Table of contents
1. Synchronization container class
1.1 - Issues with synchronous container classes
1.2 - Iteration and container locking
2.2 - CopyOnWriteArrayList class
3. Blocking queue and producer-consumer mode
4. Blocking method and interrupt method
5.2 - Using FutureTask as a lock
5.6 - Building an efficient and scalable result cache
Delegating is one of the most effective strategies for creating thread-safe classes : just let the existing thread-safe class manage all the state. The Java platform class library contains a wealth of concurrency basic building blocks, such as thread-safe container classes and various synchronization tool classes (Synchronizers) for coordinating the control flow of multiple threads that cooperate with each other.
API documentation for the Java Concurrency classes, click here .
1. Synchronization container class
Synchronized container classes include Vector and Hashtable , both of which were part of the early JDK. These synchronized wrapper classes are created by factory methods such as Collections.synchronizedXxx . The way these classes achieve thread safety is to encapsulate their state and synchronize each public method so that only one thread at a time can access the state of the container
1.1 - Issues with synchronous container classes
Synchronization container classes are thread-safe, but in some cases composite operations also require additional client-side locks for protection. Common compound operations on containers include: iteration (repeatedly access elements until all elements in the container are traversed), jump (find the next element of the current element according to the specified order), and conditional operations , such as "add if there is no" (check Whether there is a key value K in the Map, if not, join the two-tuple (K, V)). //Many current concurrent containers have not completely solved the problem of composite operations, and the locking granularity of synchronous containers is relatively large
1.2 - Iteration and container locking
Lock the container during iteration. If the size of the container is large, or if the operation takes a long time to perform on each element, then these threads will wait for a long time. Even if there is no risk of starvation or deadlock, locking the container for a long time will reduce the scalability of the program. The longer the lock is held, the more likely the competition on the lock will be, and if many threads are waiting for the lock to be released, throughput and CPU utilization will be greatly reduced . //Disadvantages of locking the entire container
If you don't want to lock the container during iteration, an alternative is to "clone" the container and iterate over the copy. Since the copy is enclosed within the thread, other threads will not modify it during the generation, thus avoiding throwing ConcurrentModificationException (the container still needs to be locked during the cloning process). There is a significant performance overhead when cloning containers. How good this approach is depends on several factors, including the size of the container, the work to be performed on each element, how often the iterative operations are called relative to other operations on the container, and your needs in terms of response time and throughput. //It is a good idea to create a copy/snapshot to iterate the container
2. Concurrent container class
Java 5.0 provides various concurrent container classes to improve the performance of synchronous containers. Synchronized containers serialize all access to container state to achieve their thread safety. The cost of this method is a serious reduction in concurrency, when multiple threads compete for the
lock of the container, the amount of leaf throughput will be severely reduced. //Synchronous container class performance is low

Concurrent containers, on the other hand, are designed for concurrent access by multiple threads. ConcurrentHashMap was added in Java 5.0 to replace the synchronized hash-based Map, and CopyOnWriteArrayList to replace the synchronized List when the traversal operation is the main operation. Added support for some common composite operations in the new ConcurrentMap interface, such as "add if not present", replace, and conditionally delete. //Learning concurrent container classes is important to operate and use
Replacing synchronous containers with concurrent containers can greatly improve scalability and reduce risk.
2.1 - ConcurrentHashMap class
Like HashMap, ConcurrentHashMap is also a hash-based Map, but it uses a completely different locking strategy to provide higher concurrency and scalability. ConcurrentHashMap does not synchronize each method on the same lock so that only one thread can access the container at a time, but uses a finer-grained locking mechanism to achieve greater sharing. It is called a segment lock (Lock Striping) . In this mechanism, any number of read threads can access the Map concurrently, threads performing read operations and threads performing write operations can access the Map concurrently, and a certain number of write threads can modify the Map concurrently. As a result of ConcurrentHashMap, higher throughput will be achieved in a concurrent access environment, while only a very small loss of performance in a single-threaded environment. //Compared with HashTable, it has better concurrency performance
ConcurrentHashMap enhances the synchronized container classes along with other concurrent containers: they provide selectors that do not throw ConcurrentModificationException, so there is no need to lock the container during the selection process. The selector returned by ConcurrentHashMap has weak consistency (Weakly Consistent) , rather than "failure in time".
A weakly consistent selector can tolerate concurrent modification. When creating an iterator, it will traverse existing elements and can (but not guarantee) reflect the modification operation to the container after the selector is constructed. // can only reflect the temporary state
2.2 - CopyOnWriteArrayList class
CopyOnWriteArrayList is used as an alternative to synchronized List, which provides better concurrency performance in some cases and does not require locking or copying of the container during iteration . (Similarly, the role of CopyOnWriteArraySet is to replace the synchronization Set)
The thread-safety of Copy-on-Write (Copy-0n-Write) containers is that as long as a de facto immutable object is properly published, no further synchronization is required when accessing that object. On each modification, a new copy of the container is created and republished, enabling mutability . Iterators for copy-on-write containers keep a reference to the underlying underlying array, which is currently at the start of the iterator, and since it will not be modified, it is only necessary to ensure that the contents of the array are visibility. Thus, multiple threads can iterate over this container concurrently without interfering with each other or with threads modifying the container. The iterator returned by the "copy-on-write" container will not throw ConcurrentModificationException, and the returned element is exactly the same as the element when the iterator was created, regardless of the impact of subsequent modification operations.
3. Blocking queue and producer-consumer mode
Blocking queues support the producer-consumer design pattern. This mode separates the two processes of "finding work that needs to be done" from "doing work", and puts work items on a "to be done" list for later processing, rather than immediately after finding out. The producer-consumer pattern simplifies the development process because it eliminates the code dependencies between producer and consumer classes. In addition, the pattern also decouples the process of producing data from the process of using data to simplify Workload management because the two processes differ in the rate at which data is processed. //BlockingQueue
Bounded queues are a powerful resource management tool when building highly reliable applications: they throttle and prevent the generation of too many work items, making the application more robust under load.
Blocking queues in Java:
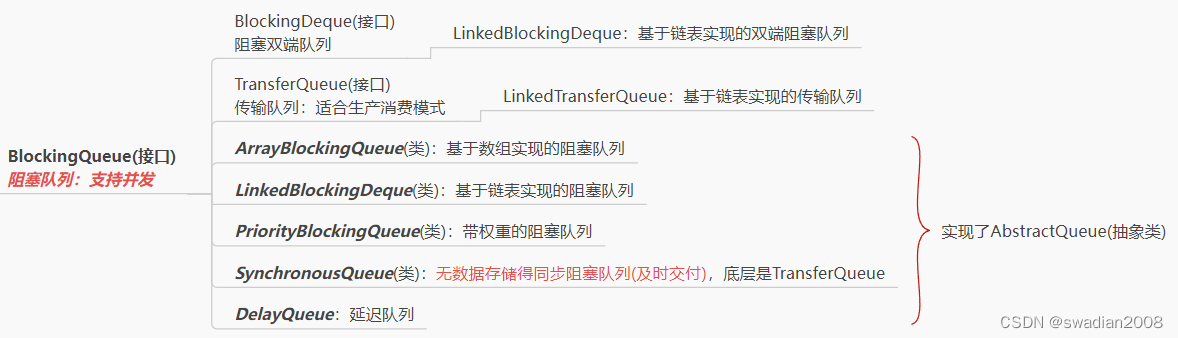
3.1 - Serial Thread Closure
The various blocking queues implemented in java.utilconcurrent contain sufficient internal synchronization mechanisms to safely post objects from producer threads to consumer threads.
For mutable objects, the producer-consumer design, together with blocking queues, facilitates serial thread confinement to transfer object ownership from producer to consumer. A thread-enclosing object can only be owned by a single thread, but ownership can be "transferred" by safely publishing the object . After ownership is transferred, only another thread can gain access to the object, and the thread that published the object will no longer have access to it. This safe publication ensures that the object state is visible to the new owner, and since the original owner will no longer access it, the object will be enclosed in the new thread. The new owner thread can make arbitrary modifications to the object because it has exclusive access.
Object pooling utilizes serial thread closures to "loan" objects to a requesting thread. As long as the object pool contains enough internal synchronization to safely publish objects in the pool, and as long as client code itself does not publish objects in the pool, or never use the objects after returning them to the pool, then it is safe to Pass ownership between threads. //Thread closure means that there is always only one thread operating on the closed object (serialization)
4. Blocking method and interrupt method
Thread provides the interrupt method, which is used to interrupt the thread or query whether the thread has been interrupted. Each thread has an attribute of type Boolean indicating the thread's interruption status, which is set when the thread is interrupted.
Interrupts are a cooperative mechanism . A thread cannot force other threads to stop their ongoing operations and perform other operations. When thread A interrupts B, A simply asks B to stop what it's doing at a point where it can pause—if thread B is willing to stop. Although no specific application-level semantics are defined for interrupts in the API or language specification, the most common use case for interrupts is to cancel an operation. The more responsive a method is to interrupt requests, the easier it is to cancel long-running operations in a timely manner.
When you call a method in your code that throws an InterruptedException, your own method becomes a blocking method and must handle interrupt responses. For library code, there are two basic choices: // strategy for handling interrupts
- Pass InterruptedException . Avoiding this exception is usually the most sensible strategy, just passing InterruptedException to the caller of the method. Ways to pass an IterruptedException include not catching the exception at all, or catching the exception and then throwing it again after performing some simple cleanup.
- Recovery interrupted . Sometimes an InterruptedException cannot be thrown, such as when the code is part of a Runnable. In these cases, the InterruptedException must be caught and the interrupted state restored by calling the interrupt method on the current thread, so that code higher up in the call stack will see An interrupt was raised.
5. Synchronization tools
All synchronization utility classes contain some specific structural properties: they encapsulate some state that will determine whether the thread executing the synchronization utility class continues or waits, in addition to providing some methods to operate on the state, and other method is used to efficiently wait for the synchronization tool class to enter the expected state.
Some synchronization tool classes provided in Java:

5.1 - Latch -> CountDownLatch
A lock is a synchronization utility class that delays a thread's progress until it reaches a terminated state. The lock acts like a door: until the lock reaches the end state, the door remains closed and no thread can pass through it. When the end state is reached, the door opens and allows all threads to pass through. When the lock reaches the end state, it will not change state, so the door will remain open forever . Latches can be used to ensure that certain activities do not proceed until other activities have completed. //Once the lock is opened, it will no longer be closed, -> CountDownLatch
CountDownLatch is a flexible latching implementation that can be used in each of the above situations to make one or more threads wait for a set of events to occur. The latched state includes a counter that is initialized to a positive number indicating the number of events to wait for. The countDown method decrements the counter, indicating that an event has occurred, and the await method waits for the counter to reach zero, indicating that all events requiring waiting have occurred. If the counter is non-zero, await blocks until the counter reaches zero, or the waiting thread is interrupted, or the wait times out. //Locking implementation principle, built-in event counter
5.2 - Using FutureTask as a lock
FutureTask can also be used as a latch. (FutureTask implements Future semantics, representing an abstract calculation that can generate results). The calculation represented by FutureTask is implemented through Callable, which is equivalent to a Runnable that can generate results, and can be in the following three states: waiting to run (Waiting to run), running (Running) and running completed (Completed). "Execution complete" means all possible ways in which a computation can end, including normal end, end due to cancellation, end due to exception, and so on. When the FutureTask enters the completed state, it will stop in this state forever. //FutureTask represents calculations that can generate results
The behavior of Future.get depends on the state of the task. If the task has completed, then get will return the result immediately, otherwise get will block until the task enters the completed state, and then return the result or throw an exception. FutureTask transfers the calculation result from the thread that executes the calculation to the thread that obtains the result, and the specification of FutureTask ensures that this transfer process can achieve the safe release of the result. //Separate calculation and result acquisition, the advantages of the process of obtaining results are similar to obtaining data from the blocking queue
In the following code, Preloader uses FutureTask to perform a high-cost calculation, and the calculation result will be used later. By starting calculations early, you can reduce the time required while waiting for results.
public class Preloader {
ProductInfo loadProductInfo() throws DataLoadException {
return null;
}
private final FutureTask<ProductInfo> future = new FutureTask<>(() -> loadProductInfo());
private final Thread thread = new Thread(future);
public void start() {
//执行任务
thread.start();
}
public ProductInfo get() throws DataLoadException, InterruptedException {
try {
//获取结果
return future.get();
} catch (ExecutionException e) {
Throwable cause = e.getCause();
if (cause instanceof DataLoadException) {
throw (DataLoadException) cause;
} else {
throw LaunderThrowable.launderThrowable(cause);
}
}
}
interface ProductInfo {
}
}
class DataLoadException extends Exception {
}5.3 - Semaphore -> Semaphore
Counting Semaphore is used to control the number of operations that simultaneously access a specific resource, or the number of simultaneous executions of a specified operation . Counting semaphores can also be used to implement some kind of resource pool, or to impose boundaries on containers.
Semaphore manages a set of virtual permits (permits), and the initial number of permits can be specified through the constructor. A license can be acquired first (as long as there are remaining licenses) when an operation is performed, and the license can be released after use. If there is no permit, then acquire will block until there is a permit (or until it is interrupted or the operation times out). The release method will return a license to the semaphore. A simplified form of computing a semaphore is a binary semaphore, a Semaphore with an initial value of 1. Binary semaphores can be used as mutexes, and have locking semantics that cannot be re-introduced: whoever owns the unique permission owns the mutex . //The semaphore is not reentrant, so the semaphore cannot be used to replace the reentrant lock
5.4 - Fence -> Barrier
We've seen latching be used to start a group of related operations, or to wait for a group of related operations to complete. Latches are single-use objects that cannot be reset once they enter the terminated state.
A barrier (Barrier) is similar to a lock, which blocks a group of threads until an event occurs. The key difference between a fence and a lock is that all threads must reach the fence location at the same time to continue execution. Latches are used to wait for events, while fences are used to wait for other threads. //The fence waits for the thread, locks and waits for the event (the event is one-time)
CyclicBarrier can make a certain number of participants repeatedly gather at the fence position. It is very useful in parallel selection algorithms: this algorithm usually splits a problem into a series of independent sub-problems. When the thread reaches the fence position, the await method will be called, and this method will block until all threads have reached the fence position. If all threads have reached the fence position, the fence will be opened, all threads will be released at this time, and the fence will be reset for the next use . // Fences are reusable
Another form of fence is Exchanger , which is a two-party (Two-Party) fence, and the parties exchange data at the fence position . Exchangers are useful when two parties perform asymmetric operations, such as when one thread writes to a buffer and another reads from it. These threads can use an Exchanger to coalesce and swap full buffers with empty ones. When two threads exchange objects through an Exchanger, the exchange safely releases the two objects to the other party. // used to handle data exchange
5.6 - Building an efficient and scalable result cache
Almost all server applications use some form of caching. Reusing previous calculation results can reduce latency and improve throughput, but requires more memory consumption . // use space for time
Like many "wheels of reinvention", caching is deceptively simple. However, simple caching can turn a performance bottleneck into a scalability bottleneck, even if the cache is used to improve single-threaded performance.
Below is an example code for the development of an efficient and scalable cache to improve a computationally expensive function. This example is very informative:
public class Memoizer <A, V> implements Computable<A, V> {
//使用ConcurrentHashMap缓存计算结果,提升性能
//使用ConcurrentMap<A, Future<V>>而不是ConcurrentMap<A, V>保存计算结果,避免重复计算
private final ConcurrentMap<A, Future<V>> cache = new ConcurrentHashMap<>();
private final Computable<A, V> c;
public Memoizer(Computable<A, V> c) {
this.c = c;
}
public V compute(final A arg) throws InterruptedException {
while (true) {
//1-计算时先获取,如果已经有线程计算,那么就阻塞等待获取前一个线程的计算结果
Future<V> f = cache.get(arg);
if (f == null) {
//2-封装计算任务,若没有则添加
Callable<V> eval = () -> c.compute(arg);
FutureTask<V> ft = new FutureTask<V>(eval);
f = cache.putIfAbsent(arg, ft); //原子性->若没有则添加
if (f == null) {
f = ft;
ft.run(); //3-执行任务
}
}
try {
//4-获取计算结果:可能会抛出异常,需对异常进行处理
return f.get();
} catch (CancellationException e) {
//5-如果执行被取消,需要移除计算任务,给其他线程计算机会
cache.remove(arg, f);
} catch (ExecutionException e) {
//6-执行异常直接抛出
throw LaunderThrowable.launderThrowable(e.getCause());
}
}
}
}
interface Computable <A, V> {
V compute(A arg) throws InterruptedException;
}
class ExpensiveFunction implements Computable<String, BigInteger> {
public BigInteger compute(String arg) {
return new BigInteger(arg);
}
}Note: Memoizer does not solve the problem of cache expiration , but it can be solved by using a subclass of FutureTask, specifying an expiration time for each result in the subclass, and periodically scanning the cache for expired elements. Likewise, it doesn't address cache cleaning, the removal of old computations to make room for new ones so that the cache doesn't consume too much memory. //Using cache, you should consider cache invalidation (storage time)
So far, the full text is over.