Pandas features:
1. It provides a simple, efficient, DataFrame object with default labels (you can also customize labels).
2. Can quickly load data from files in different formats (such as Excel, CSV, SQL files), and then convert them into processable objects; 3. Can group by row and
column labels of data, and group
4. Can easily implement data normalization and missing value processing; 5.
Can easily add, modify or delete DataFrame data columns;
6. Can handle different Format datasets, such as matrix data, heterogeneous data tables, time series, etc.;
provide a variety of ways to process datasets, such as building subsets, slicing, filtering, grouping, and reordering.
Pandas built-in data structures
There are two main data structures are Series (one-dimensional data structure) and DataFrame (two-dimensional data structure):
Series is a labeled one-dimensional array, where the label can be understood as an index, but this index is not limited to integers, it can also be a character type, such as a, b, c, etc.; DataFrame is a tabular data structure
, It has both row and column labels.

1.Series
First of all, we must understand that the index has row index (0~N integer) and column index (0~N integer)
Create a Series object

The index above is not defined so starts from 0 (implicit index)
The following is an explicit index" method to define the index label

dict creates a Series object (specify an index for the data)

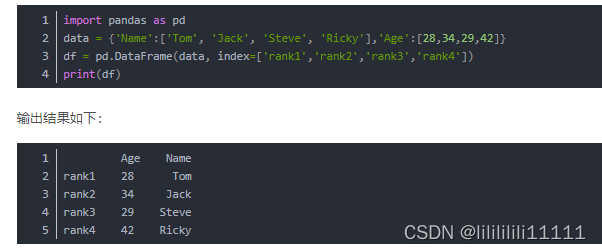
DataFrame (simplely regarded as an Excel table, when creating an array, the row index (index) and column index (columns) can be automatically generated)
List
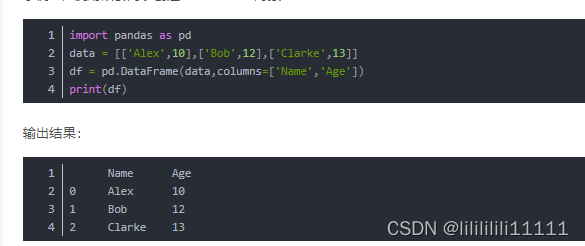
OK
Use an index to get a column of data
element=df_obj['要获取的哪列数据名称'] #df_obj是基于数组创建DataFrame对象的名称可以自己修改
element #输出结果
type(element) #查看返回的结果Get a column of data by name
element=df_obj.No2 #No2就是要获取的那列数据名称根据自己需求自己修改
elementAdd a column of data to DataFrame
df_obj['No4']=['g','h'] #添加的列名称为No4,第一行为g,第二行为h。
df_objDelete a column of data for DataFrame
del df_obj['No3'] #删除No3的一列数据
df_objPandas index object can be modified or not modified

pandas reset index

Specifies the padding value for padding when resetting the index

index operation

Indexing operations on DataFrame

pandas sort by index

pandas statistical calculation and description
import numpy as np
import pandas as pd
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj)
print('求和')
print(df_obj.sum())
print('求最大值')
print(df_obj.max())
print('按行求最小值')
print(df_obj.min(axis=1))
hierarchical index
http://t.csdn.cn/6pGGD (very good example article)
Read and write data operations

Operation:


Program question
Answer:
import numpy as np
arr = np.zeros(5)
print(arr)
Answer:
import numpy as np
arr = np.zeros((8,8),dtype=int)
arr[1::2,::2] = 1
arr[::2,1::2] = 1
print(arr)