Learning Transferable Visual Models From Natural Language Supervision
Official account: EDPJ
Table of contents
2.1 Create a large enough dataset
2.2 Select an efficient pre-training method
2.3 Selecting and scaling a model
3.1 Preliminary comparison with visual N-Grams
3.4 Robustness to migration from natural distributions
0. Summary
A SOTA computer vision system trained to predict a fixed set of predetermined categories. This restricted form of supervision limits their generality and usability, as additional labeled data are required. Learning directly from raw text about images is a promising alternative that can leverage a wider set of supervised resources. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the Internet ( representation). After pre-training, natural language is used to refer to the learned visual concepts (or describe new concepts), thereby enabling zero-shot transfer of the model to downstream tasks. We study the performance of more than 30 different computer vision datasets, covering tasks such as OCR, action recognition in videos, geolocalization, and many types of fine-grained object classification. The model transfers well to most tasks and is often comparable to fully supervised baselines without any dataset-specific training. For example, we achieve the accuracy of the original ResNet50 on ImageNet zero-shot without requiring any of the 1.28 million samples required to train ResNet50.
1 Introduction
Pre-training methods that learn directly from raw text have revolutionized NLP over the past few years. The development of "text-to-text" as a standardized input-output interface enables task-agnostic architectures that can be transferred to downstream datasets in zero-shot. Flagship systems like GPT-3 are now competitive in many tasks using bespoke models while requiring little to no specific training data.
These results demonstrate that the total supervision achievable by modern pre-training methods on web-scale text ensembles exceeds that of high-quality densely labeled (crowd-labeled) NLP datasets. However, in other fields such as computer vision, it is still standard practice to pre-train models on datasets such as ImageNet. Could scalable pre-training methods that learn directly from web text achieve similar breakthroughs in computer vision? Previous work is encouraging.
- Joulin et al. show that CNNs that predict words in image captions can obtain representations comparable to ImageNet.
- Later, Li et al. extended this method to predict phrase n-grams as well as single words, and demonstrated the ability of the system to transfer to other image classification datasets with zero-shot.
With newer architectures and pre-training methods, VirTex, ICMLM, and ConVIRT have recently demonstrated the potential for some applications: transformer-based language modeling, masked language modeling, and contrast-based learning of image representations from text.
However, the performance of the above models is still lower than the current SOTA computer vision models, such as Big Transfer, weakly supervised ResNeXt. A key difference is scale. Mahajan et al. and Kolesnikov et al. trained on millions to billions of images over several years, and VirTex, ICMLM, and ConVIRT trained on days from one to two hundred thousand images.
We close this gap by studying the behavior of image models trained with large-scale natural language supervision. We demonstrate a simplified version of ConVIRT trained from scratch for Contrastive Language-Image Pre-training, which we call CLIP. This is an efficient and scalable method for learning from natural language supervision. We find that CLIP learns to perform a large number of tasks during pre-training, including OCR, geolocation, and action recognition, and outperforms the best publicly available ImageNet models while being more computationally efficient. We also find that zero-shot CLIP models are more robust than supervised ImageNet models of comparable accuracy.
2. Method
At its core, perception is learned from the supervision contained in natural language matched to images.
2.1 Create a large enough dataset
Existing work mainly uses three data sets, MS-COCO, Visual Genome and YFCC100M. While MS-COCO and Visual Genome are high-quality densely labeled datasets, they are small by modern standards, with approximately 100,000 training photos each. By comparison, other computer vision systems were trained on as many as 3.5 billion Instagram photos. YFCC100M with 100 million photos is a possible alternative, but the metadata for each image is sparse and the quality varies. Many images use automatically generated filenames such as 20160716 113957.JPG as "title" or "description" containing camera exposure settings. After filtering to keep only images with natural language captions or English descriptions, the dataset was shrunk by a factor of 6 to 15 million photos. This is roughly the same as ImageNet.
A major incentive for natural language supervision is the vast amount of data in this form publicly available on the Internet. For testing, we construct a new dataset of 400 million (image, text) pairs collected from various publicly available sources on the Internet. In an attempt to cover as wide a range of visual concepts as possible, we search for (image, text) pairs whose text contains a set of 500,000 queries as part of the construction process. We roughly balance the results by including up to 20,000 (image, text) pairs in each query. The total word count of the resulting dataset is similar to the WebText dataset used to train GPT-2. We refer to this dataset as WebImageText (WIT).
2.2 Select an efficient pre-training method
Our initial approach is similar to VirTex, jointly training an image CNN and a text transformer from scratch to predict image captions. However, we ran into difficulty scaling this approach efficiently.

In Figure 2, we show that a 63 million parameter transformer language model, using twice the computation of its ResNet50 image encoder, learns to recognize ImageNet classes more slowly than Joulin et al. predict bag-of-words encodings for the same text three times.
Recent work in contrastive representation learning found that contrastive objectives can outperform equivalent predictive objectives. Noting this finding, we train a system to solve the potentially easier proxy task of only predicting which image an entire text is paired with, rather than predicting the exact word of that text. Starting from the same bag-of-words encoding baseline, we swap the prediction objective for the comparison objective in Figure 2, and observe a further 4x improvement in zero-shot transfer to ImageNet.
Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N*N possible (image, text) pairs in the batch actually occur. To this end, CLIP learns a multimodal embedding space by jointly training an image encoder and a text encoder to maximize the cosine similarity of N pairs of correctly matched image and text embeddings in a batch while minimizing N^2 - N Cosine similarity for incorrect matches. We optimize a symmetric cross-entropy loss over these similarity scores.

In Figure 3, we include pseudocode for the core of the CLIP implementation. This batch construction technique and objective, based on the multi-class N-pair loss first proposed by Sohn, was recently adapted by Zhang et al. for contrastive (text, image) representation learning in the medical imaging domain.
Since overfitting is not a major concern, the training details of CLIP are simplified compared to Zhang et al.
- CLIP is trained from scratch rather than initialized with pretrained weights.
- The non-linear mapping between representation and contrastive embedding spaces is removed.
- Each encoder representation is mapped to the multimodal embedding space using only a linear map.
- Also removed is the text transformation function t_u, which uniformly samples a single sentence from text, since many (image, text) pairs in CLIP's pre-training dataset are just single sentences.
- The image transformation function t_v is also simplified. Random square cropping to resize images is the only data augmentation used during training.
- Finally, the temperature parameter, which controls the range of logits in softmax, is directly optimized as a logarithmically parameterized multiplicative scalar during training to avoid turning into a hyperparameter.
2.3 Selecting and scaling a model
We consider two different architectures for image encoders.
First, we use ResNet50 as the underlying architecture of the image encoder due to its widespread use and proven performance.
- We make some modifications to the original version using He et al.'s ResNetD and Zhang's antialiased rect-2 blur pooling.
- We also replace the global average pooling layer with an attention pooling mechanism.
- Attention pooling is implemented as a single-layer “transformer-style” multi-head QKV attention, where the query is conditioned on the global average-pooled representation of the image.
For the second architecture, we experimented with the recently introduced Vision Transformer (ViT). We closely follow their implementation, only adding additional layer normalization to the combined patch and position embeddings before the transformer, and using a slightly different initialization scheme.
The text encoder is a Transformer with a modified architecture described in Radford et al.
- As a base, we use a 12-layer 512-wide model with 8 attention heads. Transformers operate on byte pair encoding (BPE) representations of text in lowercase.
- Text sequences are enclosed by [SOS] and [EOS] tags, and the activations of the transformer’s highest layer at the [EOS] tags are used as feature representations of the text, which are normalized by layers and then linearly projected into the multimodal embedding space .
- Masked self-attention is used in text encoders to preserve the ability to add language modeling as an auxiliary objective, although exploration of this is left to future work.
While previous computer vision research typically scales models by increasing width or depth individually, for the ResNet image encoder we adopt the approach of Tan & Le.
- They found that distributing the extra computation across all widths, depths and resolutions was better than distributing it to only one dimension.
- We use a simple variant that equally distributes the extra computation to increase model width, depth, and resolution.
- For the text encoder, we only scale the width of the model to be proportional to the computed ResNet width increase, not the depth, as we found that the performance of CLIP is less sensitive to the text encoder.
2.4 Pre-training
We train a series of 5 ResNets and 3 Vision Transformers.
- For ResNet, we train one ResNet50, one ResNet101, and then three more, which follow EfficientNet-style model scaling and use approximately 4x, 16x, and 64x ResNet50 computation, denoted RN50x4, RN50x16, and RN50x64, respectively.
- For Vision Transformers, we trained a ViT-B/32, a ViT-B/16 and a ViT-L/14.
The largest ResNet model, RN50x64, was trained for 18 days on 592 V100 GPUs, while the largest Vision Transformer was trained for 12 days on 256 V100 GPUs.
For ViT-L/14, we also pre-train for an additional epoch at a higher resolution of 336 pixels to improve the performance similar to FixRes. We denote this model as ViT-L/14@336px.
All results reported as “CLIP” in this paper use the model we found to perform best, unless otherwise stated.
2.5 Using CLIP
CLIP is pre-trained to predict whether an image and a text segment are paired in WIT. To apply CLIP to downstream tasks, we use this feature and study the zero-shot transfer performance of CLIP on standard computer vision datasets. Similar to the work of Radford et al., we use this as a way of measuring a system's task learning ability (as opposed to its representation learning ability).
For each dataset, we use the names of all classes in the dataset as a set of potential text pairs and predict the most likely (image, text) pair according to CLIP.
We also tried to provide CLIP with text prompts (prompts) to help specify tasks and integrate multiple of these templates to improve performance.
However, since the vast majority of unsupervised and self-supervised computer vision research has focused on representation learning, we also investigate CLIP using the common linear probe protocol.
3. Analysis
3.1 Preliminary comparison with visual N-Grams
To the best of our knowledge, Visual N-Grams is the first to study zero-shot transfer to existing image classification datasets in the manner described above. It is also, to our knowledge, the only work that studies zero-shot transfer to standard image classification datasets using task-agnostic pretrained models.
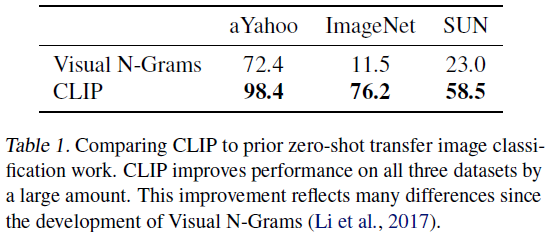
In Table 1, we compare Visual N-Grams with CLIP. Despite not using 1.28 million densely labeled training samples, the best CLIP model improves accuracy on ImageNet from 11.5% to 76.2% on the validation set and matches the performance of the original ResNet50. Furthermore, the top-5 accuracy is significantly higher for the CLIP model, which has a top-5 accuracy of 95%, matching Inception-V4.
The zero-shot setting rivals the performance of strong, fully supervised baselines, suggesting that CLIP is an important step towards flexible and practical zero-shot computer vision classifiers.
This comparison is not direct, as many differences between CLIP and Visual N-Grams are not controlled for. As a closer comparison, we trained CLIP ResNet50 on the same YFCC100M dataset used to train Visual N-Grams and found that it matched their reported ImageNet performance within a single V100 GPU day. This baseline is also trained from scratch rather than initialized from pretrained ImageNet weights as in Visual N-Grams.
3.2 Zero-Shot performance
In computer vision, zero-shot learning usually refers to the generalization of image classification to unseen categories. In contrast, we use the term in a broader sense and study generalization to unseen datasets. While much research in the field of unsupervised learning has focused on the representation learning capabilities of machine learning systems, we encourage the study of zero-shot transfer as a way to measure the task learning capabilities of machine learning systems. In this perspective, datasets evaluate the performance of tasks on a specific distribution. However, many popular computer vision datasets were created by the research community primarily as benchmarks to guide the development of general image classification methods, rather than to measure task-specific performance. To the best of our knowledge, Visual N-Grams is the first to study zero-shot transfer to existing image classification datasets in the manner described above.
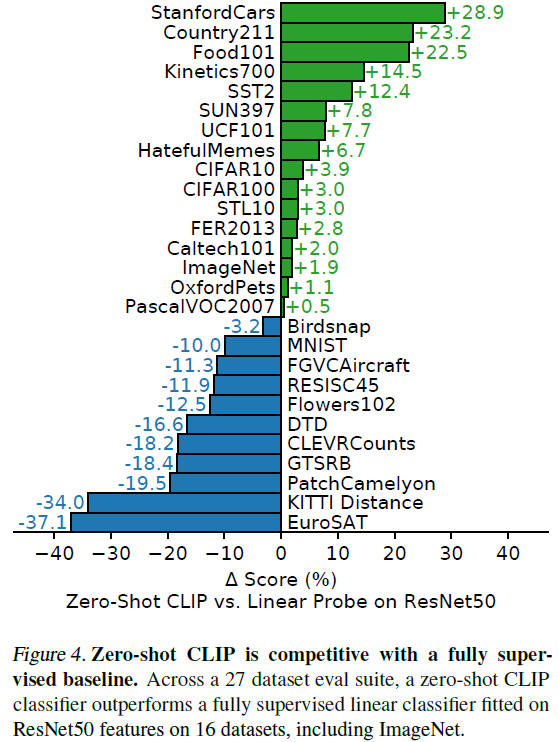
For a more comprehensive analysis, we implemented a larger evaluation suite. In total, we expand from the 3 datasets reported in Visual N-Grams to over 30 datasets and compare with over 50 existing computer vision systems. First, we see how CLIP's zero-shot classifier performs compared to a simple off-the-shelf baseline: fitting a fully supervised, regularized logistic regression classifier on the features of a canonical ResNet50. In Figure 4 we show this comparison for 27 datasets.
Zero-shot CLIP slightly outperforms this baseline and wins on 16 of the 27 datasets. The dataset where Zero-shot CLIP improves the most is STL10, which aims to encourage unsupervised learning by including only a limited number of labeled examples. Zero-shot CLIP, which achieves 99.3% on this dataset without using any training examples, seems to be a new state of the art. In the fine-grained classification task, we observe a large variance in performance. On two of the datasets, Stanford Cars and Food101, zero-shot CLIP outperforms logistic regression by more than 20% on ResNet50 features, while on Flowers102 and FGVCAircraft, zero-shot CLIP outperforms by more than 10%. We suspect that these differences are mainly due to the different amount of supervision per task between WIT and ImageNet. On "generic" object classification datasets such as ImageNet, CIFAR10, and PascalVOC2007, the performance is relatively similar, with a slight advantage for zero-shot CLIP. Zero-shot CLIP significantly outperforms ResNet50 on two datasets measuring video action recognition. On Kinetics700, Zero-shot CLIP outperforms ResNet50 by 14.5%. Zero-shot CLIP also outperforms ResNet50 features by 7.7% on UCF101. We speculate that this is due to the fact that natural language provides broader supervision for visual concepts involving verbs than the noun-centric object supervision in ImageNet.
Looking at where zero-shot CLIP clearly underperforms, we find that zero-shot CLIP performs well in satellite image classification (EuroSAT and RESISC45), lymph node tumor detection (PatchCamelyon), counting in synthetic scenes (CLEVRCounts), autonomous driving related tasks [eg Several specialized, complex or abstract tasks such as German traffic sign recognition (GTSRB), recognition of the distance to the nearest car (KITTI Distance)] are quite weak. These results highlight the poor ability of zero-shot CLIP on more complex tasks. In contrast, non-experts can robustly perform several of these tasks, such as counting, satellite imagery classification, and traffic sign recognition, suggesting that there is plenty of room for improvement. However, it is not clear to us whether measuring zero-shot transfer is a meaningful assessment for difficult tasks for which the learner has no experience (e.g. lymph node tumor classification) compared to few-shot transfer.
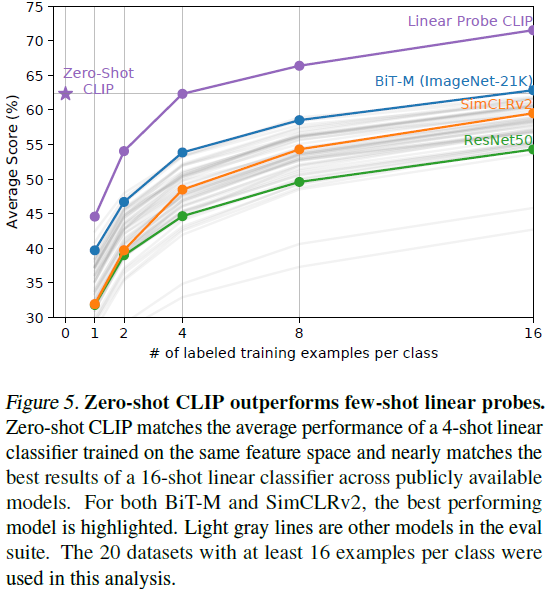
While comparing zero-shot performance to fully supervised models makes CLIP's task learning capabilities concrete, comparisons to few-shot methods are more straightforward since zero-shot is its limit. In Figure 5, we visualize zero-shot CLIP compared to few-shot logistic regression on features from a number of image models (ImageNet, self-supervised learning, and CLIP).
While one might think that zero-shot performs worse than one-shot, we find that zero-shot CLIP is comparable to the performance of 4-shot logistic regression on the same feature space. This may be due to the difference between zero-shot and few-shot methods. CLIP's zero-shot classifiers are generated through natural language (which can directly describe specified attributes), whereas supervised learning must indirectly infer attributes from training examples. The disadvantage of instance-based context-free learning is that many different hypotheses need to be consistent with the data, especially in the one-shot case, and a single image usually contains many different attributes. Although competent learners are able to exploit visual cues and heuristics, such as assuming that the attribute being exhibited is the main object in the image, this is not absolutely accurate.
When comparing zero-shot CLIP to few-shot logistic regression on other model features, zero-shot CLIP performs roughly as well as the best-performing 16-shot classifier in our evaluation suite, which was used on ImageNet-21K Feature space of BiT-M ResNet152x2 trained on . We are sure that BiT-L models trained on JFT-300M will perform better, but these models have not been released publicly. BiT-M ResNet152x2 performs best at 16-shot, which is somewhat surprising since, as analyzed in Section 3.3, Noisy Student EfficientNet-L2 outperforms it by nearly 5% on average in the fully supervised setting across 27 datasets.
3.3 Representation Learning
Although we focus on studying the task-learning ability of CLIP through zero-shot transfer, it is more common to study the representation learning ability of the model. We use the linear probe evaluation protocol because it requires minimal hyperparameter tuning and has a standardized evaluation procedure.
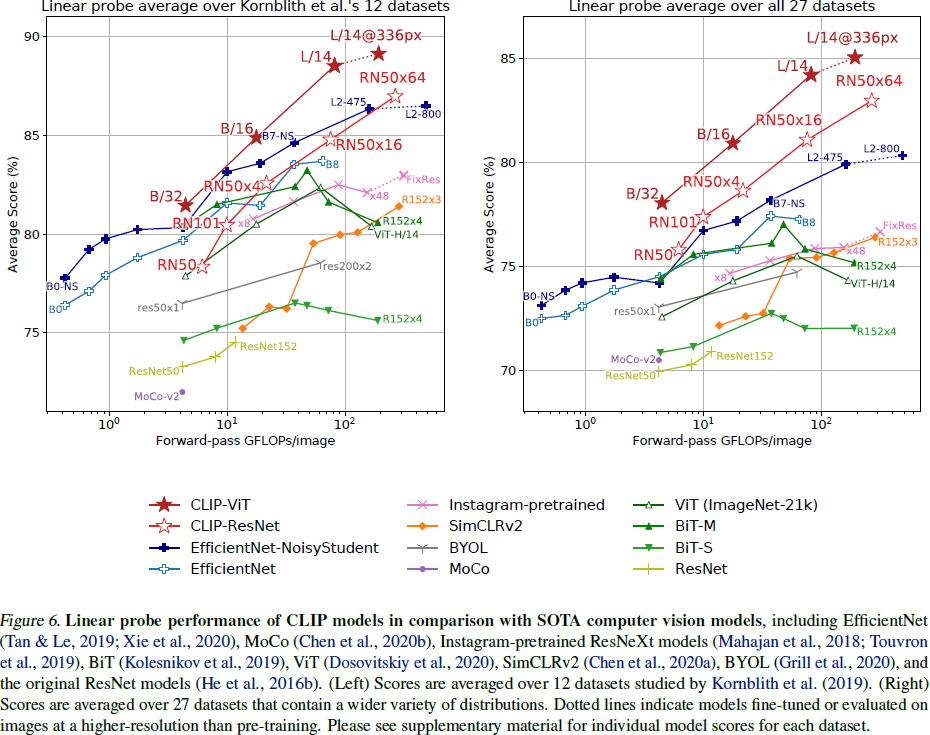
Figure 6 summarizes our findings. To minimize selection effects that could introduce confirmation or reporting bias, we first investigated the performance of the 12-dataset evaluation suite of Kornblith et al. Models trained with CLIP scale computations well, and our largest model slightly outperforms the best existing model (Noisy Student EfficientNet-L2) in terms of overall score and computational efficiency. We also find that the CLIP vision transformer is about 3x more computationally efficient than CLIP ResNets, which enables higher overall performance within our computational budget. These results replicate the findings of Dosovitskiy et al.: visual transformers are more computationally efficient than convolutional neural networks when trained on sufficiently large datasets. Our best model, ViT-L/14@336px, outperforms the best existing model in the entire evaluation suite by an average of 2.6%.
The CLIP model learns a broader set of tasks than previously demonstrated in a single computer vision model trained end-to-end from random initialization. These tasks include geolocation, optical character recognition, facial emotion recognition, and motion recognition. None of these tasks are evaluated in the evaluation suite of Kornblith et al. This is arguably a selection bias in the work of Kornblith et al. on tasks that overlap with ImageNet. To address this issue, we also measure the performance of the evaluation suite on a wider set of 27 datasets. The evaluation suite is detailed in Appendix A and includes datasets representing the above tasks, the German Traffic Sign Recognition Benchmark, and several other datasets adapted from VTAB. On this broader evaluation kit, the benefits of CLIP are even more apparent. All CLIP models, regardless of scale, outperform all evaluated systems in terms of computational efficiency. The best models achieved an average score improvement of 2.6% to 5% over previous systems.
3.4 Robustness to migration from natural distributions
In 2015, He et al. announced that deep learning models outperformed humans on the ImageNet test set. However, research in subsequent years has repeatedly found that these models still make many simple mistakes, and new benchmarks of these systems have often found them to perform well below human accuracy and ImageNet performance. Taori et al. conduct a comprehensive study aimed at quantifying and understanding ImageNet models. They study how the performance of ImageNet models varies when evaluating natural distribution transfer. They measure performance on seven distribution transfers and find that distribution transfer accuracy increases predictably with ImageNet accuracy and is well modeled as a linear function of logit-transformed accuracy. They used this finding to suggest that robustness analysis should distinguish between effective robustness and relative robustness.
- Effective robustness measures the improvement in accuracy under distributional shifts above that predicted by the relationship between in-distribution and out-of-distribution accuracy.
- Relative robustness captures any improvement in out-of-distribution accuracy.
- Taori et al. argue that robustness techniques should aim to improve both effective robustness and relative robustness.
However, almost all models studied by Taori et al. were trained or fine-tuned on the ImageNet dataset. Is training or adapting the ImageNet dataset distribution responsible for the observed robustness gap? Intuitively, a zero-shot model should not be able to exploit spurious correlations or patterns that only apply to a specific distribution because it was not trained for that distribution. Therefore, zero-shot models may exhibit higher effective robustness.
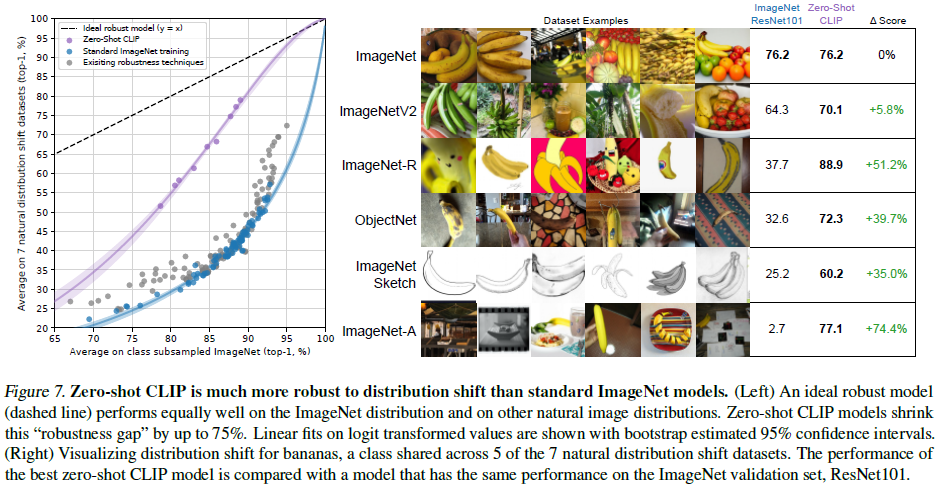
In Figure 7, we compare the performance of zero-shot CLIP with existing ImageNet models on natural distribution transfer. All zero-shot CLIP models greatly improve effective robustness and reduce the gap between ImageNet accuracy and accuracy under distribution transfer by up to 75%. The zero-shot CLIP model tracks a completely different robustness bound than all 204 previous models studied by Taori et al. These results suggest that the recent move to large-scale task- and dataset-agnostic pre-training and the reorientation of zero-shot transfer evaluation (as advocated by Yogatama et al. and Linzen) lead to the development of more robust systems and Provides a more accurate assessment of real model performance.
4. Data overlap analysis
One problem with pre-training on very large Internet datasets is overlap with downstream evaluation. We performed a deduplication analysis. Of the 35 datasets studied, there was no overlap in 9 datasets. The median overlap was 2.2%, and the average overlap was 3.2%. Due to this small amount of overlap, only 7 datasets are above this threshold, and the overall accuracy rarely deviates by more than 0.1%. Of these, only 2 were statistically significant after Bonferroni correction. The largest improvement detected on Birdsnap was only 0.6%. This echoes results from similar repeated analyzes in previous large-scale pre-training work. Mahajan et al. and Kolesnikov et al. detected similar overlap rates for their models and also observed small changes in overall performance.
5. Wider impact
CLIP allows people to design their own classifiers and removes the need for task-specific training data. The way these classes are designed can significantly affect model performance and model bias. For example, when given a set of labels, including the Fairface racial label and some overly aggressive terms such as "criminal" and "animal", the model classifies images of people aged 0-20 into the overly categorized as 32.3%. However, this behavior drops to 8.7% when we add the class "child" to the list of possible classes. We also found differences in gender and race between those classified as 'criminal' and 'non-human', underscoring that even careful design can have differential effects.
Furthermore, given that CLIP does not require task-specific training data, it can more easily solve some specific tasks. Some of these tasks may increase privacy or surveillance-related risks, which we explore by testing the performance of CLIP on celebrity recognition using the CelebA dataset. CLIP achieves a top-1 accuracy of 59.2% in "in the wild" celebrity image classification when choosing from 100 candidates and 43.3% accuracy when choosing from 1000 possible options. Although achieving these results with task-independent pre-training is notable, this performance cannot match that of widely used production-grade models. We explore the challenges presented by CLIP in our supplementary material and hope that this work will inspire future research into the characterization of the capabilities, shortcomings, and biases of such models.
6. Restrictions
The performance of Zero-shot CLIP is generally only competitive with supervised baselines of linear classifiers on ResNet-50 features. This baseline is now well below the overall state-of-the-art, and a lot of work still needs to be done to improve the task learning and transfer capabilities of CLIP. We estimate that zero-shot CLIP requires about a 1000x increase in computation to achieve overall SOTA performance in our evaluation suite. Training is not feasible with current hardware. Further research on improving the computational and data efficiency of CLIP is warranted.
While we emphasize zero-shot transfer, we also iteratively evaluate validation set performance to guide development. This is unrealistic for a true zero-shot scene. Similar concerns have been raised in the field of semi-supervised learning. Another potential issue is our choice of evaluation dataset. While we report the results of Kornblith et al. (12 datasets evaluation suite as a normalized set), our main analysis used a random set of 27 datasets that fit the capabilities of CLIP. New task benchmarks aimed at evaluating extended zero-shot transfer capabilities will help address this issue.
We emphasize that specifying image classifiers via natural language is a flexible operation, but this has its own limitations. Many complex tasks can be difficult to specify through text alone. Admittedly, real training examples are useful, but CLIP is not directly optimized for few-shot performance. We go back and fit a linear classifier on top of the CLIP features. This causes a counter-intuitive drop in performance when transitioning from zero-shot to few-shot.
7. Related work
The idea of learning to perform computer vision tasks from natural language supervision is by no means new. Instead, our main contribution is to study its behavior at scale.
- More than 20 years ago, Mori et al. explored improving content-based image retrieval by training a model to predict nouns and adjectives in text paired with images.
- Quattoni et al. demonstrate that more data-efficient image representations can be learned via manifold learning in the weight space of a classifier trained to predict words in image captions.
- Srivastava & Salakhutdinov explore deep representation learning by training multimodal deep Boltzmann machines on top of low-level image and text label features.
- The recent work that inspired CLIP is described in the introduction.
Supervised learning for the web typically studies learning from collections of Internet images, and Fergus demonstrated the ability to train competitive computer vision classifiers by treating image search engine results as supervision. In this line of work, Learning Everything about Anything: Webly-Supervised Visual Concept Learning has very similar goals to CLIP.
The development of zero-shot computer vision is crucial to CLIP.
- Socher et al. demonstrate that concatenating image and language representations enables zero-shot transfer to categories unseen on CIFAR10.
- Frome et al. improved and extended this finding to ImageNet.
- The idea of generating classifiers based on natural language goes back at least as far as Elhoseiny et al. and Lei Ba et al. explore a form of zero-shot classifier similar to CLIP.
Natural language supervision has also been explored for tasks other than image classification, including video understanding, reinforcement learning, and more recently a large body of work learning joint vision and language models for complex joint tasks beyond the scope of this paper, including visual question answering.
8. Conclusion
CLIP models learn to perform a wide variety of tasks during pre-training and then leverage these task learnings through natural language cues, enabling zero-shot transfer to many existing datasets. At a sufficiently large scale, the performance of this method is comparable to supervised models, but there is still a lot of room for improvement.
reference
Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
Summarize
1. Basic principles
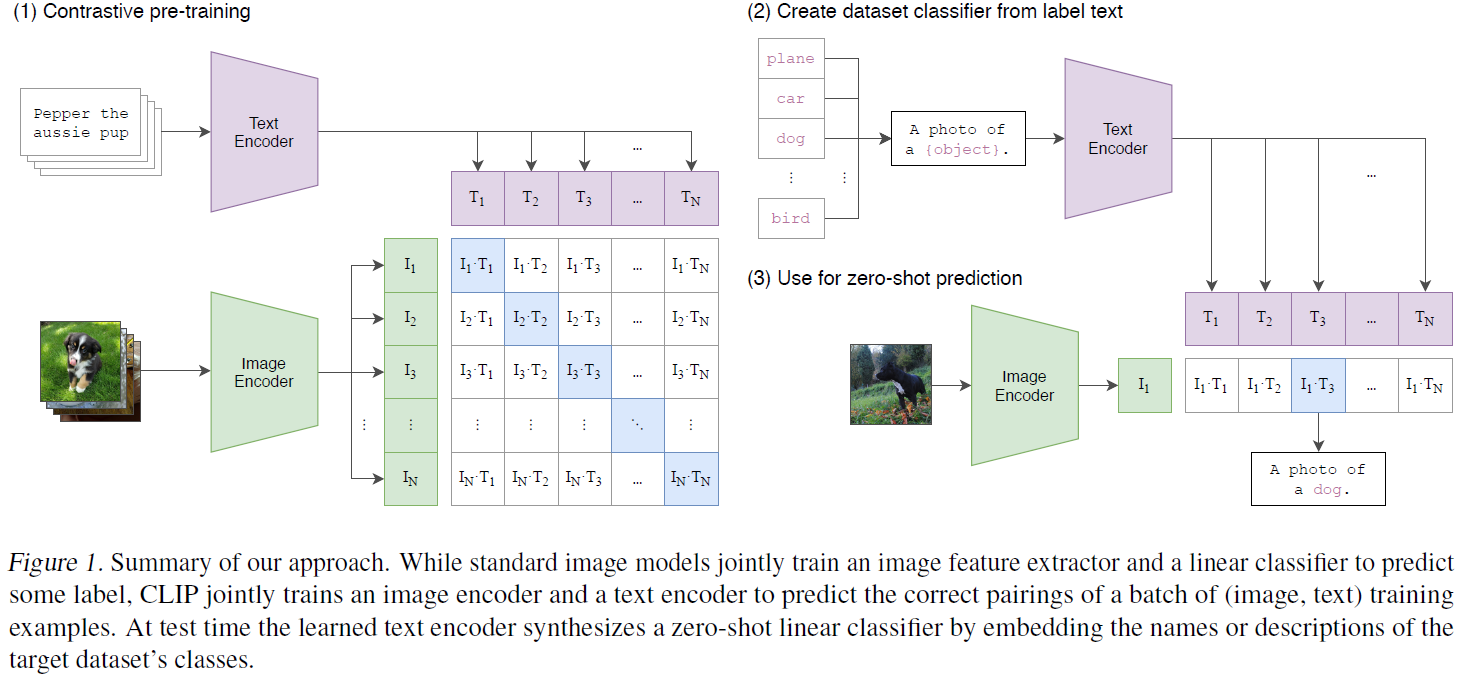
CLIP jointly trains an image encoder and a text encoder to predict the correct pairing for a batch of (image, text) training examples. At test time, the learned text encoder encodes the name or description of the target dataset category to obtain the corresponding embedding, and then performs zero-shot matching with the embedding of the image to be classified.
2. Performance
The experimental results prove that the performance of zero-shot CLIP is slightly better than that of few-shot logistic regression, unless the number of samples of few-shot exceeds a certain threshold (for example: 16). This may be due to the difference between zero-shot and few-shot methods. CLIP's zero-shot classifiers are generated through natural language (which can directly describe the specified attributes), while supervised learning must indirectly obtain information from the training data. The disadvantage of sample-based context-free learning is that many different hypotheses need to be consistent with the data, especially in the one-shot case. And a single image often contains many different visual concepts, making it impossible to determine which one is the key for prediction.
3. Restrictions
Models based on natural language hints cannot handle attributes that cannot be described in language, so some corresponding samples may be needed as a reference. As mentioned earlier, switching from zero-shot to few-shot will face the problem of performance degradation. While performance can be improved by increasing the number of samples (beyond the threshold), for some classes samples are very scarce.