Table of contents
2 FastSAM operating environment construction
2.1 Conda environment construction
2.2 Operating environment installation
introduction
The visual basic large model SAM proposed by MetaAI that can "segment everything" provides a good segmentation effect and provides a new direction for exploring large visual models. Although the effect of sam is very good, because the backbone of SAM uses vit, the video memory is occupied more during inference, the inference speed is slower, and the requirements for hardware are higher, which has great limitations in project application.
Detailed explanation of SAM: https://blog.csdn.net/lsb2002/article/details/131421165
Some studies are trying to solve this problem, one of which is Expedit-SAM of the Tsinghua team, which accelerates the model, and the results of the paper can be accelerated by up to 1.5 times. The main idea is to use two operations that do not require parameters: token clustering layer and token reconstruction layer. The token clustering layer converts high-resolution features to low-resolution through clustering, and performs convolution and other operations with low-resolution during inference, which can speed up inference time; token reconstruction layer converts low-resolution features back to high-resolution Rate. The personal test does not seem to have improved significantly, but it has opened up the idea of sam reasoning acceleration.
1 Introduction to FastSAM
1.1 The birth of FastSAM
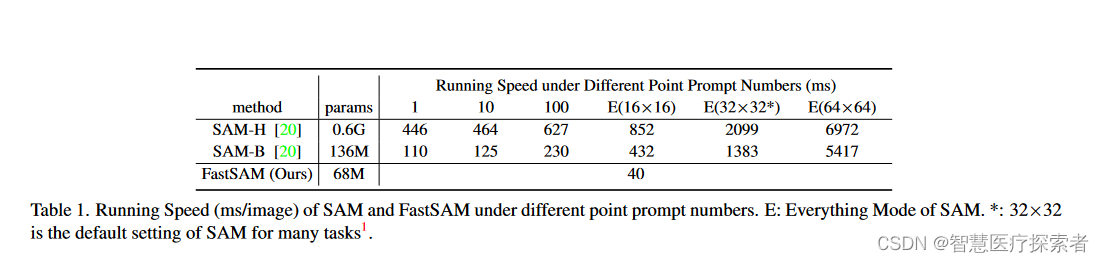
Recently released FastSAM (Fast Segment Anything), the results of the paper are increased by 50 times at the fastest, with fewer parameters and less memory usage, which is suitable for application deployment.
FastSAM is based on YOLOv8-seg, an object detector equipped with an instance segmentation branch that utilizes the YOLACT method. The authors also employ the extensive SA-1B dataset published by SAM. By directly training this CNN detector on only 2% (1/50) of the SA-1B dataset, it achieves performance comparable to SAM but with greatly reduced computation and resource requirements, enabling real-time applications. The authors also apply it to several downstream segmentation tasks to show its generalization performance. On MS COCO's object detection task, it achieves 63.7 on AR1000, which is 1.2 points higher than SAM with 32×32 point prompt input, and runs 50 times faster on NVIDIA RTX 3090.
Real-time SMAs are valuable for industrial applications. It can be applied in many scenarios. The proposed method not only provides a new and practical solution to a large number of vision tasks, but it is also very fast, tens or hundreds of times faster than current methods. It also opens up new uses for large model architectures for general vision tasks. The author believes that for professional tasks, professional models have a better trade-off between efficiency and accuracy. Then, in the sense of model compression, FastSAM's approach proves the feasibility of a path that can significantly reduce computational effort by introducing an artificial structure.


Paper address: https://arxiv.org/pdf/2306.12156.pdf
Code address: https://github.com/CASIA-IVA-Lab/FastSAM
web demo:https://huggingface.co/spaces/An-619/FastSAM
1.2 Model algorithm
Based on the instance segmentation of yolov8-seg, the instance segmentation branch is integrated during detection.
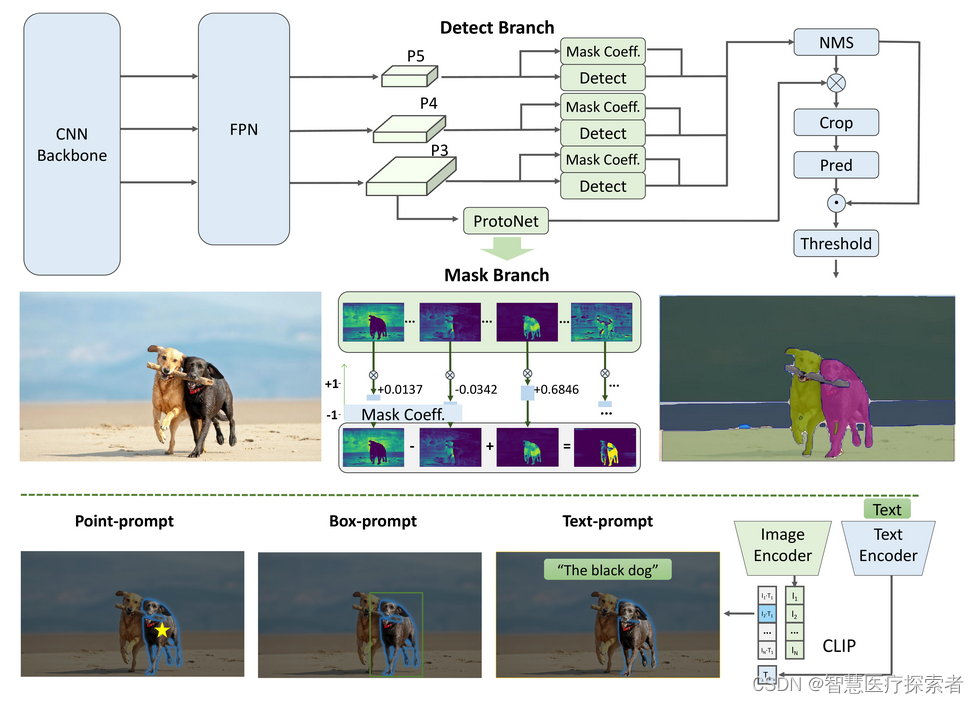
FastSAM is mainly divided into 2 steps: all instance segmentation (all instance Segmentation) and prompt-based mask output (Prompt-guided Selection).
All instance Segmentation
- Model: A model based on yolov8-seg.
- Instance segmentation: yolov8-seg implements instance segmentation, and the result includes detection and segmentation branches. The detection branch outputs box and category cls, the detection branch outputs k (default is 32) mask scores, and the detection and segmentation branches are parallel. Looking at the model of the reasoning code, this piece is actually the segment network of yolov8. For details, you can see the segment training code of yolov8.
Prompt-guided Selection
Use prompt to select interesting feature targets, similar to sam, support point/box/text.
- point prompt: The point prompt matches the point and the mask output by the instance segmentation. Like sam, use the foreground point/background point as a prompt. If a foreground point falls in multiple masks, it can be filtered by the background point. By using a set of foreground/background points, it is possible to select multiple masks within a region of interest and then merge these masks into a single mask for complete labeling of the object of interest. Furthermore, morphological operations are utilized to improve the performance of mask merging.
- Box prompt: Perform iou calculation with the box of the mask output by instance segmentation and the input box, and use the iou score to filter the mask.
- text prompt: Using the clip model, the mask with a higher score is extracted by using the direct similarity between image encoding and text encoding. Because of the introduction of the clip model, the running speed of the text prompt is relatively slow.
1.3 Experimental results
FastSAM uses the yolov8-x model; take 2% of the SA-1B dataset for supervised training; in order to detect larger instances, change the reg_max parameter of yolov8 from 16 to 26; the size of the input image is 1024. Compared with SAM's zero-shot on four levels of tasks: edge detection, target proposal, instance segmentation, and prompt input segmentation.
- Edge detection: Use the sobel operator to obtain the edge of the panoramic instance segmentation results of the model. FastSAM and SAM have similar performance, and both tend to predict more edges (edges that are not marked in the data set)
- Target Proposal: Compared SAM, ViTDet, OLN and FastSAM on coco, FastSAM and SAM are slightly worse, but it is zero-shot transfer, while OLN is pre-trained on voc
- Instance Segmentation: Using the bounding box (bbox) generated by ViTDet [23] as a hint to complete the instance segmentation task, FastSAM is slightly worse than SAM.
- Prompt input segmentation: similar to SAM performance, but the operating efficiency is somewhat low (this is mainly affected by the CLIP model)






2 FastSAM operating environment construction
2.1 Conda environment construction
For conda environment preparation, see: annoconda
2.2 Operating environment installation
conda create -n fastsam python=3.9
conda activate fastsam
git clone https://ghproxy.com/https://github.com/CASIA-IVA-Lab/FastSAM.git
cd FastSAM
pip install -r requirements.txt
pip install git+https://ghproxy.com/https://github.com/openai/CLIP.git2.3 Model download
Create a directory to save the model weights
mkdir weightsModel download address: model
After the model is downloaded, store it in the weights directory
(fastsam) [root@localhost FastSAM]# ll weights/
总用量 141548
-rw-r--r-- 1 root root 144943063 8月 21 16:28 FastSAM_X.pt3 FastSAM running
The original picture is as follows, this picture is processed by FastSAM

3.1 Command line operation
3.1.1 Everything mode
python Inference.py --model_path ./weights/FastSAM_X.pt --img_path ./images/dogs.jpg
3.1.2 Text prompt
python Inference.py --model_path ./weights/FastSAM_X.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
3.1.3 Box prompt (xywh)
python Inference.py --model_path ./weights/FastSAM_X.pt --img_path ./images/dogs.jpg --box_prompt "[[570,200,230,400]]"
3.1.4 Points prompt
python Inference.py --model_path ./weights/FastSAM_X.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
3.2 Call by code
vi test.pyfrom fastsam import FastSAM, FastSAMPrompt
model = FastSAM('./weights/FastSAM_X.pt')
IMAGE_PATH = './images/dogs.jpg'
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device=DEVICE, retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# everything prompt
ann = prompt_process.everything_prompt()
# bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bbox=[200, 200, 300, 300])
# text prompt
ann = prompt_process.text_prompt(text='a photo of a dog')
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)python test.py 
4 Summary
In the FastSAM model, the authors reconsider the choice of the segment of anything task and the corresponding model structure, and propose an alternative solution that runs 50 times faster than SAM-ViT-H (32×32). Experimental results show that FastSAM can solve multiple downstream tasks well. Nevertheless, there are still several weaknesses of FastSAM that can be improved, such as the scoring mechanism and instance mask generation paradigm. These issues are left for further study.