Thesis title: DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection (front fusion)
Unit: google
Note: 4D-Net and 3D-CVF also studied the alignment problem of the two modal features of lidar and camera
1. Summary + Intro
pre-fusion methods include pointpainting (decorating point clouds with camera features) and EPNet (fusion of mid-level features after feature extraction). However, the fusion of deep lidar features and camera features by these two types of methods brings a problem. Since these features are usually enhanced and aggregated, they cannot effectively align the features from the two modalities (alignment is to find lidar and camera features). corresponding relationship). The author believes that fusion through the Pointpainting method will cause "voxelization is not applicable to camera features; domain gap; additional computational cost; additional label problems; features are selected heuristically (methods discovered based on experience) rather than through end-to-end learning. The reason for the problem is that the feature extractor of the camera is learned separately from other tasks, such as the deeplab segmentation used here. In order to achieve effective mid-level feature fusion to solve the mentioned problems, the author proposed a model called Deepfusion, which is mainly based on InverseAug (in order to solve the image and LIDAR feature alignment problem caused by geometric related data enhancement) and LearnableAlign (in order to dynamically capture images and Correlation between LIDAR features) these two methods.
2. Difficulties in feature alignment.
The author proposed that aligning features is challenging. First of all, the first challenge is that general methods will perform data enhancement on the data of the two modalities before fusion. For example, the RandomRotation data enhancement method that rotates the 3D world coordinate system along the z-axis is usually used for lidar points, but it is not suitable for camera images. After completing this data enhancement for lidar points, it will make the characteristics of the two modalities more difficult. Alignment. The second challenge is that one voxel contains many lidar points, resulting in one voxel corresponding to multiple camera features. However, some of these many camera features are not very important, so important camera features have to be selected.
3.method
3.1 Deep feature fusion pipeline
In order to solve the problem of "voxelization is not applicable to camera features" in Pointpainting, the author fused the depth features of the camera and lidar instead of decorating the raw lidar points at the input layer step, so that The camera signal will not go through a module (voxelization) specially designed for point clouds. In order to solve the problems of "domain gap; extra computational cost; extra label problem; features are selected heuristically (methods discovered based on experience) rather than obtained through end-to-end learning" in Pointpainting, the author uses convolutional layers to extract camera features, and then train these convolutional layers together with other components of the network in an end-to-end fashion. This pipeline solves the problems mentioned before, but the author feels that his method still has certain shortcomings: compared with the input-level decoration method, aligning the camera and lidar signals at the deep feature level becomes less straightforward. Therefore, an improvement plan for subsequent alignment was proposed.
3.2 The impact of alignment quality on results
The author uses geometry-related data enhancement (RandomRotation is used here) to adjust the ease of alignment, because stronger geometry-related data enhancement will lead to worse alignment. It is experimentally found that alignment is crucial for deep feature fusion, and if the alignment is not accurate, the benefits obtained from the camera input will become minimal.
3.3 Enhancing the Quality of Alignment
The authors propose two techniques, InverseAug and LearnableAlign, to efficiently align the deep features of two modalities.
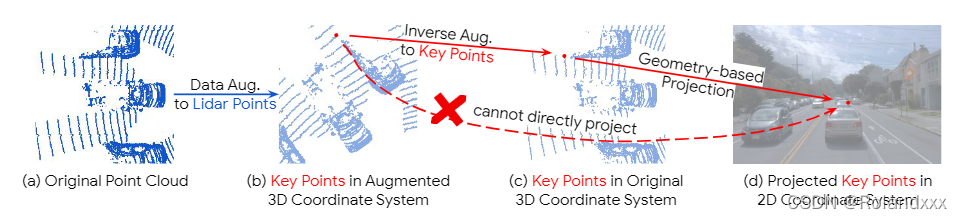
1) InverseAug
data enhancement is a must in multimodal fusion, because previous studies have found that it can improve the effect of the model. But because the original lidar and camera parameters cannot be used to locate the camera features corresponding to the data-enhanced lidar in 2D space. In order to make localization possible, when applying geometry-related data augmentation, InverseAug first saves the augmentation parameters (for example, the rotation degree of the RandomRotate data augmentation method). Then in the fusion stage, all these data augmentations are inverted to obtain the most original 3D key point (note that only key points, such as voxel center points, are inverted) coordinates. Then find the 2d camera coordinates corresponding to the 3d point coordinates.
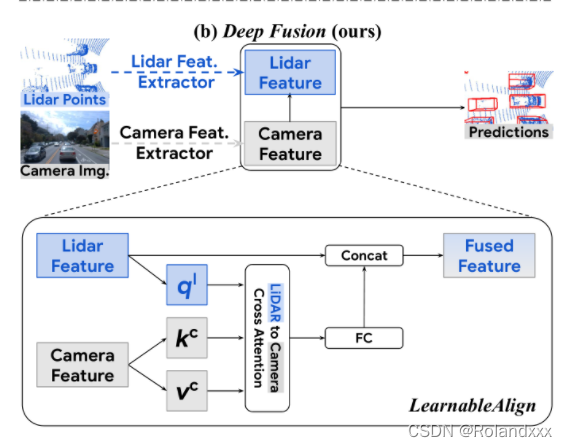
2)LearnableAlign
For the input-level decoration method of PointPainting, given a 3D lidar point, it will only correspond to the only camera pixel. But because the pipeline proposed by the author is the depth feature of the fusion of two modalities, each lidar feature represents a voxel containing a subset of points, so its corresponding camera pixel is polygonal (that is, it will correspond to many pixels. ). So there is the problem of one-voxel-to-many-pixels. There is a naive idea to average all the camera pixels corresponding to a given voxel, so that a one-voxel-to-one-pixel result will be obtained, but there is a problem that these pixels are not equally important , obviously averaging is not a good solution. So the author finally uses the cross-attention mechanism to dynamically capture the correlation between the two modalities, better aligning the information from the lidar features with the most relevant camera features (finally also becomes one-voxel-to-one- pixel). LearnableAlign uses three fully connected layers to transform voxels into query Q1 and camera features into keys Kc and values Vc, respectively. Finally, the values of the camera aggregated by cross attention are processed by the fully connected layer, and finally concat with the original lidar features. Finally feed the output into any standard 3D detection framework like PointPillars or CenterPoint for model training.
4.ResultEns
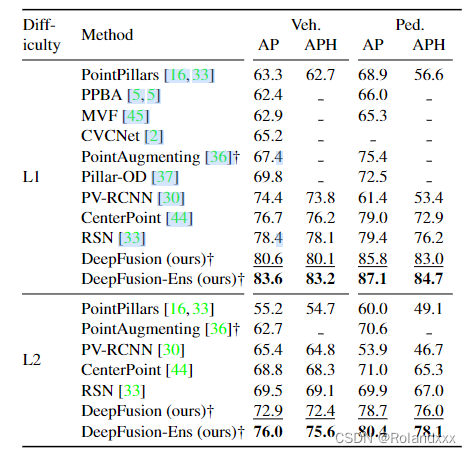
:model ensemble