This shows the life cycle of abc and finds that there is conflict, that is, the overlapping part

The following image a and b have a conflict, that is, there is a conflict between the connection a and c, that is, the connection b and c do not have any disconnected
parts, and the overlapping parts actually show that multiple registers are required to store that at the same time How to find the minimum number of registers used in instructions with various conflicts, that is, the optimal number is undoubtedly to find the least number of colors used in the graph coloring problem. At this time, an NP-complete algorithm can only guarantee a 99% probability of
finding Optimal distribution but no way to guarantee 100%
Each box here is a basic block that stores a section of instructions. Live in means that the previous block is defined and the
live cost that will be used next is the local register allocation defined by the previous block and the current block that needs to be consumed next.
It refers to each The physical register allocation of basic blocks is independent of each other. When entering a new block, everything will be reassigned.
Global register allocation refers to linking these basic blocks together for physical memory allocation.
Here we introduce two concepts of code running efficiency, compile time and performance.
Local register allocation is allocated in a block, so the implementation is very simple and can save a lot of compilation time. Its advantage lies in compile time, but the process of running these codes after compilation is The process of executing 0 and 1 in the cpu is called performance, and the performance of local registers is a disadvantage
The global register allocation is just the opposite. It takes more time at the comile time, but the performance will be very good. Note that the global register allocation does not need to be like the local allocation. After the end of each block, all the def and use need to be stored and then in the new In the block, all the required def and use are loaded. The global allocation needs to be calculated through the conlict graph algorithm, so that the code can run smoothly as a whole at the cost of inserting the least store and load.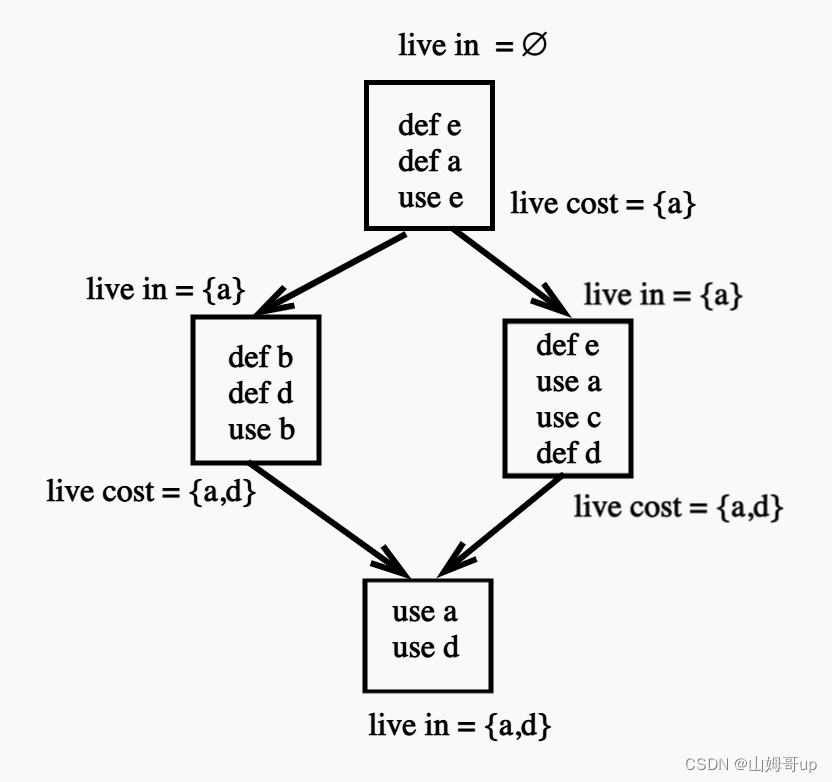

Here we can see that abd forms a conflict between a type and a ring structure, which is called a clique, so at least three colors are needed here, that is, three physical register allocations, so that there will be no spill, that is, the physical memory is not enough for allocation, and the memory space is temporarily occupied. store
When the physical registers are not enough to allocate, we need to insert store and load to temporarily import memory and take it out when needed. This also means that we need to insert store and load as little as possible to improve efficiency, so we usually choose to use less The address of the variable is imported into the memory because it needs to be loaded once if it is not used once.
It is conceivable that we should try our best to avoid the situation of accessing memory in the loop.
So in the figure above, if we only have two physical registers that can insert the least store and load, the variable b refers
to inserting a store b after def b in the leftmost block and inserting a load b before use b. You can 
see Here, importing b into memory consumes the least amount on the premise of reducing the number of physical registers, but this is not absolute because the execution frequency of each block is not shown here. The final consumption depends on the number of stores and loads multiplied by the block. frequency
Here we found that the execution frequency of each block is 0.5 because it is split and it is 10 because the block is in a loop body

cost for def : # of defs x cost of store x exec freq
cost for use : # of uses x cost of load x exec freq
spill cost for a = 1x1x1 + 1x2x0.5 + 1x2x10 = 22
spill cost for b = 1x1x0.5 + 1x2x0.5 = 1.5
spill cost for c = 1.5
spill cost for d = 1x1x0.5 + 1x1x0.5 + 1x2x10 = 21
spill cost for e = 1x1x1 + 1x2x1 = 3
Assuming that we only have two physical registers at this time, it means that we can only mark two colors in the conflict graph. The specific process is as follows:
First of all, the key to the problem lies in clique abd, so we need to spill according to the order of cost from small to large. The
essence of spill is to add store and load to temporarily import memory and reduce their live range so that the conflict is reduced.
Spill b first, then its live The range becomes as follows and 
it turns out that there is still a clique in the conflict graph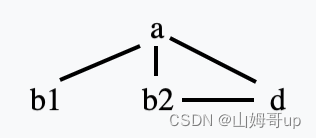
So continue to spill, so this time spill d
⚠️ Note: the spill of b is still retained.
After spill d, you can find that there is no clique in the conflict graph, indicating that it can be represented by two colors
We can define a as red, b1, b2, d1, and ce are all green. As for d2, it is completely isolated from other nodes, so red and green are fine. Even if the spill ends successfully, the virtual register is allocated to 2 physical registers with the smallest cost. in register
In this example, the problem is relatively simple and easy to solve, but in some complicated cases, there may be bugs in this problem. For example, if there are too few physical registers that can be allocated, the spill will continue and may eventually lead to BUG.
Maybe after the first spill b, you can find that you can solve the problem by just calling the position of def d and use b2 on the left. You don’t need to spill again, but note that the compiler cannot do register allocation and register scheduling at the same time, because this will cause the algorithm Too complicated. The current algorithm can only go one way to death and then change another way instead of smart seamless switching.