【Read the paper】AttentionFGAN
Paper: https://ieeexplore.ieee.org/document/9103116/
If there is any infringement, please contact the blogger
introduce
I haven’t read a paper on using GAN to achieve image fusion for a long time. I happened to see a paper in 2021 and was very interested.
The paper introduces a method for fusion of visual images and infrared images based on multi-scale and SE attention. The network architecture is based on GAN, which is somewhat similar to the structure of DDcGAN and also has two discriminators. Let’s take a look next.
Network Architecture
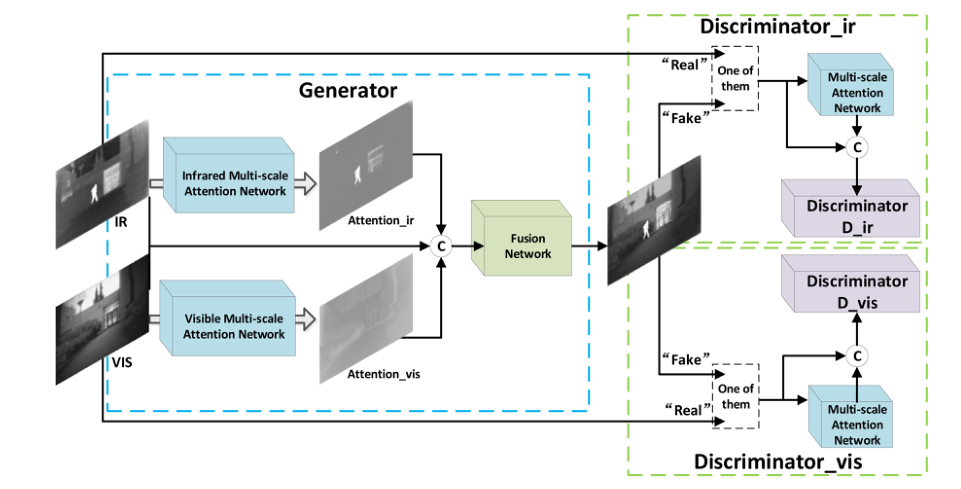
The overall architecture of the network is shown in the figure above. Let's take a brief look at it first. It can be considered that the entire network is composed of four components. They are a network used to extract target information in infrared images and a network used to extract background information in visible images. The network and two are used to distinguish whether the input image is a fused image or an infrared/visual image .
Network for extracting target information from infrared images

Looking at this part alone, I believe no one except the author knows what this is for, but fortunately there is the picture below
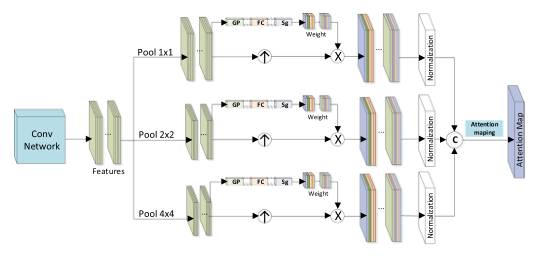
The above picture is the network structure of the infrared multi-scale attention network. It can be seen that the entire network contains three scales of attention-based feature extraction modules . From top to bottom, they are the original image information and the ones generated after 2x2 pooling. Image data and image data generated after 4x4 pooling.
Let’s take a closer look at the picture above. There are still many details.
According to what we have known before, the height and width of the image feature information at each scale should be different. So why can the extracted feature information of the three scales be directly connected in the channel dimension here?
This is because after the SE attention calculates the weight, the weight is not directly multiplied with the original scale features , but multiplied with the features after the original scale features are upsampled . The upsampling here is naturally the features of the three scales. Information information is upsampled to the same height and width .
The author gives the calculation formula of SE attention in the article. Calculated as follows
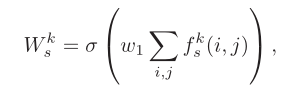
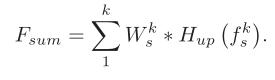
Finally, the extracted features at each scale are connected together to obtain the extracted infrared features.
The structure and principle of the visual feature attention network is the same as that of infrared.
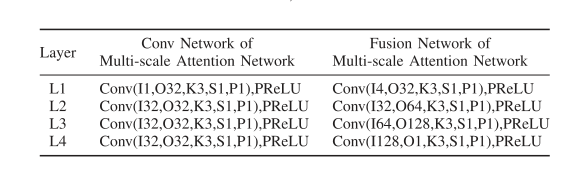
The network structure of the generator is shown in the table below, including the network structure of multi-scale feature extraction and a fusion network structure.
discriminator
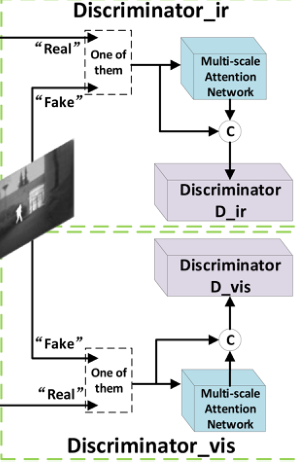
Because the structures of the two discriminators are roughly the same, we will discuss them uniformly here.
Similar to the structure of DDcGAN, two discriminators are also used here, one is used to determine whether it is a fused image or an infrared image, and whether it is a fused image or a visible image.
After seeing the above network structure, you will find why there are two more multi-scale attention networks?
The author's explanation here is that he hopes that each discriminator can pay more attention to the area that should be focused on rather than the entire image. So how to understand it?
Taking the infrared/fusion image discriminator as an example, the author here hopes that the discriminator will pay more attention to the target information features in the infrared image rather than the background information and all information. **Similarly, the same goes for visual/fused image discriminators. The SE attention block can adjust the weight according to the target loss function, that is, increase the weight of the feature information we want and reduce the weight of the feature information we do not want .
This makes it clearer that the input of the discriminator is the information after connecting the output of the multi-scale attention block and the original image information.
The structure of the discriminator is shown in the table below, consisting of a convolutional layer Conv and a fully convolutional FC.

loss function
generator loss function
Let’s first look at the overall loss function of the generator, which consists of three parts: adversarial loss, content loss and attention loss.
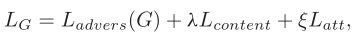
Let’s first look at the content loss, which is still a familiar formula. It is to ensure that the target intensity information of the fused image is similar to that in the visible image.
Because it is a 2021 paper after all, it does not take into account the salient target information in the visual image, which is not very consistent with the loss we often see now.
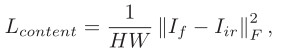
Let’s look at the attention loss function. I personally think it is the highlight of this article.
Here att represents the feature information generated after SE attention processing . We have mentioned before that the reason for adding the SE block is to generate the features we want to notice. Information rather than global information . Similarly, att here is what the network thinks we want to pay attention to.
For example, in the infrared and fused image discriminator, we definitely want to determine whether the input image is a visible image or a fused image through the salient target information of the input image. So how to judge?
It is judged by the att generated by the input image . When the att of the fused image is more similar to the att of the infrared image, it means that the fused image contains richer infrared target information. The same is true for visual images.
Finally, the adversarial loss
Dir is the probability that the infrared discriminator thinks the image is an infrared image, and Dvis is the probability that the visual discriminator thinks the image is a visible image. We hope that the fused image generated by the generator can fool the two discriminators, that is, the two A discriminator believes that the higher the probability that the fused image is a visible/infrared image, the better, that is, the larger Dir and Dvis are, the better, and a negative sign means that the smaller the overall image, the better.
discriminator loss function
The loss function of the discriminator is relatively simple, that is, the higher the probability of identifying the data from the infrared/visual image as infrared/visual, the better, and the lower the probability of identifying the data from the fused image as infrared/visual, the better. Okay, but  I really don’t know what it means here . . . . . . . Please guys, please give me some answers.
I really don’t know what it means here . . . . . . . Please guys, please give me some answers.
Summarize
There are two points that amaze me the most about the whole article. The first is the SE block added to the multi-scale feature extraction to select the features we want ; the other is the loss function , especially the attention loss . By comparing the features of the area we want to pay attention to, we can determine whether the fused image contains visual texture information and target information in the infrared image .
Interpretation of other fusion image papers
==》Read the paper column, come and click me》==
【Read the paper】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
reference
[1] AttentionFGAN: Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks