Gradient descent is the preferred method for optimizing neural networks. This article will introduce various optimizers based on gradient descent, such as Momentum, Adagrad, Adam, etc.
- Stochastic Gradient Descent(SGD)
- Momentum
- Dosing
- RMS plug
- Adam
- AdaMax
1: Gradient descent
Assume that the gradient descent method is a downhill process.
Assume a scenario: a person is trapped on a mountain and needs to come down from the mountain (find the lowest point of the mountain, which is the valley). However, the fog on the mountain was very thick at this time, resulting in very low visibility; therefore, the path down the mountain could not be determined, and one had to use the information around him to find the way down the mountain step by step. At this time, you can use the gradient descent algorithm to help you go down the mountain. How to do it, first use his current position as the benchmark, find the steepest place in this position, then take a step in the downward direction, and then continue to use the current position as the benchmark, find the steepest place, and then walk Until it finally reaches the lowest point; the same goes for going up the mountain, but at this time it becomes a gradient ascent algorithm.
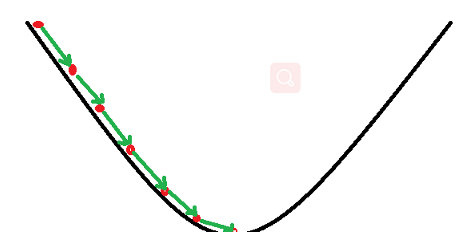


1:SGD

The common method is to repeatedly put the entire set of data into the neural network NN training, which consumes a lot of computing data.
The SGD method is to unpack the data into small batches, and then continuously put them into the NN for calculation in batches.
Batch Gradient Descent has a lot of redundant calculations for large data sets because it recalculates similar gradients before each parameter update. SGD performs parameter updates once for each sample. SGD performs a parameter update for each sample. Since SGD performs frequent updates and changes greatly, the objective function oscillates violently. At the same time, it will also bring certain benefits, the possibility of convergence to a local minimum.
2:Momentum
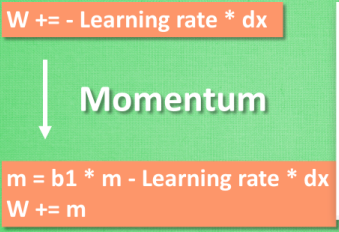
Momentum Momentum:
We compare the task of minimizing the objective function to going down a mountain. It is difficult for SGD to move in ravines, and the degree of curvature in some local dimensions will be much greater than that of the bending program going down the mountain. This makes it easy for SGD to fall into a local optimal solution. In this way, SGD will slowly update the gradient at local locations.
Momentunm is equivalent to applying a layer of momentum on top of SGD. And this momentum and inertia keeps accumulating.
In this way, the momentum parameter promotes the gradient to move in the same direction, and suppresses the gradient when it changes direction (inertia brings resistance). In this way, we obtain faster convergence and reduce the oscillation of SGD itself.
3:AdaGrad

The core idea of AdaGrad is that the sparsity brought about by the deep model causes some parameters in the model to frequently obtain large gradients, and other parameters may occasionally obtain large gradients. If the same learning rate is used, the latter will update very slowly. , so the learning rate of different parameters in the model can be adjusted instead of using a unified learning rate. If the historical cumulative gradient update of a parameter is large, then the learning rate of the parameter is reduced. If the historical cumulative gradient update of a parameter is small, then Increase the learning rate of this parameter.
One of the main advantages of the Adagrad algorithm is that there is no need to manually adjust the learning rate. In most application scenarios, 0.01 is usually used.
A major drawback of Adagrad is that it accumulates the squared gradient in the denominator: since no positive term is added, the accumulated sum will continue to grow throughout the training process. This will cause the learning rate to become smaller and eventually infinitesimal. When the learning rate is infinitely small, the Adagrad algorithm will not be able to obtain additional information.
The Adagrad algorithm is equivalent to applying a layer of resistance.
The Momentum algorithm is equivalent to applying a layer of push.
4:RMSProp
It also belongs to the category of adaptive gradient. The difference from adagrad is that it uses the EMA method to count the latest cumulative gradient of each parameter, so it will not cause slow update of model parameters after multiple iterations.
This algorithm needs to set a cumulative gradient statistic vt and an adaptive gradient momentum bt for each model parameter to be updated, so the additional memory/video memory consumption is 2 times the amount of model parameters.
5:Adam
The Adam optimizer combines the advantages of the two optimization algorithms AdaGrad and RMSProp.
In adam, the first-order moment controls the direction of model update, and the second-order moment controls the step size (learning rate). The learning rate of each parameter is dynamically adjusted using the first and second moment estimates of the gradient.
Adam's advantages
- The implementation is simple, the calculation is efficient, and it requires little memory.
- The update of parameters is not affected by the scaling transformation of the gradient.
- Hyperparameters are very interpretable and often require little or no tuning.
- The update step size can be limited to a rough range (the initial learning rate).
- The step annealing process (automatic adjustment of the learning rate) can be realized naturally.
- It is very suitable for scenarios with large-scale data and parameters.
- Suitable for unstable objective functions.
- It is suitable for problems where the gradient is sparse or the gradient has a lot of noise.
6: Adam W
The AdamW optimizer fixes the weight decay bug in Adam,
Because the learning rate of Adam is adaptive, and the effect of L2 regularization is not ideal when encountering the adaptive learning rate, so Adam+weight decay is used to solve the problem.
7: Summary + Optimizer Selection
| SGD | There is no adaptive learning rate mechanism, but the final model effect may be best if the parameters are carefully adjusted. | Up to 1 times the number of model parameters |
| Adam | The learning rate is relatively insensitive, which reduces the cost of parameter adjustment experiments, but the weight decay is not implemented well. AdamW can be used instead where Adam can be used. | Up to 3 times the number of model parameters |
| AdamW | Compared with Adam, weight decay achieves decoupling and has better results. | Up to 3 times the number of model parameters |