Cache can effectively accelerate the read and write speed of applications, and can also reduce the back-end load, which is very important for the development of daily applications. The following will introduce cache usage skills and design solutions, including the following content: benefit and cost analysis of cache, selection of cache update strategy and usage scenarios, cache granularity control method, optimization of penetration problem, optimization of bottomless pit problem, optimization of avalanche problem, hot key Rebuild optimization.
1. Benefit and cost analysis of caching
The left side of the figure below shows the architecture of the client directly calling the storage layer, and the right side shows a typical cache layer + storage layer architecture.
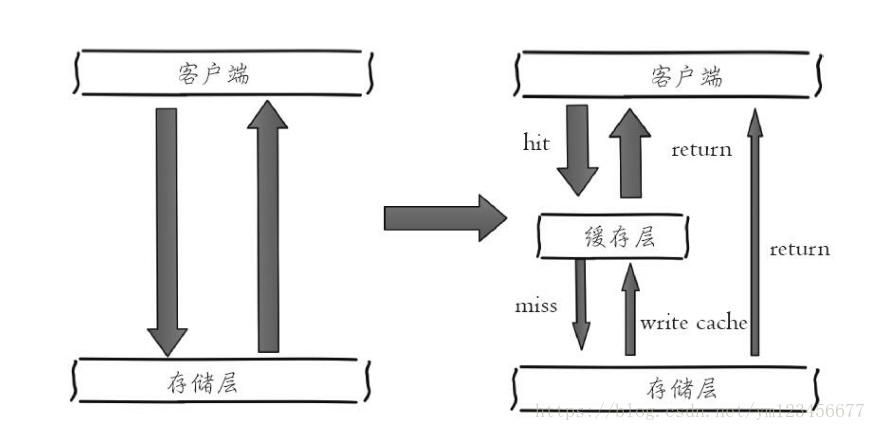
Let's analyze the benefits and costs brought about by adding the cache.
income:
① Accelerated reading and writing: Because the cache is usually full memory, and the storage layer usually has insufficient read and write performance (such as MySQL), the use of cache can effectively speed up reading and writing and optimize user experience.
② Reduce the back-end load: help the back-end reduce visits and complex calculations (such as very complex SQL statements), which greatly reduces the load on the back-end.
cost:
① Data inconsistency: The data in the cache layer and the storage layer have inconsistencies in a certain time window, and the time window is related to the update strategy.
② Code maintenance cost: After adding the cache, the logic of the cache layer and the storage layer needs to be processed at the same time, which increases the cost of developers to maintain the code.
③ Operation and maintenance costs: Take Redis Cluster as an example, after joining, the operation and maintenance costs will be virtually increased.
The usage scenarios of caching basically include the following two types:
① Complicated calculations with high cost: Taking MySQL as an example, some complex operations or calculations (such as a large number of table join operations, some group calculations), if no cache is added, not only cannot meet the high concurrency, but also bring huge problems to MySQL. burden.
② Accelerate request response: even if querying a single piece of back-end data is fast enough (for example select * from table where id = ?), cache can still be used. Taking Redis as an example, tens of thousands of reads and writes can be completed per second, and the batch operations provided can optimize the response of the entire IO chain time.
2. Cache update strategy
The data in the cache will be inconsistent with the real data in the data source for a period of time, and some strategies need to be used for updating. The following will introduce several main cache update strategies.
① LRU/LFU/FIFO algorithm elimination :
The culling algorithm is usually used for how to cull existing data when the cache usage exceeds the preset maximum value. For example, Redis uses the maxmemory-policy configuration as the data removal strategy after the maximum memory value.
② Overtime elimination :
By setting an expiration time for cached data, it is automatically deleted after the expiration time, such as the expire command provided by Redis. If the business can tolerate the inconsistency between the data in the cache layer and the data in the storage layer for a period of time, you can set an expiration time for it. After the data expires, get the data from the real data source, put it back in the cache and set the expiration time. For example, the description information of a video can tolerate data inconsistency within a few minutes, but when it comes to transactions, the consequences can be imagined.
③ Active update :
The application side has high requirements for data consistency, and needs to update the cached data immediately after the real data is updated. For example, a message system or other means may be used to notify cache updates.
Comparison of three common update strategies:

There are two suggestions:
① For low-consistency services, it is recommended to configure the maximum memory and eliminate strategies.
② High-consistency services can use timeout elimination and active update in combination, so that even if there is a problem with active update, dirty data can be deleted after the data expiration time.
3. Cache granularity control
The problem of cache granularity is a problem that is easily overlooked. If it is used improperly, it may cause a lot of waste of useless space, waste of network bandwidth, and poor code versatility. It is necessary to comprehensively combine data versatility, space occupation ratio, and code maintainability. Make a trade-off at three points.
Cache is more commonly used for selection. Redis is used for the cache layer, and MySQL is used for the storage layer.

4. Penetration optimization
Cache penetration refers to querying a data that does not exist at all, and neither the cache layer nor the storage layer will be hit. Usually, for the sake of fault tolerance, if the data cannot be found from the storage layer, it will not be written to the cache layer.
Usually, the total number of calls, the number of hits in the cache layer, and the number of hits in the storage layer can be counted separately in the program. If you find a large number of empty hits in the storage layer, there may be a cache penetration problem. There are two basic reasons for cache penetration. First, there is a problem with its own business code or data. Second, some malicious attacks, crawlers, etc. cause a large number of empty hits. Let's take a look at how to solve the cache penetration problem.
① Cache empty objects:
As shown in the figure below, when the storage layer misses in the second step, the empty object is still kept in the cache layer, and the data will be obtained from the cache when accessing the data later, thus protecting the back-end data source.

There are two problems with caching empty objects: first, empty values are cached, which means that more keys are stored in the cache layer, and more memory space is required (if it is an attack, the problem is more serious), a more effective method It is to set a short expiration time for this type of data and let it be automatically removed. Second, the data in the cache layer and the storage layer will be inconsistent for a period of time, which may have a certain impact on the business. For example, the expiration time is set to 5 minutes. If the data is added to the storage layer at this time, there will be inconsistencies between the cache layer and the storage layer data during this period. At this time, the message system or other methods can be used to clear the empty space in the cache layer. object.
② Bloom filter interception:
As shown in the figure below, before accessing the cache layer and storage layer, the existing key is saved in advance with a Bloom filter to do the first layer of interception. For example: a recommendation system has 400 million user IDs, every hour the algorithm engineer will calculate the recommended data based on the previous historical behavior of each user and put it in the storage layer, but the latest user has no historical behavior, and cache penetration will occur For this purpose, all users who recommend data can be made into Bloom filters. If the Bloom filter believes that the user id does not exist, the storage layer will not be accessed, which protects the storage layer to a certain extent.

Cache Null Object vs. Bloom Filter Scheme Comparison

Another: A brief description of the Bloom filter:
If you want to judge whether an element is in a collection, the general idea is to save all the elements in the collection, and then determine it by comparison. Linked list, tree, hash table (also called hash table, Hash table) and other data structures are all in this way. But as the number of elements in the collection increases, we need more and more storage space. At the same time, the retrieval speed is getting slower and slower.
Bloom Filter is a random data structure with high space efficiency. Bloom filter can be regarded as an extension of bit-map. Its principle is:
When an element is added to the set, K Hash functions are used to map this element into K points in a bit array (Bit array), and set them to 1. When retrieving, we only need to see if these points are all 1 to know (approximately) whether it is in the collection:
If any of these points has 0, the retrieved element must not be there; if they are all 1, the retrieved element is likely to be there.
5. Bottomless pit optimization
In order to meet business needs, a large number of new cache nodes may be added, but it is found that the performance has not improved but declined. To explain it in a simple sentence, more nodes do not mean higher performance. The so-called "bottomless pit" means that more investment does not necessarily mean more output. But distribution is unavoidable, because the amount of visits and data is increasing, and a node cannot resist it at all, so how to efficiently perform batch operations in the distributed cache is a difficult point.
Analysis of the bottomless pit problem:
① A batch operation of the client will involve multiple network operations, which means that the batch operation will take more time as the number of nodes increases.
② The increase in the number of network connections will also have a certain impact on the performance of nodes.
How to optimize batch operations under distributed conditions? Let's take a look at common IO optimization ideas:
-
Optimization of the command itself, such as optimizing SQL statements, etc.
-
Reduce the number of network communications.
-
Reduce access costs, for example, clients use persistent connections/connection pools, NIO, etc.
Here we assume that the commands and client connections are optimal, and focus on reducing the number of network operations. Below we will combine some features of Redis Cluster to illustrate the four distributed batch operation methods.
① Serial command : Since n keys are evenly distributed on each node of Redis Cluster, it cannot be obtained at one time using the mget command, so generally speaking, the easiest way to obtain the values of n keys is to execute them one by one n get commands, this kind of operation time complexity is high, its operation time = n times network time + n times command time, the number of network times is n. Obviously this solution is not optimal, but it is relatively simple to implement.
② Serial IO : Redis Cluster uses the CRC16 algorithm to calculate the hash value, and then takes the remainder of 16383 to calculate the slot value. At the same time, the Smart client will save the corresponding relationship between the slot and the node. With these two data, the The key belonging to the same node is archived to obtain the key sublist of each node, and then mget or Pipeline operation is performed on each node. Its operation time = node network time + n command time, the network time is the number of nodes The whole process is shown in the figure below. Obviously, this solution is much better than the first one, but if there are too many nodes, there are still certain performance problems.

③ Parallel IO : This solution is to change the last step in solution 2 to multi-threaded execution. Although the number of network times is still the number of nodes, but due to the use of multi-threaded network time O(1), this solution will increase the complexity of programming.

④ hash_tag implementation : the hash_tag function of Redis Cluster, which can force multiple keys to be assigned to a node, and its operation time = 1 network time + n command time.
Comparison of four batch operation solutions

6. Avalanche optimization
Cache avalanche: Since the cache layer carries a large number of requests, the storage layer is effectively protected. However, if the cache layer cannot provide services for some reason, all requests will reach the storage layer, and the number of calls to the storage layer will increase sharply, causing storage Layers will also cascade downtime.
To prevent and solve the cache avalanche problem, we can start from the following three aspects:
① Ensure high availability of cache layer services:
If the cache layer is designed to be highly available, even if individual nodes, individual machines, or even computer rooms are down, services can still be provided. For example, the Redis Sentinel and Redis Cluster introduced earlier have achieved high availability.
② Rely on isolation components to limit and downgrade backend traffic :
In actual projects, we need to isolate important resources (such as Redis, MySQL, HBase, external interfaces), so that each resource can run independently in its own thread pool, even if there is a problem with individual resources, other services No effect. However, how to manage the thread pool, such as how to close the resource pool, open the resource pool, and resource pool threshold management, is still quite complicated.
③ Drill in advance:
Before the project goes online, after the caching layer goes down, the application and back-end load conditions and possible problems will be rehearsed, and some pre-plan settings will be made on this basis.
7. Hotspot key reconstruction optimization
Developers use the strategy of "caching + expiration time" to speed up data reading and writing and ensure regular data updates. This mode can basically meet most of the needs. However, if two problems occur at the same time, it may cause fatal harm to the application:
-
The current key is a hot key (such as a popular entertainment news), and the amount of concurrency is very large.
-
Rebuilding the cache cannot be completed in a short time. It may be a complex calculation, such as complex SQL, multiple IOs, multiple dependencies, etc. At the moment when the cache becomes invalid, there are a large number of threads to rebuild the cache, which increases the load on the backend and may even cause the application to crash.
It is not very complicated to solve this problem, but it cannot bring more trouble to the system in order to solve this problem, so the following goals need to be formulated:
-
Reduce the number of cache rebuilds;
-
The data is as consistent as possible;
-
less potential danger.
① Mutex lock :
This method only allows one thread to rebuild the cache, and other threads wait for the thread that rebuilds the cache to finish executing, and then get data from the cache again. The whole process is shown in the figure.

The following code uses the setnx command of Redis to achieve the above functions:

1) Get data from Redis, if the value is not empty, return the value directly; otherwise, perform the following 2.1) and 2.2) steps.
2.1) If the result of set(nx and ex) is true, it means that no other thread rebuilds the cache at this time, then the current thread executes the cache construction logic.
2.2) If the result of set (nx and ex) is false, it means that other threads are already performing the work of building the cache at this time, then the current thread will rest for a specified time (for example, 50 milliseconds here, depending on the speed of building the cache), Re-execute the function until the data is obtained.
② never expires:
"Never expires" has two meanings:
-
From the perspective of the cache, there is indeed no expiration time set, so there will be no problems caused by the expiration of the hot key, that is, the "physical" does not expire.
-
From a functional perspective, a logical expiration time is set for each value. When the logical expiration time is found to be exceeded, a separate thread will be used to build the cache.
From the perspective of actual combat, this method effectively eliminates the problems caused by hot keys, but the only shortcoming is that data inconsistency may occur during cache reconstruction, which depends on whether the application side tolerates this inconsistency.

Two hot key solutions:

Well, this is the end of this article. Welcome friends to leave a message in the background, tell me what redis knowledge you have used in the project?