Lstm can be regarded as a special form of RNN, which is an improved recurrent neural network.
It can solve the problem that RNN cannot handle long-distance dependencies.
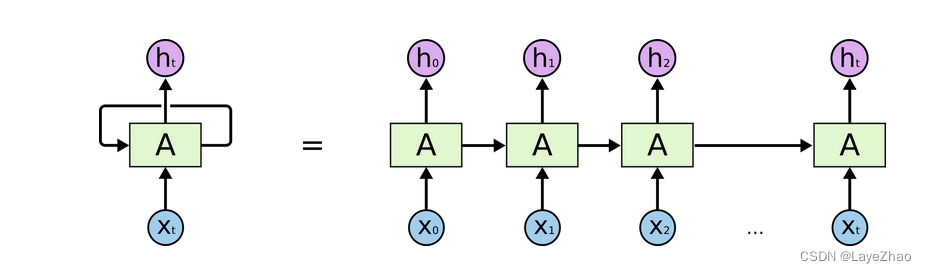
The specific features of LSTM can be summarized as one more unit state and three gates (forgetting gate, input gate, output gate) when the hidden layer is transferred, which work together on the hidden layer unit of the original RNN.
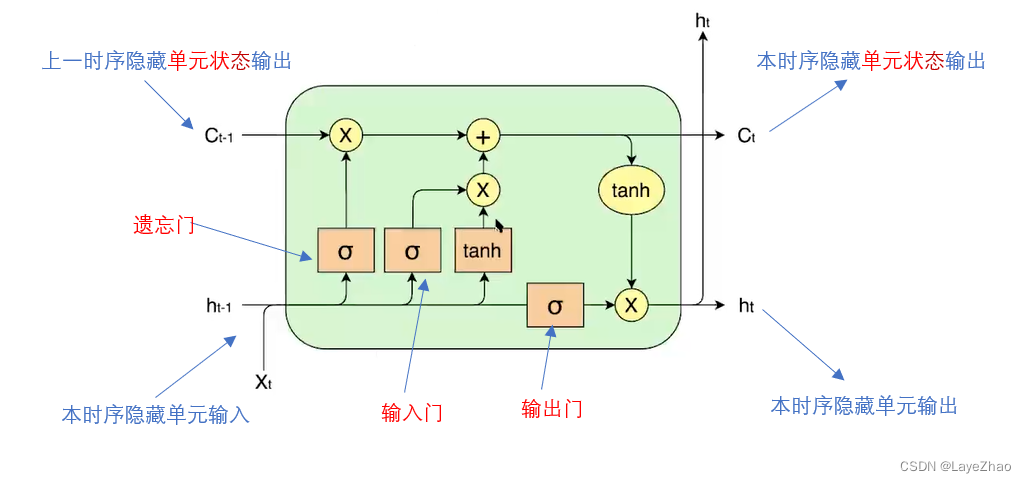
The forgetting gate acts on the hidden state of the previous sequence
. Determine the effect of the previous time series hidden unit state on the current hidden unit.
The input gate acts on the input of the current hidden unit
(the input is the output of the previous hidden unit
and the input of the current hidden unit). Determines the effect of the current input on the current hidden unit.
The forgetting gate combined with the input gate determines the current hidden layer state output , and the output gate
acts on the current output to generate the current hidden unit output.
where are all linear combinations of the inputs of the current hidden unit, and then normalized by the sigmoid function:
1. Lstm implementation in Pytorch----torch.nn.lstm function
parameter:
-
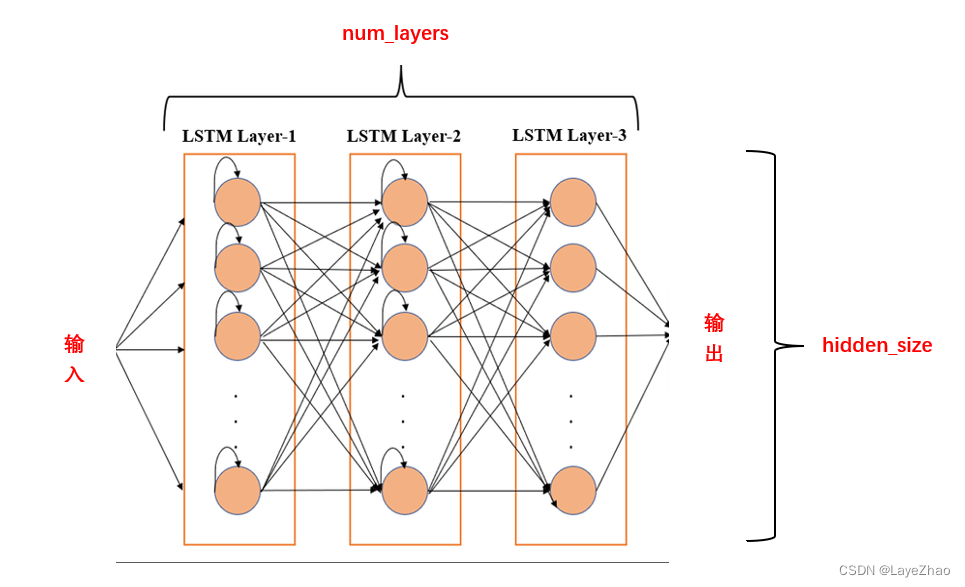
input_size: The number of features of the input data, the dimension of X in the above figure
-
hidden_size: hidden unit size, the dimension of h in the above figure
-
num_layer: Number of hidden layers. LSTM can be stacked in multiple layers in space
-
bias: bias
-
bidirectional: whether it is bidirectional LSTM
-
batch_first: When acting on input data, use batch as the first dimension
2. The entire model input data is a three-dimensional tensor with a size of (seq_len, batch, input_size)
-
seq_len: number of time steps.
It is equivalent to entering a sentence containing several words. Each word of a sentence is input to the model in turn, producing steps in time. Usually all sentence padding is of fixed length
-
input_size: The number of features of the input data, which is also the size of the input hidden unit data, equivalent to the feature dimension (dimension) of each word
-
batch: batch size. It is equivalent to how many sentences are input to the model at one time and processed at the same time.
For example, enter the following verse:
goose
Quxiang Xiangtiange
White hair floating in green water
Anthurium stirs clear waves
Assume that the feature dimension of each word is 6, and the batch size is specified to be 4.
Then in this example: seq_len=5 (the first sentence is automatically padded to 5 characters), batch=4, input_size=6
Each time 4 characters are input into the model, the first batch is: "goose", "qu", "white", "red"
Then the question comes. These four words are not in the same sentence. Their hidden states should be independent of each other and should not affect the next sequential word in different sentences.
We have two parameters that record the hidden unit data: h, c. In h,c, the status of each word (timing) of each sentence in the same batch is saved separately.
3. In addition to the input data, the input model also has two initial states ( , ) of each hidden unit . Note that in pytorch, we do not have to initialize the initial state. 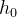
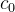
Its size is still a tensor
-
h0(num_layers*num_directions,batch,hidden_size)
-
c0( num_layers*num_directions,batch,hidden_size)
num_layers: Number of LSTM layers, number of layers of hidden units (spatial dimension)
hidden_size: the dimension of the hidden unit (the dimension of )
batch: batch size
Another dimension, batch (batch size), cannot be shown in the figure. It actually ensures that different words in the same batch have their own status data. You can imagine repeating the same sequence a batch of times.
4. The output data of LSTM is also a three-dimensional tensor with a size of (seq_len,batch,num_directions*hidden_size)
The content is the output of the last layer of hidden units
Parameter meaning is the same as above
also,
5. The output data also includes ( 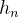 ,
, 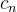 ), which saves the status of each hidden unit in the nth time series.
), which saves the status of each hidden unit in the nth time series.
Its size is:
-
hn(num_layers*num_directions,batch,hidden_size)
-
cn( num_layers*num_directions,batch,hidden_size)
Parameter meaning is the same as above
Rotate the above picture 90 degrees and expand it to different timings. The input, output, hidden unit output and overall state are shown in the figure below
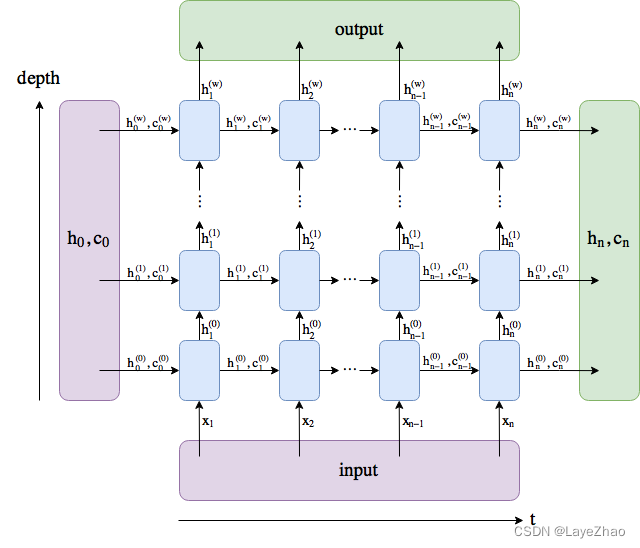
6.A calling example:
input_size=300;hidden_size=100;num_layers=1;batch_size=64;seq_len=7

7.An application example
Use the LSTM model as the encoder layer and splice the linear transformation model (nn.Linear) as the decoder layer to implement an emotion classification model.
Here is the code snippet for model creation:
class SentimentNet(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
bidirectional, weight, labels, use_gpu, **kwargs):
super(SentimentNet, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.use_gpu = use_gpu
self.bidirectional = bidirectional
self.embedding = nn.Embedding.from_pretrained(weight)
self.embedding.weight.requires_grad = False
self.encoder = nn.LSTM(input_size=embed_size, hidden_size=self.num_hiddens,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=0)
if self.bidirectional:
self.decoder = nn.Linear(num_hiddens * 4, labels)
else:
self.decoder = nn.Linear(num_hiddens * 2, labels)
def forward(self, inputs):
embeddings = self.embedding(inputs)
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
encoding = torch.cat([states[0], states[-1]], dim=1)
outputs = self.decoder(encoding)
return outputs
For other codes such as data cleaning and model training, please see this project