LORA, which is similar to nuclear weapons in large-model fineturn technology, is simple and efficient. Its theoretical basis is: when migrating a general large model to a specific professional field, only the low-rank subspace of its high-dimensional parameters needs to be updated. Based on this simple logic, LORA lowers the fineturn threshold of large models. There is no need to save the gradient of the original parameters during model training, and only needs to optimize the low-rank subspace parameters. And its low-rank subspace can be superimposed into the original parameters after training is completed, thereby realizing the transfer of model capabilities to professional fields. In order to understand this high-dimensional parameter space => low-rank subspace projection implementation, study its project source code.
Project address: https://github.com/microsoft/LoRA LORA提出至今已经2年了,但现在任然在更新项目代码
Paper address: https://arxiv.org/pdf/2106.09685.pdf
Brief reading address: https://blog.csdn.net/a486259/article/details/ 132767182?spm=1001.2014.3001.5501
1. Basic introduction
1.1 Implementation results
The LORA technique achieves results comparable to or better than fully fine-tuned on the GLUE benchmark using RoBERTa (Liu et al., 2019) base and large and DeBERTa (He et al., 2020) XXL 1.5B, while only training and A small set of parameters are stored. LORA技术展现了与全参数迁移学习相同甚至更优的效果
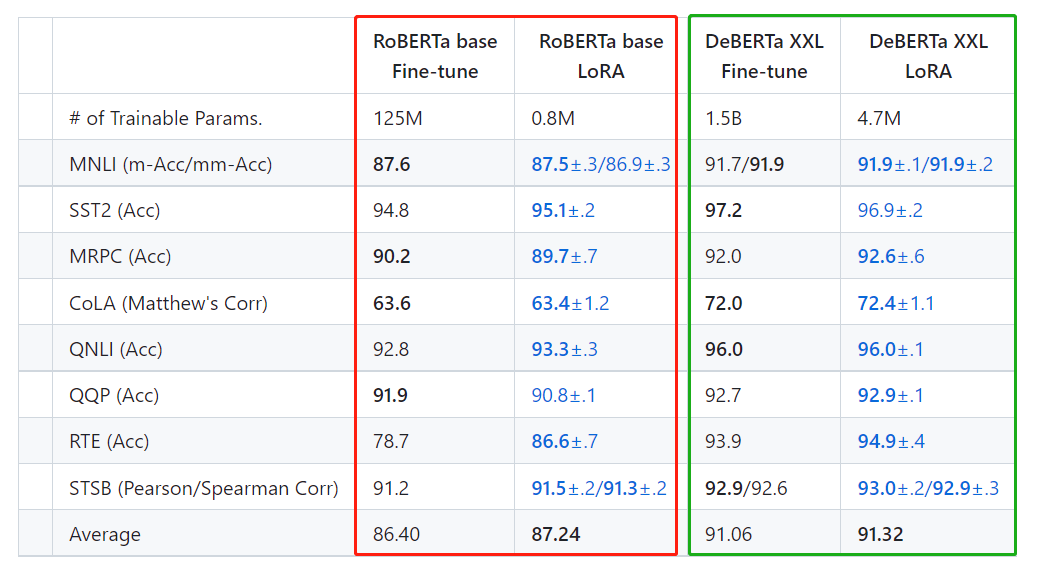
On GPT-2, LoRA compares favorably with both full fine-tuning and other large model fine-tuning methods such as Adapter (Houlsby et al., 2019) and Prefix (Li and Liang, 2021).
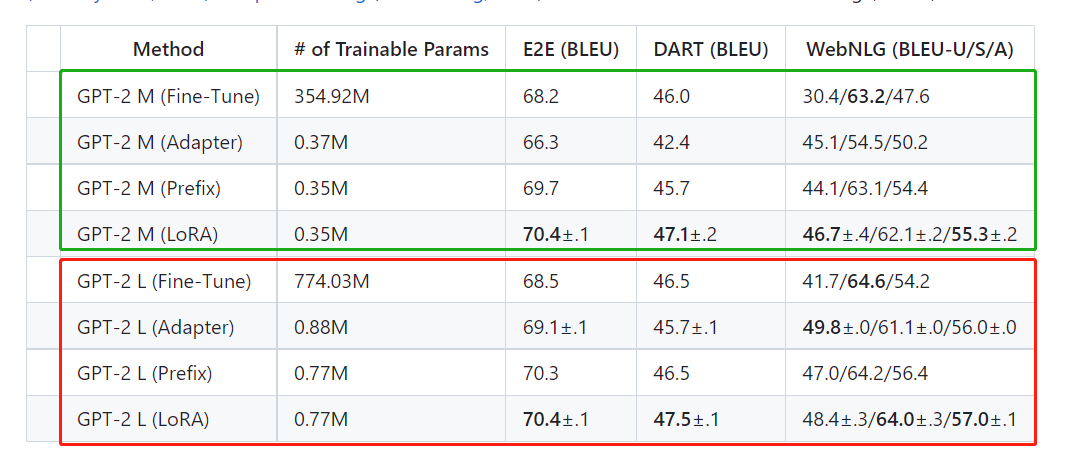
The above two figures not only show the fine-tuning effect of LORA on large models, but also reveal the difficulty in improving the performance of large models.
The number of parameters of DeBERTa XXL is more than a hundred times that of RoBERTa base, but the average accuracy is only 4.6% higher. The number of parameters of GPT2 L is more than twice that of GPT M, but the average accuracy is only about 0.5% higher . This difference between parameter growth and accuracy growth is rare in the image field, especially in target detection | semantic segmentation | image classification.
1.2 Installation and use
This is limited to the use cases given on the official website.LORA的实际使用应该是基于其他框架展开的
Installation command
pip install loralib
# Alternatively
# pip install git+https://github.com/microsoft/LoRA
Construct a low-rank training layer
LORA currently supports other layers in addition to the Linear layer. The layer created based on lora is a subclass of lora and a subclass of torch.nn.module.
# ===== Before =====
# layer = nn.Linear(in_features, out_features)
# ===== After ======
import loralib as lora
# Add a pair of low-rank adaptation matrices with rank r=16
layer = lora.Linear(in_features, out_features, r=16)
Set only the LORA layer to be trainable
It is required that some layers in the model object are subclasses of lora. The mark_only_lora_as_trainable function will set all parts of the parameter name that do not contain lora_ to untrainable.
import loralib as lora
model = BigModel()
# This sets requires_grad to False for all parameters without the string "lora_" in their names
lora.mark_only_lora_as_trainable(model)
# Training loop
for batch in dataloader:
...
Save model parameters
For models containing the LORA layer, parameter saving is completed in two steps. The first step is to save the parameters of the original model (usually can be ignored), and the second step is to save the parameters of the lora layer. The corresponding code is:torch.save(lora.lora_state_dict(model), checkpoint_path)
# ===== Before =====
torch.save(model.state_dict(), checkpoint_path)
# ===== After =====
torch.save(lora.lora_state_dict(model), checkpoint_path)
Load model parameters
The loading of model parameters including the lora layer is also completed in two steps. The first step is to load the original parameters, and the second step is to load the lora layer parameters.
# Load the pretrained checkpoint first
model.load_state_dict(torch.load('ckpt_pretrained.pt'), strict=False)
# Then load the LoRA checkpoint
model.load_state_dict(torch.load('ckpt_lora.pt'), strict=False)
Additional instructions
Some Transformer implementations use a single nn.Linear. The projection matrix of query, key and value is nn.Linear. lora.MergedLinearIf you wish to constrain the updated rank to a single matrix, you must break it into three separate matrices or use If you choose to decompose the layer, make sure to modify the checkpoint accordingly.
# ===== Before =====
# qkv_proj = nn.Linear(d_model, 3*d_model)
# ===== After =====
# Break it up (remember to modify the pretrained checkpoint accordingly)
q_proj = lora.Linear(d_model, d_model, r=8)
k_proj = nn.Linear(d_model, d_model)
v_proj = lora.Linear(d_model, d_model, r=8)
# Alternatively, use lora.MergedLinear (recommended)
qkv_proj = lora.MergedLinear(d_model, 3*d_model, r=8, enable_lora=[True, False, True])
2. Code interpretation
The source code of the lora project is as follows. Its core code has only two files, layers.py and utils.py.
Examples are two use cases, which are third-party codes and will not be discussed in depth here.
2.1 Layer.py
In the lora source code, there are four layer objects: Embedding, Linear, MergedLinear, and ConvLoRA, all of which are subclasses of nn.Module and LoRALayer.
Template layer analysis
There are many layer objects in the lora source code. Here, only Linear and ConvLoRA are described in detail.
Linear
In lora, the low-rank decomposition of Linear is realized by the multiplication of matrices A and B. In forward, lora branch BAlora_dropout operation, and the output result of BA is scaled. When layer.train(True) is called, the BA parameters in the weight will be accumulated and removed according to the self.merged parameter. When layer.train(False) is called, the BA parameters will be accumulated into the weight.
这里需要注意,LoRA.Linear是nn.Linear的子类,在使用时直接参考nn.Linear的用法即可。
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
ConvLoRA
LORA can perform low-rank decomposition of conv, which is unexpected by the blogger. This operation completely applies the idea of LoRALinear to the conv kernel. There are two trainable parameters, self.lora_B and self.lora_A, to express the kernel parameters of conv. The results of self.lora_B @ self.lora_A are directly applied to conv.weight. , and then call self.conv._conv_forward to complete the convolution operation.
这里需要注意的是,使用ConvLoRA跟使用torch.nn.Conv是没有任何区别。这里只有一个问题,我们不能直接将conv对象转换为ConvLoRA对象。需要在构建网络时就使用ConvLoRA layer
class Conv2d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
class Conv1d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv1d, self).__init__(nn.Conv1d, *args, **kwargs)
class Conv3d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv3d, self).__init__(nn.Conv3d, *args, **kwargs)
class ConvLoRA(nn.Module, LoRALayer):
def __init__(self, conv_module, in_channels, out_channels, kernel_size, r=0, lora_alpha=1, lora_dropout=0., merge_weights=True, **kwargs):
super(ConvLoRA, self).__init__()
self.conv = conv_module(in_channels, out_channels, kernel_size, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
assert isinstance(kernel_size, int)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(
self.conv.weight.new_zeros((r * kernel_size, in_channels * kernel_size))
)
self.lora_B = nn.Parameter(
self.conv.weight.new_zeros((out_channels//self.conv.groups*kernel_size, r*kernel_size))
)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.conv.weight.requires_grad = False
self.reset_parameters()
self.merged = False
def reset_parameters(self):
self.conv.reset_parameters()
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode=True):
super(ConvLoRA, self).train(mode)
if mode:
if self.merge_weights and self.merged:
if self.r > 0:
# Make sure that the weights are not merged
self.conv.weight.data -= (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
if self.r > 0:
# Merge the weights and mark it
self.conv.weight.data += (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = True
def forward(self, x):
if self.r > 0 and not self.merged:
return self.conv._conv_forward(
x,
self.conv.weight + (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling,
self.conv.bias
)
return self.conv(x)
Complete code
# ------------------------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
# ------------------------------------------------------------------------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Optional, List
class LoRALayer():
def __init__(
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
class Embedding(nn.Embedding, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
r: int = 0,
lora_alpha: int = 1,
merge_weights: bool = True,
**kwargs
):
nn.Embedding.__init__(self, num_embeddings, embedding_dim, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=0,
merge_weights=merge_weights)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
def reset_parameters(self):
nn.Embedding.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.zeros_(self.lora_A)
nn.init.normal_(self.lora_B)
def train(self, mode: bool = True):
nn.Embedding.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
if self.r > 0 and not self.merged:
result = nn.Embedding.forward(self, x)
after_A = F.embedding(
x, self.lora_A.transpose(0, 1), self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq, self.sparse
)
result += (after_A @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return nn.Embedding.forward(self, x)
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
class MergedLinear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
enable_lora: List[bool] = [False],
fan_in_fan_out: bool = False,
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
assert out_features % len(enable_lora) == 0, \
'The length of enable_lora must divide out_features'
self.enable_lora = enable_lora
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0 and any(enable_lora):
self.lora_A = nn.Parameter(
self.weight.new_zeros((r * sum(enable_lora), in_features)))
self.lora_B = nn.Parameter(
self.weight.new_zeros((out_features // len(enable_lora) * sum(enable_lora), r))
) # weights for Conv1D with groups=sum(enable_lora)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
# Compute the indices
self.lora_ind = self.weight.new_zeros(
(out_features, ), dtype=torch.bool
).view(len(enable_lora), -1)
self.lora_ind[enable_lora, :] = True
self.lora_ind = self.lora_ind.view(-1)
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def zero_pad(self, x):
result = x.new_zeros((len(self.lora_ind), *x.shape[1:]))
result[self.lora_ind] = x
return result
def merge_AB(self):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
delta_w = F.conv1d(
self.lora_A.unsqueeze(0),
self.lora_B.unsqueeze(-1),
groups=sum(self.enable_lora)
).squeeze(0)
return T(self.zero_pad(delta_w))
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0 and any(self.enable_lora):
self.weight.data -= self.merge_AB() * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0 and any(self.enable_lora):
self.weight.data += self.merge_AB() * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.merged:
return F.linear(x, T(self.weight), bias=self.bias)
else:
result = F.linear(x, T(self.weight), bias=self.bias)
if self.r > 0:
result += self.lora_dropout(x) @ T(self.merge_AB().T) * self.scaling
return result
class ConvLoRA(nn.Module, LoRALayer):
def __init__(self, conv_module, in_channels, out_channels, kernel_size, r=0, lora_alpha=1, lora_dropout=0., merge_weights=True, **kwargs):
super(ConvLoRA, self).__init__()
self.conv = conv_module(in_channels, out_channels, kernel_size, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
assert isinstance(kernel_size, int)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(
self.conv.weight.new_zeros((r * kernel_size, in_channels * kernel_size))
)
self.lora_B = nn.Parameter(
self.conv.weight.new_zeros((out_channels//self.conv.groups*kernel_size, r*kernel_size))
)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.conv.weight.requires_grad = False
self.reset_parameters()
self.merged = False
def reset_parameters(self):
self.conv.reset_parameters()
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode=True):
super(ConvLoRA, self).train(mode)
if mode:
if self.merge_weights and self.merged:
if self.r > 0:
# Make sure that the weights are not merged
self.conv.weight.data -= (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
if self.r > 0:
# Merge the weights and mark it
self.conv.weight.data += (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = True
def forward(self, x):
if self.r > 0 and not self.merged:
return self.conv._conv_forward(
x,
self.conv.weight + (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling,
self.conv.bias
)
return self.conv(x)
class Conv2d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
class Conv1d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv1d, self).__init__(nn.Conv1d, *args, **kwargs)
# Can Extend to other ones like this
class Conv3d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv3d, self).__init__(nn.Conv3d, *args, **kwargs)
2.2 utils.py
There are two functions mark_only_lora_as_trainable and lora_state_dict in the period. The mark_only_lora_as_trainable function is used to freeze the non-lora layer parameters of the model. This function distinguishes lora layers based on name 层name中包含lora_. Its parameter bias setting is used to determine whether the bias in the model is trainable, bias == 'none'表示忽略bias, bias == 'all'表示所有偏置都可以训练,bias == 'lora_only'表示仅有lora layer的bias可以训练
The lora_state_dict function is used to load the parameters saved by lora, 参数bias == 'none'表明只加载lora参数, 参数bias == 'all'表明加载lora参数和所有bias参数,
import torch
import torch.nn as nn
from typing import Dict
from .layers import LoRALayer
def mark_only_lora_as_trainable(model: nn.Module, bias: str = 'none') -> None:
for n, p in model.named_parameters():
if 'lora_' not in n:
p.requires_grad = False
if bias == 'none':
return
elif bias == 'all':
for n, p in model.named_parameters():
if 'bias' in n:
p.requires_grad = True
elif bias == 'lora_only':
for m in model.modules():
if isinstance(m, LoRALayer) and \
hasattr(m, 'bias') and \
m.bias is not None:
m.bias.requires_grad = True
else:
raise NotImplementedError
def lora_state_dict(model: nn.Module, bias: str = 'none') -> Dict[str, torch.Tensor]:
my_state_dict = model.state_dict()
if bias == 'none':
return {
k: my_state_dict[k] for k in my_state_dict if 'lora_' in k}
elif bias == 'all':
return {
k: my_state_dict[k] for k in my_state_dict if 'lora_' in k or 'bias' in k}
elif bias == 'lora_only':
to_return = {
}
for k in my_state_dict:
if 'lora_' in k:
to_return[k] = my_state_dict[k]
bias_name = k.split('lora_')[0]+'bias'
if bias_name in my_state_dict:
to_return[bias_name] = my_state_dict[bias_name]
return to_return
else:
raise NotImplementedError