Hive is the essence: the HQL / SQL into MapReduce running on Hadoop, can be seen as
a SQL parsing engine
Hadoop Hive is based on a
data warehouse
tool, you can map the structure of the data file to a table, and provides SQL-like query.
Hive table
is HDFS file directory, a table corresponds to a directory name, if there is a partition, then the partition values corresponding subdirectory.
Hive Tutorial: hive wiki
Two, Hive architecture:
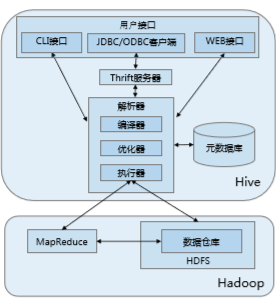
1. User Interface:
(1) CLI: Hive will also start a copy when you start
(2) JDBC client: encapsulates Thrift, java application, the server can connect to the hive another process running in the host and port specified by
(3) ODBC Client :: ODBC driver allows applications that support ODBC protocol connection to the Hive.
2.Thrift server: socket-based communication, cross-language support
3. parser (parse the statement to be executed):
(1) compiler: parsing the statement, parsing, compilation, develop work plans inquiry
(2) Optimizer: Evolution assembly rules: the construction of the column, under pressure predicate
(3) Actuator: will perform all Job order.
4. yuan database:
Hive data consists of two parts: the data files and metadata. Metadata is used to store basic information Hive repository, it is stored in a relational database, such as mysql, derby. Metadata includes: a column attribute information database, table names, and table partitions and their attributes, tables, table of contents and other data is located.
Three, Hive operating mechanism
1. A user
interface to a user
connected Hive, published Hive SQL;
2.Hive
parse the query
and
formulate a query plan
;
3.Hive turn the query
into MapReduce jobs
;
4.Hive
implementation of MapReduce in Hadoop
jobs.
Four, Hive advantages and disadvantages
Location data warehouse, data analysis and calculation of the direction of deflection
1. Advantages:
(1) suitable for handling large quantities of data
(2) take advantage of the cluster CPU computing resources, storage resources, parallel computing
(3) Class SQL, generated automatically MapReduce
(4). Scalability
2. Disadvantages:
(1) a finite HQL expression .Hive
Low (2) .Hive efficiency: Hive MR job generated automatically, usually not intelligent; HQL tuning difficult, coarse grain size; poor controllability.
For inefficiencies: SparkSQL the emergence of the Sql effectively improve the operational efficiency of the analysis on Hadoop.
Five, Hive applicable scene
1. The mass data storage and data analysis
2. Data Mining
3. Not suitable for complex algorithms and calculations, not suitable for real-time query
Sixth, the use of Hive
(A) connection Hive
Use HiveServer2, Beeline, Cli connection
(Ii) .Hive data type
|
classification
|
Types of
|
description
|
Examples
|
|
Primitive types
|
BOOLEAN
|
true/false
|
TRUE
|
|
|
TINYINT
|
1-byte signed integer -128 to 127
|
1Y
|
|
|
SMALLINT
|
2-byte signed integer -32768 to 32767
|
1S
|
|
|
INT
|
With 4-byte signed integer
|
1
|
|
|
BIGINT
|
8-byte signed integer
|
1L
|
|
|
FLOAT
|
4-byte single-precision floating-point number 1.0
|
|
|
|
DOUBLE
|
8-byte double-precision floating-point
|
1.0
|
|
|
DEICIMAL
|
Arbitrary-precision signed decimal
|
1.0
|
|
|
STRING
|
String, variable length
|
“a”,’b’
|
|
|
VARCHAR
|
Variable-length strings
|
“a”,’b’
|
|
|
CHAR
|
Fixed-length string
|
“a”,’b’
|
|
|
BINARY
|
Byte array
|
Can not be represented
|
|
|
TIMESTAMP
|
Time stamp, nanosecond precision
|
122327493795
|
|
|
DATE
|
date
|
‘2016-03-29’
|
|
Complex type
|
ARRAY
|
An ordered set of the same type
|
array(1,2)
|
|
|
MAP
|
key-value, key must be a primitive type, value can be any type
|
map(‘a’,1,’b’,2)
|
|
|
STRUCT
|
Field set, may be different types
|
struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0)
|
|
|
UNION
|
A value within a limited range of
|
create_union(1,’a’,63)
|
(C) .Hive operating table and
Data stored metadata composition +
Hive also has a database, the database can be created by CREATE DATABASE. The default library is the default library.
1 comprises two kinds of hosting and outer tables
(1) The data storage
Managed Table: directory data storage in the warehouse.
External table: Any directory data storage HDFS.
(2) The data deleted
Managed Table: Remove metadata and data.
External table: delete only
the metadata
.
(3) Create table
Hosting Table: CREATE TABLE table_name (attr1 STRING);
外部表:CREATE
EXTERNAL TABLE table_name(attr1 STRING)
LOCATION ‘path’;
A data partitioning approach can speed up queries. Table -> Partition -> barrel.
2. Partition (folder-level classification carried out)
(1) Partition Column Data are not actually stored, but the partition table nested directory under the directory.
Example:
data:

(2) The table may be partitioned (according to the above example is to partition the ID fan) in various dimensions.
(3) partitions can
narrow your search query to improve efficiency.
(4) when the partition is to create a table with the
PARTITION BY
clause defined.
(5)
loading data into a partition
specified partition value used statements LOAD, and to be displayed.
(6) Use
SHOW PARTITIONS
statement to see what the next Hive partition table.
(7) using the
SELECT
statement to view data in a specified partition, Hive only scan the specified partition data.
(8) Hive table is divided into two partitions, static partitions and dynamic partitions. Static and dynamic partitions partitioning
the time difference is to import data, partition name is entered manually, or data to determine the data partition (typically through naming conventions in accordance with the hive by a partition to help us hive
generated automatically partitions
).
For large bulk import data, it is clear that
the use of dynamic partitioning
is more simple and convenient

3. barrel (split classified within the file)
(1) barrel is attached on the table additional structure, can
improve query performance;
beneficial to make map-side-join operation.
(2) a more convenient and efficient to use sampling
(3) using
CLUSTER BY
columns, and the number of buckets to be divided is divided clause specifies the tub used.
create table bucketed_user(id int,name string) clustered by (id) into 4 buckets;
(4) the data bucket you can do to sort. Use
SORTED BY
clause.
create table bucketed_user(id int, name string) clustered by(id) sorted by (id asc) into 4 buckets;
(5)
does not recommend our own points barrels, it is recommended to let Hive divided barrel.
Is first divided barrel, go down to the bucket filled with data.
(6) minutes before the bucket is filled the data necessary to provide
hive.enforce.bucketing set to true
. (Create a barrel is inserted into the tub when queried data from other tables, dynamic process)
insert overwrite table bucket_users select * from users;
(7) practically corresponds to the tub MapReduce output partition file:
the same number of barrels and reduce tasks generated by a job.
Hive is also using the column values were hash ,
and then dividing by the number of barrels of ways to take more than this record of decision which should be stored in the bucket.
This is the principle HashPartitioner of MR is the same.
For sub-barrel Detailed refer to the following elements:
4. The storage format
Hive manage storage table from two dimensions: "Line Format" (row format) and "File Format" (file format).
(1) Line format:
Storing data in a row format. In accordance with the terms of the hive,
the definition defined by SerDe line format
, i.e., serialization and deserialization. I.e. the query data, SerDe file in
bytes of data in the form of
rows
deserialized
as an object in the form of internal operation Hive data rows used. Hive when inserting data into a table, the sequence of the tool will Hive internal data line representation into a sequence of bytes written to the output file in the form and go.
(2) File Formats
The simplest file format is a plain text file, but you can also use the column-oriented and line-oriented binary file format. Binary files can be sequential file, Avro, RCFile, ORC, parquet file.
The default storage format is
: delimited text, delimited text processing using LazySimpleSerDe default.
5. Data Import
Import data (1) Insert mode:
Multi-table insert, insert dynamic partitioning.
(2) Load mode introduced
(3)CATS方式:(CREATE TABLE … AS SELECT)
The basic idea is to check out the data, create a table
6. modify, and delete tables
Hive using the "read mode", so after creating the table,
it is very flexible support modifications to the table definition
. But generally we need to be vigilant, in many cases, be modified by the user to ensure that the data is in line with the new structure.
(1) Rename table
ALERT TABLE tablename
RENAME TO new_tablename
;
(2) modify the column definition (only cited the example of adding columns, you can go to see more examples of official documents)
ALERT TABLE tablename
ADD COLUMNS(colname
STRING);
(3) Delete table
DROP TABLE; (for hosting remove metadata table is table data +; external remove metadata table only)
(4) cutting off the table (the table structure stored, the data table empty)
delete (delete) and truncate (cut) will reclaim the space occupied by the data, and the associated index. Only the table owner can truncate table.
TRUNCATE TABLE tablename
[PARTITION partition_spec
];
7. Development:
the
solution Avro, RCFile, ORC, parquet storage structure, comparing similarities and differences.
The following blog describes the file format in the Hive, summarizes these
characteristics file formats
The following blog on Hive common storage formats were compared (mainly for
storage space and query efficiency
was tested)
