0x0. Preamble
The Segment Anything Model (SAM) proposed by Meta last month hopes to solve the problem of target segmentation through the routine of Prompt + basic large model in the visual field. After actual measurement, the performance of SAM in most scenarios is amazing enough, and various secondary creative work based on SAM has also exploded, such as Grounded-Segment-Anything that detects everything (https://github.com/IDEA-Research/Grounded -Segment-Anything), which extends Segment Anything to the field of medical images . But at present, the Chinese community does not seem to do a detailed analysis of the SAM model, so here is a fork of the SAM warehouse and a detailed code analysis of the model implementation part. The address of the fork warehouse is as follows: https://github.com/Oneflow -Inc/segment-anything .
This article will try to sort out the code of the SAM model part by comparing the structure diagram of the paper and the code comments in the fork's SAM warehouse. Finally, I will also introduce what to do if you want to use oneflow to run SAM. In fact, just add 2 lines of code to the prediction script:
import oneflow.mock_torch as mock
mock.enable(lazy=True, extra_dict={
"torchvision": "flowvision"})
Finally, summarize what this fork's SAM warehouse does:
- Sinicize the inference script below https://github.com/Oneflow-Inc/segment-anything/tree/main/notebooks.
- Sinicize https://github.com/Oneflow-Inc/segment-anything/blob/main/README_zh.md.
- Conduct a comprehensive analysis of the model implementation of https://github.com/Oneflow-Inc/segment-anything/tree/main/segment_anything/modeling SAM, and add Chinese comments for each function code implementation.
- The mock torch technology based on oneflow can switch the oneflow backend to run SAM model reasoning with one click, which is convenient for secondary development and performance optimization based on oneflow.
Welcome to click star: https://github.com/Oneflow-Inc/segment-anything
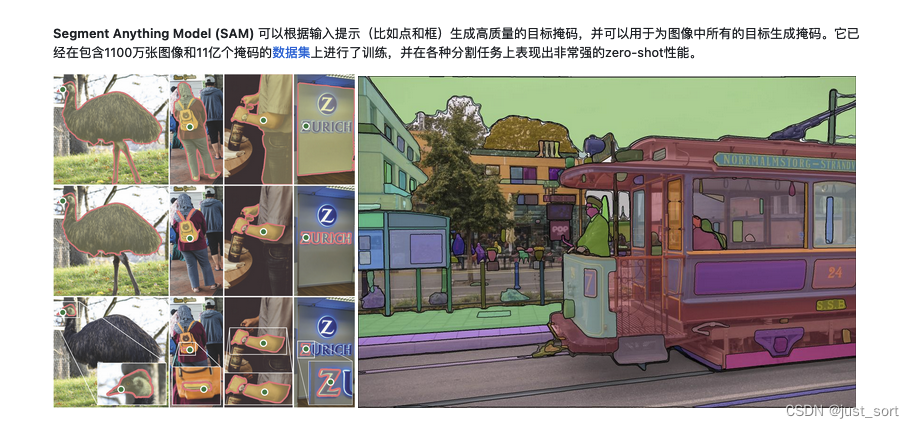
0x1. Model + code analysis
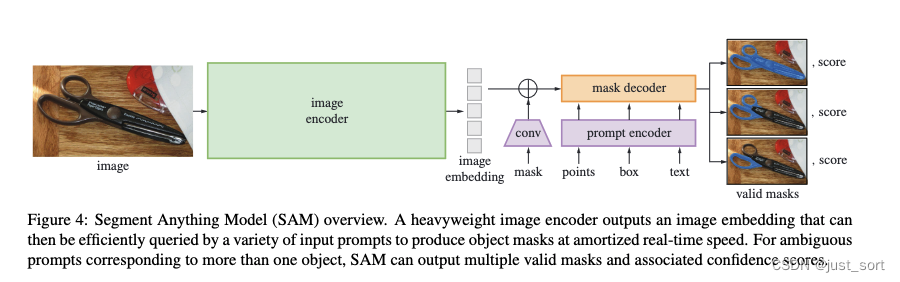
In fact, the model implementation part corresponds to this picture.
The green part indicates that the original image is encoded as a vector, and VIT is used in SAM to implement the image encoder. The original image is scaled to 1024the size of the ratio and padding (corresponding https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/sam.py#L131), and then the convolution is used to discretize kernel sizethe image into a vector (corresponding ,), and the vector is sequentially flattened on W and C ( ) and then Enter the multi-layer transformer encoder, and the vector output by vit is then compressed to the feature dimension ( ) by two layers of convolution (kernel size and respectively , and each layer output is connected to LayerNorm2d) .16stride16batch_size x 64x64X768https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py#L482-L518https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py#L20813256https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py#L98-L114
For an explanation of the detailed code details of the image encoder part, please check: https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py
https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/prompt_encoder.py#L251Next, the purple part represents the prompt encoder. The output of the prompt encoder includes sparse_embeddings that encode points, boxes, and text, and dense_embeddings (corresponding ) that encodes the input mask. Finally, the output shape of sparse_embeddings is batch_sizexNx(embed_dim=256), where N is determined by the number of input points and boxes. The output shape of dense_embeddings is batch_sizex(embed_dim=256)x(embed_H)x(embed_W), where embed_H and embed_H are both equal to 64. ( https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/build_sam.py#L73). Note that the convolution operation on the mask corresponds to the image https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/prompt_encoder.py#L64-L71.
Please refer to the explanation of the detailed code details of the prompt encoder part: https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/prompt_encoder.py
Finally, let's look at the Mask Decoder part, which is the orange part in the picture. The details of Mask Decoder can be represented by the following figure:
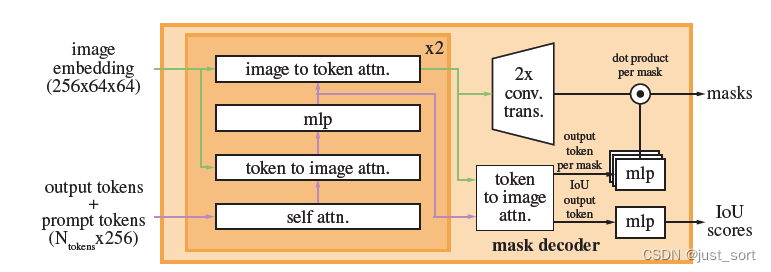
The image embedding (256x64x64) here is the output of the above image decoder, because when it is input to the Mask Decoder, the batch dimension is traversed and then processed, so there is no Batch in the dimension here. Then output tokens+prompt tokens in the lower left corner( N tokens × 256 N_{tokens}\times 256Ntokens×256 ) represent the iou token embedding and the embedding of the three segmentation result tokens (sparse_embeddings+dense_embeddings) respectively. (Corresponding to:https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/mask_decoder.py#LL171C9-L173C1). Another detail that needs to be noted here is that the dense embedding in the prompt embedding part is directly superimposed on the image embedding. (correspondinghttps://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/mask_decoder.py#L175-L177C18).
Then each layer in the Transformer implementation does
- Token embedding does self attention calculation.
- Do cross attention calculation between token embedding and src.
- Do cross attention calculation between src and token embedding.
- There is a feed-forward MLP network between the 2nd and 3rd; the results of the cross attention are added and normed by the residual method.
For detailed code explanation, please see: https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/transformer.py#L133-L244
There is an x2 in the upper right corner of the Transformer block, which means that the number of Transformer layers is 2. Then the purple and green arrows here indicate the source of the query, key, and value of the current Attention module, and each layer has 1 self attention and 2 cross attention modules. Before the final output of transform, the token embedding needs to do a cross attention with src, which is the token to image attn in the figure.
Finally, the 3 mask token embeddings returned by Transform pass through 3 layers of mlp, and dot product with the aligned image embeddings to get 3 final segmentation results; the iou token gets 3 segmentation result confidence scores through mlp. (Corresponding to: https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/mask_decoder.py#L182-L199)
0x2. Switch the backend of SAM
SAM's inference script runs with PyTorch by default. If you want to use oneflow to execute and try to get inference acceleration, you can add before running the script:
import oneflow.mock_torch as mock
mock.enable(lazy=True, extra_dict={
"torchvision": "flowvision"})
The OneFlow version needs to be installed nightly, so that OneFlow can be used as the backend to infer SAM. For mock torch black magic, you can check https://docs.oneflow.org/master/cookies/oneflow_torch.html This official document.
The installation method of oneflow nightly version is as follows: https://github.com/Oneflow-Inc/oneflow#install-with-pip-package
Unfortunately, we have not had time to do tuning work in the future. If you are interested in using OneFlow to accelerate SAM reasoning, you can try to contact me personally to discuss and implement it.
0x3. Summary
This article introduces some things done by https://github.com/Oneflow-Inc/segment-anything and analyzes the structure and code implementation of SAM. For SAM, more important than the model is the most important data processing, you can refer to this aspect: https://zhuanlan.zhihu.com/p/620355474
0x4. Follow-up work
If I have time later, I will continue to Chineseize the jupyet notebook exported by onnx, and do some related performance tuning work and the analysis of the remaining SamAutomaticMaskGenerator.