Deep Hough Voting for 3D Object Detection in Point
Clouds
PS:
pointnet: Due to the global features obtained by its maxpooling operation, the classification task works well;
For the segmentation task, the global features are concatenated with the local features of each point cloud learned before, and then the classification result of each point is obtained through mlp.
Pointnet++: It is a supplementary and upgraded version of the previous pointnet. The local feature extraction ability of pointnet is poor, which makes it difficult to analyze complex scenes.
pointnet++ draws on the idea of CNN's multi-layer receptive field, first samples and divides the point cloud, and uses the pointnet network to extract features in each small area, and iterates continuously.
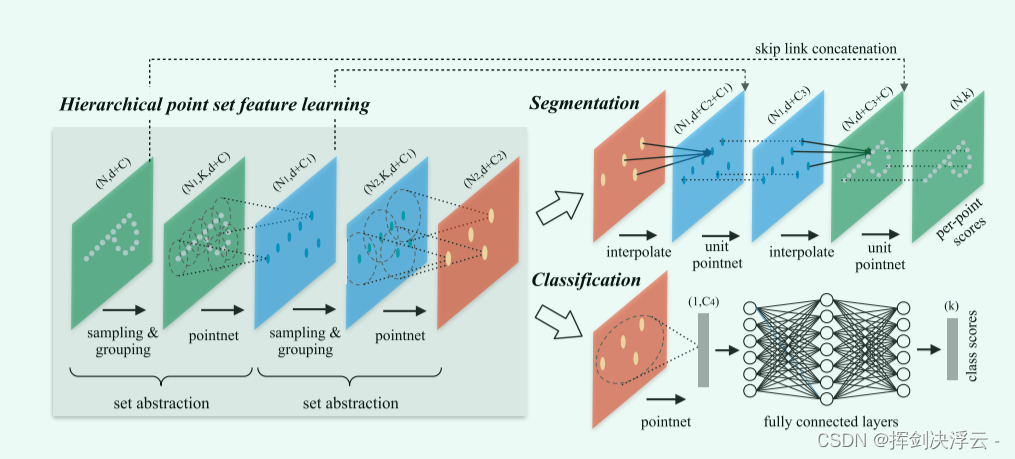
The network structure is as follows:
1. Sample layer : It mainly samples the input points, selects several center points from these points, and uses the FPS to sample the farthest points to ensure that the sampling points are evenly distributed on the entire point cloud.
2. Grouping layer : Use the center point obtained from the previous layer to divide the point set into several regions.
3. PointNet layer : Use MLP to extract features from these points and aggregate them into sampling point coordinates through maximum pooling.
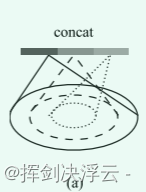
In the set abstraction, multi-scale feature extraction is used for optimization, and some small features are spliced together with large ones (different radii) to improve the generalization ability.
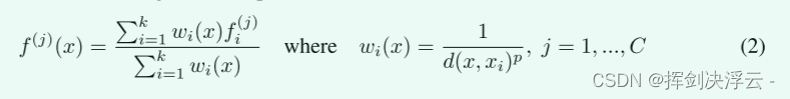
For the optimization of the segmentation task, what we have to do is to make a semantic segmentation label for each point. In the network, we first do an upsampling. How do we do it? This is achieved by doing an interpolation, using a distance-based interpolation and a hierarchical propagation strategy of skip links. Among the many interpolation options, we use an inverse distance-weighted average based on k nearest neighbors (such as formula 2, default case we use p = 2, k = 3). It will make a weighted average based on the distance of K points in the neighborhood and the characteristics of the points. After interpolation, it will restore the global features. We also need to splice these features with the previous local features, and then continue to do something later. Feature propagation, repeating this process until we propagate the features to the original point set, and then do the semantic segmentation task, the effect will be better.
VoteNet:
What do you want to do:
Construct a 3D detection structure as general as possible for point cloud data
Bringing up the background:
The goal of 3D object detection is to localize and recognize objects in 3D scenes, more specifically, in this work we aim to estimate oriented 3D bounding boxes as well as semantic categories of objects from point clouds.
However, the current 3D object detection methods are greatly influenced by 2D detectors, and some 2D detection frameworks are extended to 3D, such as extending 2D detection frameworks such as Faster or Mask R-CNN to 3D, and irregular point cloud voxels into a regular 3D grid and apply a 3D CNN detector, which cannot exploit the sparsity in the data and suffers from high computational cost due to expensive 3D convolutions.
Or project point cloud data into a regular 2D bird's-eye view image, and then apply 2D detectors to localize objects. However, this sacrifices geometric details that may be crucial in cluttered indoor environments, and image visual transformation requires additional computational overhead.
This paper introduces a point cloud-centric 3D detection framework that directly processes raw data and does not rely on any 2D detectors in both architecture and object proposals. Our detection network, VoteNet, is based on recent advances in point cloud 3D deep learning models and inspired by the generalized Hough voting process for object detection
Problems encountered:
However, due to the sparsity of the data, there is a major challenge in predicting bounding box parameters directly from scene points: the centroid of a 3D object may be far away from any surface points, making it difficult to regress accurately with one step.
solution:
Using Hough voting, first sample several seed points on the input point cloud and vote the center point of the target to which it belongs, so that many vote points close to the center of the target can be obtained, and then the bounding box suggestion is proposed on the vote point, which is very good Fixed a bug where the target center point was inaccurate when it was far from the surface point
Network architecture diagram:
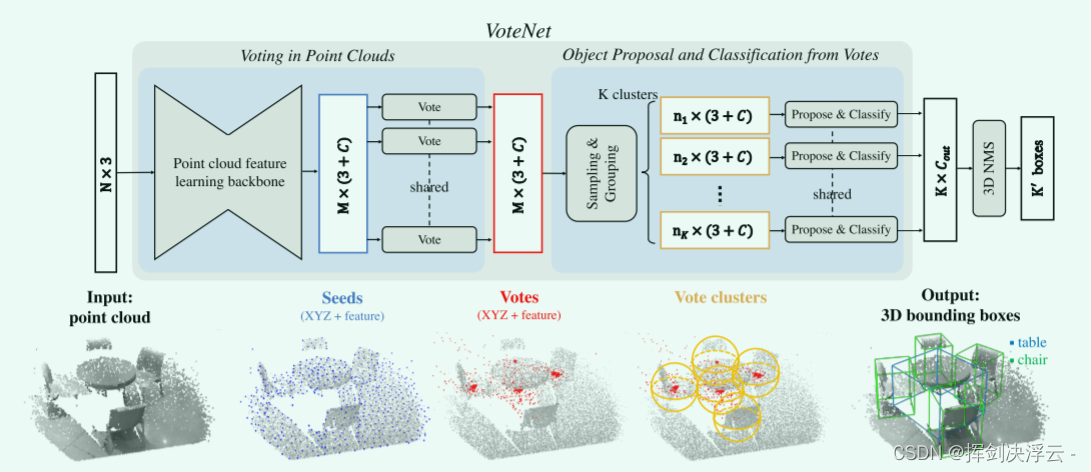
First of all, use pointnet++ to extract an information of the point cloud in the original scene. If we want to find out the bonding box of the target object, we need to determine the center point of an object. Since our point cloud is a representation of the surface information of the object, the center must be additionally determined. Yes, we use the Hough voting mechanism to pick out these candidate points, and get some central point proposals (originally called proposals) that did not exist in the point cloud data. After having these points, we continue to use sampling and grouping in pointnet++ Go to the farthest point to sample K cluster centers, divide the spherical space, use mlp to extract the feature vectors representing them from these clusters, and then predict a category label for these vectors, including where the bonding box should be.
To be perfected. . . . . .