The paper proposes a hybrid network based on convolution and VIT, using Transformers to capture long-range dependencies and CNN to extract local information. A series of models cmt are built, which have better trade-offs in terms of accuracy and efficiency.

CMT: Architecture
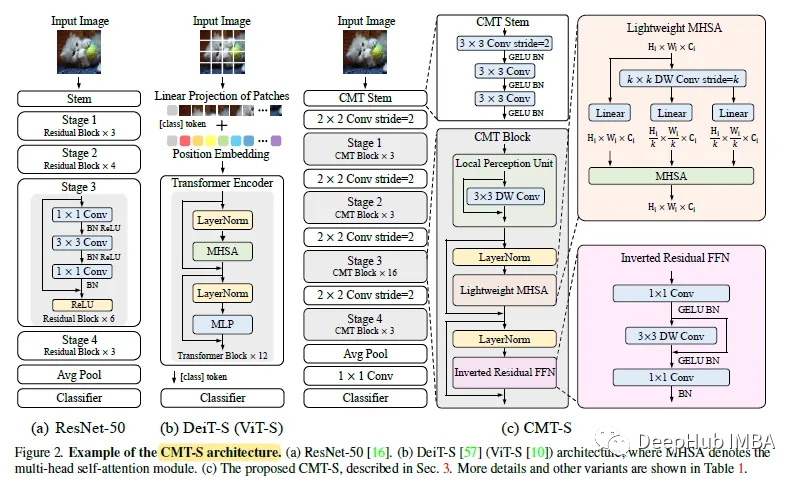
The CMT block consists of a local sensing unit (LPU), a lightweight multi-head self-attention module (LMHSA), and an inverse residual feedforward network (IRFFN).
1. Local sensing unit (LPU)
The absolute position encoding used in previous transformers was designed to exploit the order of markers, which broke translation invariance.
To alleviate limitations, LPU uses convolution (MobileNetV1) to extract local information, which is defined as:
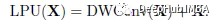
2. Lightweight Bull Self Attention (LMHSA)
In the original attention module, the self-attention module is:

In order to reduce the computational overhead, k × k depth convolution (MobileNetV1) with stride k is used to reduce the spatial size of k and V before the attention operation. Add a relative position bias B in each self-attention module (similar to Shaw NAACL '18):

The h here are attention heads similar to ViT.
3. Inverse residual feedforward network (IRFFN)
The original FFN uses two linear layers with a GELU in the middle:

IRFFN consists of an expansion layer (MobileNetV1) and a convolution (projection layer). For better performance, the position of the residual connection is also modified:

Use deep convolutions (MobileNetV1) to extract local information with negligible additional computational cost.
4. CMT block
With the above three components, the CMT block can be formulated as:
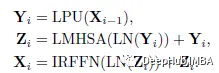
In the above formula, Yi and Zi represent the output characteristics of the LPU and LMHSA modules for the i-th block respectively. LN stands for layer normalization.
CMT variants
1. Model complexity
The computational complexity (FLOPs) of Transformer can be calculated as:

In the formula, r is the expansion ratio of FFN, dk and dv are the dimensions of key and value respectively. ViT assumes d = dk = dv, r = 4, then the calculation can be simplified as:
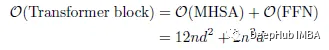
FLOPs of CMT blocks:

Among them, k≥1 is the reduction ratio of LMHSA.
As can be seen, the CMT block is more computationally cost friendly and easier to process feature maps at higher resolutions (larger n) than the standard Transformer block.
2. Expansion strategy
Inspired by EfficientNet, use the composite coefficient φ to uniformly scale the number of layers (depth), dimension and input resolution:
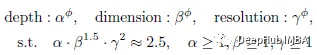
The constraint of α·β^(1.5) ·γ²≈2.5 is added, so for a given new φ, the total FLOPS will increase by approximately 2.5^φ. According to the test, the default is α=1.2, β=1.3, γ=1.15.
3. CMT variants
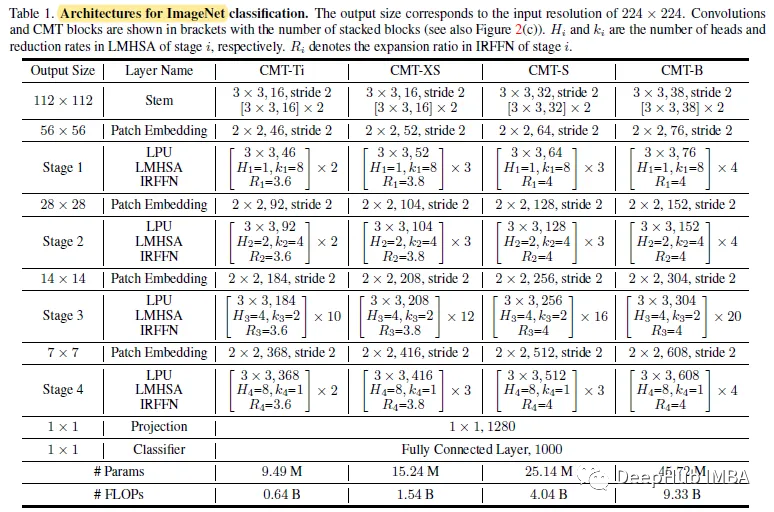
On the basis of CMT-S, CMT-Ti, CMT-XS and CMT-B were constructed according to the proposed scaling strategy. The input resolutions of the four models are 160, 192, 224 and 256 respectively.
result
1. Ablation research

ViT/DeiT can only generate single-scale feature maps, losing a lot of multi-scale information, but this part of information is crucial for dense prediction.
DeiT has the same 4-stage stage as CMT-S, namely DeiT-s-4stage, which can achieve improvements.
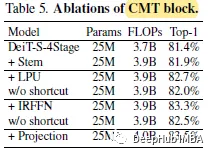
All incremental improvements show that stem, LPU and IRFFN also make important contributions to performance improvements. CMT uses LN before LMHSA and IRFFN, and inserts BN after the convolutional layer. If all LNs are replaced by BN, the model cannot converge during the training process.

2.ImageNet
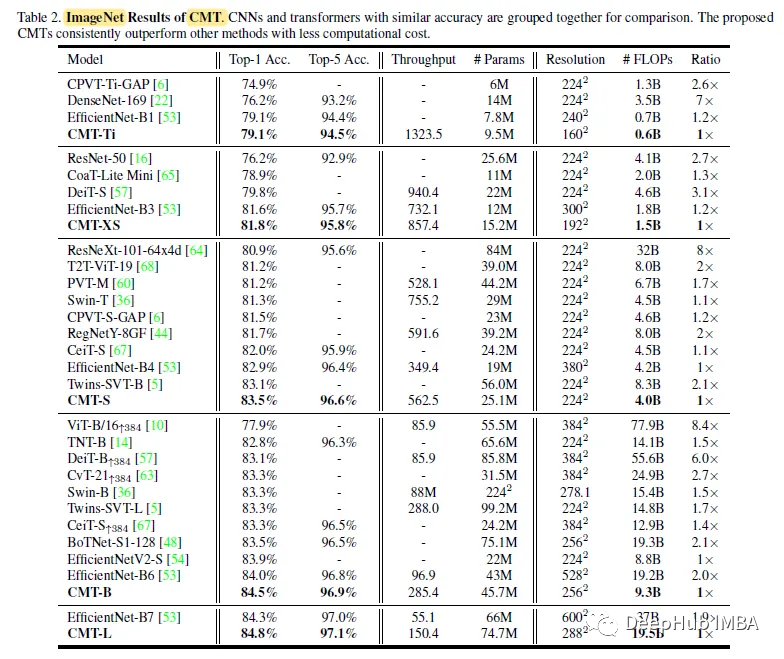
CMTS achieves 83.5% top-1 accuracy with 4.0B FLOPs, which is 3.7% higher than the baseline model DeiT-S and 2.0% higher than CPVT, indicating the advantages of CMT blocks in capturing local and global information.
It is worth noting that all previous transformer-based models are still inferior to EfficientNet obtained through thorough architecture search, but CMT-S is 0.6% higher than EfficientNet-b4 and has lower computational cost, which also proves the effectiveness of the proposed hybrid structure sex.
3. Downstream tasks
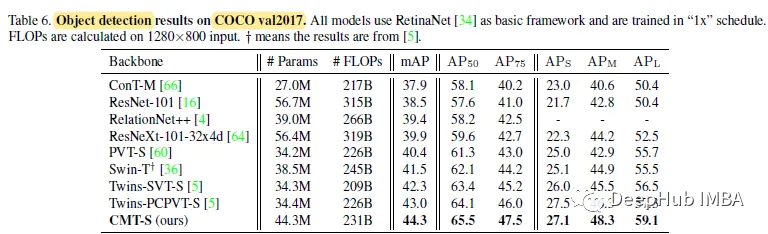
For target detection with RetinaNet as the basic framework, CMT-S is better than twin-pcpvt-s (mAP is 1.3%) and twin-svt-s (mAP is 2.0%).

For segmentation using Mask R-CNN as the basic framework, CMT-S surpassed Twins-PCPVTS with 1.7% AP and surpassed Twins-SVT-S with 1.9% AP.

CMT-s outperforms other transformer-based models with fewer FLOPs in all datasets and achieves comparable performance to EfficientNet-B7 with 9x fewer FLOPs, which demonstrates the superiority of the CMT architecture.
Paper address:
https://avoid.overfit.cn/post/2da9f18b7b6d4da89b44eb16c861ab88