Certain portions of RAM are permanently allocated to the kernel to store kernel code and static kernel data structures. The rest of the RAM is called dynamic memory, which is a valuable resource required not only by the process, but also by the kernel itself.
Page frame management
Intel's Pentinum processor can use two different page frame sizes: 4KB and 4MB (2MB if PAE is activated). Linux uses 4KB page frame size as the standard memory allocation unit.
1. Page fault exceptions caused by paging units are easily explained, either because the requested page exists but the process is not allowed to access it, or because the requested page does not exist. In the second case, the memory allocator must find a 4KB free page frame and allocate it to the process.
2. Although 4KB and 4MB are multiples of the disk block size, in most cases, it is more efficient when transmitting small blocks of data between main memory and disk.
page descriptor
The kernel must keep track of the current state of each page frame. For example, the kernel must be able to distinguish which page frames contain pages belonging to the process and which page frames contain kernel code or kernel data. Similarly, the kernel must also be able to determine whether a page frame in dynamic memory is free. The status information of the page frame is stored in a page descriptor of type page, whose fields are as shown in the table:
| type | name | illustrate |
|---|---|---|
| unsigned long | flags | A set of signs. Number the management area where the page frame is located. |
| atomic_t | _count | Page frame reference counter |
| atomic_t | _mapcount | The number of page table entries in the page frame (-1 if none) |
| unsigned long | private | Kernel components available for pages in use |
| struct address_space* | mapping | Used when a page is inserted into the page cache. Or used when the page belongs to an anonymous area. |
| unsigned long | index | Used by several kernel components as different meanings. |
| struct list_head | lru | Pointer to the least recently used doubly linked list containing the page |
All page descriptors are stored in the mem_map array. The space required by mem_map is slightly less than 1% of the entire RAM. The virt_to_page(addr) macro generates the page descriptor address corresponding to the linear address addr. The pfn_to_page(pfn) macro generates the page descriptor address corresponding to the page frame number pfn. Let us describe the following two fields in more detail: The above conversion works because the kernel knows the starting linear address of the page descriptor array, gets the physical address through the linear address, and gets the page frame index in the array through the physical address. Then locate the page descriptor address.
_count
页的引用计数器。如字段为-1,则相应页框空闲,并可被分配给任一进程或内核本身。
如该字段值大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放一些内核数据结构。
page_count返回__count加1后的值,即该页的使用者的数目。
flags
包含多达32个用来描述页框状态的标志。
对每个PG_xyz标志,内核都定义了操纵其值的一些宏。通常,PageXyz宏返回标志的值,SetPageXyz和ClearPageXyz宏分别设置和清除相应的位。
| Logo name | meaning |
|---|---|
| PG_locked | The page is locked. For example, pages involved in disk I/O operations |
| PG_error | An I/O error occurred while transferring the page |
| PG_referenced | Page just visited |
| PG_uptodate | Set after a read operation is completed, unless a disk I/O error occurs |
| PG_dirty | Page has been modified |
| PG_lru | The page is in the active or inactive page list |
| PG_active | page in active page list |
| PG_highmem | The page frame belongs to the ZONE_HIGHMEM management zone |
| PG_checked | Flag used by some file systems |
| PG_arch_1 | Not used on 80x86 architecture |
| PG_reserved | Page frames are left to kernel code or are not used |
| PG_private | The private field of the page descriptor stores meaningful data |
| PG_writeback | The page is being written to disk using the writeback method. |
| PG_nosave | Used when the system is suspended or woken up |
| PG_compound | Handling page frames through extended paging mechanism |
| PG_swapcache | Page belongs to swap cache |
| PG_mappedtodisk | All data in the page frame corresponds to allocated blocks on disk |
| PG_reclaim | The page has been marked for writing to disk for memory reclamation |
| PG_nosave_free | Used when the system is suspended or restored |
Non-uniform memory access (NUMA)
It is customary to think of computer memory as a uniform, shared resource. Ignoring the role of hardware cache, it is expected that the CPU's access to the memory unit will take the same time regardless of where the memory unit is and where the CPU is. Unfortunately, these assumptions do not always hold true on some architectures. For example, for some multi-processor Alpha or MIPS computers, this is not true. Linux 2.6 supports a non-uniform memory access model, in which access times to different memory units by a given CPU may vary. The physical memory of the system is divided into several nodes. Within a single node, the time required for any given CPU to access a page is the same. However, this time may be different for different CPUs.
For each CPU, the kernel attempts to minimize the number of accesses to time-consuming nodes, which requires careful selection of the storage locations of the kernel data structures that are most frequently referenced by the CPU. The physical memory in each node can be divided into several management areas. Each node has a descriptor of type pg_data_t.
| type | name | illustrate |
|---|---|---|
| struct zone[] | node_zones | Array of management area descriptors in the node |
| struct zonelist[] | node_zonelists | Array of zonelist data structures used by the page allocator |
| int | nr_zones | The number of management areas in the node |
| struct page* | node_mem_map | Array of page descriptors in the node |
| struct bootmem_data* | bdata | Used in kernel initialization phase |
| unsigned long | node_start_pfn | The index of the first page frame in the node |
| unsigned long | node_present_pages | Size of memory node, excluding holes (in page frames) |
| unsigned long | node_spanned_pages | Size of node, including holes (in page frames) |
| int | node_id | node identifier |
| pg_data_t* | pgdat_next | The next item in the node memory list |
| wait_queue_head_t | kswapd_wait | The kswapd page swaps out the wait queue used by the daemon. |
| struct task_struct* | kswapd | Pointer to the process descriptor of the kswapd kernel thread |
| int | kswapd_max_order | kswapd takes the logarithmic value of the free block size to be created |
同样,我们只关注80x86。IBM兼容PC使用一致内存访问模型,因此,并不真正需要NUMA的支持。然而,即使NUMA的支持没有编译进内核,Linux还是使用节点。不过,这是一个单独的节点,它包含了系统中所有的物理内存。此时,pgdat_list指向一个链表,此链表是由一个元素组成的。这个元素就是节点0描述符,它被存放在config_page_data。在80x86结构中,把物理内存分组在一个单独的节点中可能显得没用处;但,这种方式有助于内核代码的处理具有可移植性。
内存管理区
在一个理想的计算机体系结构中,一个页框就是一个内存存储单元,可用于任何事情:存放内核数据和用户数据,缓冲磁盘数据等等。任何种类的数据页都可存放在任何页框中。但实际的计算机体系结构有硬件的制约,这限制了页框可使用的方式。尤其是,Linux内核必须处理80x86体系结构的两种硬件约束:
1.ISA总线的直接内存存取(DMA)处理器有一个严格的限制:它们只能对RAM的前16MB寻址、
2.在具有大容量RAM的现代32位计算机中,CPU不能直接访问所有的物理内存,因为线性地址空间太小。为应对这两种限制,Linux2.6把每个内存节点的物理内存划分为三个管理区。在80x86UMA体系结构中的管理区为:
ZONE_DMA
包含低于16MB的内存页框
ZONE_NORMAL
包含高于16MB且低于896MB的内存页框
ZONE_HIGHMEM
包含从896MB开始高于896MB的内存页框
ZONE_DMA区包含的页框可由老式基于ISA的设备通过DMA使用。ZONE_DMA和ZONE_NORMAL区包含内存的"常规"页框,通过把它们线性地址映射到线性地址空间的第4个GB,内核就可直接进行访问。相反,ZONE_HIGHMEM区包含的内存页不能由内核直接访问,尽管它们页线性地映射到了线性地址空间的第4个GB。在64位体系结构上,ZONE_HIGHMEM区总是空的。每个内存管理区都有自己的描述符。
| 类型 | 名称 | 说明 |
|---|---|---|
| unsigned long | free_pages | 管理区中空闲页的数目 |
| unsigned long | pages_min | 管理区中保留页的数目 |
| unsigned long | pages_low | 回收页框使用的下界;同时也被管理区分配器作为阀值使用 |
| unsigned long | pages_high | 回收页框使用的上届;同时也被管理区分配器作为阀值使用 |
| unsigned long[] | lowmem_reserve | 指明在处理内存不足的临界情况下每个管理区必须保留的页框数目 |
| struct per_cpu_pageset[] | pageset | 用于实现单一页框的特殊高速缓存 |
| spinlock_t | lock | 保护该描述符的自旋锁 |
| struct free_area[] | free_area | 标识出管理区的空闲页框块 |
| spinlock_t | lru_lock | 活动以及非活动链表使用的自旋锁 |
| struct list_head | active_list | 管理区中的活动页链表 |
| struct list_head | inactive_list | 管理区中的非活动页链表 |
| unsigned long | nr_scan_active | 回收内存时需扫描的活动页数目 |
| unsigned long | nr_scan_inactive | 回收内存时需扫描的非活动页数目 |
| unsigned long | nr_active | 管理区的活动链表上的页数目 |
| unsigned long | nr_inactive | 管理区的非活动链表上的页数目 |
| unsigned long | pages_scanned | 管理区内回收页框时使用的计数器 |
| int | all_unreclaimable | 在管理区中填满不可回收页时此标志被置位 |
| int | temp_priority | 临时管理区的优先级 |
| int | prev_priority | 管理区优先级,范围在12和0之间 |
| wait_queue_head_t* | wait_table | 进等待队列的散列表,这些进程正在等待管理区中的某页 |
| unsigned long | wait_table_size | 等待队列散列表的大小 |
| unsigned long | wait_table_bits | 等待队列散列表数组大小,值为2^order |
| struct pglist_data* | zone_pgdat | 内存节点 |
| struct page* | zone_mem_map | 指向管理区的第一个页描述符的指针 |
| unsigned long | zone_start_pfn | 管理区第一个页框的下标 |
| unsigned long | spanned_pages | 以页为单位的管理区的总大小,包括洞 |
| unsigned long | present_pages | 以页为单位的管理区的总大小,不包括洞 |
| char* | name | 指针指向管理区的传统名称:“DMA”,“NORMAL”,“HighMem” |
每个页描述符都有到内存节点和节点内管理区的链接。为节省空间,这些链接被编码成索引存放在flags字段的高位。实际上,刻画页框的标志的数目是有限的。保留flags字段的最高位来编码特定内存节点和管理区号总是可能的。page_zone接收一个页描述符的地址作为它的参数;它读取页描述符中flags字段的最高位,然后通过查看zone_table数组来确定相应管理区描述符的地址。在启动时用所有内存节点的所有管理区描述符的地址初始化这个数组。当内核调一个内存分配函数时,必须指明请求页框所在的管理区。内核通常指明它愿意使用哪个管理区。为了在内存分配请求中指定首选管理区,内核使用zonelist数据结构,这就是管理区描述符指针数组。
保留的页框池
可用两种不同的方法来满足内存分配请求。如有足够的空闲内存可用,请求就会被立刻满足。否则,必须回收一些内存,且将发出请求的内核控制路径阻塞,直到内存被释放。(NUMA下默认策略是本地节点内内存不足,回收内存再分配比不上其他节点存在足量内存时,从其他节点完成剩余部分分配的方案)
当请求内存时,一些内核控制路径不能被阻塞–如,这种情况发生在处理中断或执行临界区内的代码时。此时,一条内核控制路径应产生原子内存分配请求。原子请求从不被阻塞:如没有足够的空闲页,则仅仅是分配失败而已。尽管无法保证一个原子内存分配请求决不失败,但内核会设法尽量减少这种不幸事件发生的可能性。为做到这一点,内核为原子内存分配请求保留了一个页框池,只有在内存不足时才使用。
保留内存的数量(以KB为单位)存放在min_free_kbytes中。它的初始值在内核初始化时设置,并取决于直接映射到内核线性地址空间的第4个GB的物理内存的数量。即,取决于包含在ZONE_DMA和ZONE_NORMAL内存管理区内的页框数目。
保留池的大小=sqrt(16*直接映射内存)(KB)
但,min_free_kbytes的初始值不能小于128也不能大于65536。ZONE_DMA和ZONE_NORMAL内存管理区将一定数量的页框贡献给保留内存,这个数目与两个管理区的相对大小成比例。例,如ZONE_NORMAL管理区比ZONE_DMA大8倍,则页框的7/8从ZONE_NORMAL获得。1/8从ZONE_DMA获得。管理区描述符的pages_min存储了管理区内保留页框的数目。这个字段和pages_low,pages_high一起还在页框回收算法中起作用。pages_low总是设为pages_min的值的5/4,pages_high总是被设为pages_min的3/2。
分区页框分配器
被称作分区页框分配器的内核子系统,处理对连续页框组的内存分配请求。它的主要组成如下:
管理区分配器
ZONE_DMA内存管理区
伙伴系统
每CPU页框高速缓存
ZONE_NORMAL内存管理区
伙伴系统
每CPU页框高速缓存
ZONE_HIGHMEM内存管理区
伙伴系统
每CPU页框高速缓存
其中,名为"管理区分配器"部分接受动态内存分配和释放的请求。在请求分配的情况下,该部分搜索一个能满足所请求的一组连续页框内存的管理区。在每个管理区内,页框被名为"伙伴系统"的部分来处理。为达到更好的系统性能,一小部分页框保留在高速缓存中用于快速地满足对单个页框的分配请求。
请求和释放页框
alloc_pages(gfp_mask, order)
用这个函数请求2^order个连续的页框。它返回第一个所分配页框描述符的地址,或,如分配失败,则返回NULL
alloc_page(gfp_mask)
用于获得一个单独页框的宏;扩展为:alloc_pages(gfp_mask, 0)
__get_free_pages(gfp_mask, order)
类似alloc_pages,返回第一个所分配页的线性地址
__get_free_page(gfp_mask)
用于获得一个单独页框的宏;扩展为:__get_free_pages(gfp_mask, 0)
get_zeroed_page(gfp_mask)
获取填满0的页框;它调用:alloc_pages(gfp_mask | __GFP_ZERO, 0);
__get_dma_pages(gfp_mask, order)
获得适用于DMA的页框,它扩展为:__get_free_pages(gfp_mask | __GFP_DMA, order);
参数gfp_mask是一组标志,指明了如何寻找空闲的页框。能在gfp_mask中使用的标志如下:
| 标志 | 说明 |
|---|---|
| __GFP_DMA | 所请求的页框必须处于ZONE_DMA管理区。等价于GFP_DMA |
| __GFP_HIGHMEM | 所请求的页框处于ZONE_HIGHMEM管理区。 |
| __GFP_WAIT | 允许内核对等待空闲页框的当前进程进行阻塞 |
| __GFP_HIGH | 允许内核访问保留的页框池 |
| __GFP_IO | 允许内核在低端内存页上执行I/O传输以释放页框 |
| __GFP_FS | 如清0,则不允许内核执行依赖文件系统的操作 |
| __GFP_COLD | 所请求的页框可能为"冷的" |
| __GFP_NOWARN | 一次内存分配失败将不会产生警告信息 |
| __GFP_REPEAT | 内核重试内存分配直到成功 |
| __GFP_NOFAIL | 与__GFP_REPEAT相同 |
| __GFP_NORETRY | 一次内存分配失败后不再重试 |
| __GFP_NO_GROW | slab分配器不允许增大slab高速缓存 |
| __GFP_COMP | 属于扩展页的页框 |
| __GFP_ZERO | 任何返回的页框必须被填满0 |
实际上,Linux使用预定义标志值的组合。
| 组名 | 相应标志 |
|---|---|
| GFP_ATOMIC | __GFP_HIGH |
| GFP_NOIO | __GFP_WAIT |
| GFP_NOFS | __GFP_WAIT |
| GFP_KERNEL | __GFP_WAIT |
| GFP_USER | __GFP_WAIT |
| GFP_HIGHUSER | __GFP_WAIT |
__GFP_DMA和__GFP_HIGHMEM被称作管理区修饰符;它们标示寻找空闲页框时内核所搜索的管理区。contig_page_data节点描述符的node_zonelists是一个管理区描述符链表的数组,它代表后备管理区:对管理区修饰符的每一个设置,相应的链表包含的内存管理区能在原来的管理区缺少页框的情况下被用于满足内存分配请求。在80x86 UMA体系结构中,后备管理区如下:
1.如__GFP_DMA被置位,则只能从ZONE_DMA内存管理区获取页框
2.如__GFP_HIGHMEM没被置位,按优先次序从ZONE_NORMAL,ZONE_DMA内存管理区获取页框
3.__GFP_HIGHMEM被置位,按优先次序从ZONE_HIGHMEM,ZONE_NORMAL,ZONE_DMA内存管理区获取页框
下面4个函数和宏中的任一个都可释放页框
__free_pages(page, order)
先检查page指向的页描述符;如该页框未被保留,就把描述符的count字段减1。如count变为0,
就假定从与page对应的页框开始的2^order个连续页框不再被使用。此时,函数释放页框。
free_pages(addr, order)
类似于__free_pages(page, order),它接收的参数为要释放的第一个页框的线性地址addr
__free_page(page)
释放page所指描述符对应的页框;扩展为:__free_pages(page, 0)
free_page(addr)
释放线性地址为addr的页框;扩展为:free_pages(addr, 0)
高端内存页框的内核映射
与直接映射的物理内存末端,高端内存的始端所对应的线性地址存放在high_memory变量。被设置为896MB。896MB边界以上的页框并不映射在内核线性地址空间的第4个GB,因此,内核不能直接访问它们。意味着,返回所分配页框线性地址的页分配器函数不适用于高端内存。即不适用于ZONE_HIGHMEM内存管理区内的页框。如,假定内核调__get_free_pages(GFP_HIGHMEM, 0)在高端内存分配一个页框,如分配器在高端内存确实分配了一个页框,则__get_free_pages不能返回它的线性地址。依次类推,内核不能使用这个页框;甚至更坏情况下,也不能释放该页框。
在64位硬件平台上不存在这个问题,因为可使用的线性地址空间远大于能按照的RAM大小。简言之,这些体系结构的ZONE_HIGHMEM管理区总是空的。但在32位平台上,如80x86体系结构,Linux设计者不得不找到某种方法来允许内核使用所有可使用的RAM,达到PAE所支持的64GB。采用的方法如下:
1.高端内存页框的分配只能通过alloc_pages和它的快捷函数alloc_page。这些函数不返回第一个被分配页框的线性地址,因为如该页框属于高端内存,则这样的线性地址根本不存在。这些函数返回第一个被分配页框的页描述符的线性地址。这些线性地址总是存在的,因为所有页描述符一旦被分配在低端内存,它们在内核初始化阶段就不会改变。
2.没有线性地址的高端内存中的页框不能被内核访问。故,内核线性地址空间的最后128MB中的一部分专门用于映射高端内存页框。这种映射是暂时的。通过重复使用线性地址,使得整个高端内存能在不同的时间被访问。
内核可采用三种不同的机制将页框映射到高端内存(线性地址);分别叫永久内核映射,临时内核映射,非连续内存分配。
建立永久内核映射可能阻塞当前进程;这发生在空闲页表项不存在时,即在高端内存上没有页表项可用作页框的"窗口"时。永久内核映射不能用于中断处理程序和可延迟函数。
建立临时内核映射不会要求阻塞当前进程;它的缺点是只有很少的临时内核映射可同时建立起来。使用临时内核映射的内核控制路径必须保证当前没其他的内核控制路径在使用同样的映射。意味着内核控制路径永不能被阻塞,否则其他内核控制路径很可能使用同一个窗口来映射其他的高端内存页。
这些技术中没一种可确保对整个RAM同时进行寻址。
永久内核映射–64下高端内存区不存在,自然也无永久内核映射
永久内核映射允许内核建立高端页框到内核地址空间(线性地址)的长期映射。它们使用主内核页表中一个专门的页表。地址存放在pkmap_page_table。页表中的表项数由LAST_PKMAP宏产生。页表照样含512或1024项,这取决于PAE是否被激活;因此,内核一次最多访问2MB或4MB的高端内存。该页表映射的线性地址从PKMAP_BASE开始。pkmap_count数组包含LAST_PKMAP个计数器,pkmap_page_table页表中的每一项都有一个。
计数器为0
对应的页表项没映射任何高端内存页框,且是可用的
计数器为1
对应的页表项没映射任何高端内存页框,但它不能使用,因为自从它最后一次使用以来,其相应的TLB表项还未被刷新。
计数器为n
相应的页表项映射一个高端内存页框,意味着正好有n-1个内核成分在使用这个页框。
为记录高端内存页框与永久内核映射包含的线性地址之间的关系,内核使用了page_address_htable散列表。该表包含一个page_address_map数据结构,用于为高端内存中的每一页框进行当前映射。该数据结构还包含一个指向页描述符的指针和分配给该页框的线性地址。
page_address返回页框(物理地址)对应的线性地址,如页框在高端内存(线性地址)中且没被映射,则返回NULL。这个函数接受一个页描述符指针page(描述一个页框)作为参数,区分以下两种情况:
1.如页框不在高端内存(PG_highmem为0),—直接映射。则线性地址总是存在且是通过计算页框下标,然后将其转换成物理地址,最后根据相应的物理地址得到线性地址。__va((unsigned long)(page - mem_map) << 12)
2.如页框在高端内存(PG_highmem为1),该函数就到page_address_htable散列表中查找。如在散列表中找到页框,page_address就返回它的线性地址,否则返回NULL。kmap建立永久内核映射。
void* kmap(struct page* page)
{
if(!PageHighMem(page))
return page_address(page);
return kmap_high(page);
}
如页框确实属于高端内存,则调kmap_high。
void *kamp_high(struct page* page)
{
unsigned long vaddr;
spin_lock(&kmap_lock);// 永久内核映射对所有处理器可见。防止多核并发,需加锁保护。
vaddr = (unsigned long)page_address(page);// 查找哈希表
if(!vaddr)
vaddr = map_new_virtual(page);// 向哈希表插入,并返回线性地址
pkmap_count[(vaddr-PKMAP_BASE) >> PAGE_SHIFT]++;// 通过线性地址找到索引
spin_unlock(&kmap_lock);
return (void*)vaddr;
}
中断处理程序和可延迟函数不能调kmap。kmap_high通过调page_address检查页框是否已经被映射。如不是,调map_new_virtual把页框的物理地址插入到pkmap_page_table的一个项,并在page_address_htable中加入一个元素。然后,kmap_high使页框的线性地址所对应的计数器加1来将调用该函数的新内核成分考虑在内。最后,kmap_high释放kmap_lock并返回对该页框进行映射的线性地址。map_new_virtual本质上执行两个嵌套循环:
for(;;)
{
int count;
DECLARE_WAITQUEUE(wait, current);
for(count = LAST_PKMAP; count > 0; --count)// 遍历所有表项
{
last_pkmap_nr = (last_pkmap_nr+1)&(LAST_PKMAP-1);
// 后半部分搜索每找到可用表项。
// 刷新,再从开始位置再搜索一遍
if(!last_pkmap_nr)
{
flush_all_zero_pkmaps();// 将使用者不存在的槽位清理腾出多余位置
count = LAST_PKMAP;
}
if(!pkmap_count[last_pkmap_nr])
{
unsigned long vaddr = PKMAP_BASE+(last_pkmap_nr<<PAGE_SHIFT);
set_pte(&(pkmap_page_table[last_pkmap_nr]), mk_pte(page/*页框物理地址*/, __pgprot(0x63)));
pkmap_count[last_pkmap_nr] = 1;// 表示页表映射建立了。但此页表项映射的页框并没有使用者。
set_page_address(page, (void*)vaddr);// 建立物理地址-线性地址映射
return vaddr;// 返回线性地址
}
}
// 后半部分没搜索到可用表项,刷新从头搜依然没搜到
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue(&pkmap_map_wait, &wait);
spin_unlock(&kmap_lock);// 放弃cpu之前先释放锁。因为存在放弃cpu,所以不能在中断处理触发
schedule();// 选择另一进程运行。
// 走到这里,一定是其他进程腾出表项后,发现有人在等待空闲表项。所以,让等待者变为就绪,并加入可调度队列。
// 某次调度,等待者被调度恢复后继续执行这里
remove_wait_queue(&pkmap_map_wait, &wait);// 将自己从等待队列移除
spin_lock(&kmap_lock);// 重新加锁
if(page_address(page))
return (unsigned long)page_address(page);
}
内循环中,函数扫描pkmap_count中所有计数器直到找到一个空值。当在pkmap_count中找到一个未使用项时,大的if代码块运行。这段代码确定该项对应的线性地址,为它在pkmap_page_table页表中创建一个项,将count置1,调set_page_address插入一个新元素到page_address_htable散列表,返回线性地址。
搜索从上次因调map_new_virtual而跳出的地方开始。在pkmap_count中搜索到最后一个计数器时,又从下标为0计数器开始搜索。继续之前,map_new_virtual调flush_all_zero_pkmaps开始寻址计数器为1的另一趟扫描。每个值为1的计数器都表示在pkmap_page_table中表项是空闲的,但不能使用,因为相应的TLB表项还没被刷新。flush_all_zero_pkmaps把它们的计数器重置为0,删除page_address_htable散列表中对应的元素,并在pkmap_page_table的所有项上进行TLB刷新。
如内循环在pkmap_count中没找到空的计数器,map_new_virtual就阻塞当前进程,直到某个进程释放了pkmap_page_table页表中的一个表项,通过把current插入到pkmap_map_wait等待队列,把current设置为TASK_UNINTERRUPTIBLE,并调schedule放弃CPU来达到此目的。一旦进程被唤醒,函数就调page_address检查是否存在另一个进程已映射了该页。如还没其他进程映射该页,则内循环重新开始。kunmap撤销先前由kmap建立的永久内核映射。如页确实在高端内存中,则调kunmap_high。
void kunmap_high(struct page* page)
{
spin_lock(&kmap_lock);
// 这是检测此高端内存内页框释放后,此页框占据的页表表项是否没了使用者,进而可被清理后复用(用来服务于另一个页框)
if((--pkmap_count[((unsigned long)page_address(page)-PKMAP_BASE)>>PAGE_SHIFT]) == 1)
{
if(waitqueue_active(&pkmap_map_wait))
wake_up(&pkmap_map_wait);// 唤醒等待空闲表项进程
spin_unlock(&kmap_lock);
}
}
中括号内的表达式从页的线性地址计算出pkmap_count数组的索引。计数器被减1并与1相比。匹配成功表明没进程在使用页。函数最终能唤醒由map_new_virtual添加在等待队列中的进程。
临时内核映射–32位下,每个cpu各自划分出一个内核线性区域,互不重叠(就是固定映射)
可用在中断处理程序和可延迟函数的内部。它们从不阻塞当前进程。在高端内存的任一页框都可通过一个"窗口"映射到内核地址空间。留给临时内核映射的窗口数是非常少的。每个CPU有它自己的包含13个窗口的集合,它们用enum km_type数据结构表示。该数据结构中定义的每个符号,如KM_BOUNCE_READ,KM_USER0或KM_PTE0,标识了窗口的线性地址。内核必须确保同一窗口永不会被两个不同的控制路径同时使用。故,km_type中的每个符号只能由一种内核成分使用,并以该成分命名。最后一个符号KM_TYPE_NR本身并不表示一个线性地址,但由每个CPU用来产生不同的可用窗口数。
在km_type中的每个符号(除了最后一个)都是固定映射的线性地址的一个下标。enum fixed_address数据结构包含符号FIX_KMAP_BEGIN和FIX_KMAP_END;把后者的值赋成下标FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1。这种方式下,系统中的每个CPU都有KM_TYPE_NR个固定映射的线性地址。此外,内核用fix_to_virt(FIX_KMAP_BEGIN)线性地址对应的页表项的地址初始化kmap_pte变量。为建立临时内核映射,内核调kmap_atomic。
void* kmap_atomic(struct page* page, enum km_type type)
{
enum fixed_address idx;
unsigned long vaddr;
current_thread_info()->preempt_count++;// 这样就禁止了内核抢占
if(!PageHighMem(page))
return page_address(page);
idx = type + KM_TYPE_NR * smp_processor_id();
vaddr = fix_to_virt(FIX_KMAP_BEGIN+idx);
set_pte(kmap_pte-idx/* pte表项地址 */, mk_pte(page/* 页框物理地址 */, 0x63));
__flush_tlb_single(vaddr);
return (void*)vaddr;
}
type参数和CPU标识符指定必须用哪个固定映射的线性地址映射请求页。如页框不属于高端内存,则该函数返回页框的线性地址;否则,用页的物理地址及Present,Accessed,Read/Write和Dirty位建立该固定映射的线性地址对应的页表项。最后,该函数刷新适当的TLB项并返回线性地址。为撤销临时内核映射,内核使用kunmap_atomic。在80x86结构中,这个函数减少当前进程的preempt_count。因此,如在请求临时内核映射之前能抢占内核控制路径, 则在同一个映射被撤销后可再次抢占。此外,kunmap_atomic检查当前进程的TIF_NEED_RESCHED标志是否被置位。如是,就调schedule。
伙伴系统算法
内核应为分配一组连续的页框建立一种健壮,高效的分配策略。频繁地请求和释放不同大小的一组连续页框,必然导致在已分配页框的块内分散了许多小块的空闲页框。
本质上,避免外碎片的方法有两种:
1.利用分页单元把一组非连续的空闲页框映射到连续的线性地址区间。
2.开发一种适当的技术来记录现存的空闲连续页框块的情况,以尽量避免为满足对小块的请求而分割大的空闲块。
基于以下三种原因,内核首选第二种方法:
1.某些情况下,连续的页框确实是必要的。因为仅连续的线性地址不足以满足请求。典型例子就是给DMA处理器分配缓存区的内存请求。因为当在一次单独的I/O操作中传送几个磁盘扇区的数据时,DMA忽略分页单元而直接访问地址总线,故,所请求的缓冲区必须位于连续的页框中。
2.即使连续页框的分配并不是很必要,但它在保持内核页表不变方面所起的作用也不容忽视。在内核页表中,只需要为这些连续的页框创建一个条目,而不是为每个页框创建一个单独的条目。这可以减少内核页表的大小,并降低内存管理的开销。在查找页表时,操作系统只需要查找一个条目,而不是多个条目操作系统只需要查找一个页表条目,就可以确定该虚拟地址对应的物理地址。连续页框的分配可以使得内存块更加连续和紧凑。这有助于提高内存利用率,因为操作系统可以更有效地管理和调度内存。修改页表会怎样?频繁修改页表势必导致平均访问内存次数增加,因为这会使CPU频繁刷新TLB(TLB不命中率提高)的内容。
3.内核通过4MB的页可访问大块连续的物理内存。这样减少了TLB失效率(TLB命中率提高),提高了访问内存的平均速度。
Linux采用著名的伙伴系统算法来解决外碎片。把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512,1024个连续的页框。对1024个页框的最大请求对应着4MB大小的连续RAM块。每个块的第一个页框的物理地址是该块大小的整数倍。例如,大小为16个页框的块,其起始地址是16*2^12的倍数。
通过举例来说明算法的工作原理。假设要请求一个256个页框的块。算法先在256个页框的链表中检查是否有一个空闲块。如没有,算法会查找下一个更大的页块。即在512个页框的链表中找一个空闲块。如存在,内核把256的页框分成两等份。一半用作满足请求。另一半插入到256个页框的链表。如在512个页框的块链表没找到空闲块,就继续在1024找。如找到,内核把1024个页框块的256个页框用作请求,剩余的768个页框中拿512个插入到512页框的链表。把最后256个插入到256个页框的链表。如1024页框链表还没找到,算法就放弃并发出错误信号。(意味着连续页框分配最大只能一次分配4MB内存)、
以上过程的逆过程就是页框块的释放过程。内核试图把大小为b的一对空闲伙伴块合并为一个大小为2b的单独块。满足以下条件的两个块称为伙伴:
1.两个块有相同的大小,记作b
2.它们的物理地址是连续的。
3.第一个块的第一个页框的物理地址是2b2^12的倍数。该算法是迭代的,如它成功合并所释放的块,它继续试图合并2b的块。
数据结构
Linux 2.6为每个管理区使用不同的伙伴系统。因此,在80x86结构中,有三种伙伴系统:
第一种处理适合ISA DMA的页框
第二种处理"常规"页框
第三种处理高端内存页框。
每个伙伴系统使用的主要数据结构如下:
1.前面介绍过的mem_map数组。实际上,每个管理区都关系到mem_map元素的子集。子集中的第一个元素和元素的个数分别由管理区描述符的zone_mem_map和size字段指定。
2.包含有11个元素,元素类型为free_area的一个数组,每个元素对应一种块大小。该数组存放在管理区描述符的free_area字段中。
考虑管理区描述符中free_area数组的第k个元素,它标识所有大小为2的k幂次,
的空闲块。这个元素的free_list字段是双向循环链表的头,这个双向循环链表集中了大小为2的k幂次页的空闲块对应的页描述符。更精确地说,该链表包含每个空闲页框块大小为2的k幂次的起始页框的页描述符;
指向链表中相邻元素的指针存放在页描述符的lru字段中。除了链表头外,free_area数组的第k个元素同样包含字段nr_free,它指定了大小为2^k页的空闲块个数。如没大小为2的k幂次的空闲页框块,则nr_free等于0且free_list为空。
一个2的k幂次的空闲页块的第一个页的描述符的private字段存放了块的order,即k。正是由于此字段,页块被释放时,内核可确定这个块的伙伴是否也空闲。如是,它可以把两个块结合成大小为2^(k+1)页的单一块。应注意,直到Linux 2.6.10,内核使用了10组标志来对这种信息进行编码。
分配块
__rmqueue用来在管理区找到一个空闲块。需两个参数:管理区描述符地址,order。order表示请求的空闲页块大小的对数值。如页框被成功分配,__rmqueue就返回第一个被分配页框的页描述符。否则, 返回NULL。
__rmqueue假设调用者已经禁止了本地中断,并获得了保护伙伴系统数据结构的zone->lock自旋锁。从所请求order的链表开始,它扫描每个可用块链表进行循环搜索,如需要搜索更大的order,就继续搜索。
struct free_area* area;
unsigned int current_order;
for(current_order = order; current_order < 11; ++current_order)
{
area = zone->free_area + current_order;
if(!list_empty(&area->free_list))
goto block_found;
}
return NULL;
如直到循环结束还没找到合适的空闲块,则__rmqueue就返回NULL。否则,找到了一个合适的空闲块,这种情况下,从链表中删除它的第一个页框描述符,并减少管理区描述符中的free_pages的值。
block_found:
// 1.定位到链表首个有效元素
// 2.链表首个有效元素是一个struct page对象的lru字段。
// 3.从lru字段地址导出隶属的struct page对象起始地址
page = list_entry(area->free_list.next, struct page, lru);
// 从隶属的双向链表中移除该节点
list_del(&page->lru);
// 清理page的private字段
ClearPagePrivate(page);
// 暂时被设置为0
page->private = 0;
// 更新有效块数
area->nr_free--;
// 更新隶属管理区内空闲页框数
zone->free_pages -= 1UL << order;
当为了满足2^h个页框的请求而有必要使用2^k个页框的块时(h<k),
程序就分配前面的2^h个页框,把后面2^k-2^h个页框循环再分配给free_area链表中下标在h到k之间的元素:
// 这是获得得到块尺寸
size = 1 << curr_order;
//
while(curr_order > order)
{
// 规模小一级空闲块
area--;
// 规模
curr_order--;
// 页数
size >>= 1;
// page是分配出去的块的首个页框。page+size得到剩余可放入当前规模块链表的起始页框
buddy = page + size;
// 将该页框放入当前规模块链表
list_add(&buddy->lru, &area->free_list);
// 规模块中可用块数量更新
area->nr_free++;
// 设置该page的private以记录其隶属的块的规模
buddy->private = curr_order;
// 设置page的标志。来表示其private字段有效。
SetPagePrivate(buddy);
}
return page;// 被分配出去的块的首个page的private字段无效
因为__rmqueue已经找到了合适的空闲块,所以它返回所分配的第一个页框对应的页描述符的地址page。上述分配过程看,每次分配页框会被规整到2的幂次后再执行页框分配(造成分配时内部碎片,牺牲容量,换取性能优化)。
释放块
__free_pages_bulk按伙伴系统的策略释放页框。它使用三个基本输入参数:
page
被释放块中所包含的第一个页框描述符的地址
zone
管理区描述符的地址
order
块大小的对数
函数假设调用者已禁止本地中断(防止外部中断打断执行流程)并获得了保护伙伴系统数据结构的zone->lock(防止其他处理器打断执行流程)自旋锁。__free_pages_bulk先声明和初始化一些局部变量:
struct page* base = zone->zone_mem_map;
unsigned long buddy_idx, page_idx = page - base;
struct page* buddy, *coalesced;
int order_size = 1 << order;// 页数
page_idx包含块中第一个页框的下标,这是相对于管理区中第一个页框而言的。order_size用于增加管理区中空闲页框的计数器:
zone->free_pages += order_size;
现在函数开始执行循环,最多循环(10-order)次,每次都尽量把一个块和它的伙伴进行合并。函数以最小块开始,然后向上移动到顶部:
while(order < 10)
{
// order是当前规模
// 这里的意思是将page_idx的二进制下第order位取反。
// 若此位之前是1,buddy_idx此位是0。这样取得前一个buddy。因为只有前一个buddy才能作为合并后buddy的起始部分。对齐要求。
// 若此位之前是0,buddy_idx此位是1。这样取得后一个buddy。此时只有自己才能作为合并后buddy的起始部分。对齐要求。
buddy_idx = page_idx ^ (1 << order);
buddy = base + buddy_idx;
// 验证此page是否符合作为规模为order的buddy块首个page的条件
if(!page_is_buddy(buddy, order))
break;
list_del(&buddy->lru);// 将此buddy块从隶属的双向链表移除
zone->free_area[order].nr_free--;// 更新本来隶属的规模中可有块数量
// 清理此块首个page的private
ClearPagePrivate(buddy);
buddy->private = 0;
// 确定合并块的首个page的索引。
// page_idx的二进制下第order位
// 若此位之前是1,buddy_idx此位是0。
// 这样合并后块内首个page索引,取buddy_idx
// 若此位之前是0,buddy_idx此位是1。
// 这样合并后块内首个page索引,取page_idx
// page_idx &= buddy_idx得到的结果其余位和page_idx一致。但第order位固定为0。符合上述要求。
page_idx &= buddy_idx;
// 这样我们得到了规模为order+1的块及块内首个page。继续迭代。
order++;
}
在循环体内,函数寻找块的下标buddy_idx,它是拥有page_idx页描述符下标的块的伙伴。结果这个下标可被简单地如下计算:
buddy_idx = page_idx ^ (1 << order);
实际上,使用(1<<order)掩码的异或转换page_idx第order位的值。因此,如这个位原先是0,buddy_idx就等于page_idx+order_size;相反,如这个位原先是1,buddy_idx就等于page_idx - order_size。一旦知道了伙伴块下标,就可通过下式很容易获得伙伴块的页描述符:
buddy = base + buddy_idx;
现在调page_is_buddy来检查buddy是否描述了大小为order_size的空闲页框块的第一个页。
int page_is_buddy(struct page* page, int order)
{
if(PagePrivate(buddy) && page->private == order && !PageReserved(buddy) && page_count(page) == 0)
return 1;
return 0;
}
buddy的第一个页必须为空闲(_count等于-1),它必须属于动态内存,它的private字段必须有意义,最后private字段必须存放将要被释放的块的order。如所有这些条件都符合,伙伴块就被释放,且函数将它从以order排序的空闲块链表上删除,并再执行一次循环以寻找两倍大小的伙伴块。如page_is_buddy中至少有一个条件没被满足,则该函数跳出循环,因为获得的空闲块不能再和其他空闲块合并。函数将它插入适当的链表并以块大小的order更新第一个页框的private。
// 得到最终合并块的首个page
coalesced = base + page_idx;
// 设置其private
coalesced->private = order;
SetPagePrivate(coalesced);
// 将page加入对应规模块的双向链表
list_add(&coalesced->lru, &zone->free_area[order].free_list);
zone->free_area[order].nr_free++;// 更新对应规模内有效块数
每CPU页框高速缓存
内核经常请求和释放单个页框。为提升系统性能,每个内存管理区定义了一个"每CPU"页框高速缓存。所有"每CPU"高速缓存包含一些预先分配的页框,它们被用于满足本地CPU发出的单一内存请求。实际上,这里为每个内存管理区和每个CPU提供了两个高速缓存:一个热高速缓存,它存放的页框中所包含的内容很可能就在CPU硬件高速缓存中;还有一个冷高速缓存。
如内核或用户态进程在刚分配到页框后就立即向页框写,那么从热高速缓存中获得页框就对系统性能有利。实际上,每次对页框存储单元的访问都会导致从另一个页框中给硬件高速缓存"窃取"一行。当然,除非硬件高速缓存包含有一行:它映射刚被访问的"热"页框单元。反过来,如页框将要被DMA操作填充,则从冷高速缓存中获得页框是方便的。在这种情况下,不会涉及到CPU,且硬件高速缓存的行不会被修改。从冷高速缓存获得页框为其他类型的内存分配保存了热页框储备。
实现每CPU页框高速缓存的主要数据结构是存放在内存管理区描述符的pageset字段中的一个per_cpu_pageset数组数据结构。该数组包含为每个CPU提供的一个元素;这个元素依次由两个per_cpu_pages描述符组成,一个留给热高速缓存,另一个留给冷高速缓存。per_cpu_pages描述符的字段
| 类型 | 名称 | 描述 |
|---|---|---|
| int | count | 高速缓存中的页框个数 |
| int | low | 下界,表示高速缓存需要补充 |
| int | high | 上届 |
| int | batch | 在高速缓存中将要添加或被删去的页框个数 |
| struct list_head | list | 高速缓存中包含的页框描述符链表 |
内核使用两个位来监视热高速缓存和冷高速缓存的大小:如页框个数低于下界low,内核通过从伙伴系统中分配batch个单一页框来补充对应的高速缓存。否则,如页框个数高于上界high,内核从高速缓存中释放batch个页框到伙伴系统。
值batch,low,high本质上取决于内存管理区中包含的页框个数。
通过每CPU页框高速缓存分配页框
buffered_rmqueue在指定的内存管理区中分配页框。它使用每CPU页框高速缓存来处理单一页框请求。参数为内存管理区描述符的地址,请求分配的内存大小的对数order,分配标志gfp_flags。如pfp_flags中的__GFP_COLD标志被置位,则页框应当从冷高速缓存中获取,否则,它应从热高速缓存中获取。(此标志只对单一页框分配有意义)函数操作:
1.如order不等于0,每CPU页框高速缓存就不能被使用;跳到4
2.检查由__GFP_COLD标志所标识的内存管理区本地每CPU高速缓存是否需补充。这种情况下,它执行:
2.1.通过反复调__rmqueue从伙伴系统中分配batch个单一页框
2.2.将已分配页框的描述符插入高速缓存链表
2.3.通过给count增加实际被分配页框来更新它
3.如count为正,则函数从高速缓存链表获得一个页框,count减1跳到5。
4.这里,内存请求还没被满足,或是因为请求跨越了几个连续页框,或是因为被选中的页框高速缓存为空,调__rmqueue从伙伴系统分配所请求的页框
5.如内存请求得到满足,初始化第一个页框的页描述符:清除一些标志,将private置为0,将页框引用计数器置1。如gfp_flags中__GPF_ZERO被置位,则函数将被分配的内存区域填充0
6.返回(第一个)页框的页描述符地址,如内存分配请求失败,则返回NULL。
释放页框到每CPU页框高速缓存–位于伙伴系统和页框使用者的中间层
为释放单个页框到每CPU页框高速缓存,内核用free_hot_page和free_cold_page。它们都是free_hot_cold_page的封装。接收的参数为将要释放的页框的描述符地址page和cold标志;free_hot_cold_page操作:
1.从page->flags获取包含该页框的内存管理区描述符地址
2.获取由cold标志选择的管理区高速缓存的per_cpu_pages描述符地址
3.检查高速缓存是否应被清空:如count高于或等于high,则调free_pages_bulk,
将管理区描述符,将被释放的页框个数(batch),高速缓存链表的地址及数字0(为0到order个页框)传递给该函数。free_pages_bulkl依次反复调__free_pages_bulk来释放指定数量的页框到内存管理区的伙伴系统中。
4.把释放的页框添加到高速缓存链表上,增加count。Linux 2.6内核版本中,从没有页框被释放到冷高速缓存中:至于硬件高速缓存,内核总是假设被释放的页框是热的。当达到下界时,通过buffered_rmqueue补充冷高速缓存。热的–页框最近被使用过,不远将来很可能再次被使用。适合供cpu使用。冷的–页框较长时间没被使用过。适合供DMA使用。
管理区分配器
管理区分配器是内核页框分配器的前端。该构建必须分配一个包含足够多空闲页框的内存区,使它能满足内存请求。管理区分配器必须满足几个目标:
1.应当保护保留的页框池
2.当内存不足且允许阻塞当前进程时它应触发页框回收算法。一旦某些页框被释放,管理区分配器将再次尝试分配。
3.如可能,它应保存小而珍贵的ZONE_DMA内存管理区。例如,如是对ZONE_NORMAL或ZONE_HIGHMEM页框的请求,则管理区分配器会不太愿意分配ZONE_DMA内存管理区中的页框。在前面"分区页框分配器"一节已经看到,对一组连续页框的每次请求实质上是通过执行alloc_pages宏来处理的。接着,这个宏又依次调__alloc_pages,该函数是管理区分配器的核心。它接收以下三个参数:
gfp_mask
在内存分配请求中指定的标志
order
将要分配的一组连续页框数量的对数
zonelist
指向zonelist数据结构的指针,该数据结构按优先次序描述了适用于内存分配的内存管理区
__alloc_pages扫描包含在zonelist数据结构中的每个内存管理区。
for(i = 0; (z = zonelist->zones[i]) != NULL; i++)
{
if(zone_watermark_ok(z, order, ...))
{
page = buffered_rmqueue(z, order, gfp_mask);
if(page)
return page;
}
}
对每个内存管理区,该函数将空闲页框的个数与一个阈值作比较,该阈值取决于内存分配标志,当前进程的类型及管理区被函数检查过的次数。实际上, 如空闲内存不足,则每个内存管理区一般会被检查几遍,每一遍在所请求的空闲内存最低量的基础上使用更低的阈值扫描。
zone_watermark_ok接收几个参数,它们决定内存管理区中空闲页框个数的阈值min。特别是,如满足下列两个条件则函数返回1
1.除被分配的页框外,在内存管理区中至少还有min个空闲页框。不包括为内存不足保留的页框。
2.除了被分配的页框外,这里在order至少为k的块中起码还有min/2^k个空闲页框
对于k,取值在1和分配的order之间。阈值min的值由zone_watermark_ok确定:
1.作为参数传递的基本值可是内存管理区界值pages_min,pages_low和pages_high中的任意一个。
2.作为参数传递的gfp_high标志被置位,则base值被2除。通常,如gfp_mask中的__GFP_WAIT标志被置位(即能从高端内存中分配页框),则这个标志等于1
3.如作为参数传递的can_try_harder被置位,则阈值将会再减少四分之一。如gfp_mask中的__GFP_WAIT被置位,或如当前进程是一个实时进程且在进程上下文中(在中断处理程序和可延迟函数之外)已经完成了内存分配,则can_try_harder标志等于1
__alloc_pages执行:
1.执行对内存管理区的第一次扫描
第一次扫描中,阈值min被设为z->pages_low其中z指向正被分析的管理区描述符
2.如函数在上一步没终止,则没剩下多少空闲内存:函数唤醒kswapd内核线程来异步地开始回收页框
3.执行对内存管理区的第二次扫描,将值z->pages_min作为阈值base传递。实际阈值由can_try_harder和gfp_high决定。
4.如函数在上一步没终止,则系统内存肯定不足。如产生内存分配请求的内核控制路径不是一个中断处理程序或一个可延迟函数,且它试图回收页框(或是current的PF_MEMALLOC被置位,或它的PF_MEMDIE被置位),则函数随即执行对内存管理区的第三次扫描,试图分配页框并忽略内存不的阈值。即不调zone_watermark_ok。唯有这种情况下才允许内核控制路径耗用为内存不足预留的页。这种情况下,产生内存请求的内核控制路径最终将试图释放页框,因此只要有可能它就应得到它所请求的。如没有任何内存管理区包含足够的页框,函数就返回NULL来提示调用者发生了错误。
5.这里,正调用的内核控制路径并没试图回收内存。如gfp_mask的__GFP_WAIT没被置位,函数就返回NULL来提示该内核控制路径内存分配失败:此时,如不阻塞当前进程就没办法满足请求。
6.在这里当前进程能被阻塞:调cond_resched检查是否有其他的进程需CPU
7.设置current的PF_MEMALLOC来表示进程已经准备好执行内存回收
8.将一个执行reclaim_state数据结构的指针存入current->reclaim_state。这个数据结构只包含一个字段reclaimed_slab。
9.调try_to_free_pages寻找一些页框来回收。后一个函数可能阻塞当前进程。一旦函数返回,__alloc_pages就重设current的PF_MEMALLOC并再次调cond_resched。
10.如上一步已释放了一些页框,则函数还要执行一次与3步相同的内存管理区扫描。如内存分配请求不能被满足,则函数决定是否应继续扫描内存管理区;如__GFP_NORETRY被清除,且内存分配请求跨越了多达8个页框或__GFP_REPEAT和__GFP_NOFAIL其中之一被置位,则函数就调blk_congestion_wait使进程休眠一会儿,跳回6。否则,返回NULL。
11.如9没释放任何页框,就意味着内核遇到很大的麻烦。如允许内核控制路径依赖于文件系统的操作来杀死一个进程且__GFP_NORETRY为0,则执行:
11.1.使用等于z->pages_high的阈值再一次扫描内存管理区
11.2.调out_of_memory通过杀死一个进程开始释放一些内存
11.3.跳回1
释放一组页框
管理区分配器同样负责释放页框。__free_pages,它接收的参数为将要释放的第一个页框的页描述符的地址,将要释放的一组连续页框的数量的对数。步骤:
1.检查第一个页框是否真正属于动态内存(PG_reserved清0);如不是,终止。
2.减少page->count;如仍大于或等于0,终止。
3.如order等于0,则调free_hot_base来释放页框给适当内存管理区的每CPU热高速缓存。
4.如order大于0,则它将页框加入到本地链表中,调free_pages_bulk把它们释放到适当的内存管理区的伙伴系统中。
内存区管理
本节关注具有连续物理地址和任意长度的内存单元序列。伙伴系统算法采用页框作为基本内存区,这适合于对大块内存的请求,如何处理对小内存区的请求?引入一种新的数据结构来描述在同一个页框中如何分配小内存区。内碎片产生主要是由于请求内存的大小与分配给它的大小不匹配造成的。内核建立了13个按几何分布的空闲内存区链表,它们的大小从32字节到131072字节。伙伴系统的调用既为了获得存放新内存区所需的额外页框,也为了释放不再包含内存区的页框。用一个动态链表来记录每个页框所包含的空闲内存区。
slab分配器
1.所存放数据的类型可影响内存区的分配方式。
slab分配器,把内存区看作对象。这些对象由一组数据结构和几个叫构造,析构的函数组成。前者初始化内存区,后者回收内存区。为避免重复初始化对象,slab分配器并不丢弃已分配的对象,而是释放但把它们保存在内存中。当以后又要请求新的对象时,就可从内存获取而不用重新初始化。
2.内核函数倾向于反复请求同一类型的内存区。slab分配器把那些页框保存在高速缓存中并很快地重新使用它们。
3.对内存区的请求可根据发生的频率来分类。对预期频繁请求一个特定大小的内存区而言,可通过创建一组具有适当大小的专用对象来高效地处理,由此,以避免内碎片的产生。另一种情况,对很少遇到的内存区大小,可通过基于一系列几何分布大小(2的幂)的对象的分配模式来处理。即使这种方法会导致内碎片的产生。
4.在引入的对象大小不是几何分布的情况下,即数据结构的起始物理地址不是2的幂。可借助处理器硬件高速缓存而导致较好的性能。
5.硬件高速缓存的高性能又是尽可能限制对伙伴系统分配器调用的另一个理由。因为对伙伴系统函数的每次调用都"弄脏"硬件高速缓存,增加了对内存的平均访问时间。内核函数对硬件高速缓存的影响就是所谓的函数"足迹",其定义为函数结束时重写高速缓存的百分比。
slab分配器把对象分组放进高速缓存。每个高速缓存都是同种类型对象的一种"储备"。包含高速缓存的主内存区被划分为多个slab,每个slab由一个或多个连续的页框组成。这些页框中既包含已分配的对象,也包含空闲的对象。内核周期性地扫描高速缓存并释放空slab对应的页框。
高速缓存描述符
每个高速缓存由kmem_cache_t类型的数据结构来描述。
| 类型 | 名称 | 说明 |
|---|---|---|
| struct array_cache*[] | array | 每CPU指针数组指向包含空闲对象的本地高速缓存 |
| unsigned int | batchcount | 要转移进本地高速缓存或从本地高速缓存中转出的大批对象的数量 |
| unsigned int | limit | 本地高速缓存中空闲对象的最大数目。 |
| struct kmem_list3 | lists | 参见下一个表 |
| unsigned int | objsize | 高速缓存中包含的对象的大小 |
| unsigned int | flags | 描述高速缓存永久属性的一组标志 |
| unsigned int | num | 封装在一个单独slab中的对象个数 |
| unsigned int | free_limit | 整个slab高速缓存中空闲对象的上限 |
| spinlock_t | spinlock | 高速缓存自旋锁 |
| unsigned int | gfporder | 一个单独slab中包含的连续页框数目的对数 |
| unsigned int | gfpflags | 分配页框时传递给伙伴系统函数的一组标志 |
| size_t | colour | slab使用的颜色个数 |
| unsigned int | colour_off | slab中的基本对齐偏移 |
| unsigned int | colour_next | 下一个被分配的slab使用的颜色 |
| kmem_cache_t* | slabp_cache | 指针指向包含slab描述符的普通slab高速缓存 |
| unsigned int | slab_size | 单个slab的大小 |
| unsigned int | dflags | 描述高速缓存动态属性的一组标志 |
| void* | ctor | 指向与高速缓存相关的构造方法的指针 |
| void* | dtor | 指向与高速缓存相关的析构方法的指针 |
| const char* | name | 存放高速缓存名字的字符数组 |
| struct list_head | next | 高速缓存描述符双向链表使用的指针 |
kmem_cache_t描述符的lists是一个结构体
| 类型 | 名称 | 说明 |
|---|---|---|
| struct list_head | slabs_partial | 包含空闲和非空闲对象的slab描述符双向循环链表 |
| struct list_head | slabs_full | 不包含空闲对象的slab描述符双向循环链表 |
| struct list_head | slabs_free | 只包含空闲对象的slab描述符双向循环链表 |
| unsigned long | free_objects | 高速缓存中空闲对象的个数 |
| int | free_touched | 由slab分配器的页回收算法使用 |
| unsigned long | next_reap | 由slab分配器的页回收算法使用 |
| struct array_cache* | shared | 指向所有CPU共享的一个本地高速缓存的指针 |
slab描述符
| 类型 | 名称 | 说明 |
|---|---|---|
| struct list_head | list | slab描述符的三个双向循环链表中的一个 |
| unsigned long | colouroff | slab中第一个对象的偏移 |
| void* | s_mem | slab中第一个对象的地址 |
| unsigned int | inuse | 当前正使用的slab中的对象个数 |
| unsigned int | free | slab中下一个空闲对象的下标,如没剩下空闲对象则为BUFCTL_END |
slab描述符可存放在两个可能的地方:
外部slab描述符
存放在slab外部,位于cache_sizes指向的一个不适合ISA DMA的普通高速缓存中
内部slab描述符
存放在slab内部,位于分配给slab的第一个页框的起始位置
当对象小于512MB,或当内部碎片为slab描述符和对象描述符在slab中留下足够的空间时,slab分配器选第二种方案。如slab描述符存放在slab外部,则高速缓存描述符的flags中CFLAGS_OFF_SLAB置1。
普通和专用高速缓存
高速缓存被分为两种类型:普通和专用。普通高速缓存只由slab分配器用于自己的目的,专用高速缓存由内核的其余部分使用。普通高速缓存是:
1.第一个高速缓存叫kmem_cache,包括由内核使用的其余高速缓存的高速缓存描述符。cache_cache变量包含第一个高速缓存的描述符。
2.另外一些高速缓存包含用作普通用途的内存区。内存区大小的范围一般包括13个几何分布的内存区。一个叫malloc_sizes的表分分别指向26个高速缓存描述符,与其相关的内存区大小为32,64,128,256,512,1024,2048,4096,8192,16384,32768,65536和131072字节。对每种大小,都有两个高速缓存:一个适用于ISA DMA分配,另一个适用于常规分配。
在系统初始化期间调kmem_cache_init来建立普通高速缓存。专用高速缓存由kmem_cache_create创建。函数从cache_cache普通高速缓存中为新的高速缓存分配一个高速缓存描述符,插入到高速缓存描述符的cache_chain。还可调kmem_cache_destroy撤销一个高速缓存,并将它从cache_chain链表上删除。
内核必须在撤销高速缓存前,撤销其所有的slab。kmem_cache_shrink通过反复调slab_destroy来撤销高速缓存中所有的slab。所有普通和专用高速缓存的名字都可在运行期间通过读/proc/slabinfo得到。这个文件也指明每个高速缓存中空闲对象的个数和已分配对象的个数。
slab分配器与分区页框分配器的接口
当slab分配器创建新的slab时,它依靠分区页框分配器来获得一组连续的空闲页框。为此,它调kmem_getpages,在UMA系统上该函数本质上等价于
void* kmem_getpages(kmem_cache_t* cachep, int flags)
{
struct page* page;
int i;
flags |= cachep->gfpflags;
page = alloc_pages(flags, cachep->gfporder);
if(!page)
return NULL;
i = (1 << cache->gfporder);
if(cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
while(i--)
SetPageSlab(page++);
return page_address(page);
}
cachep
指向需额外页框的高速缓存的高速缓存描述符,请求页框的个数由存放在cache->gfporder中的order决定
flags
说明如何请求页框。这组标志与存放在高速缓存描述符的gfpflags中的专用高速缓存分配标志相结合
内存分配请求的大小由高速缓存描述符的gfporder指定,该字段将高速缓存中slab的大小编码。如已创建了slab高速缓存且SLAB_RECLARM_ACCOUNT标志已经置位,则内核检查是否有足够的内存来满足一些用户态请求时,分配给slab的页框将被记录为可回收的页。函数还将所分配页框的页描述符中的PG_slab标志置位。相反的操作中,通过调kmem_freepages可释放分配给slab的页框
void kmem_freepages(kmem_cache_t* cachep, void* addr)
{
unsigned long i = (1 << cachep->gfporder);
struct page* page = virt_to_page(addr);
if(current->reclaim_state)
current->reclaim_state->reclaimed_slab += i;
while(i--)
ClearPageSlab(page++);
free_pages((unsigned long)addr, cachep->gfporder);
if(cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_sub(1 << cachep->gfporder, &slab_reclaim_pages);
}
函数从线性地址addr开始释放页框,这些页框曾分配给由cachep标识的高速缓存中的slab。如当前进程正在执行内存回收,reclaim_state结构的reclaimed_slab就被适当地增加,于是刚被释放的页就能通过页框回收算法被记录下来。此外,如SLAB_RECLAIM_ACCOUNT标志置位,slab_reclaim_pages则被适当地减少。
给高速缓存分配slab
一个新创建的高速缓存没有包含任何slab,因此也没空闲的对象。只有当以下两个条件都为真时,才给高速缓存分配slab。
1.已发出一个分配新对象的请求
2.高速缓存不包含任何空闲对象
这些情况发生时,slab分配器通过调cache_grow给高速缓存分配一个新的slab。这个函数调kmem_getpages从分区页框分配器获得一组页框来存放一个单独的slab,然后又调alloc_slabmgmt获得一个新的slab描述符。如高速缓存描述符的CFLGS_OFF_SLAB置位,则从高速缓存描述符的slabp_cache字段指向的普通高速缓存中分配这个slab描述符,否则,从slab的第一个页框中分配这个slab描述符。
给定一个页框,内核需确定它是否被slab分配器使用。如是, 迅速得到相应高速缓存和slab描述符地址。故,cache_grow扫描分配给新slab的页框的所有页描述符,将高速缓存描述符和slab描述符的地址分别赋给页描述符中lru的next和prev。只有当页框空闲时伙伴系统的函数才会使用lru。slab分配器函数所处理的页框不空闲并将PG_slab置位。
在高速缓存中给定一个slab,用那些页框来实现它。可通过使用slab描述符的s_mem和高速缓存描述符的gfporder来回答。接着,cache_grow调cache_init_objs,将构造方法应用到新slab包含的所有对象上。最后,cache_grow调list_add_tail将新的到的slab描述符slabp,添加到高速缓存描述符cachep的slab链表末端,并更新高速缓存中的空闲对象计数器
list_add_tail(&slab->list, &cachep->lists->slabs_free);
cachep->lists->free_objects += cachep->num;
从高速缓存中释放slab
在两种条件下才能撤销slab:
1.slab高速缓存中有太多的空闲对象
2.被周期性调用的定时器函数确定是否有完全未使用的slab能被释放。
在两种情况下,调slab_destroy撤销一个slab,并释放相应的页框到分区页框分配器。
void slab_destroy(kmem_cache_t *cachep, slab_t *slabp)
{
if(cachep->dtor)
{
int i;
for(i = 0; i < cachep->num; i++)
{
void* objp = slabp->s_mem + cachep->objsize * i;
(cachep->dtor)(objp, cachep, 0);
}
}
kmem_freepages(cachep, slabp->s_mem - slabp->colouroff);
if(cachep->flags & CFLAGS_OFF_SLAB)
kmem_cache_free(cachep->slabp_cache, slabp);
}
检查高速缓存是否为它的对象提供了析构,如是,使用析构方法释放slab中所有对象。objp记录当前已检查的对象。kmem_freepages,把slab使用的所有连续页框返回给伙伴系统。如slab描述符存放在slab外面,就从slab描述符的高速缓存释放这个slab描述符。实际上,该函数稍微复杂些。如,可使用SLAB_DESTROY_BY_RCU来创建slab高速缓存,这意味着应使用call_rcu注册一个回调来延期释放slab。回调函数接着调kmem_freepages,也可能调kmem_cache_free
对象描述符
每个对象有类型为kmem_bufctl_t的一个描述符,对象描述符存放在一个数组中,位于相应的slab描述符后。类似slab描述符,slab的对象描述符也可用两种可能的方式来存放
外部对象描述符
存放在slab的外面,位于高速缓存描述符的slabp_cache字段指向的一个普通高速缓存中。内存区的大小取决于在slab中所存放的对象个数。
内部对象描述符
存放在slab内部,正好位于描述符所描述的对象前
对象描述符只不过是一个无符号整数,只有在对象空闲时才有意义。它包含的是下一个空闲对象在slab中的下标。因此实现了slab内部空闲对象的一个简单链表。空闲对象链表中的最后一个元素的对象描述符用常规值BUFCTL_END标记。
对齐内存中的对象
slab分配器所管理的对象可在内存中进行对齐。即存放它们的内存单元的起始物理地址是一个给定常量的倍数。通常是2的倍数,这个常量就叫对齐因子。slab分配器所允许的最大对齐因子是4096,即页框大小。这意味着通过访问对象的物理地址或线性地址就可对齐对象。这两种情况下,只有最低的12位才可通过对齐来改变。
通常,如内存单元的物理地址是字大小(即计算机内部内存总线宽度)对齐的,则微机对内存单元的存取会非常快。因此,缺省下,kmem_cache_create根据BYTES_PER_WORD宏所指定的字大小来对齐对象。对于,80x86处理器,这个宏产生值4。当创建一个新的slab高速缓存时,就可让它所包含的对象在第一级高速缓存中对齐。为做到这点,设置SLAB_HWCACHE_ALIGN标志。kmem_cache_create按如下方式处理请求:
1.如对象的大小大于高速缓存行的一半,就在RAM中根据L1_CACHE_BYTES的倍数对齐对象
2.否则,对象的大小就是L1_CACHE_BYTES的因子取整。这可保证一个小对象不会横跨两个高速缓存行。显然,slab分配器这里做的事情就是以内存空间换取访问时间,即通过人为增加对象的大小来获得较好的高速缓存性能,由此也引起额外的内碎片。
slab着色
同一硬件高速缓存行可映射RAM中很多不同的块。相同大小的对象倾向于存放在高速缓存内相同的偏移量处。在不同slab内具有相同偏移量的对象最终很可能映射在同一高速缓存行中。高速缓存的硬件可能因此而花费内存周期在同一高速缓存行与RAM内存单元之间来来往往传送两个对象,而其他的高速缓存行并未充分使用。
slab分配器通过一种叫slab着色的策略,尽量降低高速缓存的这种不愉快行为:把叫做颜色的不同随机数分配给slab。我们考虑某个高速缓存,它的对象在RAM中被对齐。意味着对象的地址肯定是某个给定正数值的倍数。连对齐的约束也考虑在内,在slab内放置对象就有很多种可能的方式。方式的选择取决于对下列变量所作的决定:
num
可在slab中存放的对象个数
osize
对象的大小。包括对齐的字节。
dsize
slap描述符的大小加上所有对象描述符的大小,就等于硬件高速缓存行大小的最小倍数。如slab描述符和对象描述符都放在slap外部,这个值等于0。
free
在slab内未用字节个数
一个slab中的总字节长度=(num*osize)+dsize+free。free总是小于osize,不过可大于aln。slab分配器利用空闲未用的字节free来对slab着色。术语着色只是用来再细分slab,并允许内存分配器把对象展开在不同的线性地址中。这样的话,内核从微处理器的硬件高速缓存中可获得最好性能。具有不同颜色的slab把slab的第一个对象存放在不同的内存单元,同时满足对齐约束。
可用颜色的个数是free/aln(这个值存放在高速缓存描述符的colour字段)。故,第一个颜色表示0,最后一个颜色表示为(free/aln)-1。一种特殊的情况是,如free比aln小,则colour被设为0,不过所有slab都使用颜色0,故颜色的真正个数是1。
如用颜色col对一个slab着色,则,第一个对象的偏移量(相对于slab的起始地址)就等于col*aln+dsize。着色本质上导致把slab中的一些空闲区域从末尾移到开始。只有当free足够大时,着色才起作用。显然,如对象没请求对齐,或如果slab内的未使用字节数小于所请求的对齐(free<=aln),则唯一可能着色的slab就是具有颜色0的slab,即,把这个slab的第一个对象的偏移量赋为0。
通过把当前颜色存放在高速缓存描述符的colour_next字段,就可在一个给定对象类型的slab之间平等地发布各种颜色。 cache_grow把colour_next所表示的颜色赋给一个新的slab,并递增这个字段的值。当colour_next的值变为colour后,又从0开始。这样,每个新创建的slab都与前一个slab具有不同的颜色,直到最大可用颜色。此外,cache_grow从高速缓存描述符的colour_off字段获得值aln,根据slab内对象的个数计算dsize,最后把col*aln+dsize的值存放到slab描述符的colouroff字段中。
空闲Slab对象的本地高速缓存–slab分配器和内存申请使用者的中间层
Linux 2.6对多处理器系统上slab分配器的实现不同于Solaris 2.4最初实现。为减少处理器之间对自旋锁的竞争并更好利用硬件高速缓存,slab分配器的每个高速缓存包含一个被称作slab本地高速缓存的每CPU数据结构,该结构由一个指向被释放对象的小指针数组组成。slab对象的大多数分配和释放只影响本地数组,只有在本地数组下溢或上溢时才涉及slab数据结构。类似前面的每CPU页框高速缓存。高速缓存描述符的array字段是一组指向array_cache数据结构的指针,系统中的每个CPU对应于一个元素。每个array_cache数据结构是空闲对象的本地高速缓存的一个描述符。
| 类型 | 名称 | 说明 |
|---|---|---|
| unsigned int | avail | 指向本地高速缓存中可使用对象的指针的个数。同时作为高速缓存中第一个空槽的下标 |
| unsigned int | limit | 本地高速缓存的大小。即本地高速缓存中指针的最大个数 |
| unsigned int | batchcount | 本地高速缓存重新填充或腾空时使用的块大小 |
| unsigned int | touched | 如本地高速缓存最近已被使用过,则该标志设为1 |
本地高速缓存描述符并不包含本地高速缓存本身的地址;事实上,它正好位于描述符之后。当然,本地高速缓存存放的是指向已释放对象的指针。对象本身总是位于高速缓存的slab中。
当创建一个新的slab高速缓存时,kmem_cache_create决定本地高速缓存的大小(将这个值存放在高速缓存描述符的Limit字段),分配本地高速缓存,将它们的指针存放在高速缓存描述符的array字段。这个大小取决于存放在slab高速缓存中对象的大小,范围从1到120。此外,batchcount字段的初始值,即从一个本地高速缓存的块里添加或删除的对象的个数,被初始化为本地高速缓存大小的一半。
在多处理器系统中,小对象使用的slab高速缓存同样含一个附加的本地高速缓存,它的地址被存放在高速缓存描述符的lists.shared中。共享的本地高速缓存正如它的名字暗示那样,被所有CPU共享,它使得将空闲对象从一个本地高速缓存移动到另一个高速缓存的任务更容易。它的初始大小等于batchcount字段值的8倍。
分配slab对象
通过调kmem_cache_alloc可获得新对象。参数cachep指向高速缓存描述符,新空闲对象必须从该高速缓存描述符获得,参数flag表示传递给分区页框分配器函数的标志。该高速缓存的所有slab应是满的
void* kmem_cache_alloc(kmem_cache_t* cachep, int flags)
{
unsigned long save_flags;
void* objp;
struct array_cache* ac;
local_irq_save(save_flags);
ac = cache_p->array[smp_processor_id()];
if(ac->avail)
{
ac->touched = 1;
objp = ((void**)(ac+1))[--ac->avail];
}
else
objp = cache_alloc_refill(cache_p, flags);
local_irq_restore(save_flags);
return objp;
}
先试图从本地高速缓存获得一个空闲对象。如有,avail就包含指向最后被释放的对象的项在本地高速缓存中的下标。因为本地高速缓存数组正好存放在ac描述符后面。故, ((void**)(ac+1))[–ac->avail];获得空闲对象地址,递减ac->avail。当本地高速缓存没空闲对象时,cache_alloc_refill重新填充本地高速缓存并获得一个空闲对象。cache_alloc_refill:
1.将本地高速缓存描述符地址放在ac局部变量ac = cachep->array[smp_processor_id()]
2.获得cachep->spinlock
3.如slab高速缓存包含共享本地高速缓存,且该共享本地高速缓存包含一些空闲对象,就通过从共享本地高速缓存中上移ac->batchcount个指针来重新填充CPU的本地高速缓存。跳6
4.试图填充本地高速缓存,填充值为高速缓存的slab中包含的多达ac->batchcount个空闲对象的指针
4.1.查看高速缓存描述符的slabs_partial和slabs_free,获得slab描述符的地址slabp,该slab描述符的相应slab或部分被填充,或为空。如不存在这样的描述符,跳5
4.2.对slab中的每个空闲对象,增加slab描述符的inuse,将对象的地址插入本地高速缓存,更新free使得它存放了slab中下一空闲对象下标
slabp->inuse++;
((void**)(ac+1))[ac->avail++] = slabp->s_mem + slabp->free * cachep->obj_size;
slabp->free = ((kmem_bufctl_t*)(slabp+1))[slabp->free];
4.3.如必要,将清空的slab插入到适当的链表上,可以是slab_full,也可是slab_partial。
5.这里,被加到本地高速缓存上的指针个数被存放在ac->avail:函数递减同样数量的kmem_list3结构的free_objects来说明这些对象不再空闲
6.释放cachep->spinlock
7.如现在ac->avail字段大于0(一些高速缓存再填充的情况发生了),函数将ac->touched设为1,返回最后插入到本地高速缓存的空闲对象指针:
return ((void**)(ac+1))[--ac->avail];
8.否则,没发生高速缓存缓存再填充情况,调cache_grow获得一个新slab。从而获得新的空闲对象。
9.如cache_grow失败了,函数返回NULL。否则,返回1
释放slab对象
void kmem_cache_free(kmem_cache_t* cachep, void *objp)
{
unsigned long flags;
struct array_cache* ac;
local_irq_save(flags);
ac = cachep->array[smp_procesor_id()];
if(ac->avail == ac->limit)
cache_flusharray(cachep, ac);
((void**)(ac+1))[ac->avail++] = objp;
local_irq_restore(flags);
}
先检查本地高速缓存是否有空间给指向一个空闲对象的额外指针,如有,该指针就被加到本地高速缓存然后返回。否则,它首选调cache_flusharray清空本地高速缓存,然后将指针加到本地高速缓存。cache_flusharray:
1.获得cachep->spinlock
2.如slab高速缓存包含一个共享本地高速缓存,且如该共享本地缓存还没满,函数就通过从CPU的本地高速缓存中上移ac->batchcount个指针来重新填充共享本地高速缓存
3.调free_block将当前包含在本地高速缓存中的ac->batchcount个对象归还给slab分配器。对在地址objp处的每个对象,执行如下:
3.1.增加高速缓存描述符的lists.free_objects
3.2.确定包含对象的slab描述符的地址
slabp = (struct slab*)(virt_to_page(objp)->lru.prev);
记住,slab页的描述符的lru.prev指向相应的slab描述符
3.3.从它的slab高速缓存链表(cachep->lists.slabs_partial或cachep->lists.slabs_full)上删除slab描述符。
3.4.计算slab内对象的下标
objnr = (objp - slabp->s_mem) / cachep->objsize;
3.5.将slabp->free的当前值存放在对象描述符中,并将对象的下标放入slabp->free(最后被释放的对象将再次成为首先被分配的对象,提升硬件高速缓存命中率)
// 单向链表插法
((kmem_bufctl_t*)(slabp+1))[objnr] = slabp->free;// 利用对象内存(空闲对象)作为单向链表的索引值
slabp->free = objnr;// 下次分配将从上次释放对象开始分配(提升硬件高速缓存命中率)
3.6.递减slabp->inuse
3.7.如slabp->inuse等于0(即slab中所有对象空闲)且整个slab高速缓存中空闲对象的个数(cachep->lists.free_objects)大于cachep->free_limit字段中存放的限制,则函数将slab的页框释放到分区页框分配器
cachep->lists.free_objects -= cachep->num;
slab_destroy(cachep, slabp);
存放在cachep->free_limit字段中的值通常等于cachep->num+(1+N)*cachep->batchcount,其中N代表系统中CPU的个数
3.8.否则,如slab->inuse等于0,但整个slab高速缓存中空闲对象的个数小于cachep->free_limit,函数就将slab描述符插入到cachep->lists.slab_free链表中
3.9.最后,如slab->inuse大于0,slab被部分填充,则函数将slab描述符插入到cachep->lists.slabs_partial链表
4.释放cachep->spinlock
5.通过减去被移到共享本地高速缓存或被释放到slab分配器的对象的个数来更新本地高速缓存描述符的avail
6.移动本地高速缓存数组起始处的那个本地高速缓存中的所有指针。因为,已经把第一个对象指针从本地高速缓存上删除,故剩下的指针必须上移。
通用对象
如对存储器的请求不频繁,就用一组普通高速缓存来处理。普通高速缓存中的对象具有几何分布的大小,范围为32~131072字节。
void* kmalloc(size_t size, int flags)
{
struct cache_sizes *csizep = malloc_sizes;
kmem_cache_t* cachep;
for(; csizep->cs_size; csizep++)
{
if(size > csizep->cs_size)
continue;
if(flag & __GFP_DMA)
cachep = csizep->cs_dmacachep;
else
cachep = csizep->cs_cachep;
return kmem_cache_alloc(cachep, flags);
}
return NULL;
}
函数用malloc_sizes表为所请求的大小分配最近的2的幂次方大小内存。然后,调kmem_cache_alloc分配对象。传递的参数或者适用于ISA DMA页框的高速缓存描述符,或者为适用于"常规"页框的高速缓存描述符。取决于调用者是否用来__GFP_DMA
void kfree(const void* objp)
{
kmem_cache_t* c;
unsigned long flags;
if(!objp)
return;
local_irq_save(flags);
c = (kmem_cache_t*)(virt_to_page(objp)->lru.next);
kmem_cache_free(c, (void*)objp);
local_irq_restore(flags);
}
通过读取内存区所在的第一个页框描述符的lru.next子字段,就可确定出合适的高速缓存描述符。通过调kmem_cache_free来释放相应的内存区。
内存池–使用者可以直接与kmem_cache交互,也可与mempool_t交互
是Linux2.6的一个新特性。基本上讲,一个内存池允许一个内核成分,如块设备子系统,仅在内存不足的紧急情况下分配一些动态内存来使用。不应该将内存池与前面"保留的页框池"一节描述的保留页框混淆。实际上,这些页框只能用于满足中断处理程序或内部临界区发出的原子内存分配请求。而内存池是动态内存的储备,只能被特定的内核成分(即池的"拥有者")使用。拥有者通常不使用储备;但,如动态内存变得极其稀有以至于所有普通内存分配请求都将失败的话,那么作为最后的解决手段, 内核成分就能调特定的内存池函数提取储备得到所需的内存。因此,创建一个内存池就像手头存放一些罐装食物作为储备,当没有新鲜食物时就使用开罐器。
一个内存池常常叠加在slab分配器之上–即,它用来保存slab对象的储备。但,一般而言,内存池能被用来分配任何一种类型的动态内存,从整个页框到使用kmalloc分配的小内存区。故,我们一般将内存池处理的内存单元看作"内存元素"。内存池由mempool_t描述
| 类型 | 名称 | 说明 |
|---|---|---|
| spinlock_t | lock | 用来保护对象字段的自旋锁 |
| int | min_nr | 内存池中元素的最大个数 |
| int | curr_nr | 当前内存池中元素的个数 |
| void** | elements | 指向一个数组的指针,该数组由指向保留元素的指针组成 |
| void* | pool_data | 池的拥有者可获得的私有数据 |
| mempool_alloc_t* | alloc | 分配一个元素的方法 |
| mempool_free_t* | free | 释放一个元素的方法 |
| wait_queue_head_t | wait | 当内存池为空时使用的等待队列 |
min_nr字段存放了内存池中元素的初始个数。即,存放在该字段的值代表了内存元素的个数。内存池拥有者确信能从内存分配器得到这个数目。curr_nr字段总是低于或等于min_nr,它存放了内存池中当前包含的内存元素个数。内存元素自身被一个指针数组引用,指针数组地址存放在elements。
alloc,free与基本的内存分配器交互,分别用于获得和释放一个内存元素,两个方法可是拥有内存池的内核成分提供的定制函数。当内存元素是slab对象时,alloc,free一般由mempool_alloc_slab和mempool_free_slab实现,它们只是分别调kmem_cache_alloc和kmem_cache_free。这种情况下,mempool_t对象的pool_data字段存放了slab高速缓存描述符的地址。
mempool_create创建一个新的内存池;它接收的参数为:内存元素的个数min_nr,实现alloc,free方法的函数的地址,赋给pool_data字段的值。函数分别为mempool_t对象和指向内存元素的指针数组分配内存,然后反复调alloc方法来得到min_nr个内存元素。相反地,mempool_destroy释放池中所有内存元素,然后释放元素数组和mempool_t对象自己。
为从内存池分配一个元素,内核调mempool_alloc,将mempool_t对象的地址和内存分配标志传递给它。函数本质上依据参数所指定的内存分配标志,试图通过调alloc从基本内存分配器分配一个内存元素。如成功,函数返回获得的内存元素而不触及内存池。否则,如分配失败,就从内存池获得内存元素。当然,内存不足情况下过多的分配会用尽内存池:这种情况下,如__GFP_WAIT标志置位,则mempool_alloc阻塞当前进程直到有一个内存元素被释放到内存池中。为释放一个元素到内存池,内核调mempool_free。如内存池未满,则函数将元素加到内存池。否则,mempool_free调free方法来释放元素到基本内存分配器。
非连续内存区管理
把内存区映射到一组连续的页框是最好的选择,会充分利用高速缓存并获得较低的平均访问时间。如对内存区的请求不频繁,则通过连续的线性地址来访问非连续的页框这样一种分配模式会很有意义。这种模式优点是避免了外碎片,缺点是打乱内核页表。显然,非连续内存区大小必须是4096倍数。Linux在几个方面使用非连续内存区,
如:为活动的交换区分配数据结构,为模块分配空间,或者给某些I/O驱动程序分配缓冲区。此外,非连续内存区还提供了另一种使用高端内存页框的方法。
非连续内存区的线性地址
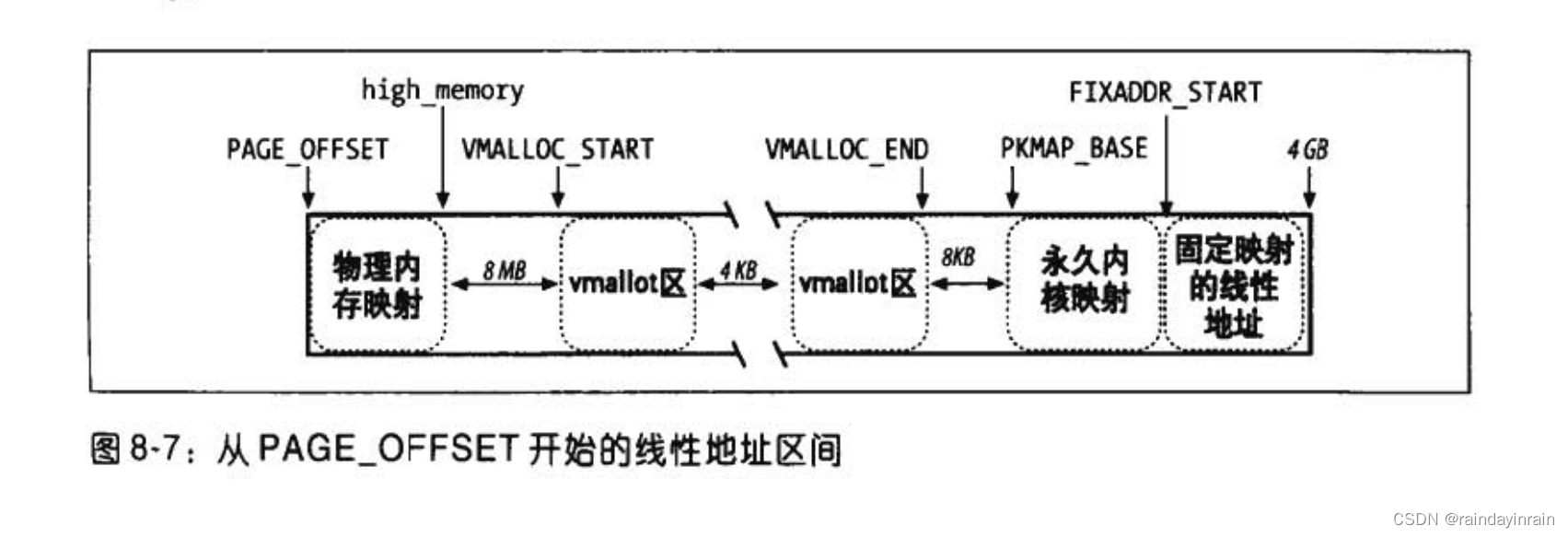
要查找线性地址的一个空闲区,可从PAGE_OFFSET开始查找。
1.内存区的开始部分包含的是对前896MB RAM进行映射的线性地址。直接映射的物理内存末尾所对应的线性地址保存在high_memory
2.内存区的结尾部分包含的是固定映射的线性地址。
3.从PKMAP_BASE开始,查找用于高端内存页框的永久内核映射的线性地址
4.其余的线性地址可用于非连续内存区。在物理内存映射的末尾与第一个内存区之间插入一个大小为8MB的安全区,目的是为了"捕获"对内存的越界访问。出于同样的理由,插入其他4KB大小的安全区来隔离非连续的内存区。
以下针对32位处理器
直接映射线性地址空间:PAGE_OFFSET---high_memory
vmalloc线性地址空间:VMALLOC_START--VMALLOC_END
永久内核映射的线性地址空间:PKMAP_BASE--FIXADDRSTART
固定映射的线性地址空间:FIXADDR_START--4GB
为非连续内存区保留的线性地址空间的起始地址由VMALLOC_START定义,末尾地址由VMALLOC_END定义。
非连续内存区的描述符
每个非连续内存区都对应着一个类型为vm_struct的描述符
| 类型 | 名称 | 说明 |
|---|---|---|
| void* | addr | 内存区内第一个内存单元的线性地址 |
| unsigned long | size | 内存区的大小加4096 |
| unsigned long | flags | 非连续内存区映射的内存的类型 |
| struct page** | pages | 指向nr_pages数组的指针,该数组由指向页描述符的指针组成 |
| unsigned int | nr_pages | 内存区填充的页的个数 |
| unsigned long | phys_addr | 该字段设为0,除非内存已被创建来映射一个硬件设备的I/O共享内存 |
| struct vm_struct* | next | 指向下一个vm_struct结构的指针 |
通过next,这些描述符被插入到一个简单的链表中,链表的第一个元素的地址存放在vmlist变量中。对这个链表的访问依靠vmlist_lock读写自旋锁来保护。flags字段标识了非连续区映射的内存的类型:
VM_ALLOC表示使用vmalloc得到的页,
VM_MAP表示使用vmap映射的已经被分配的页
VM_IOREMAP表示使用ioremap映射的硬件设备的板上内存
get_vm_area在线性地址VMALLOC_START和VMALLOC_END之间查找一个空闲区域。函数使用两个参数:将被创建的内存区的字节大小,指定空闲区类型的标志步骤:
1.调kmalloc为vm_struct类型的新描述符获得一个内存区
2.为写得到vmlist_lock锁,并扫描类型为vm_struct的描述符链表来查找线性地址一个空闲区域,至少覆盖size+4096个地址(4096是内存区之间的安全区间大小)
3.如存在这样一个区间,函数就初始化描述符的字段,释放vmlist_lock,并以返回非连续内存区描述符的起始地址而结束
4.否则,get_vm_area释放先前得到的描述符,释放vmlist_lock,返回NULL
分配非连续内存区
vmalloc给内核分配一个非连续内存区,size表示所请求内存区的大小
void* vmalloc(unsigned long size)
{
struct vm_struct *area;
struct page **pages;
unsigned int array_size, i;
size = (size + PAGE_SIZE - 1) & PAGE_MASK;
area = get_vm_area(size, VM_ALLOC);
if(!area)
return NULL;
area->nr_pages = size >> PAGE_SHIFT;
array_size = (area->nr_pages * sizeof(struct page*));
area->pages = pages = kmalloc(array_size, GFP_KERNEL);
if(!area->pages)
{
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
memset(area->pages, 0, array_size);
for(i = 0; i < area->nr_pages; i++)
{
area->pages[i] = alloc_page(GFP_KERNEL | __GFP_HIGHMEM);
if(!area->pages[i])
{
area->nr_pages = i;
fail:
vfree(area->addr);
return NULL;
}
}
// 通过页表表项逐个处理构建连续线性地址和离散物理地址之间的映射
if(map_vm_area(area, __pgprot(0x63), &pages))
goto fail;
return area->addr;
}
函数首先将size设为4096的整数倍,然后,vmalloc调get_vm_area来创建一个新的描述符,并返回分配给这个内存区的线性地址。描述符的flags字段被初始化为VM_ALLOC标志,该标志意味着通过使用vmalloc函数,非连续页框将被映射到一个线性地址空间。然后,vmalloc调kmalloc来请求一组连续页框,这组页框足够包含一个页描述符指针数组。调memset将所有这些指针设为NULL。接着重复调alloc_page,每一次为区间中nr_pages个页的每一个分配一个页框,并把对应页描述符的地址存放在area->pages中。
到这里,已经得到一个新的连续线性地址空间,且已分配了一组非连续页框来映射这些线性地址。最后重要的步骤是修改内核使用的页表项,以此表明分配给非连续内存区的每个页框现在对应着一个线性地址,这个线性地址被包含在vmalloc产生的连续线性地址空间中。这就是map_vm_area要做的。
area
指向内存区的vm_struct描述符的指针
prot
已分配页框的保护位。它总是被置为0x63,对应着Present,Accessed,Read/Write,Dirty
pages
指向一个指针数组的变量的地址,该指针数组的指针指向页描述符
函数首先把内存区的开始和末尾的线性地址分别分配给局部变量address和end:
address = area->addr;
end = address + (area->size - PAGE_SIZE);
记住,area->size存放的是内存区的实际地址加上4KB内存之间的安全区间。函数使用pgd_offset_k宏来得到在主内核页全局目录中的目录项,该项对应于内存区起始线性地址,然后获得内核页表自旋锁:
pgd = pgd_offset_k(address);
spin_lock(&init_mm.page_table_lock);
然后,函数执行下列循环
int ret = 0;
for(i = pgd_index(address); i < pgd_index(end-1); i++)
{
pud_t* pud = pud_alloc(&init_mm, pgd, address);
ret = -ENOMEM;
if(!pud)
break;
next = (address + PGDIR_SIZE) & PGDIR_MASK;
if(next < address || next > end)
next = end;
if(map_area_pud(pud, address, next, prot, pages))
break;
address = next;
pgd++;
ret = 0;
}
spin_unlock(&init_mm.page_table_lock);
flush_cache_vmap((unsigned long)area->addr, end);
return ret
每次循环都首先调pub_alloc来为新内存区创建一个页上级目录,并把它的物理地址写入内核页全局目录的合适表项。调alloc_area_pud为新的页上级目录分配所有相关的页表。接下来,把常量2的30幂次(在PAE被激活的情况下,否则为2的22幂次)与address的当前值相加(2的30幂次就是一个页上级目录所跨越的线性地址范围的大小)。最后增加指向页全局目录的指针pgd。循环结束的条件是:指向非连续内存区的所有页表项全被建立。map_area_pud为页上级目录所指向的所有页表执行一个类似的循环:
do{
pmd_t* pmd = pmd_alloc(&init_mm, pud, address);
if(!pmd)
return -ENOMEM;
if(map_area_pmd(pmd, address, end-address, prot, pages))
return -ENOMEM;
address = (address + PUD_SIZE) & PUD_MASK;
pud++;
} while(address < end);
map_area_pmd为页中间目录所指向的所有页表执行一个类似的循环
do{
pre_t* pte = pte_alloc_kernel(&init_mm, pmd, address);
if(!pte)
return -ENOMEM;
if(map_area_pte(pte, address, end-address, prot, pages))
return -ENOMEM;
address = (address + PMD_SIZE) & PMD_MASK;
pmd++;
} while(address < end);
pte_alloc_kernel分配一个新的页表,并更新页中间目录中相应的目录项。接下来,map_area_pte为页表中相应的表项分配所有的页框。address值增加222(222就是一个页表所跨越的线性地址区间的大小),且循环反复执行map_area_pte主循环为:
do{
struct page* page = **pages;
set_pte(pte, mk_pte(page, prot));
address += PAGE_SIZE;
pte++;
(*pages)++;
} while(address < end);
将被映射的页框的页描述符地址page从地址pages处的变量指向的数组项读得的。通过set_pte和mk_pte宏,把新页框的物理地址写进页表。把常量4096(即一个页框的长度)加到address上之后,循环又重复执行。
注意,map_vm_area并不触及当前进程的页表。故,当内核态的进程访问非连续内存区时,缺页发生。因为该内存区所对应的进程页表的表项为空。然而,缺页处理程序要检查这个缺页线性地址是否在主内核页表中(即init_mm.pgd页全局目录和它的子页表)一旦处理程序发现一个主内核页表含有这个线性地址的非空项,就把它的值拷贝到相应的进程页表项中,并恢复进程的正常执行。
除了vmalloc外,非连续内存区还能由vmalloc_32分配,该函数与vmalloc相似,但它只从ZONE_NORMAL和ZONE_DMA管理区分配页框。
Linux2.6还特别提供了一个vmap,它将映射非连续内存区中已经分配的页框:本质上,该函数接收一组指向页描述符的指针作为参数,调get_vm_area得到一个新vm_struct描述符,然后调map_vm_area来映射页框。故该函数与vmalloc相似,但它不分配页框。
释放非连续内存区
vfree释放vmalloc和vmalloc_32创建的非连续内存区,而vunmap释放vmap创建的内存区。两个函数都使用同一个参数–将要释放的内存区的起始线性地址address,它们都依赖于__vunmap来作实质性的工作。
__vunmap接收两个参数:
将要释放的内存区的起始地址的地址addr,及标志deallocate_pages,如被映射到内存区的页框应当被释放到分区页框分配器,则这个标志被置位,否则被清除。执行:
1.调remove_vm_area得到vm_struct描述符的地址area,清除非连续内存区中的线性地址对应的内核的页表项
2.如deallocate_pages被置位,函数扫描指向页描述符的area->pages指针数组;对数组的每一个元素,调__free_page释放页框到分区页框分配器。执行kfree(area->pages)来释放数组自身
3.调kfree(area)来释放vm_struct
write_lock(&vmlist_lock);
for(p = &vmlist; (tmp = *p); p = &tmp->next)
{
if(tmp->addr == addr)
{
unmap_vm_area(tmp);
*p = tmp->next;
break;
}
}
write_unlock(&vmlist_lock);
return tmp;
内存区本身通过调unmap_vm_area来释放。这个函数接收单个参数,即指向内存区的vm_struct描述符的指针area。它执行下列循环以进行map_vm_area的反向操作:
address = area->addr;
end = address + area->size;
pgd = pgd_offset_k(address);
for(i = pgd_index(address); i <= pgd_index(end-1); i++)
{
next = (address + PGDIR_SIZE) & PGDIR_MASK;
if(next <= address || next > end)
next = end;
unmap_area_pud(pgd, address, next - address);
address = next;
pgd++;
}
unmap_area_pud依次在循环中执行map_area_pud的反操作:
do {
unmap_area_pmd(pud, address, end - address);
address = (address + PUD_SIZE) & PUD_MASK;
pud++;
} while(address && (address < end));
unmap_area_pmd函数在循环体中执行map_area_pmd的反操作
do {
unmap_area_pte(pmd, address, end - address);
address = (address + PMD_SIZE) & PMD_MASK;
pmd++;
} while(address < end);
最后,unmap_area_pte在循环中执行map_area_ate的反操作
do {
pte_t page = ptep_get_and_clear(pte);
address += PAGE_SIZE;
pte++;
if(!pte_none(page) && !pte_present(page))
printk("Whee ... Swapped out page in kernel page table\n");
} while(address < end);
在每次循环过程中,ptep_get_and_clear将pte指向的页表项设为0。与vmalloc一样,内核修改主内核页全局目录和它的子页表中的相应项,但映射第4个GB的进程页表的项保持不变。因为内核永远不会回收扎根于主内核页全局目录中的页上级目录,页中间目录,页表。如,假定内核态的进程访问一个随后要释放的非连续内存区。进程的页全局目录项等于主内核页全局目录中的相应项。这些目录项指向相同的页上级目录,页中间目录,页表。unmap_area_pte只清除页表中的项(不回收页表本身)。进程对已释放非连续内存区的进一步访问必将由于空的页表项而触发缺页异常。缺页异常处理程序会认为这样的访问是一个错误,因为主内核页表不包含有效的表项。