Today, in this blog, let's learn about an important and difficult knowledge in microservices: distributed transactions.
We will learn based on the Seata framework.
1. Distributed transaction issues
Transactions, we should have a better understanding, we know that all transactions must meet the principles of ACID. that is
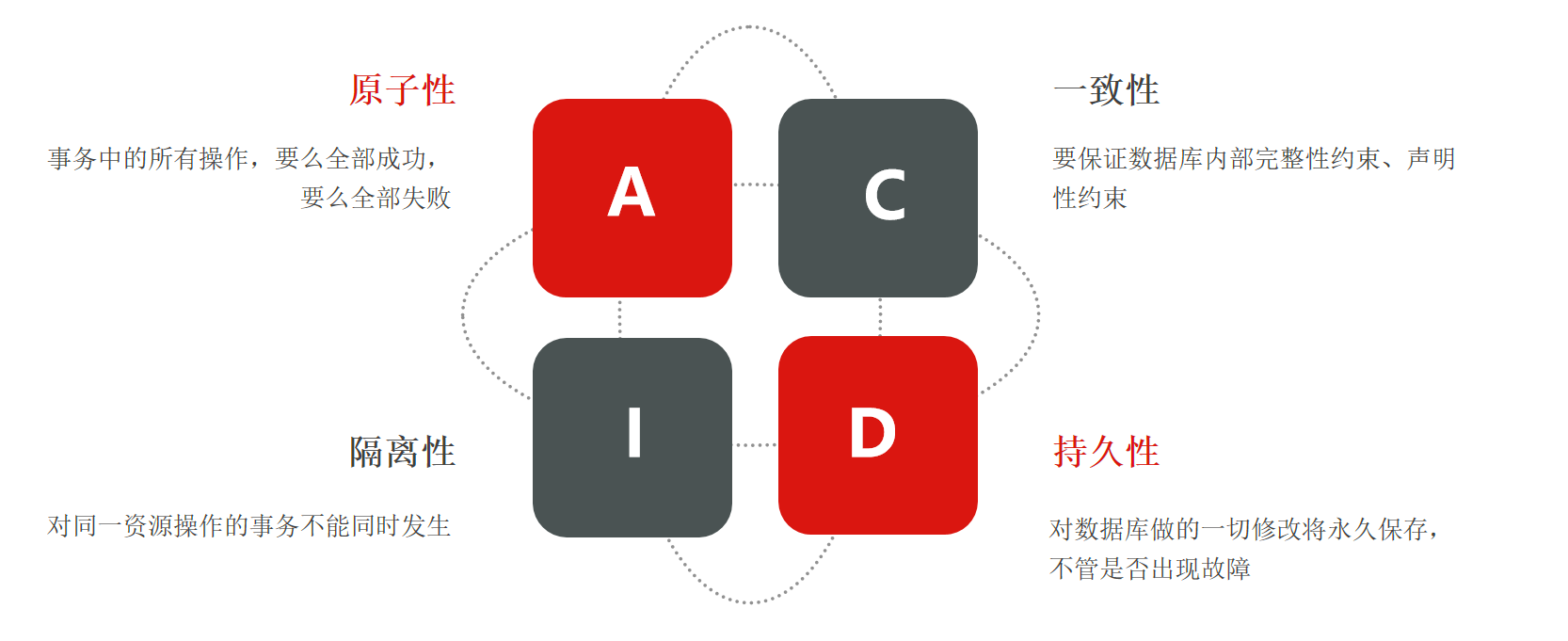
This service in the single architecture we learned before directly accesses a database, and the business is relatively simple. Based on the characteristics of the database itself, ACID can already be realized.
However, what we are going to look at now is microservices. The business of microservices is often more complicated. Maybe one business will span multiple services, and each service will have its own database.
At this time, if you rely on the characteristics of the database itself, can you still guarantee the ACID of the entire business? This is not necessarily the case.
Let's look at an example.
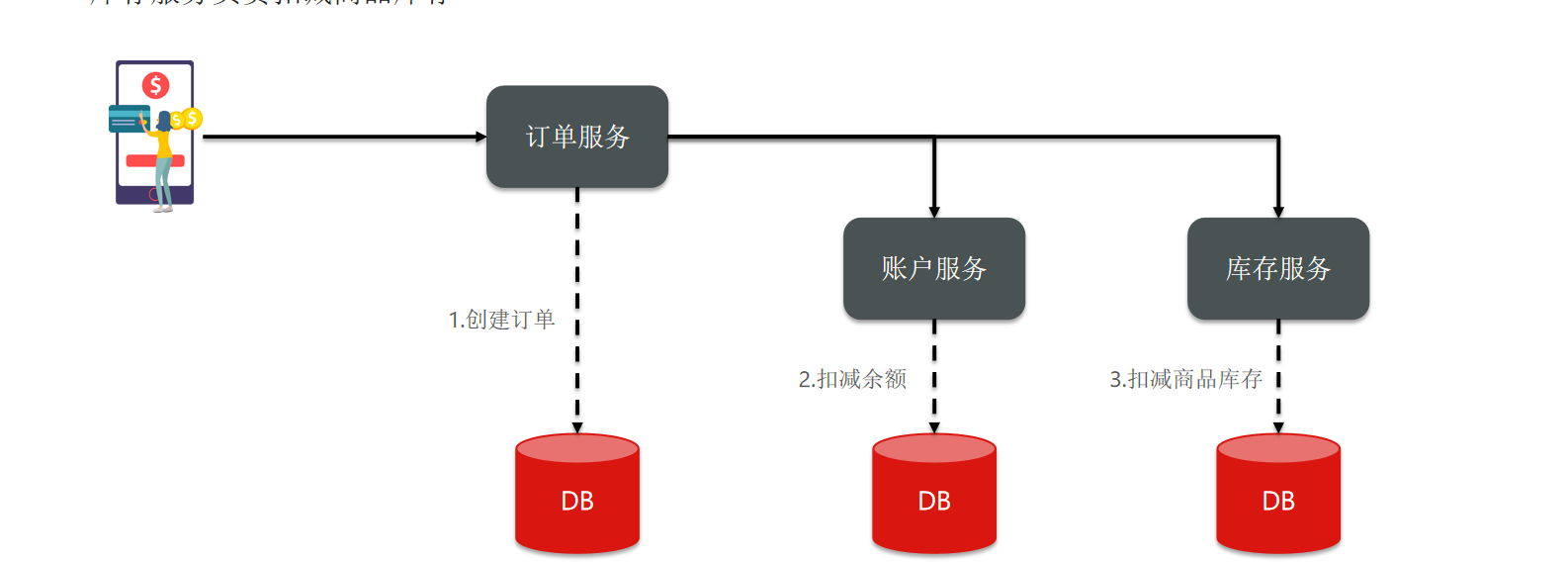
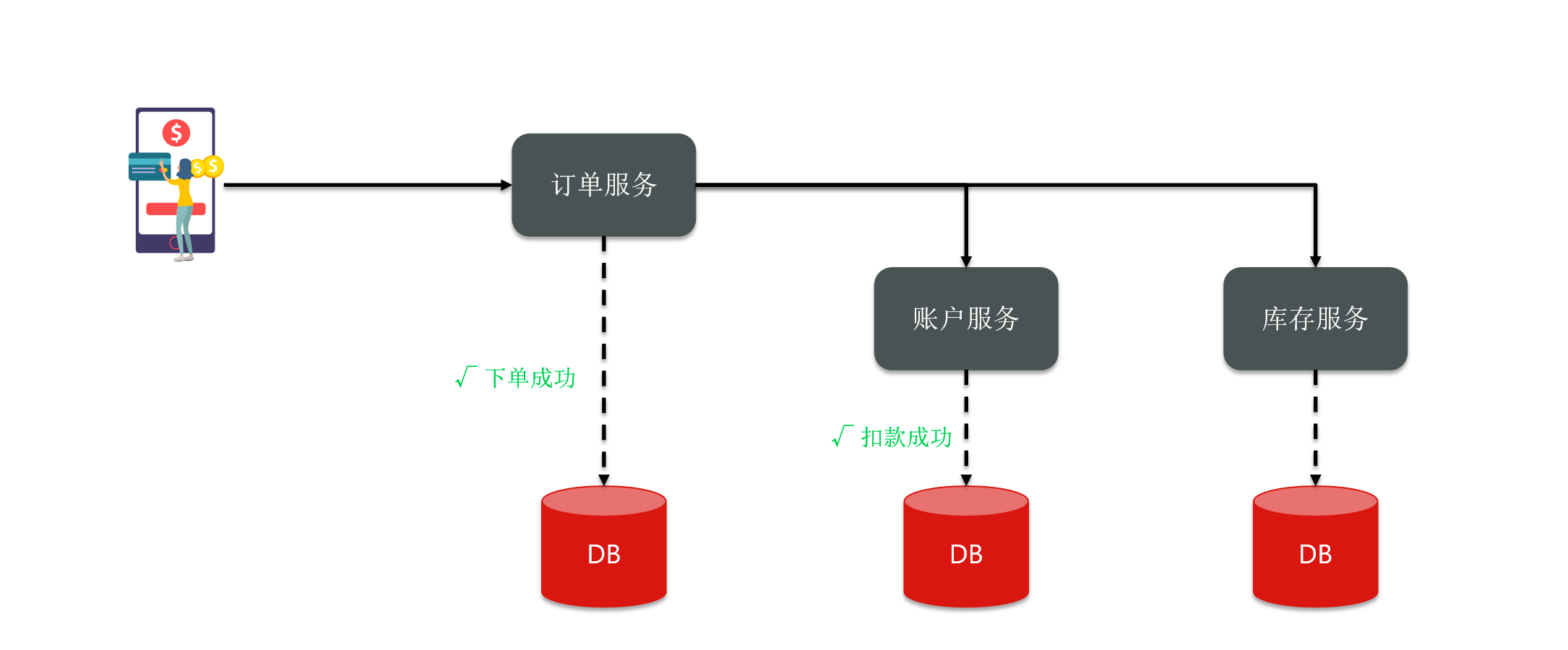
For example, I have a microservice here, which contains three services, including orders, accounts and inventory.
Now, we have a business where the user places an order. When the user places an order, I want the order service to create the order and write it to the database.
Then, he calls the account service and inventory service. The account service deducts the user's balance, and the inventory service deducts the product inventory.
Then you can see that this business contains calls to three different microservices, and each microservice has its own independent database, which is an independent transaction.
Then what we ultimately hope for is that once my order business is executed, will every order be successful? Of course, if you fail, does everyone fail?
1.1 Demonstration of distributed transaction problems
The result is such a result, but can such an effect be achieved? Let's verify.
The microservice structure is as follows:
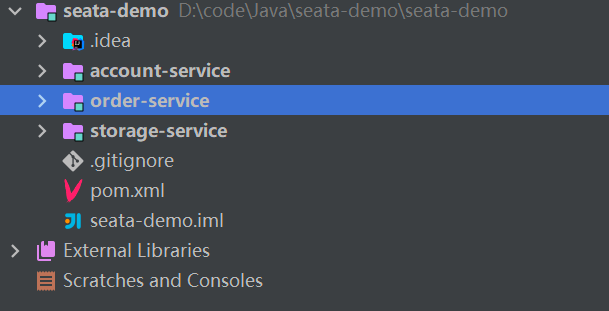
in:
seata-demo: parent project, responsible for managing project dependencies
- account-service: Account service, responsible for managing users’ capital accounts. Provides an interface for deducting balances
- storage-service: Inventory service, responsible for managing product inventory. Provides an interface for deducting inventory
- order-service: Order service, responsible for managing orders. When creating an order, account-service and storage-service need to be called
Let's take a look at this order (order service) first. Look at the business logic in it. In the controller, we can see an interface for creating orders.
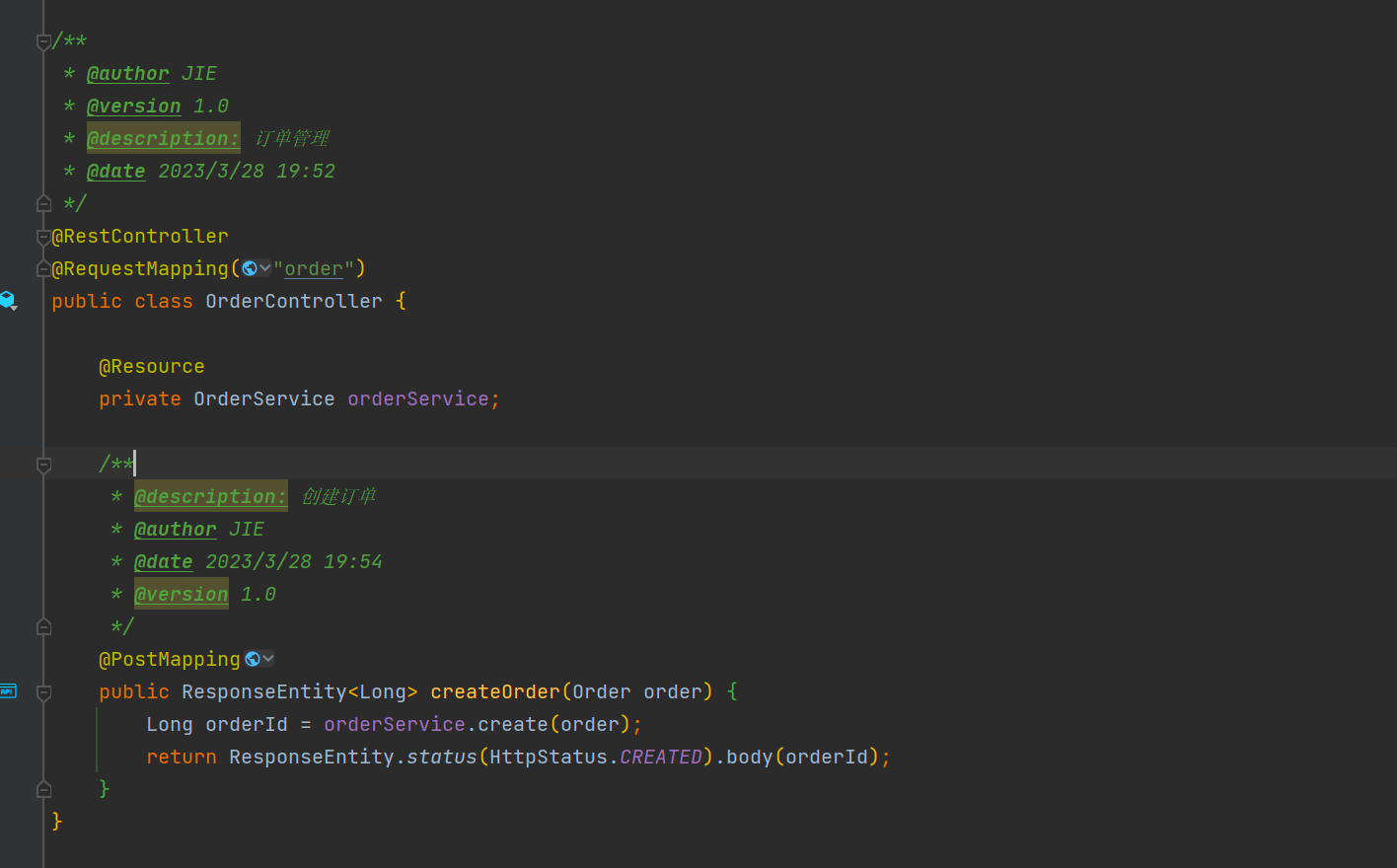
In the controller, it calls the service, so we go into the service method.
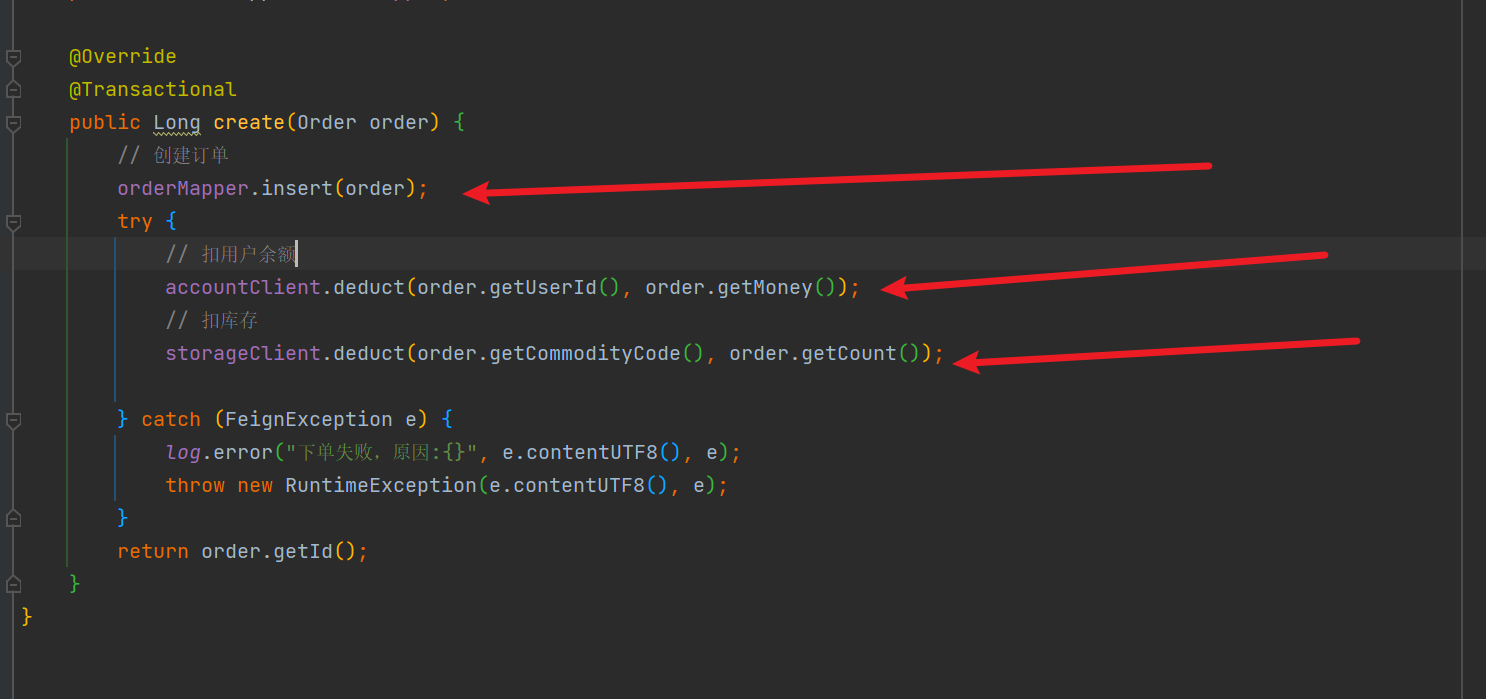
In this service method, we can see that it first creates an order and writes the order data directly to the database.
After creating the order, call accountClient (deduct user balance) and storageClient (deduct inventory) to complete deduction of balance and inventory.
accountClient and storageClient are called by Feign.
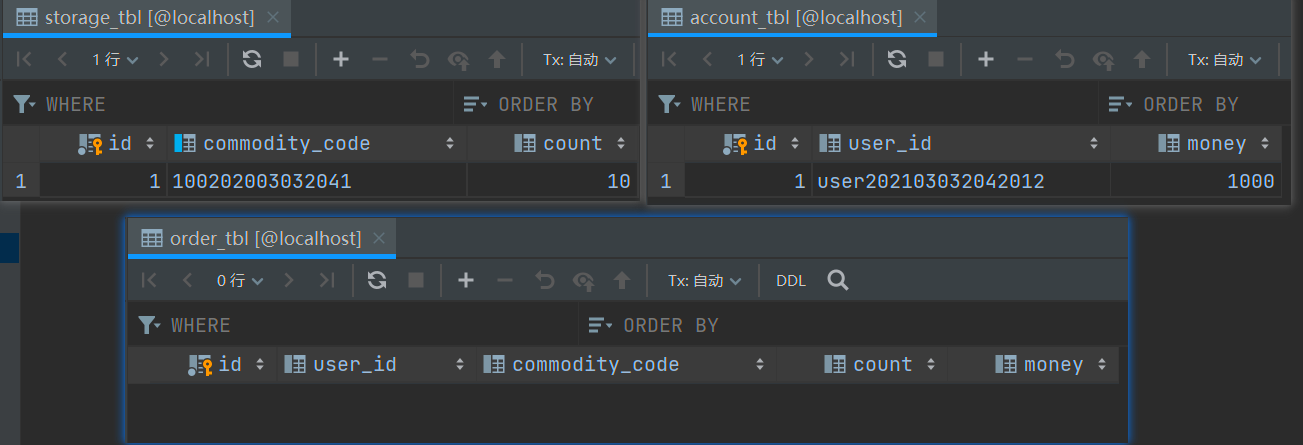
This is the data from these three tables.
The business logic is like this, let's use Postman to test it next.
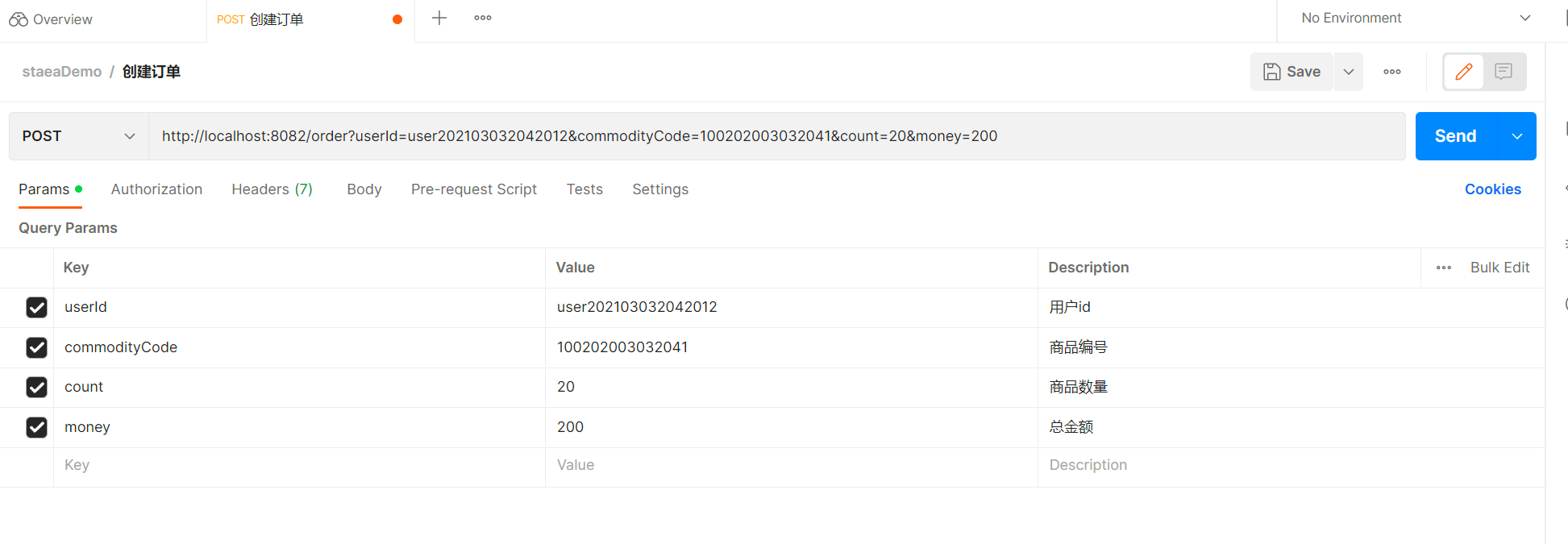
We send a request.

500 was returned, let's take a look at the database.
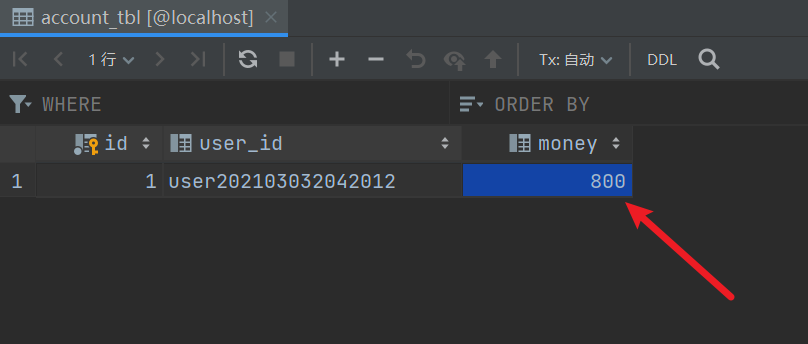
It is found that the user balance is 200 less.
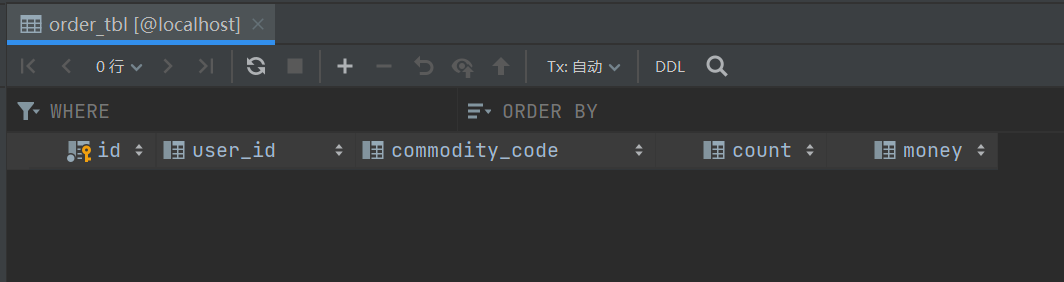
order was not created
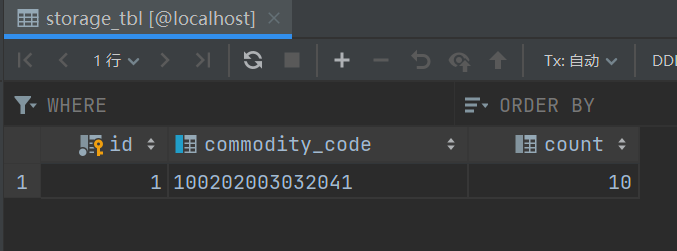
Inventories are not decreasing either.
Is the status of the transaction consistent at this time? no?
So why is this happening?
In the business just now, our order service created an order.
Then call the accounting service and inventory service to complete the balance deduction and inventory deduction.
Among them, the order and accounting services have been successfully executed.
However, when the inventory service was executed, an error was reported due to insufficient inventory.
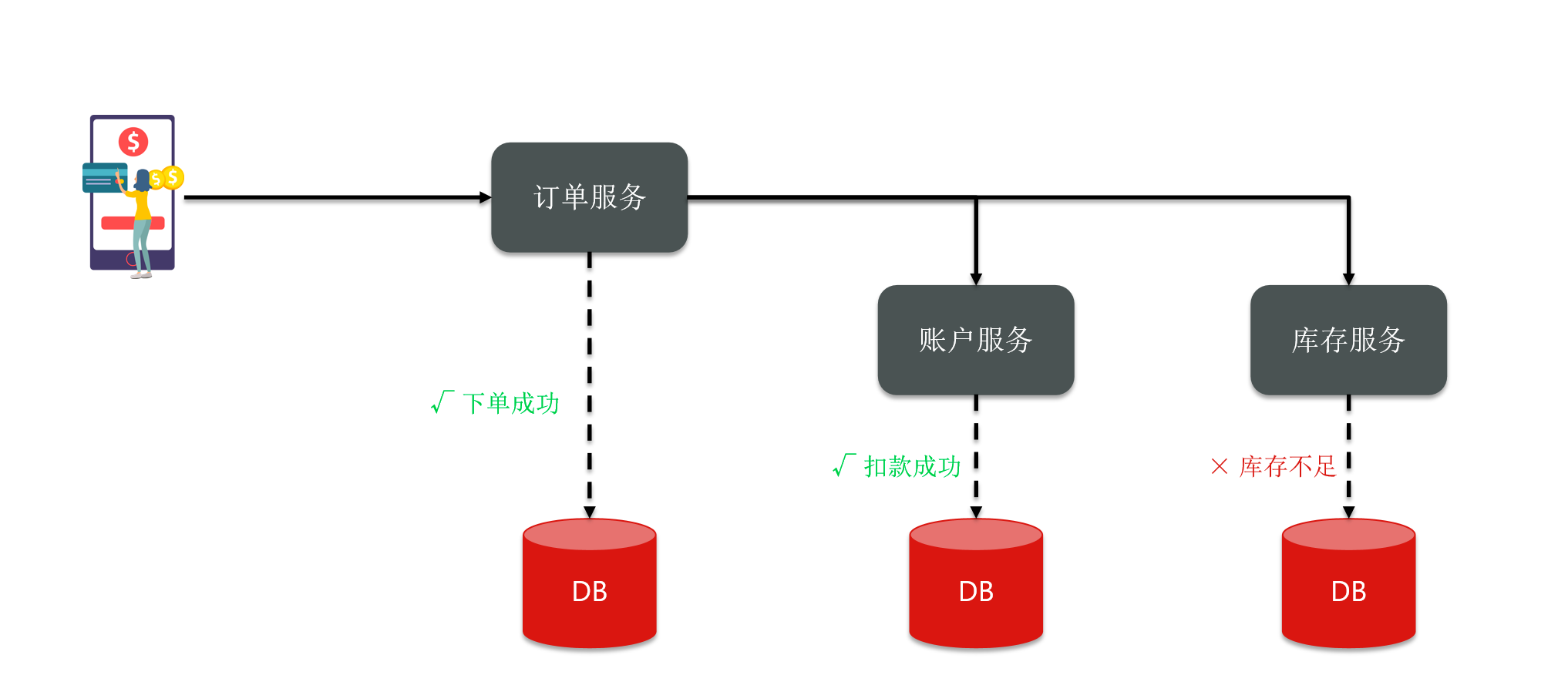
Theoretically speaking, if an error is reported here, shouldn't everything else be rolled back? But the result we have seen is that the inventory service has failed. Should the balance of the account be deducted or deducted? why?
First, each of our services is independent.
Then now you throw an exception in the inventory service.
Does the account service know about it? It doesn't know!
Then I don't even know that you threw an exception, what should I roll back?
Second, each service is independent, so their affairs are also independent.
Now for my order service and accounting service, after I finish the business and my transaction is over, should I submit it directly?
Now you ask me to roll back, how do I roll back? I have done everything, submitted it, and it cannot be undone.
So in the end, the transaction status was not consistent. Then at this time, the problem of distributed transactions appeared!
1.2 What is a distributed transaction
Then let's summarize what is a distributed transaction.
A business under distributed system, which spans multiple services and data sources. Each service can be considered as a branch transaction, and what we want to ensure is that the final state of all branch transactions is consistent.
Either everyone succeeds, or everyone fails. Then such a transaction is a distributed transaction.
So why is there a problem with distributed transactions?
This is because the various services, or the transactions of various branches, are not aware of each other. If everyone submits their own affairs, they will not be able to roll back in the future, resulting in inconsistent status.
2. Theoretical basis
Next, we will enter the study of the theoretical basis of distributed transactions.
Solving distributed transaction problems requires some basic knowledge of distributed systems as theoretical guidance.
2.1 CAP theorem
The CAP theorem was proposed by Eric Brewer, a computer scientist at the University of California in 1998. It said that there are often three indicators in a distributed system.
They are:
- Consistency
- Availability
- Partition tolerance
As Eric said, it is impossible for a distributed system to meet these three indicators at the same time.
You are like these three circles, don't you just distinguish three characteristics?

But you can see that these three circles will not overlap three at the same time, at most two will overlap.
Then this conclusion is called the CAP theorem. So why does such a situation occur?
We must first figure out the meaning of consistency, availability and partition fault tolerance to understand the meaning of this.
2.1.1.Consistency
Let's take a look at the first one, consistency.
Consistency means that the data obtained by users when accessing any node in the distributed system must be consistent. Let's say I have two nodes now.

There is a data called data on the first node, and the value is v0, and the same is true on the second node. So what do they actually form? Master-slave.
Now the user visits these two nodes, no matter who is visiting, will the results be the same?
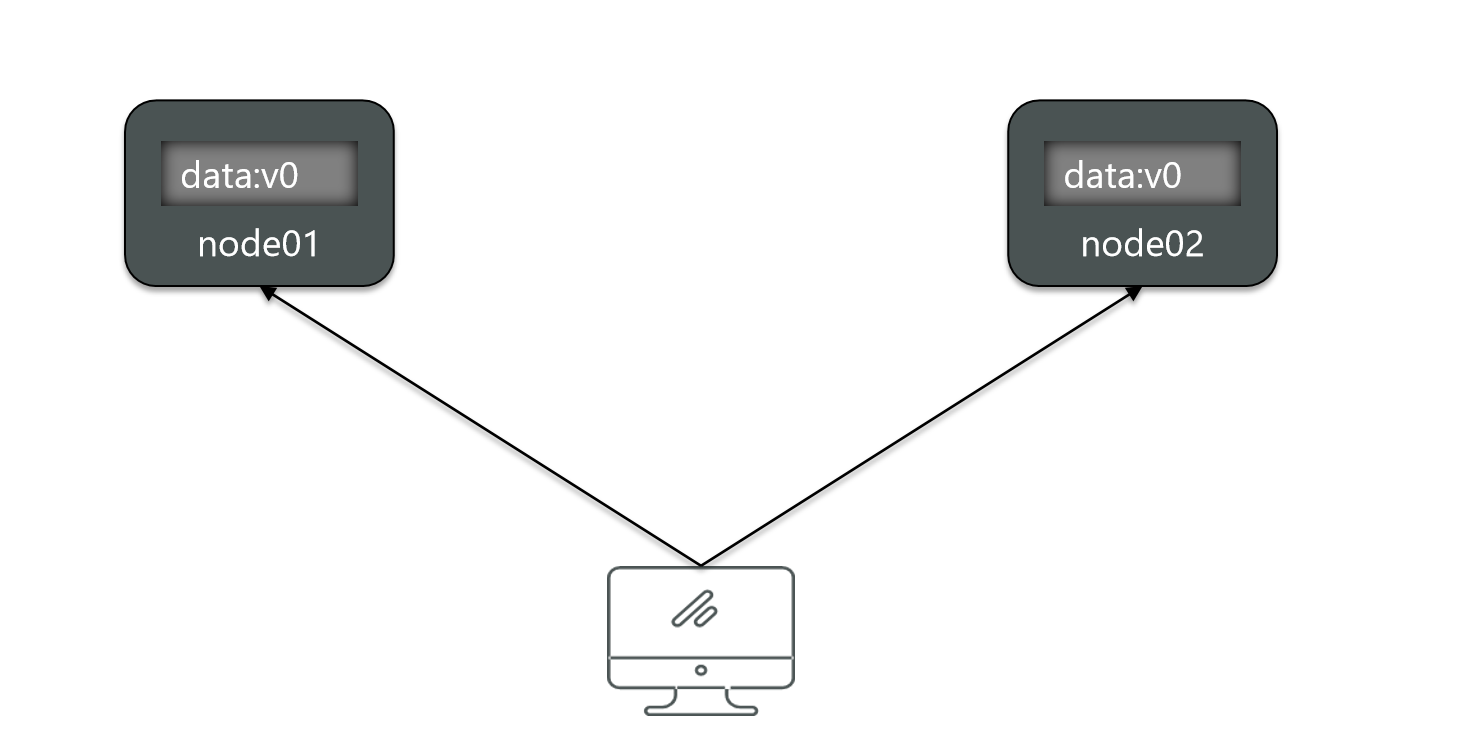
But now, if I modify the data of node 1.
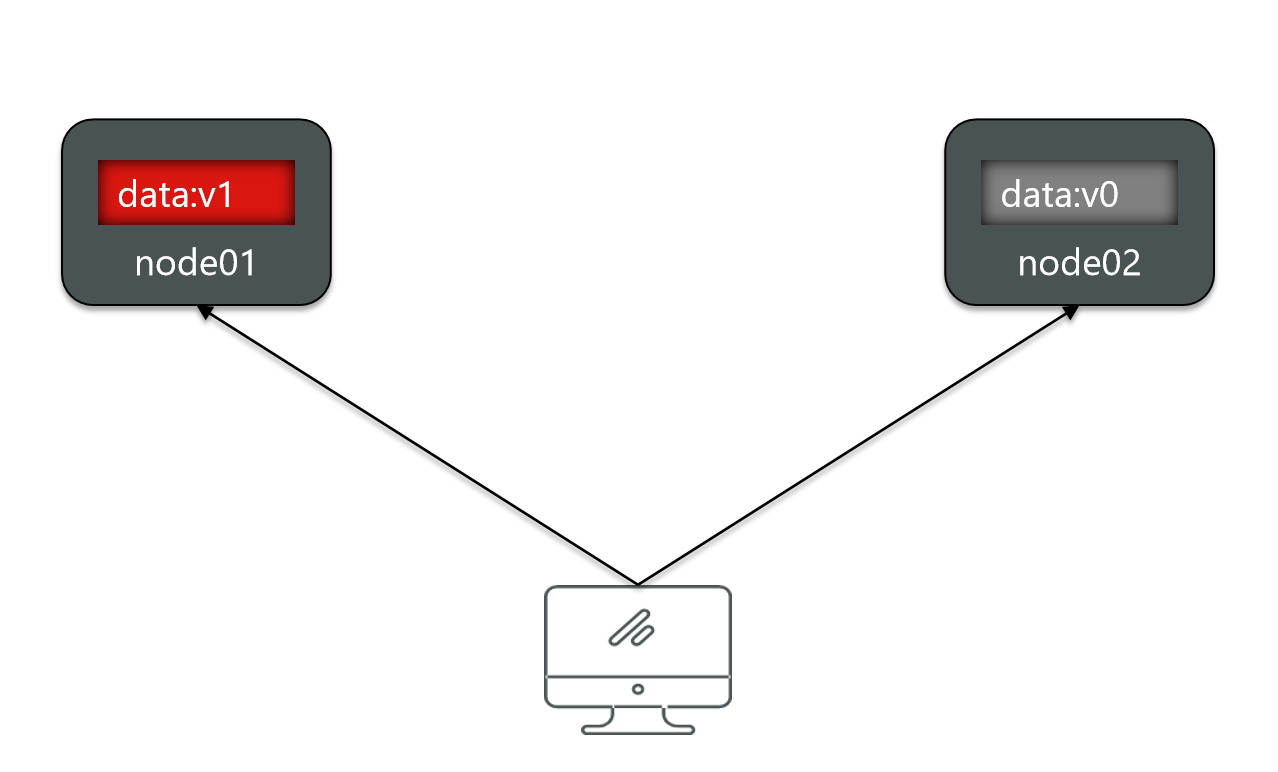
Is the data of the two nodes different at this time?
So what do you do to achieve consistency?
Do you have to synchronize the data of node 01 to node 02?
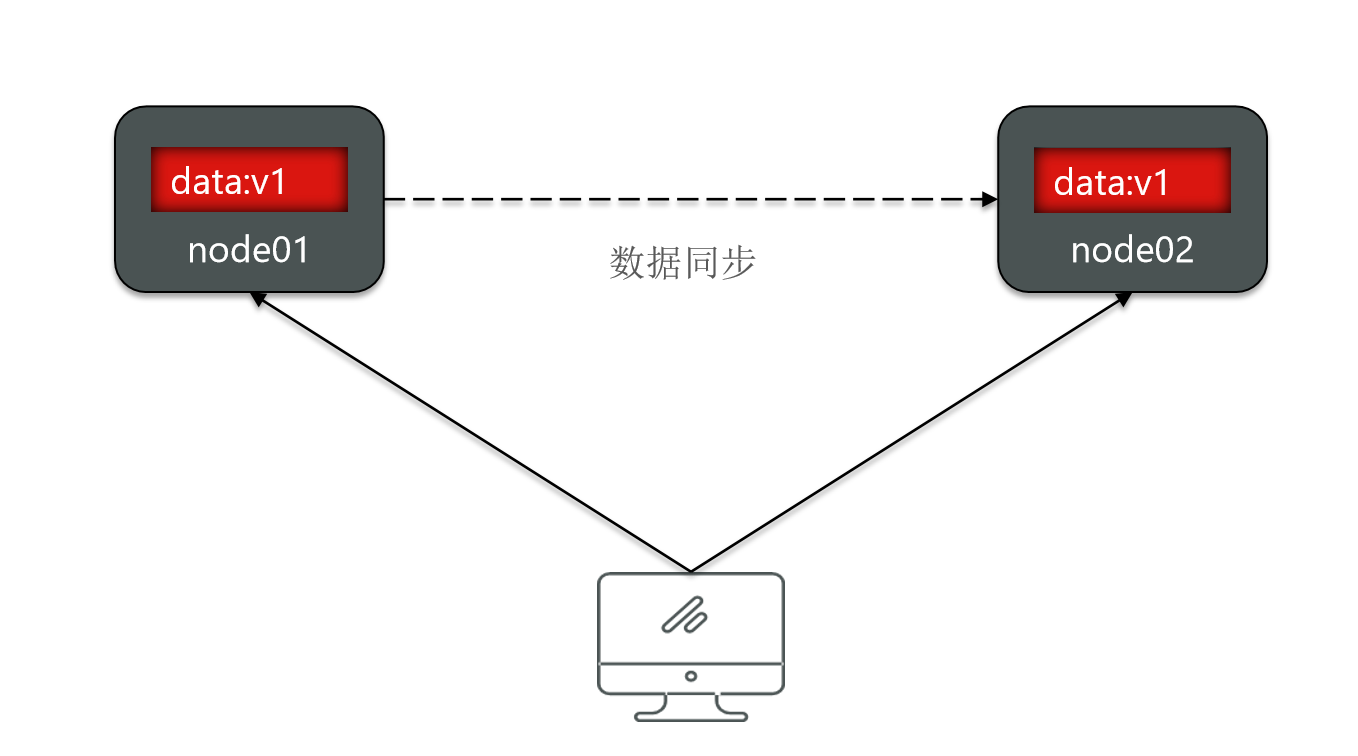
Once the data synchronization between the two is completed, is the data consistent again? So, as a distributed system.
When doing data backup, you must complete data synchronization in a timely manner to ensure consistency.
2.1.2. Availability
The second concept is usability.
It says that when users access any healthy node in the cluster, they must get a response instead of timeout or rejection.
For example, I currently have three nodes in this cluster.

Under normal circumstances, there is no problem for users to access any of them.
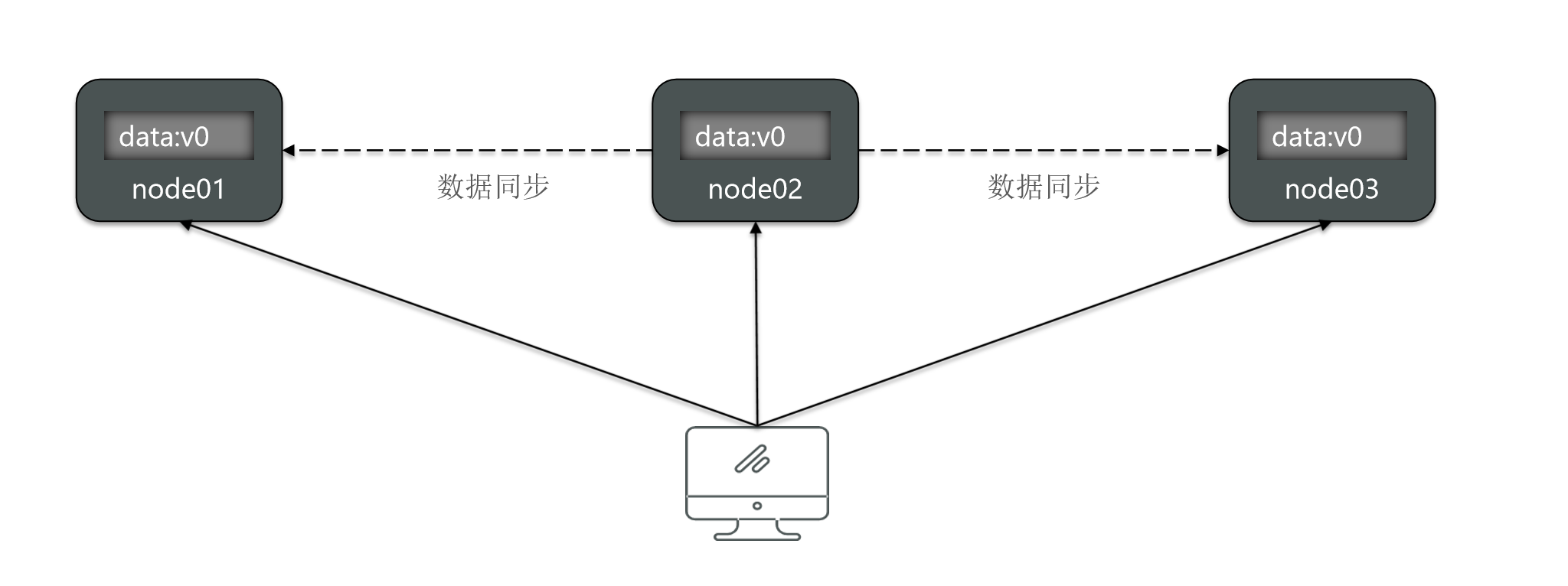
Now, these three nodes have not experienced any downtime. But I don't know why, for example, this node3, its request will be blocked or rejected.
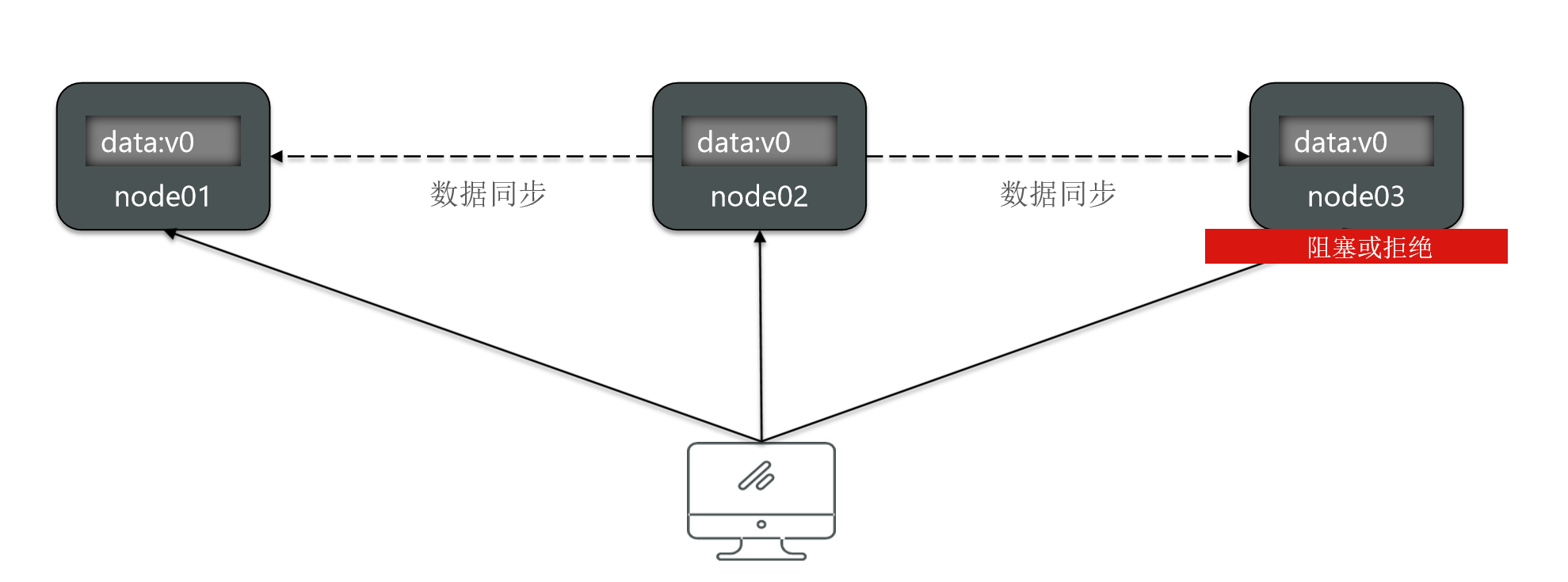
Then all requests come in and cannot be accessed at all. At this time, node3 is not available. So availability refers to whether this node can be accessed normally.
2.1.3 Partition fault tolerance
The third concept: partition fault tolerance.
Partition refers to the fact that due to network failure or other reasons, some nodes in the distributed system lose connection with other nodes, forming an independent partition.
For example, these three nodes are still node 123.
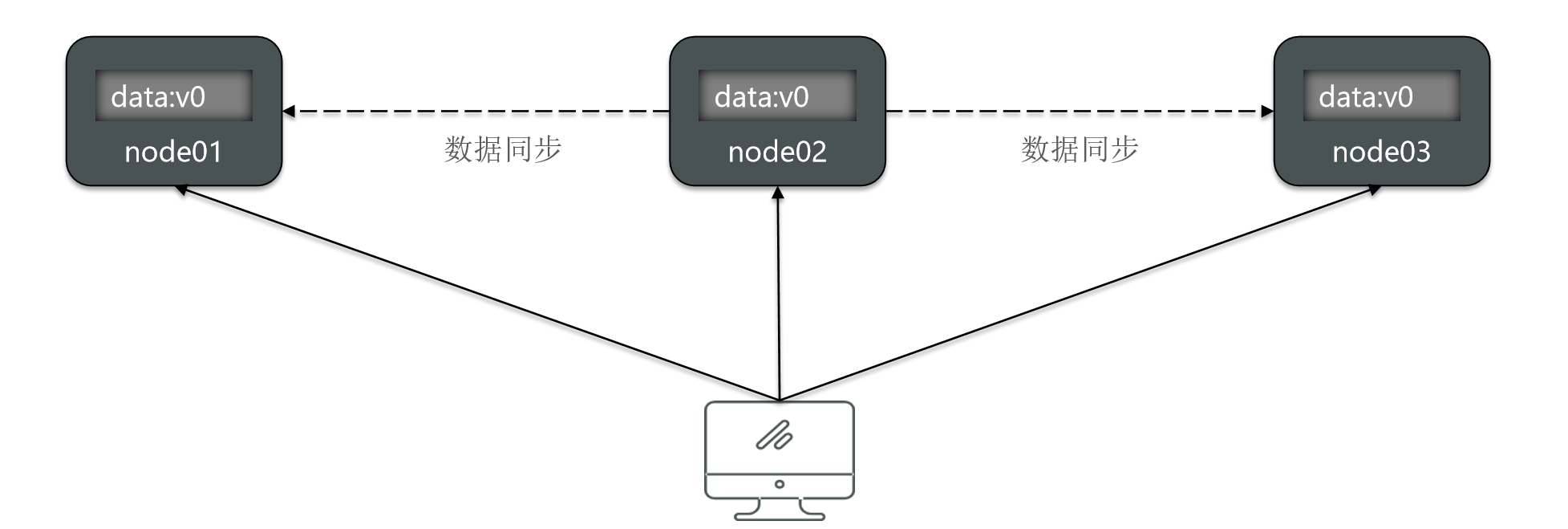
Then the user can access any of them.
But because the network failed, the machine did not hang up, and then the connection between node 3 and node 1 and node 2 was disconnected.
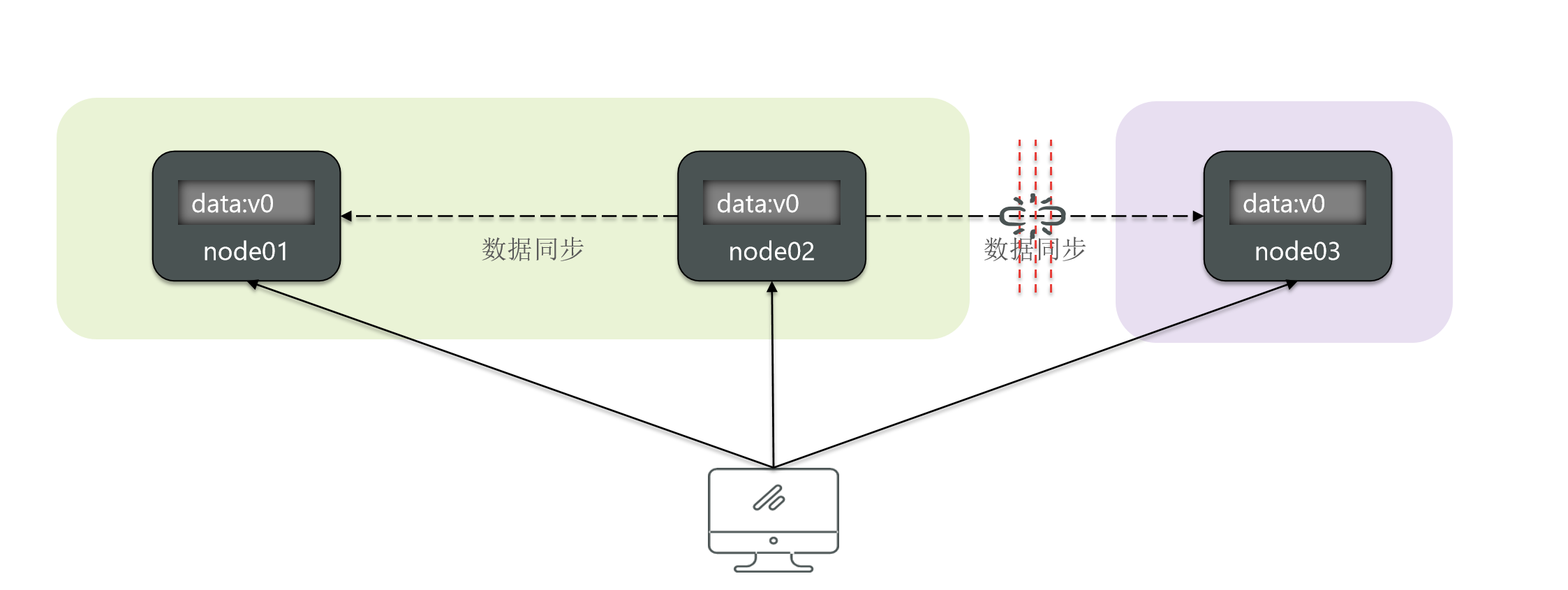
Node 1, node 2, normal access, they can perceive each other, but node 3 can't perceive each other. So, at this point the entire cluster will be divided into two zones.
Then node1 and node2 are in the same area, and node3 itself is a partition.
At this time, if a user writes a new data to node 02.
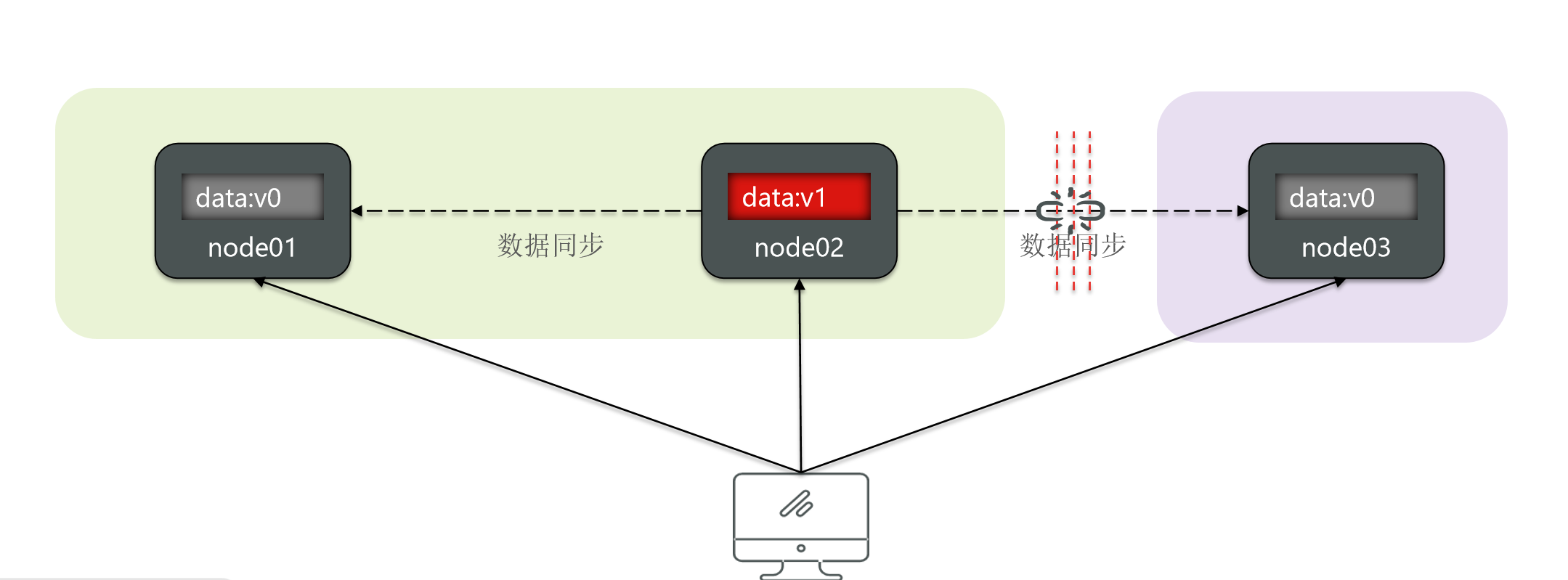
Then node 02 can synchronize data to node 01.
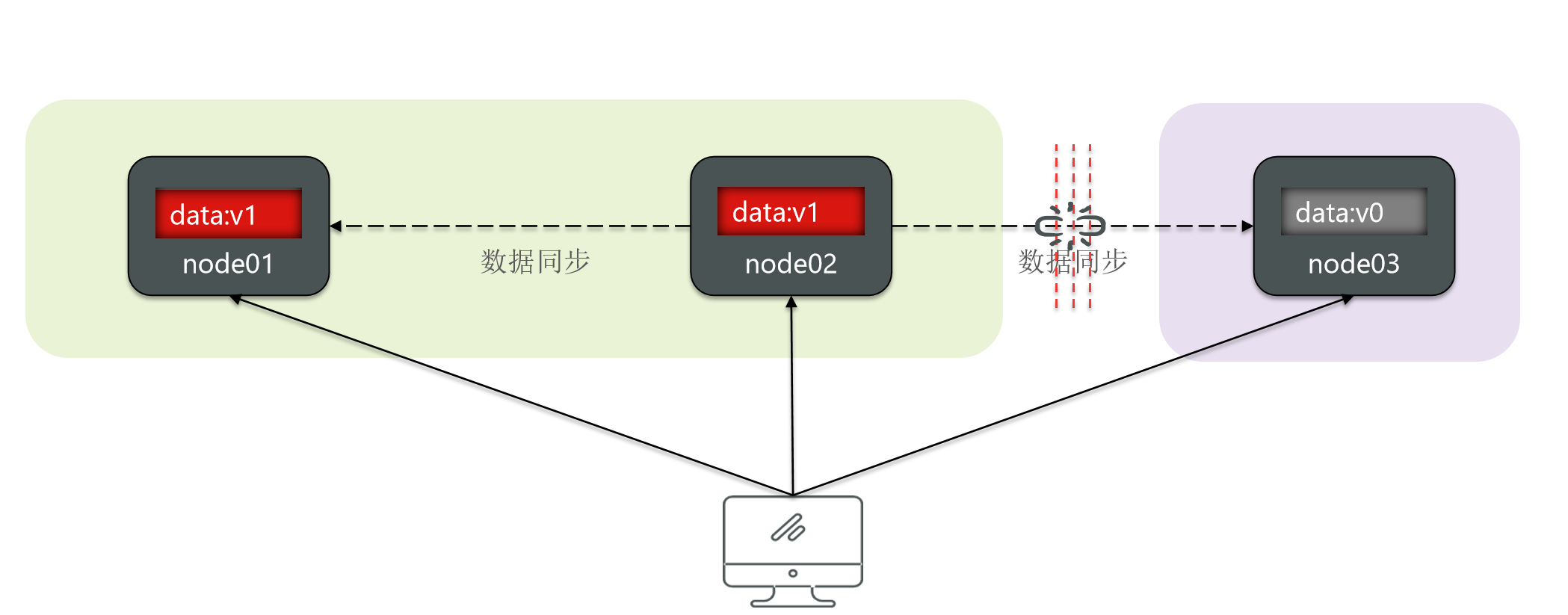
But is there synchronization on node 3?
Obviously not, because they can't perceive it, how to do synchronization?
Then the data of the two partitions will be inconsistent.
So what does partition fault tolerance mean?
Fault tolerance means that the entire system must continue to provide external services regardless of whether the cluster is partitioned or not.
2.1.4.Contradiction
That is to say, even though you have partitioned here, do users still need to access it?
But if I go to visit node1 now, will the result I get be the same as the result of visiting node3? no the same.
So there is a data inconsistency, and the consistency is not satisfied. So if I must satisfy consistency.
what should I do? So can I do this?
I let node 3 wait for the recovery of the network and data synchronization of node 2.
before recovery. All the requests to visit me, I will block here, saying that my data is not ready yet.
Is it possible?
If I do this, will I be able to satisfy the data consistency? But your node3 is obviously a healthy node, but you are stuck here for incoming requests, and people are not allowed to visit it.
Then wouldn’t node3 become unavailable? So it doesn't satisfy usability.
So you will now find that when the network is partitioned, is there no way to satisfy availability and consistency at the same time? However, this partition is inevitable.
Why do you say that?
As long as you are a distributed system, do your nodes have to be connected through the network? And as long as you are connected through the network, do you have a way to ensure that the network is 100% always healthy?
This is impossible, right?
So we can think that all distributed system partitions will definitely appear, since partitions will definitely appear.
And your entire cluster must provide services to the outside world, so that means.
Partition tolerance must be achieved, so at this time, do you have to make a choice between Consistency and Availability? You either have Consistency or Availability. There is no way to be satisfied at the same time,
This is one reason for the CAP theorem.
2.2 BASE theory
We have already studied the theorem of CAP. We know that in a distributed system, because partitioning is inevitable, you have to make a choice between consistency and availability. However, these two characteristics are actually very important. I I don’t want to give up on any of them, so what should I do?
Well, then BASE theory can just solve this problem.
BASE theory is a solution to CAP. In fact, it mainly contains three ideas:
- Basically Available : When a failure occurs in a distributed system, partial availability is allowed to be lost, that is, core availability is guaranteed.
- **Soft State (soft state): **In a certain period of time, an intermediate state is allowed, such as a temporary inconsistent state.
- Eventually Consistent : Although strong consistency cannot be guaranteed, data consistency will eventually be achieved after the soft state ends.
In fact, the BASE theory is a reconciliation and choice for the contradiction between Consistency (consistency) and Availability (availability) in CAP.
In CAP, if you want to achieve consistency, you have to sacrifice availability. But in BASE, if we achieve strong consistency, you have to sacrifice availability, but it is not unavailability, but a sacrifice or temporary loss of partial availability. is not available.
2.3. Ideas for solving distributed transactions
Having said so many ideas, can it solve our distributed transaction problems?
Actually it is possible. So what's wrong with our distributed transactions?
Distributed transactions often contain n sub-transactions, and each transaction is executed and submitted separately. As a result, some succeeded and some failed. At this time, everyone's state was inconsistent.
What we hope is that each sub-transaction in this distributed transaction must have the same final status, either all succeed or all fail.
So how do we solve this distributed transaction based on base theory?
The first solution is actually the AP-based model.
AP mode: Each sub-transaction is executed and submitted separately, allowing inconsistent results, and then taking remedial measures to restore the data to achieve final consistency.
That is to meet availability and sacrifice a certain degree of consistency. For example, if each of our sub-transactions is executed and submitted separately when we execute it in the future, some will succeed and some will fail. So what is this called?
This is called status inconsistency.
In other words, what are you in?
Soft state.
Temporary inconsistent state, okay, why? After the execution is completed, each of our sub-transactions can take a breather.
Take a look at each other, did you succeed? Oh, I made it. Um, did you make it? Hey, what should I do if someone fails in such a comparison?
Don't be anxious at this time. We will take compensatory measures to restore the data. Some say that it has been submitted and cannot be restored. Then we can do the reverse operation. For example, you have added a new pair before. wrong?
Then if I delete it next, won’t that be the end of it?
Doesn't this restore the data to its original state? Doesn't this achieve eventual consistency?
So this model is actually an idea of AP.
What about the other way around, can I reach strong consensus? Hey, that’s also possible.
CP mode: Each sub-transaction waits for each other after execution, commits at the same time, and rolls back at the same time to reach a strong consensus. However, while the transaction is waiting, it is in a weakly available state.
Previously, each sub-transaction was executed and submitted separately. If you finish executing them all at the beginning, you can't roll back, right?
But now, after each of my sub-transactions has been executed, don’t submit it, just wait for each other. Let’s take a look at each other. Hey, I’ve finished executing it. Have you finished executing it? In this way, there is no problem until we have executed all of them.
Then if we submit at the same time or someone fails in the middle, then we roll back at the same time. Will this be able to achieve strong consensus? There is no intermediate state, right?
It's just that in this process, do your sub-transactions have to wait for each other? Waiting for each other's execution, so during this process, your service is actually in a weakly available state.
Because you will lock the resource and make it inaccessible.
Do you think we have implemented an idea to solve distributed transactions based on the theory of base?
Later we will solve distributed transactions based on this idea, but whether you are CP or AP, there is one thing in common here, that is, each sub-transaction will have to communicate with each other in the future to identify the execution status of the other party.
So how to communicate between various sub-transactions?
Therefore, it needs a coordinator to help each sub-transaction in the distributed transaction communicate and perceive. The status of the other party or each other, let’s give an example, let’s take our previous order as an example.
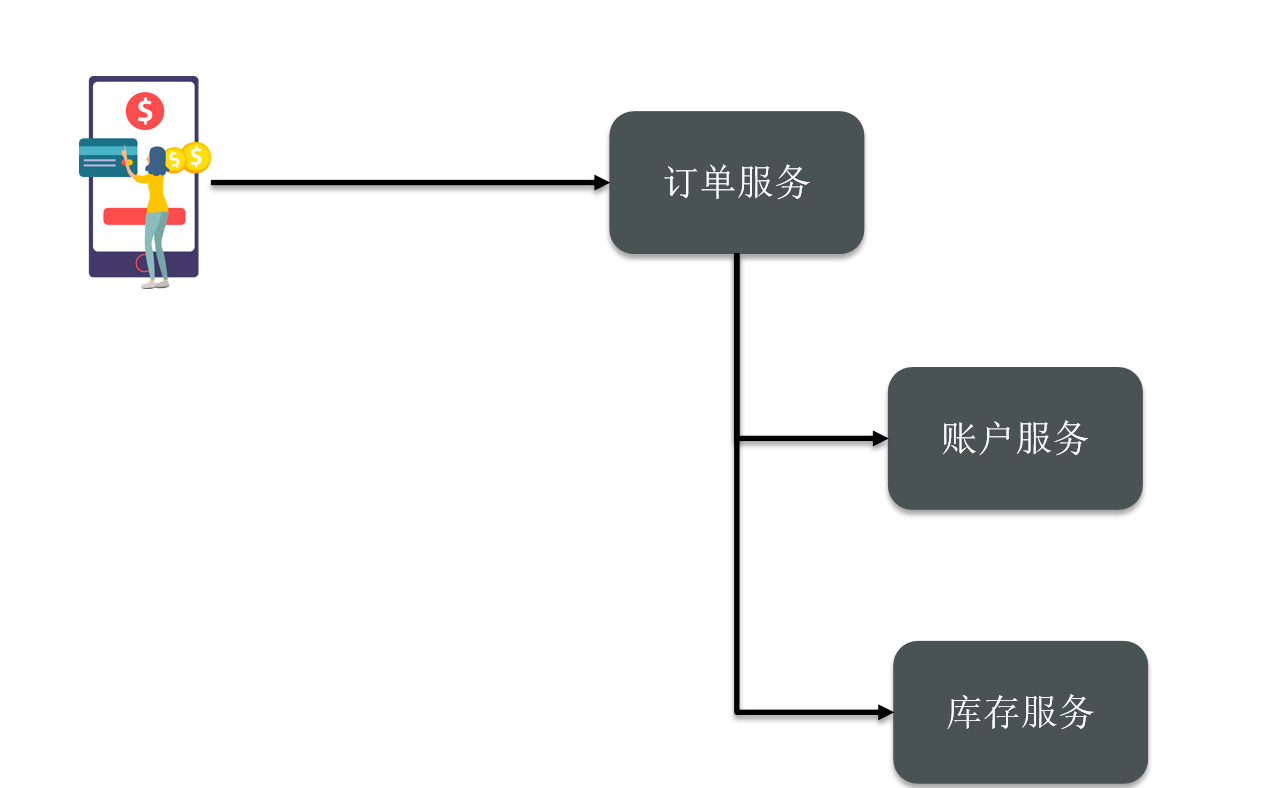
The user places an order and calls the order service, and then calls the accounting service and inventory service. What about this place? We need a transaction coordinator, and then each microservice maintains a connection with the transaction coordinator.
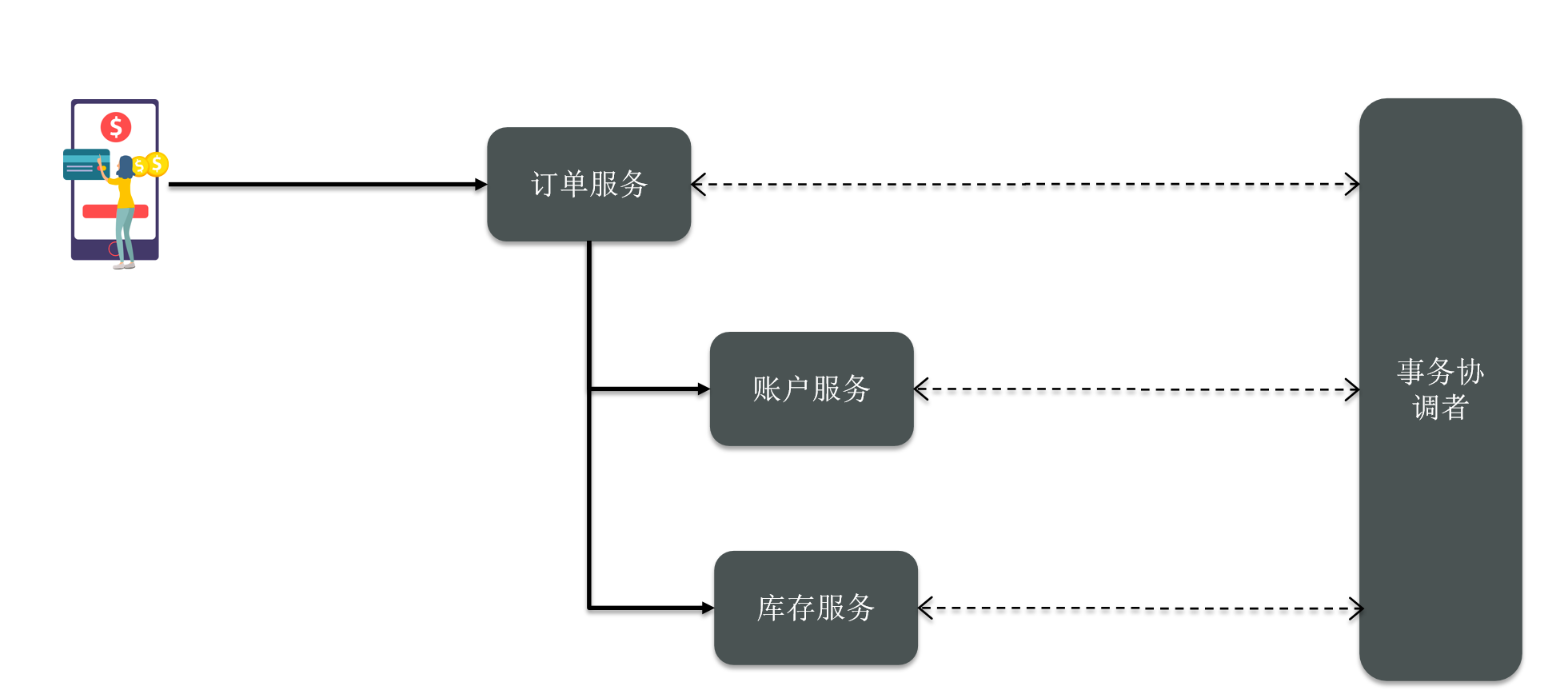
After the business comes, everyone executes it independently. If you want to be strong consistent now, then don't submit it when the third service is executed. Execute the order deduction service, perform the deduction inventory service, and execute the inventory.
But after the execution, it turned out that the inventory failed.
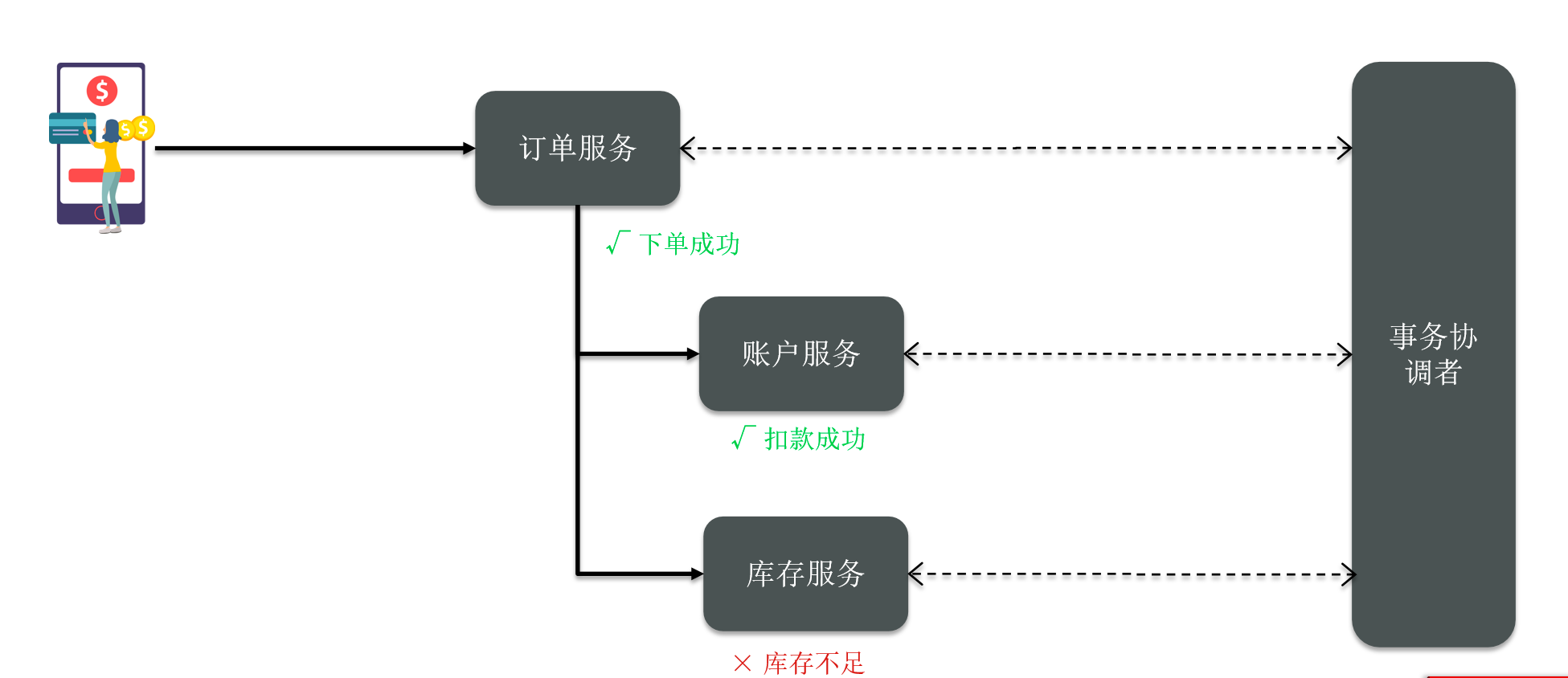
How do you know? Do they want to inform the coordinator of their execution results? Then the coordinator sees that someone has failed and then notifies them to do this rollback in the future.
So can everyone be consistent? Therefore, the coordinator of this transaction plays a very key role. During the entire process, we participate in the transactions of each subsystem in the distributed transaction, which we call branch transactions.
The entire branch transaction is called a global transaction, so the transaction coordinator is actually here to coordinate the status of each branch transaction so that they can reach an agreement.