routine is easily referenced by using C language constructs to reference its parameters, for example
int sys_write(unsigned int fd, const char * buf, unsigned int count)
int sys_fork(struct pt_regs regs)
The return value of the service routine must be written to the eax register. This is done automatically by the C compiler when executing the "return n;" instruction.
Validation parameters
Access process address space
System call service routines need to read and write data from the process's address space very frequently. Linux includes a set of macros to make this access easier. We will describe two of these macros named get_user() and put_user().
The first macro is used to read 1, 2 or 4 consecutive bytes from an address, while the second macro is used to write the contents of these sizes to an address. Both functions receive two parameters, a value x to be transferred and a variable ptr. The second variable also determines how many bytes are to be transferred. Therefore, in get_user(x, ptr), the size of the variable pointed to by ptr causes the function to expand into a __get_user_1(), __get_user_2(), or __get_user_4() assembly language function. Let's look at one of them, say, __get_user_2():
__get_user_2:
addl $1,%eax
jc bad_get_user
movl $0xffffe000, %edx /*or xxfffff000 for 4-kb stacks */
andl %esp,%edx
cmpl 24(%edx), %eax
jae bad_get_user
2: movzwl -1(%eax), %edx
xorl %eax, %eax
ret
bad_get_user:
xorl %edx, %edx
movl $-EFAULT, %eax
ret
The eax register contains the address ptr of the first byte to be read. The check performed by the first 6 instructions is actually the same as the access_ok() macro, which is to ensure that the address of the two bytes to be read is less than 4GB and smaller than the addr_limit.seg field of the current process (this field is located in the current thread_info structure). The shift amount is 24, which appears in the first operand of the cmpl instruction). If this address is valid, the function executes the movzwl instruction, stores the data to be read into the two low bytes of the edx register, sets the two high bytes to 0, and then sets the return code 0 in eax and terminates. If the address is invalid, the function clears edx, sets eax to -EFAULT and terminates. The put_user(x,ptr) macro is similar to the get_user discussed earlier, but it writes the value x into the process address space starting at address ptr.
Depending on the size of x, it uses the __put_user_asm() macro (size 1, 2, or 4 bytes), or the __put_user_u64() macro (size 8 bytes). These two macros return 0 in the eax register if the value is successfully written, otherwise they return -EFAULT. Table 10-1 lists several other functions or macros used to access the process address space in kernel mode. Note that many functions or macros have their names prefixed with two underscores (__). Functions or macros without an underscore in the header will take extra time to check the validity of the requested linear address range, while those with an underscore will skip the check. When the kernel must repeatedly access the same linear area of the process address space, it is more efficient to check the address only once at the beginning, and then do not need to check the process area again.

Dynamic address checking: fixed code
Let's first explain the four situations that cause page fault exceptions in kernel mode. These situations must be distinguished by the page fault exception handler, because the actions taken in different situations are very different:
1. The kernel attempts to access a page that belongs to the process address space, but either the corresponding page frame does not exist, or the kernel attempts to access the page. Write a read-only page (copy-on-write). In these cases, the handler must allocate and initialize a new page frame
2. The kernel addresses a page that belongs to its address space, but the corresponding page table entry has not yet been initialized (see Chapter 9, "Handling Non-Contiguous Memory Regions" Access" section). In this case, the kernel must create appropriate entries in the current process's page table. Page frames are also allocated.
3. A certain kernel function contains a programming error, causing an exception when this function is run; or, the exception may be caused by a transient hardware error. When this happens, the handler must execute a kernel exploit (see the "Handling Bad Addresses Outside Address Space" section in Chapter 9).
4. A situation discussed in this chapter: the system call service routine attempts to read and write a memory area, and the address of the memory area is passed through the system call parameter, but does not belong to the address space of the process.
exception table
It doesn't take much effort to put the address of every kernel instruction that accesses the process's address space into a structure called an exception table. When a page fault exception occurs in kernel mode, the do_page_fault() handler checks the exception table: if the table contains the address of the instruction that generated the exception, then the error is caused by an illegal system call parameter, otherwise, it is caused by some more serious caused by bug.
Linux defines several exception tables. The main exception table is automatically generated by the C compiler when building the kernel program image. It is stored in the __ex_table section of the kernel code segment, and its start and end addresses are identified by the two symbols __start__ex_table and __stop__ex_table generated by the C compiler. Each dynamically loaded kernel module (see Appendix 2) contains its own local exception table. This table is automatically generated by the C compiler when building the module image, and is loaded into memory when the module is inserted into the running kernel. The entry of each exception table is an exception_table_entry structure, which has two fields:
insn
访问进程地址空间的指令的线性地址。
fixup
当存放在insn单元中的指令所触发的缺页异常发生时,
fixup就是要调用的汇编语言代码的地址。
The correction code consists of several assembly instructions to solve problems caused by page fault exceptions. As we will see later, correction usually consists of inserting a sequence of instructions that forces the service routine to return an error code to the user-space process. These instructions are usually defined in the same function or macro that accesses the process's address space; they are placed by the C compiler in a separate part of the kernel code segment called .fixup. The search_exception_tables() function is used to search for a specified address in all exception tables: if the address is in a certain table, a pointer to the corresponding exception_table_entry structure is returned; otherwise, NULL is returned. Therefore, the page fault handler do_page_fault() executes the following statement:
if((fixup = search_exception_tables(regs->eip))){
regs->eip = fixup->fixup;
return 1;
}
The regs->eip field contains the value saved to the kernel state stack eip register when an exception occurs. If the value in the eip register (instruction pointer) is in an exception table, do_page_fault() replaces the saved value with the return address of search_exception_tables(). The page fault handler then terminates, and the interrupted program resumes execution with correction code.
Generate exception table and correction code
The GNU assembler (Assembler) directive .section allows programmers to specify which part of an executable file contains the code to be executed immediately. An executable file consists of a code segment, which may in turn be divided into sections. Therefore, the following assembly instruction adds an entry to the exception table; the "a" attribute specifies that this section must be loaded into memory along with the rest of the kernel image.

The .previous directive forces the assembler to insert the following code into the section that was activated when the previous .section directive was encountered. Let's take another look at the __get_user_1(), __get_user_2(), and __get_user_4() functions discussed earlier. Instructions that access a process's address space are labeled 1, 2, and 3.


Each exception entry consists of two labels. The first is a numeric label whose prefix b indicates that the label is "backward"; in other words, the label appears on the previous line of the program. The corrected code is common to these three functions and is marked bad_get_user. If the page fault exception is generated by the instruction at label 1, 2, or 3, then the correction code is executed. The corrected code at bad_get_user simply returns an error code - EFAULT to the process that issued the system call.
Kernel wrapper routines
Although system calls are primarily used by user-mode processes, they can also be called by kernel threads, which cannot use library functions. In order to simplify the declaration of the corresponding package routines, Linux defines a set of 7 macros from _syscal10 to _syscall6.
The numbers 0~6 in each macro name correspond to the number of parameters used in the system call (except the system call number). These macros can also be used to declare wrapper routines that are not included in the libc standard library (for example, because Linux system calls are not yet supported by the library). However, you cannot use these macros to define wrapper routines for system calls that take more than 6 arguments (other than the system call number) or for system calls that produce nonstandard return values. Each macro strictly requires 2+2×n parameters, where n is the number of parameters in the system call. The first two parameters specify the return value type and name of the system call; each pair of additional parameters specifies the type and name of the corresponding system call parameter. Therefore, taking the fork() system call as an example, its encapsulated routine can be generated by the following statement: _syscall0(int, fork). The wrapper routine of the write() system call can be generated by the following statement: _syscall3(int, write, int, fd, const char *, buf, unsigned int, count)
#define _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3) \
type name(type1 arg1,type2 arg2,type3 arg3) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long)(arg2)), \
"d" ((long)(arg3))); \
__syscall_return(type,__res); \
}
#define __syscall_return(type, res) \
do { \
if ((unsigned long)(res) >= (unsigned long)(-(128 + 1))) { \
errno = -(res); \
res = -1; \
} \
return (type) (res); \
} while (0)
In the latter case, this macro can be expanded into the following code: The


__NR_write macro comes from the second parameter of _syscal13; it can be expanded into the system call number of write(). When the previous function is compiled, the following assembly code is generated:

Additional instructions
A section definition such as .section xxx is inserted into the code segment. When the code segment is executed sequentially, will the instructions in .section xxx be executed next? Won't. It can be understood that a definition like .section xxx will cause the compiler to place the content in .section xxx in an extra section when compiling the executable file. In this way, in the actual executable file, the executable instructions before .section xxx are not adjacent to the executable instructions in .section xxx.
xxx1
.section yyy1
…
.previous
.section yyy2
…
.previous
xxx2
The above instruction sequence, in the compiled executable file,
section yy1
…
xxx1
xxx2
…
section yyy1
…
section yyy2
…
Therefore, after the xxx1 instruction is executed, the xxx2 representative is executed next instructions
#define __put_user_asm(x, addr, err, itype, rtype, ltype, errret) \
__asm__ __volatile__( \
"1: mov"itype" %"rtype"1,%2\n" \
"2:\n" \
".section .fixup,\"ax\"\n" \
"3: movl %3,%0\n" \
" jmp 2b\n" \
".previous\n" \
".section __ex_table,\"a\"\n" \
" .align 4\n" \
" .long 1b,3b\n" \
".previous" \
: "=r"(err) \
: ltype (x), "m"(__m(addr)), "i"(errret), "0"(err))