Segment Anything Model (SAM) is a new image segmentation task and model recently open sourced by Facebook Research. Segment Anything Model (SAM) can generate high-quality object masks from input cues such as points or boxes, and can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 11 billion masks, enabling zero-shot transfer to new image distributions and tasks. Its segmentation effect is amazing, and it is the current algorithm for segmenting SOTA.
SAM code: https://github.com/facebookresearch/segment-anything
SAM official website: https://segment-anything.com
SAM paper: https://arxiv.org/pdf/2304.02643.pdf
1 Overview
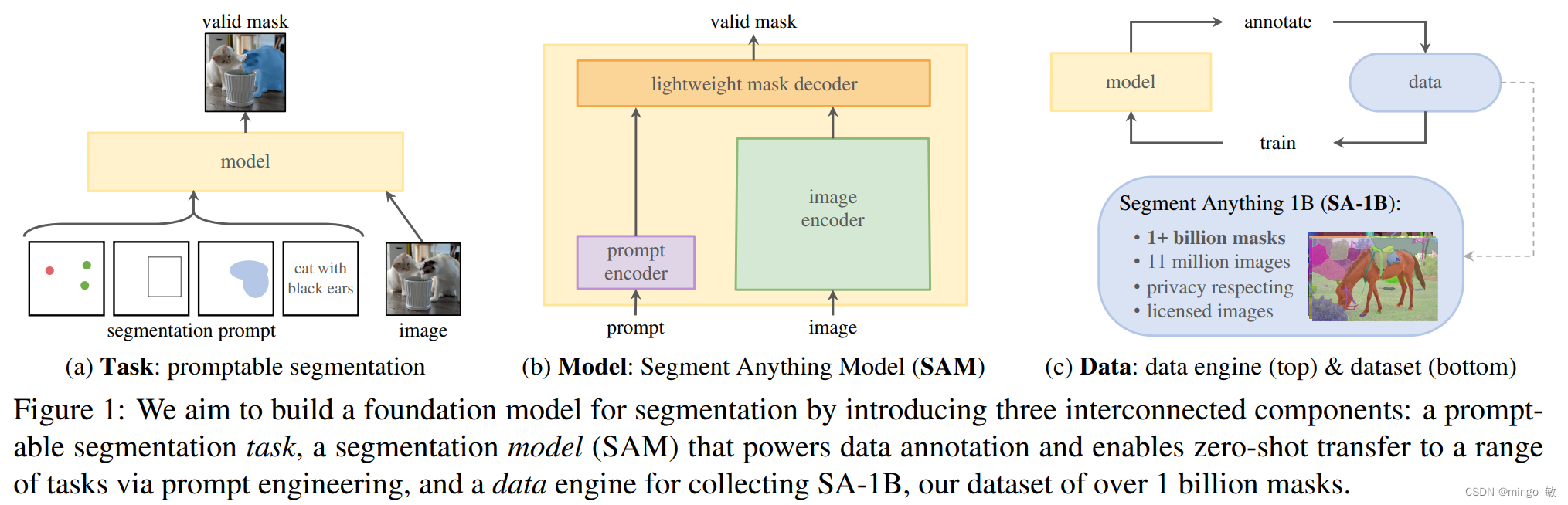
SAM, or Segment Anything, uses the idea of Prompt in the NLP task to complete the rapid segmentation of any target by providing a Prompt prompt for the image segmentation task. A hint can be a set of foreground/background points, a rough box or mask, arbitrary text, or any information that indicates that segmentation needs to be done in the image. The input of this task is the original image and some prompts, and the output is the mask information of different targets in the picture.
2 Segment Anything Task
Translating the concept of hints in NLP into the domain of segmentation. In this domain, a hint can be a set of foreground/background points, a rough box or mask, free text, or generally anything that indicates what to segment in the image. Hence, the hintable segmentation task is to return an efficient segmentation mask given any hint. By "effective" masks, the output should be a plausible mask for at least one object, even if the cue is ambiguous and may involve multiple objects.
3 Segment Anything Model
The Segment Anything Model (SAM) model for hinted segmentation consists of three components: image encoder, hint encoder, and mask decoder.
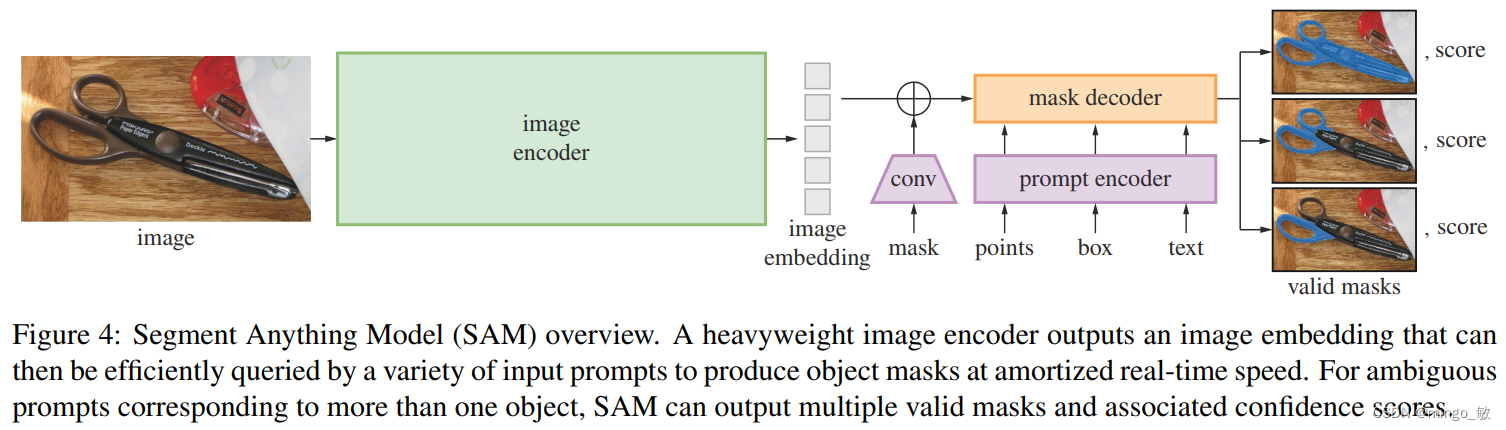
Image encoder Image encoder . Uses a MAE pre-trained Vision Transformer (ViT) with minimal adaptation to handle high-resolution inputs, which is designed to improve scalability and leverage powerful pre-training methods. The image encoder runs only once per image and can be applied before hinting the model.
Prompt encoder Prompt encoder . Consider two sets of cues: sparse cues (points, boxes, text) and dense cues (masks). For points and boxes, we use positional encoding [95] representations, plus learned embeddings for each cue type. For free text, an off-the-shelf text encoder from CLIP [82] is used for representation. For dense cues (i.e. masks), convolutional embeddings are used and added element-wise with image embeddings.
Mask decoder mask decoder . And finally the mask decoder. A mask decoder efficiently maps image embeddings, cue embeddings, and output tokens to masks. This design employs a modified version of the Transformer decoder block followed by a dynamic mask prediction header. The modified decoder block updates all embeddings using hinted self-attention and cross-attention in both directions (hint-to-image embedding and vice versa). After running both blocks, image embeddings are upsampled and output tokens are mapped to a dynamic linear classifier using an MLP, and masked foreground probabilities are then computed at each image location.
Resolving ambiguity resolves ambiguity . For an ambiguous cue, if there is only one output, the model will average over multiple valid masks. To address this issue, we modify the model so that it can predict multiple output masks for a single cue. We found that predicting 3 mask outputs is sufficient for most common cases (nested masks are usually at most three levels: whole, part, and subpart). To better train the model, we only backpropagate the smallest mask loss to ensure the model can focus on the most accurate masks. In addition, we predict a confidence score for each mask in order to rank the masks. This confidence score is derived from the IoU between the predicted mask and the ground truth mask. In this way, we can better guide the model learning how to produce accurate masks during training.
Efficiency . The design of the whole model is mainly for the pursuit of high efficiency. Given precomputed image embedding vectors, the hint encoder and mask decoder can run CPU-wise on a web browser in about 50 ms. This runtime performance enables our model to achieve seamless, real-time interactive prompting.
Losses and training loss and training . For supervised mask prediction, we employ a linear combination of focal loss and dice loss. We train the cueable segmentation task using a series of geometric cues. To simulate an interactive setting, we randomly sample 11 rounds of cues in each mask so that the SAM can be seamlessly integrated into our data engine.
4 Segment Anything Data
4-1 Segment Anything Data Engine
Since segmentation masks are not abundant on the Internet, we built a data engine to collect our 1.1B mask dataset SA-1B. This data engine is divided into three phases: (1) a model-assisted manual annotation phase, (2) a semi-automatic phase, including automatic prediction masks and model-assisted annotations, and (3) a fully automatic phase, in which our model Masks can be generated without input from annotators.
Assisted-manual stage: Early in the model-assisted manual annotation stage, SAMs are trained using common public segmentation datasets. With the addition of data annotations, we retrain the SAM using the newly annotated masks, and refine the image encoder extensions and other architectural details. In the assisted manual phase, similar to classic interactive segmentation, masks are labeled by a team of professional annotators by clicking on foreground/background object points in a browser-based interactive segmentation tool powered by SAM. We do not enforce semantic constraints to label objects, and annotators freely label "items" and "substances". We suggested that annotators mark objects that they could name or describe, but did not collect these names or descriptions. Annotators are asked to label objects by prominence.
At this stage, we collected 4.3M masks from 120k images.
Semi-automatic stage: In the semi-automatic stage, we aim to increase the diversity of masks to improve the model's ability to segment any object. To allow annotators to focus more on less conspicuous objects, we first automatically detect confident masks. We then apply these masks to the images and ask the annotators to label any uncovered objects. To detect confident masks, we train a bounding box detector on all first-stage masks using a common "object" category.
At this stage, we collect an additional 5.9M masks, for a total of 10.2M masks.
Fully automatic stage: In the fully automatic stage, labeling becomes fully automatic. This is due to our model undergoing two major improvements. First, at the beginning of this stage, we have collected enough masks to substantially improve the model, including diverse masks from the previous stage. Second, at this stage, we develop ambiguity-aware models that allow us to predict effective masks in ambiguous situations. Specifically, we cue the model through a 32×32 point matrix and predict for each point a set of masks that may correspond to valid objects. With ambiguity-aware models, if a point lies on a part or subpart, our model returns subparts, parts, and the whole object. The IoU prediction module of our model is used to select confident masks; in addition, we also identify and select stable masks (we think that if we set the probability map threshold at 0:5-δ and 0:5+δ, the result A similar mask is a stable mask). Finally, after selecting confident and stable masks, we apply non-maximum suppression (NMS) to filter duplicate masks. To further improve the quality of smaller masks, we also handle multiple overlapping downscaled image crops.
We applied fully automatic mask generation to all 11M images in our dataset, resulting in a total of 1.1B high-quality masks.
4-2 Segment Anything Dataset
Our dataset SA-1B consists of 11 million diverse, high-resolution, licensed and privacy-preserved images, and 1.1 billion high-quality segmentation masks, collected through our data engine.
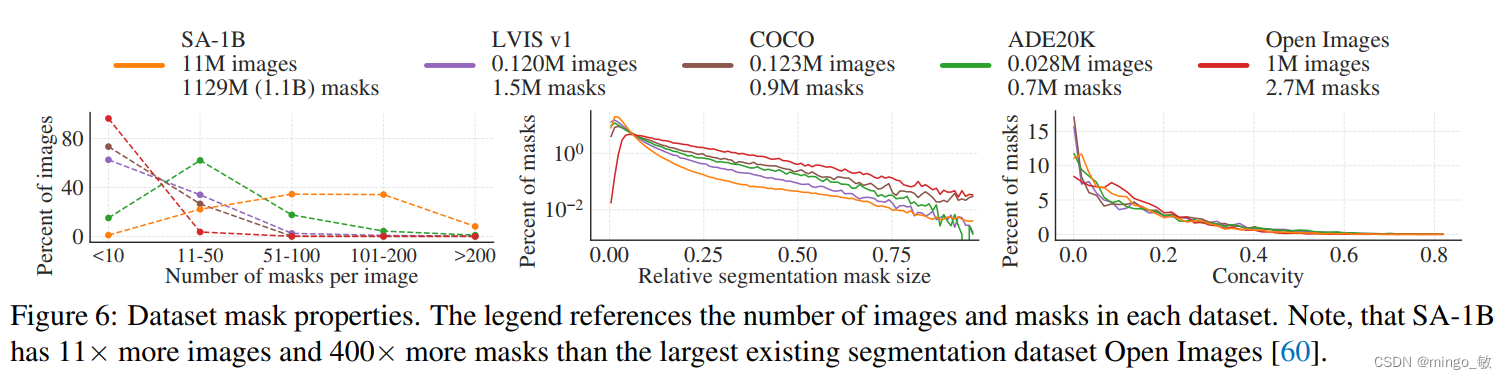
Images , we obtained a new set of 11 million images from vendors who work directly with photographers, these images are high resolution (average 3300×4950 pixels each), but the data size may bring access and Storage challenges. Therefore, the images we publish are all downsampled and set to 1500 pixels on the shortest side. Even after downsampling, our image resolution is still much higher than that of many existing vision datasets (for example, the image size in the COCO dataset is about 480 × 640 pixels).
For Masks , our data engine generated 1.1 billion masks, 99.1% of which were fully automated. Therefore, the quality of automatic masks is critical. Compared with the main segmentation datasets, our automatic masking is of high quality and effective for training models. Therefore, SA-1B contains only automatically generated masks.
Mask quality The quality of the mask , we randomly sampled 500 images (~50k masks) and asked professional annotators to use our model and pixel-accurate "brush" and "eraser" editing tools to improve the quality of these images The quality of all masks. This process yields a set of automatically predicted and professionally corrected masks. We calculated the IoU between each pair of masks and found that 94% of the log IoUs were greater than 90% (97% of the log IoUs were greater than 75%). In contrast, previous studies estimated inter-annotator agreement at 85-91% IoU. Our experiments further confirm the high quality of the masks, and the fact that training a model with automatic masking performs nearly identically to all masks generated using the data engine.