
1. Description
GAN, the abbreviation of Generative Adversarial Network, is an unsupervised learning algorithm proposed by Goodfellow et al. in 2014. GAN consists of a generator network and a discriminator network. Through the confrontation between the two, the generator network is trained to generate fake samples that are similar to real samples. The generator and discriminator compete against each other to continuously improve their performance. GAN is widely used in generation tasks in image, speech, natural language and other fields.
2. Overview of generating AI & GAN
GANs are a type of machine learning that can generate new examples using the original data set used to train the model. There are two neural networks here: generator and discriminator. Here, agents play against each other in a zero-sum game, where one agent's win is another agent's loss. The goal of the generator is to create fake data that is as realistic as real data, while the goal of the discriminator is to identify fake data from real data. The two networks play a game of cat and mouse until the generator creates data that the discriminator cannot distinguish from real data.
While many AI algorithms exist, one type of AI that is creating a buzz in the industry is generative AI. With the increasing popularity of generative AI tools like ChatGPT and Midjourney, users can now generate new ideas, content, and solutions faster than ever before.
2.1 What is generative artificial intelligence?
Generative AI is a subfield of artificial intelligence that utilizes unsupervised and semi-supervised machine learning techniques. Generative AI describes algorithms and models that can be used to create entirely new content, including audio, video, text, and even simulations.
It has a host of practical uses, from improving image resolution and creating new business models to being used to develop new drugs in the medical field.
Unlike other forms of AI, such as predictive or classification models that are trained to make predictions or classify data, generative AI models aim to create new data that is similar to the original input data.
2.2 Generating models for artificial intelligence?
Some of the prominent frameworks or models for generating artificial intelligence are:
- 1. Generative adversarial network
- 2. Transformer-based model
- 3. Variable speed automatic encoder
- 4. Bert
- 5. Autoregressive model
- 4. Bert
- 3. Variable speed automatic encoder
- 2. Transformer-based model
3. Generative Adversarial Network (GAN)
3.1 Understand the components of GAN
Generative adversarial network (GAN) is an artificial neural network architecture in machine learning and deep learning. It consists of two neural networks, a generator and a discriminator, which are trained together in a competitive process. The generator attempts to generate data (such as images, text, or audio) that is indistinguishable from real data, while the discriminator is tasked with distinguishing real data from generated data. This adversarial training process helps the generator continually improve its ability to create increasingly realistic data.
Imagine you want to create realistic landscape paintings. You decide to use GAN for this purpose.
- Generator (Artist): A generator is like an artist starting from a blank canvas. Initially, it randomly generates an image that doesn't look like a landscape at all.
- Discriminator (Art Critic): A discriminator is like an art critic. It shows real landscape paintings (from the dataset) and fake landscapes created by the generator. In the beginning, the discriminator was terrible at distinguishing real paintings from fake paintings because the generator did such a bad job.
- Training process:
- The generator creates a false landscape.
- The discriminator evaluates it. If it detects that it is fake, it provides feedback to the generator.
- The generator uses this feedback to try to create a more convincing landscape.
- This process repeats in a loop. Over time, the generator gets better at making realistic landscapes, and the discriminator becomes more adept at telling what's real and what's fake.
End result: After many iterations, the generator becomes so good at creating landscapes that the discriminator can barely differentiate between real and generated paintings. You now have a GAN that can produce highly realistic landscape paintings!
3.2 FAN architecture.

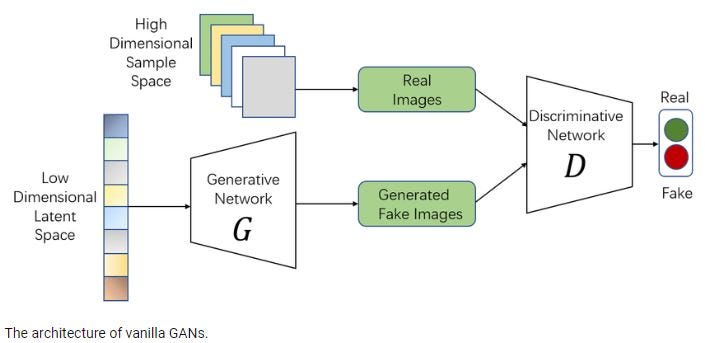
GAN is a deep learning architecture consisting of two neural networks working together: a generator and a discriminator. The generator and discriminator are trained together in a process called adversarial training. During training, the generator takes random noise as its input and converts this noise into meaningful output, i.e. fake data that resembles real data.
As for the discriminator, it accepts the output of the generator and real data as input and outputs a probability score if the input is true or false. Both networks are trained together. The generator receives probability scores from the discriminator as feedback on how to improve the quality of the generated data, and the cycle continues. The discriminator is trained using backpropagation to adjust its weights and biases to minimize its classification error. As the generator improves, the discriminator performance decreases because it cannot easily differentiate the data.
The optimal stage is reached when the discriminator cannot determine whether the data comes from the generator or the actual dataset.
3.3 Generator and evaluator of GAN
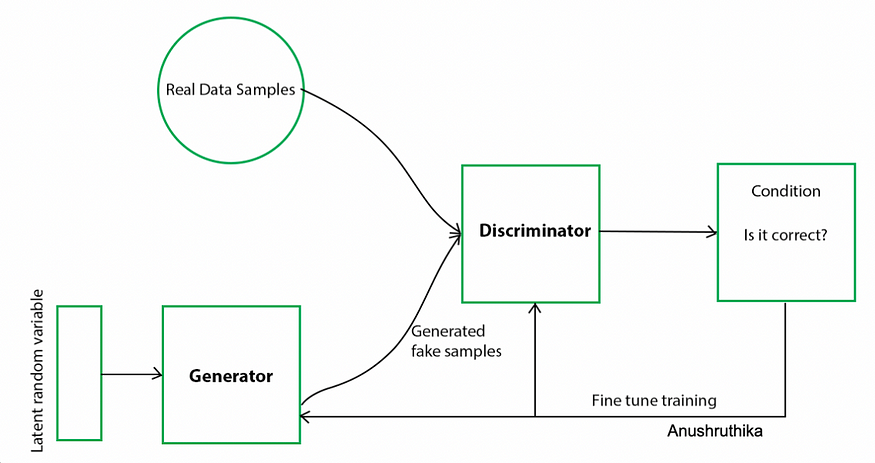
In every GAN, you provide a random noise seed or latent vector, which can be a 2D array or 2D array that is sent as input to the generator as noise. The generator network amplifies this array to create a fake 2D image. Now, both fake and real images are sent to the discriminator network, which is trained to classify real and fake images.
The maximum number of cycles is fine-tuned based on the generator loss and discriminator loss.
3.4 5 steps to implement GAN
- Define the GAN architecture according to the application
- Train the discriminator to distinguish between real and fake
- Train the generator on fake data, which can fool the discriminator and look realistic
- Continue training the discriminator and generator for multiple epochs.
- Save the generator model to create new fake data.
During training of the generator, the discriminator value is held constant, while training the discriminator holds the generator value constant. Everyone should train against static opponents.
application
- Generate fake data to enhance other machine learning algorithms
- Generate faces
- image to image conversion
- Text to image translation
- Super Resolution: Get higher resolution pictures.
4. Application of GAN.
GANs have a wide range of applications, including the following:
1. Images and Videos: GANs can create realistic videos and images that can be used for graphics and animations.
2. Image super-resolution: Use super-resolution generative adversarial network (SRGAN) to improve the resolution of the image
3. Text to Speech: GAN can be used to generate speech from provided text using GAN-TTS (Generative Adversarial Network for Text to Speech)
Generative adversarial networks are powerful tools in AIML that revolutionize the way machines interact with data. As GANs continue to develop and advance, they will have a greater impact on shaping the future of AI and driving innovation. The growth of generative AI demonstrates the huge potential and impact of GANs.
5. Table GAN (generating AI)
Tabular GAN is a generative adversarial network (GAN) specifically designed to generate synthetic tabular data. Unlike image data, tabular data is typically represented as a feature matrix, where each row represents an instance or observation and each column represents a feature or attribute.
Tabular GANs use architectures more suitable for tabular data, such as multilayer perceptrons (MLP) or convolutional neural networks (CNN) with 1D filters. The generator network takes random noise vectors as input and produces a synthetic tabular dataset as output. The discriminator network attempts to differentiate between real and synthetic data by outputting a binary classification score.
The training process of tabular GANs involves updating the generator and discriminator networks in an adversarial manner, where the generator tries to generate synthetic data that can fool the discriminator, and the discriminator tries to correctly distinguish between real and synthetic data. The goal of the generator is to minimize the loss of the discriminator on synthetic data, while the goal of the discriminator is to maximize the loss of synthetic data and minimize the loss of real data.
Tabular GANs have various applications, such as generating synthetic datasets for data augmentation, imputing missing values in datasets, and generating data for testing and validation purposes. However, they also have some limitations, such as the risk of generating biased or unrealistic data if the training data is not representative of the real population.
#GANs #GenerativeAI
6. Generative AI: GAN verification technology
Generative Adversarial Networks (GANs) have several validation techniques used to evaluate the quality and performance of generated samples. Some of the most common verification techniques for GANs are:
- Initial Score (IS): This technique uses a pre-trained initial model to calculate a score that measures the diversity and quality of the generated images. The score is calculated based on the similarity between the generated image and the real image in terms of class distribution and visual quality.
- Frechet Inception Distance (FID): This technique also uses a pre-trained Inception model, but calculates the distance between the feature representation of the real image and the generated image in a high-dimensional feature space. A lower FID score indicates that the generated image is more similar to the real image.
- Precision and Recall (PR): This technique evaluates the precision and recall of generated samples relative to real samples. Precision measures the percentage of generated samples that are similar to the actual samples, while recall measures the percentage of actual samples that are similar to the generated samples.
- Visual inspection: This technique involves visually inspecting the generated sample and comparing it with the real sample. This is a subjective technique, but can provide valuable insights into the visual quality and diversity of the generated samples.
- User Study: This technique involves conducting user studies to assess the perceived quality and diversity of the generated samples. This technique is more subjective and may vary based on participant preferences and biases.