Common data sets and research status of Videos Understanding
- Dataset
-
-
- 1. KTH (2004)
- 2. Weizmann (2005)
- 3. Hollywood V1/V2 (2008、2009)
- 4. HMDB51 (2011)
- 5. UCF101(2007-2012)
- 6. THUMOS(2014)
- 7. Sports-1M(2014)
- 8. ActivityNet(2015)
- 9. Youtube-8M(2016)
- 10. Charades(2016)
- 12. Kinetics(2017)
- 13. AVA(2017)
- 14. Moments(2018)
- 15. Something Something v1/v2(2019)
- 16. HowTo100M(2019)
- 17. HiEve(2021)
- 18. Diving-48(2018)
- 19. FineAction(2021)
- 20.MultiSports(2021)
-
- TASK
Dataset
1. KTH (2004)
Link : http://pan.baidu.com/s/1hsuQktA Password:rfr7
Size:1GB
Class : Class 9
Brief Description : The KTH data set was released in 2004, which is a milestone in the field of computer vision. Since then, many new databases have been released. The database includes a total of 2391 video samples of 6 categories of actions (walking, jogging, running, boxing, hand waving and hand clapping) performed by 25 people in 4 different scenes. It was the largest human action database captured at that time, which makes it possible to use the same The input data makes it possible to systematically evaluate the performance of different algorithms. The video samples in the database include scale changes, clothing changes and lighting changes, but the background is relatively simple and the camera is fixed. (static)
SOTA:
2. Weizmann (2005)
Link:https://www.wisdom.weizmann.ac.il/~vision/SpaceTimeActions.html
Size:340MB
Class : Class 9
Brief Description : In 2005, the Weizmann institute in Israel released the Weizmann database. The database contains 10 actions (bend, jack, jump, pjump, run, side, skip, walk, wave1, wave2), each action has 9 different samples. The perspective of the video is fixed, the background is relatively simple, and there is only one person doing actions in each frame. In addition to category labels, the calibration data in the database also include: actor silhouettes in the foreground and background sequences used for background extraction. (static)
SOTA:
3. Hollywood V1/V2 (2008、2009)
Link:http://www.di.ens.fr/~laptev/actions/hollywood2/
Size : 15G for action recognition, 25G for scene recognition
Class : Class 12
Brief Description : Hollywood (released in 2008) and Hollywood-2 databases are released by the French IRISA Research Institute. The databases released earlier were basically shot in controlled environments, with limited video samples. Hollywood-2, released in 2009, is an expanded version of the Hollywood database, containing a total of 3,669 samples in 12 action categories and 10 scenes. All samples were extracted from 69 Hollywood movies. The expressions, postures, clothing, camera movements, lighting changes, occlusions, backgrounds, etc. of the actors in the video samples vary greatly and are close to the situation in real scenes. Therefore, the analysis and identification of behaviors is extremely challenging. For older datasets, the data is easier to obtain. There are fewer samples and categories, and the research interest is low. There will be a similar Hollywood Extended data set in the future. Friends who are interested in movies can pay attention to it.
SOTA:
4. HMDB51 (2011)
Link:http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/#dataset
Size:2G
Class : Class 51
Brief Description : HMDB51 released by Brown University was released in 2011. Most of the videos come from movies, and some come from public databases and online video libraries such as YouTube. The database contains 6849 samples, which are divided into 51 categories, and each category contains at least 101 samples. Similar to UCF101, it is entry-level data. The data is easy to obtain and the amount is small, and it is easy to reproduce or verify the effect. The current research enthusiasm is high.
SOTA:
5. UCF101(2007-2012)
Link:http://crcv.ucf.edu/data/
Size:6.46G
Class : Class 101
Brief Description : A series of databases released by the University of central Florida (UCF) in the United States since 2007: UCF sports action dataset (2008), UCF Youtube (2008), UCF50, UCF101 (2012), have attracted widespread attention. These database samples come from various sports samples collected from BBC/ESPN radio and television channels, as well as samples downloaded from the Internet, especially the video website YouTube. Among them, UCF101 is one of the databases with the largest number of action categories and samples. The samples are 13320 videos and the number of categories is 101. Entry-level data. The data is easy to obtain, and the research enthusiasm is high, but the accuracy is already very high, and it is difficult to improve.
SOTA:
6. THUMOS(2014)
Link:https://www.crcv.ucf.edu/THUMOS14/download.html
Size:unknow
Class : Class 101
Brief Description : Behavior recognition task: Its training set is the UCF101 data set, including 101 types of actions, with a total of 13320 segmented video clips; its verification set and test set include 1010 and 1574 unsegmented videos respectively. Temporal behavior detection task: Only unsegmented videos of 20 types of actions are annotated with sequential behavioral clips, including 200 verification set videos (containing 3007 behavior clips) and 213 test set videos (containing 3358 behavior clips); these are Annotated unsegmented videos can be used to train and test temporal behavior detection models.
SOTA:
7. Sports-1M(2014)
Link:https://cs.stanford.edu/people/karpathy/deepvideo/
Size:unknow
Class : Class 487
Brief Description : Sports-1M comes from the sports video data set collected by YouTube. It was produced in 2014 and contains a total of 1,133,158 samples. The categories are all sports-related. The video ID of YouTube is provided on Github for downloading. Friends who like sports or are engaged in sports-related projects can find out. Unfortunately, the video ID provided is YouTube’s video ID, which is more difficult for domestic friends to obtain.
SOTA:
8. ActivityNet(2015)
Link:http://activity-net.org/index.html
Size:unknow
Class : 200 class
Brief Description : ActivityNet is a large-scale behavior recognition competition. Started from CVPR 2016, it focuses on identifying daily life, goal-oriented activities from user-generated videos. The videos are taken from the Internet video portal Youtube, and categories include eating, doing Food, sports, etc. Note: Because ActivityNet is a competition, challenges have been updated on CVPR in recent years (such as Kinetics-400 in recent years). What we introduce here is the 2016 challenge. The official version will be updated every year. It appeared earlier and was gradually replaced by subsequent versions; the official website provides a Youtube URL to obtain data, which is not easy to download (domestic friends cannot afford it); and the sample size is too small, and the research enthusiasm is average.
SOTA:
9. Youtube-8M(2016)
Link:https://research.google.com/youtube8m/download.html
Size : about 1.5T
Class : 4800 class
Brief Description : Youtube-8M began to appear in 2016, with 8 million samples at the beginning. It has been updated year by year, with fewer and fewer samples (possibly due to link failure). The training samples of the 2018 version are around 5.6 million. 2019 also provides tagging of video clips. The official download file format is tfrecord. This data set is too large, the cost of conducting experiments is too great, and there has been little progress in the academic community recently. There have been competitions held on Kaggle, and Tencent also won the ranking (the second plan above). Although the download format of tfrecord is provided, the download process is still not friendly to domestic friends. Interested friends can try it.
SOTA:
10. Charades(2016)
Link: https://allenai.org/plato/charades/
Size : Various sizes ranging from 13G-76G
Class : Class 157
Brief Description : Charades is data collected through Amazon Mechanical Turk in 2016. The total data set is 9848 video clips, mainly indoor actions. This data set contains both video-level classification and frame-level classification. It has become a hot topic in recent research and the data is relatively easy to obtain.
SOTA:
12. Kinetics(2017)
Link:https://deepmind.com/research/open-source/kinetics
- Kinetics 400:https://opendatalab.org.cn/Kinetics-400/download
- Kinetics 600:https://opendatalab.org.cn/Kinetics600/download
- Kinetics 700:https://opendatalab.org.cn/Kinetics_700/download
- Kinetics-700-2020:https://opendatalab.org.cn/Kinetics_700-2020/download
Size : About 135G (Kinetics 400)
Class : Class 400, 600 and 700
Brief Description : Kinetics videos come from YouTube. There are currently three versions, including 400 categories, 600 categories and 700 categories, containing 200,000, 500,000 and 650,000 videos respectively. The categories of the data set are mainly divided into three categories: interaction between people and objects, such as playing musical instruments; interaction between people, such as shaking hands and hugging; sports, etc.
This data set was released by DeepMind in the 2017 Activity challenge. When it was released, it made big news. It was called "ImageNet in the field of behavior recognition", and it suddenly felt like it opened up a new direction for the majority of CV researchers. Moreover, the I3D method that emerged at the same time has also increased the research interest in 3D convolution. Pre-training of Kinetics data can indeed add a lot to various test sets. KaiMing has also published several related works recently, which shows its influence. .
However, here is a small reminder for domestic students who want to get started. This data set is really difficult to obtain (you need to access the Internet scientifically), and there are still many YouTube URLs that are invalid and the number is huge, making it even more difficult to imagine training. One time cost. Hansong and his team recently published an article saying that Kinetics can be trained in 15 minutes. Looking at the inference of the paper, we found that more than 1,500 GPUs are needed. However, I saw on Zhihu that someone successfully obtained a version of data from a certain fish, but it seems that it is not complete.
If you want to do demo training by yourself, we recommend [Tiny-Kinetics-400] Kinetics-400 mini data set , only 600MB!
SOTA:
13. AVA(2017)
Link: https://research.google.com/ava/
Size:unknow
Class : 80 atomic action categories, more than 1.58 million action categories
Brief Description : The AVA data set contains 80 atomic visual actions. According to the action in space and time, 1.58 million action tags are generated, and there are approximately 430 15-minute video clips, which are then divided into clips. The label set is large and is used for multi-label behavior recognition tasks. Data is obtained by providing YouTube IDs, and the research interest is high.
SOTA:
14. Moments(2018)
Link: http://moments.csail.mit.edu/
Size:unknow
Class : Class 339
Brief Description : Moments is a research project developed by the MIT-IBM Watson AI Lab in 2017. This project focuses on building very large-scale datasets to help AI systems recognize and understand actions and events in videos. There are 1 million video clips in total, each clip is 3 seconds long. Includes people, animals, objects or natural phenomena. Focus on the action itself, such as opening, opening your mouth, opening a door, etc. The research is more difficult, the research enthusiasm is low, the acquisition method requires information from individuals and research institutions, and the size of the data is unknown.
SOTA:
15. Something Something v1/v2(2019)
Link: https://20bn.com/datasets/something-something
Size:20G
Class : Class 174
Brief Description : The Something Something dataset is a collection of a large number of densely labeled video clips that show humans performing predefined basic actions on everyday objects (scissors, cups, etc.). The total number of videos is more than 220,000. Free for academic research. The amount of data is moderate and the research interest is high, but the accuracy is difficult to achieve, possibly because of its video content. After watching a few videos, I found that many of the actions were very strange, such as pouring water into a cup, etc.
SOTA:
16. HowTo100M(2019)
Link: https://www.di.ens.fr/willow/research/howto100m/
Size:unknow
Class : 23k activities
Brief Description : Miech released the HowTo100M data set in 2019, which mainly consists of teaching videos to assist the model in learning multi-modal representations from videos with narration text with automatic subtitles. The researchers used WikiHow to retrieve 23,611 visual tasks that interact with the physical world, and searched for corresponding videos in YouTube based on these tasks. Finally, 136M clips were cut from 1.22M teaching videos with narration to form video-text pairs. HowTo100M far exceeds previous video pre-training data sets in terms of data volume. The data set has a total duration of 15 years, an average duration of 6.5 minutes, and an average of 110 video-text pairs per video. Different from previous manual annotation data sets, the annotation of HowTo100M is derived from automatic narration subtitles. Some video text pairs may not be aligned, and a specific text may not constitute a complete sentence content, which results in a relatively noisy data set. . However, due to the large scale of the data set, most current mainstream work still uses the HowTo100M data set for pre-training and other tasks.
SOTA:
17. HiEve(2021)
Link : http://humaninevents.org or https://gas.graviti.cn/dataset/hello-dataset/HiEve
Size:unknow
Class : Class 14
Brief Description : A new large-scale dataset for understanding human actions, postures and movements in a variety of real-world events, especially crowds and complex events. A total of 32 video sequences of some abnormal scenes (such as prisons) and abnormal events (such as fights, earthquakes) were collected on YouTube, most of which exceed 900 frames, with a total length of 33 minutes and 18 seconds, divided into 19 and 13 training and test sets. The video is carefully produced. The dataset contains 9 different scenarios.
SOTA:
18. Diving-48(2018)
Link:http://www.svcl.ucsd.edu/projects/resound/dataset.html
Size:9.6GB
Class : Class 48
Brief Description : Diving48's video footage was obtained by segmenting online videos of major diving competitions. Ground truth labels were transcribed from the information board before the start of each dive. The dataset is randomly divided into a training set of ~16k videos and a test set of ~2k videos. The aim is to create an action recognition dataset without significant bias towards static or short-term motion representations so that the model's ability to capture long-term dynamic information can be evaluated.
SOTA:
19. FineAction(2021)
Link:https://deeperaction.github.io/datasets/fineaction.html
Size:unknow
Class : Class 103
Brief Description : To take temporal action localization to the next level, we develop FineAction, a new large-scale fine video dataset collected from existing video datasets and web videos. In total, this dataset contains 139K fine motion instances densely annotated in nearly 17K uncut videos spanning 106 motion categories.
SOTA:
20.MultiSports(2021)
Link:https://huggingface.co/datasets/MCG-NJU/MultiSports
Size:unknow
Class : Class 66
Brief Description : Multiple people: In the same scene, different people perform different fine-grained actions, reducing the information provided by the background. Classification: Fine-grained action categories, accurately defined, need to describe the character's own actions, long-term information modeling, modeling of relationships between people, objects, and the environment, and reasoning. Timing: Action boundaries are well defined. Tracking: Fast movement, large deformation, and occlusion. Based on the above characteristics, we used collective sports as the background of the data set and selected a total of 66 movements from four sports: football, basketball, volleyball, and aerobics.
SOTA:
TASK
1. Video Action Classfication
What : outputclass_label
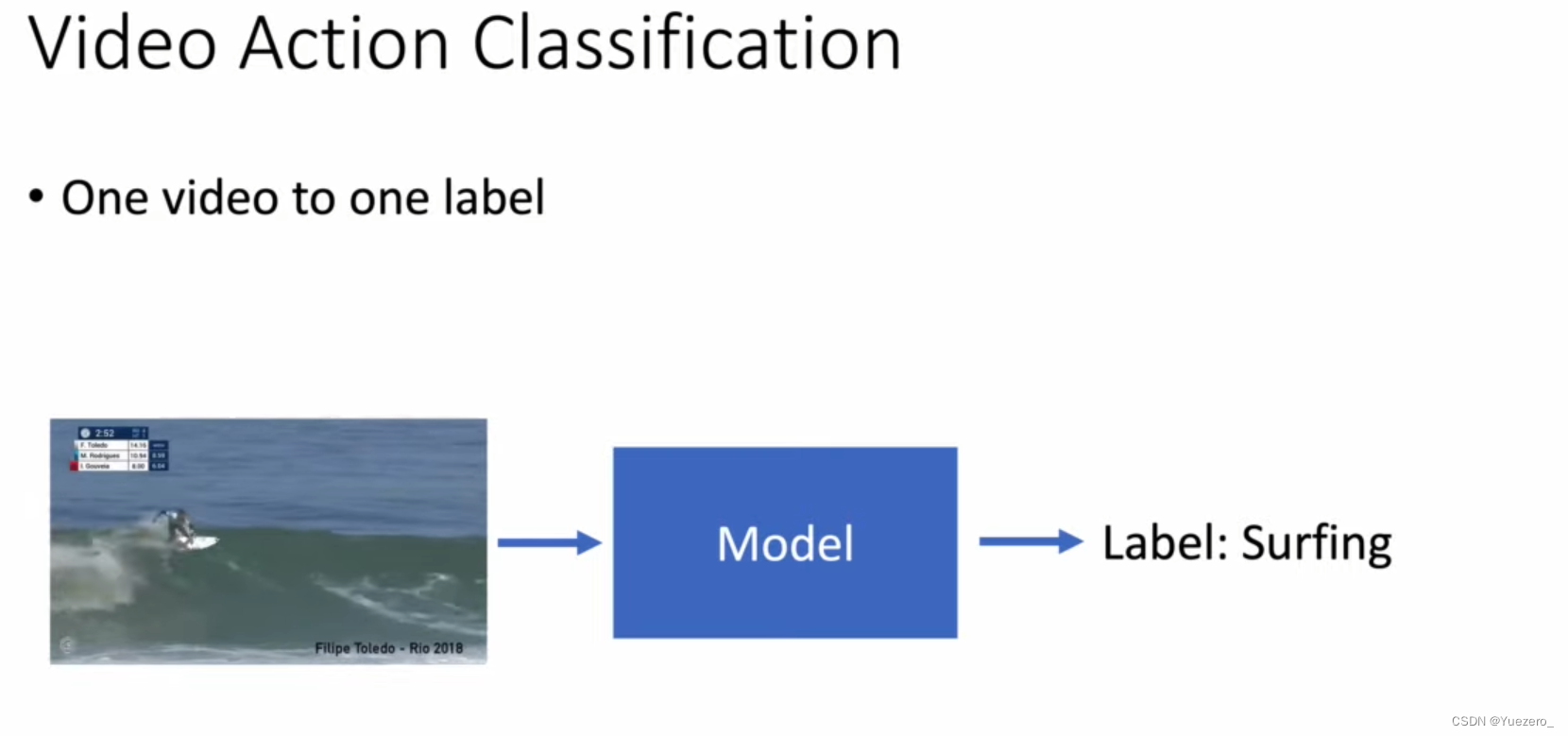
cut out
Whether the video clips have been manually cropped: Uncropped methods need to exclude irrelevant interference clips.

Number of people
Multi-person videos have more interactions between people than single-person videos

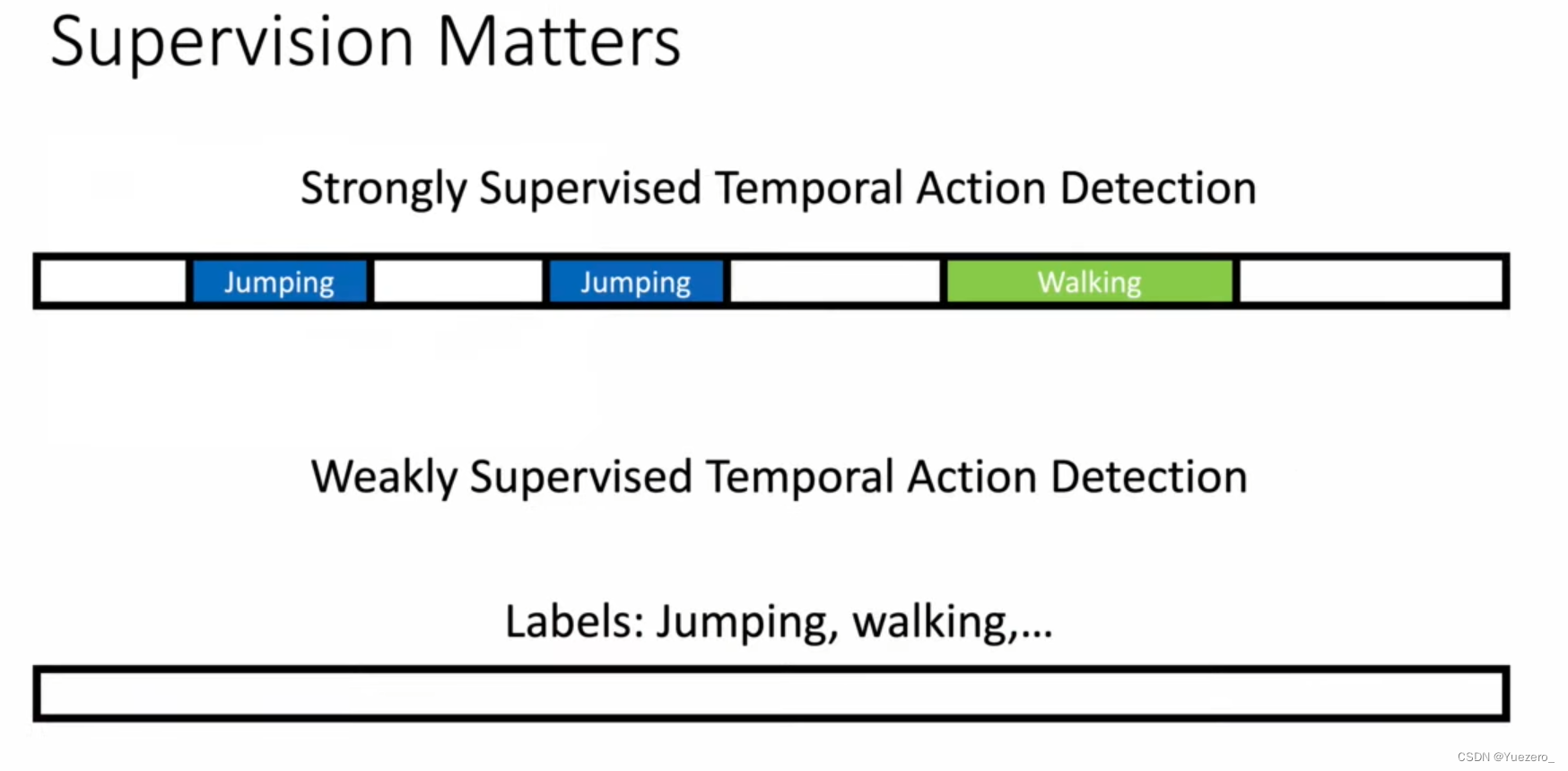
2. Temporal Action Dection
What+When : Output[class_label, start_end_timesteps]

Difficulty labeling
It is difficult to collect labeled long video data, which inspires people to do weakly supervised learning
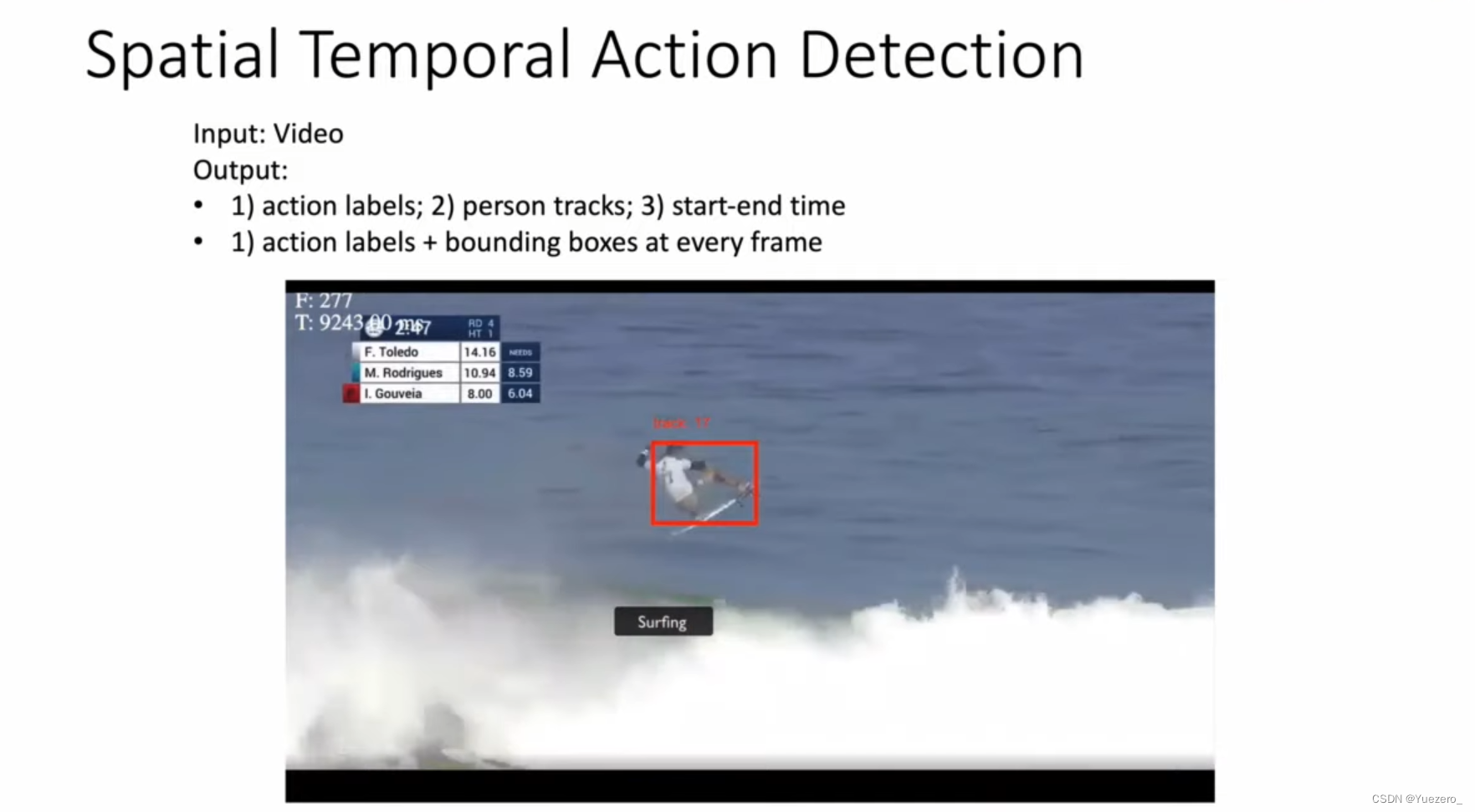
3. Spatial Temporal Action Detection
What+When+Where : Output [class_label, bbox, start_end_time]
4. Continuous learning
Online models can learn from examples they have already seen
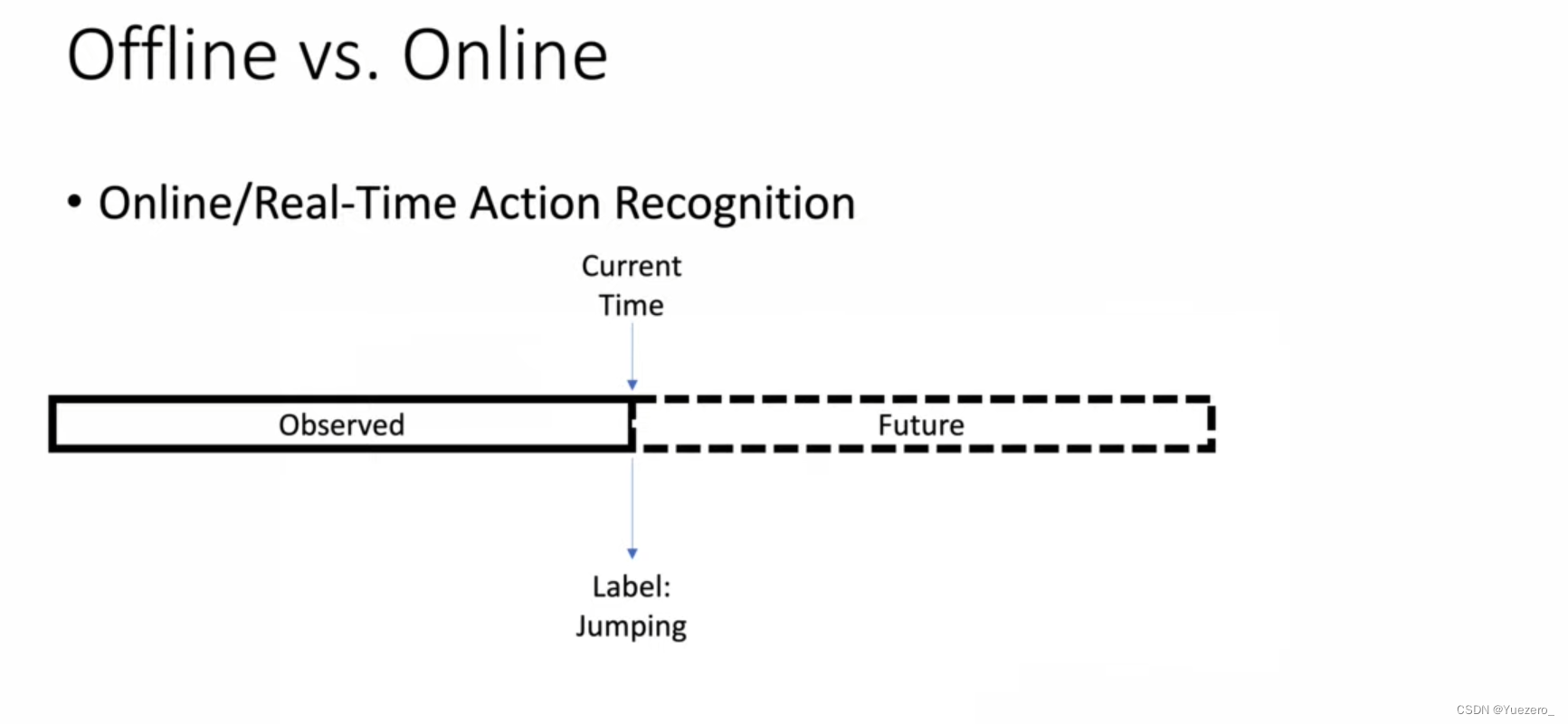
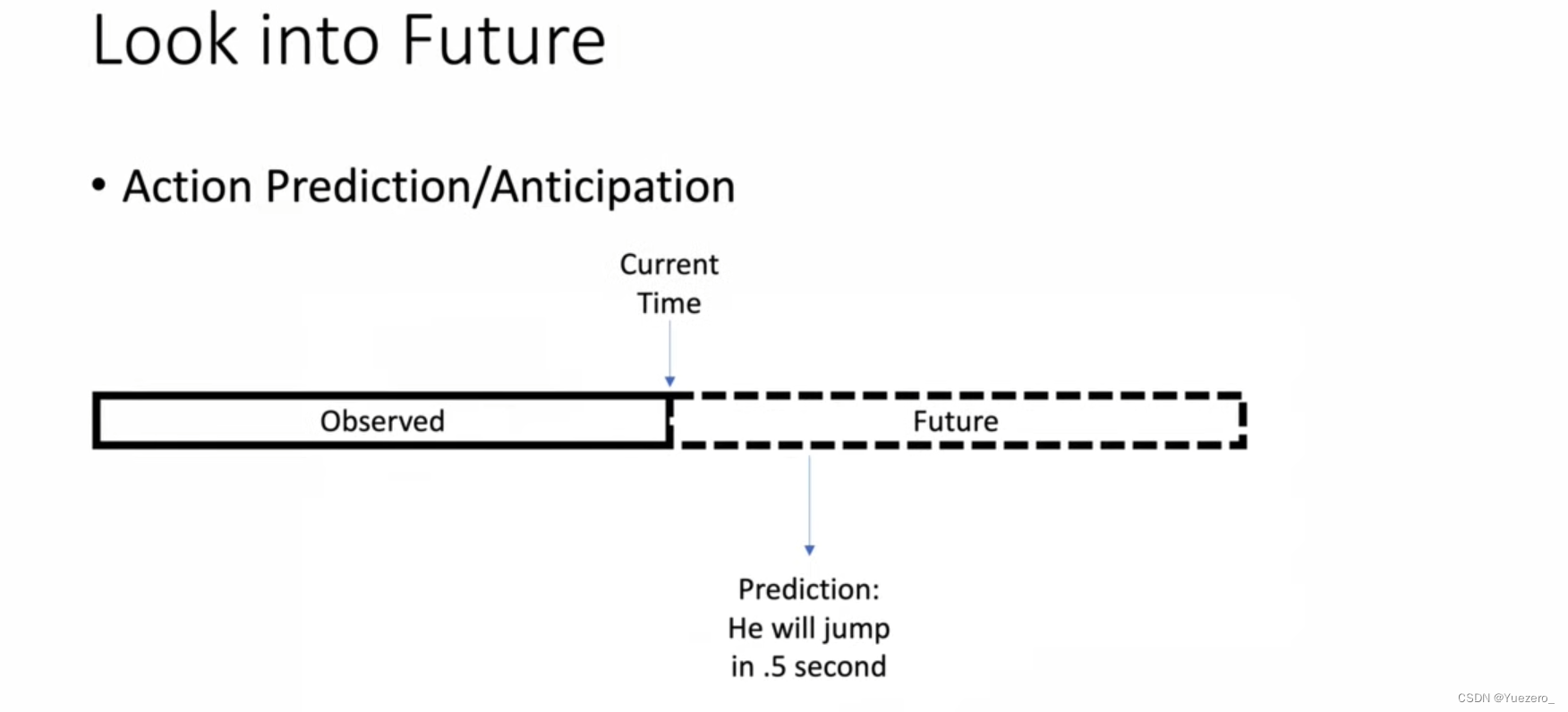
5. Action prediction
Predict what's next based on some of the video clips you've watched