Table of contents
Five Hadoop development and version
1 What is big data?
Big data refers to the collection of data whose content cannot be captured, managed and processed by conventional software tools within a certain period of time.
Problems to be solved by big data technology: massive data storage and massive data computing
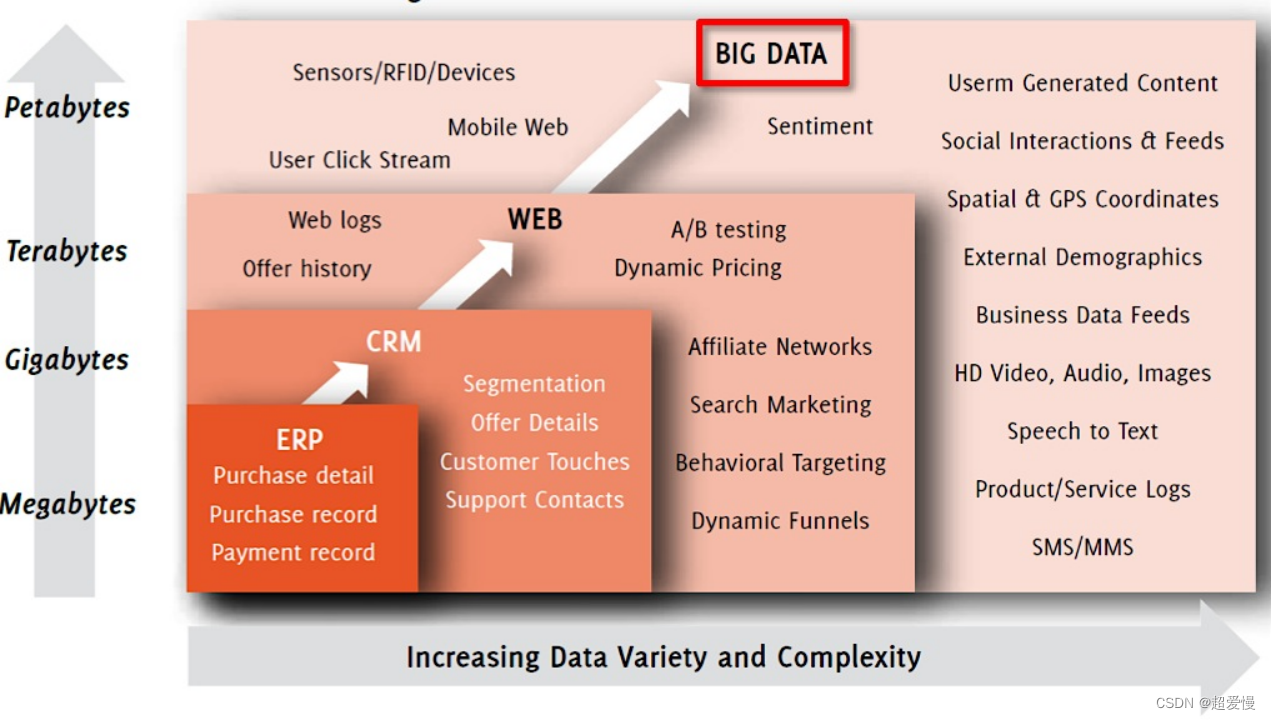
Two big data characteristics
- 4V characteristic
- Volume (large amount of data): 90% of the data was generated in the past two years
- Velocity (fast): the data growth rate is fast,
- High timeliness Variety (diversification): Data types and sources are diversified Structured data (such as tabular data), semi-structured data (such as json), unstructured data (such as log information)
- Value (low value density): Need to mine to obtain data value
- Inherent feature
- Timeliness
- immutability
Three distributed computing
Distributed computing divides larger data into smaller parts for processing.
| traditional distributed computing |
The New Distributed Computing - Hadoop |
|
| Calculation |
Copy data to compute nodes |
Computing in parallel on different data nodes |
| The amount of data that can be processed |
small amount of data |
Large amount of data |
| CPU performance limit |
Highly limited by CPU |
Limited by a single device |
| Improve computing power |
Improve the computing power of a single machine |
Scale low-cost server clusters |
4 What is Hadoop?
- Hadoop is an open source distributed system architecture that solves the problems of massive data storage and massive data computing
- Architecture of choice for handling massive amounts of data
- Complete big data computing tasks very quickly
- Has developed into a Hadoop ecosystem

Five Hadoop development and version
- Hadoop originated from the search engine Apache Nutch
- Founder: Doug Cutting
- 2004 - Initial version implemented
- 2008 - Became an Apache top-level project
- Hadoop distribution
- Community Edition: Apache Hadoop
- Cloudera distribution: CDH
- Hortonworks Distribution: HDP
Six Why use Hadoop
- high scalability
- Distribute task data among clusters, easily expand thousands of nodes
- high reliability
- Hadoop bottom layer maintains multiple data copies
- high fault tolerance
- The Hadoop framework can automatically reassign failed tasks
- low cost
- Hadoop architecture allows deployment on inexpensive machines
- Flexible, can store any type of data
- Open source, active community
七 Hadoop vs. RDBMS
Comparison between Hadoop and relational database
| RDBMS |
Hadoop |
|
| Format |
required when writing data |
required when reading data |
| speed |
read data fast |
write data fast |
| data governance |
standard structured |
arbitrary structured data |
| data processing |
limited processing power |
powerful processing capability |
| type of data |
structured data |
structured, semi-structured, unstructured |
| Application Scenario |
Interactive OLAP analysis ACID transaction processing Enterprise business system |
Handle unstructured data Massive Data Storage Computing |
Eight Hadoop ecosystem
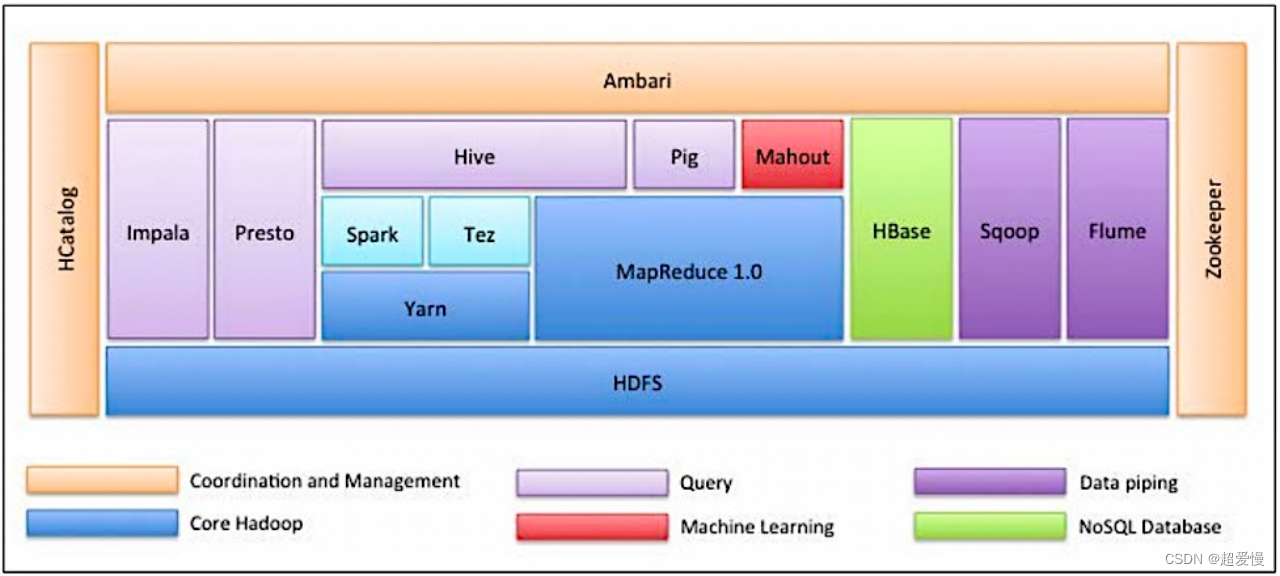
Nine Hadoop architecture
- HDFS(Hadoop Distributed File System)
- Distributed file system, solving distributed storage
- MapReduce
- Distributed Computing Framework
- YARN
- Distributed resource management system introduced in Hadoop 2.x
- Common
- Common utilities supporting all other modules

- Common utilities supporting all other modules