ASCII code only requires 7 bits to be completely represented, but it can only represent 128 characters including English letters. In order to represent most of the writing systems in the world, Unicode was invented. It is a superset of ASCII and includes all writing systems in the world. All characters present in the system, and each code is assigned a standard number (called Unicode CodePoint), called rune in the Go language, which is an alias for int32 .
In the go language, the underlying representation of strings is a byte (8 bit) sequence, not a rune (32 bit) sequence .
func main() {
str := "nihao"
length := len(str)
fmt.Println(length)
for i, _ := range str {
fmt.Println(reflect.TypeOf(str[i]))
}
}
The running result is:
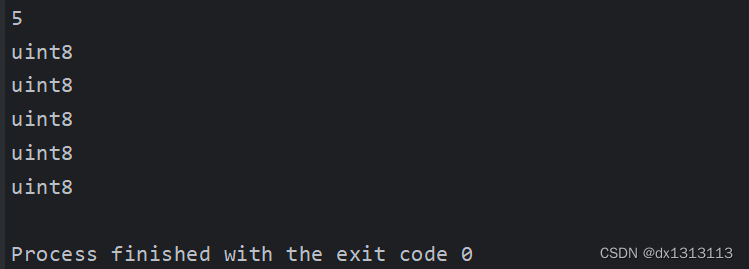
However, if you use for range to traverse the string value, the value type obtained is rune type (3 characters), which is the int32 type, corresponding to the Unicode character type .
func main() {
str := "nihao"
length := len(str)
fmt.Println(length)
for _, v := range str {
fmt.Println(reflect.TypeOf(v))
}
}
operation result:
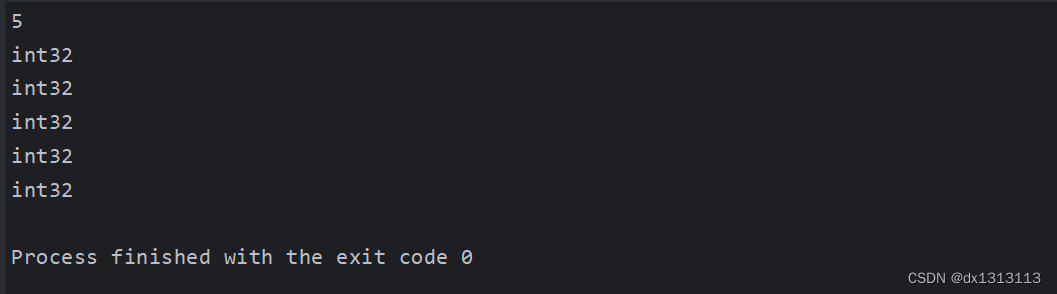
Modify string
So when modifying strings in Go language, write according to different situations:
When there are Chinese characters in the string:
At this time, you need to convert the string into a []rune slice for operation
func main() {
str := "你好"
fmt.Printf("修改前:%s", str)
fmt.Println()
strr := []rune(str)
strr[0] = '我'
fmt.Printf("修改后:%s", string(strr))
}
result:

If you use []byte, the compilation will not pass.
When there is only English in the string :
At this time, you can use []rune or []byte, but generally []byte is used:
func main() {
str := "nihao"
fmt.Printf("修改前:%s", str)
fmt.Println()
strr := []rune(str)
strr[0] = 'w'
fmt.Printf("[]rune修改后:%s", string(strr))
fmt.Println()
strrr := []byte(str)
strrr[0] = 'w'
fmt.Printf("[]byte修改后:%s", string(strr))
fmt.Println()
}operation result:
