0. Introduction
Since MetaAI proposed a visual basic large model SAM that can "segment everything", it has provided a good segmentation effect and provided a new direction for exploring large visual models. Although the effect of SAM is very good, because the backbone of SAM uses ViT, it takes up a lot of video memory during inference, the inference speed is slow, and it has high hardware requirements, which has great limitations in project applications. FastSAM can achieve better real-time segmentation by replacing the detection head, but it is still unrealistic to replace SAM's "heavyweight" decoder with a "lightweight" so that it can be deployed on mobile applications. Therefore, " Faster Segment Anything: Towards Lightweight SAM for Mobile Applications proposes a "decoupled distillation" solution to distill SAM's ViT-H decoder, and the resulting lightweight encoder can be "seamlessly compatible" with SAM's decoder. The relevant code has also been open sourced on Github

Figure 1: Overview of the Segment Anything model
1. Main contributions
Considering that the default image encoder in SAM (Space-Aware Multi-Head Attention) is based on ViT-H (Vision Transformer-H) , a direct way to obtain MobileSAM is to follow the official process of Kirillov et al. [2023], using A smaller image encoder such as ViT-L (Vision Transformer-L) or smaller ViT-B (Vision Transformer-B) to retrain a new SAM.
- Continuing the SAM architecture: using a lightweight ViT decoder to generate latent features, and then using prompt words to guide the decoder to generate the desired Mask.
- This article proposes a "decoupled distillation" scheme to distill SAM's ViT-H decoder, and the resulting lightweight encoder can be "seamlessly compatible" with SAM's decoder.
- Our approach has the advantage of being simple, effective, and reproducible at low cost (less than a day on a single GPU). The resulting MobileSAM reduces encoder parameters by a factor of 100 and total parameters by a factor of 60. In terms of inference speed, MobileSAM only takes 10ms to process an image (8ms@Encoder, 2ms@Decoder), which is 4 times faster than FastSAM. This makes MobileSAM very suitable for mobile applications.
2. Mobile SAM background and project goals
2.1 SAM (Segment Anything Model, the “cut anything” model) background
First, let’s summarize the structure and working methods of SAM. SAM consists of a ViT (Vision Transformer) based image encoder and a hint-guided mask decoder . The image encoder takes an image as input and generates an embedding, which is then fed into the mask decoder. The mask decoder generates a mask based on a hint (such as a point or box) to cut out any object from the background. Additionally, SAM allows multiple masks to be generated for the same cue to resolve ambiguities, which provides valuable flexibility. With this in mind, we retain the pipeline of SAM, first employing a ViT-based encoder to generate image embeddings, and then employing a hint-guided decoder to generate the required masks. This process is best suited for "cut anything" and can be used for the downstream task "cut everything"
2.2 Project goals
The goal of this project is to generate a mobile-oriented SAM (MobileSAM) that achieves satisfactory performance in a lightweight manner and is faster than the original SAM . The hint-guided mask decoder in the original SAM has less than 4M parameters and is therefore considered lightweight . As shown in their public demonstration, SAM can run on resource-constrained devices as long as there are image embeddings processed by the encoder because the mask decoder is lightweight. However, the default image encoder in the original SAM is based on ViT-H and has more than 600M parameters , which is very heavy and makes the entire SAM process incompatible with mobile devices. Therefore, the key to getting a mobile-ready SAM is to replace the heavy image encoder with a lightweight image encoder, which also automatically retains all the functionality and features of the original SAM. Next, we detail our proposed approach to achieve this project goal.
3. Method proposed by Mobile SAM
3.1 Coupling refinement
A straightforward way to achieve the goals of our project is to retrain a new SAM with a smaller image encoder following the official process of Kirillov et al. [2023] . As described by Kirillov et al. [2023], training SAM using the ViT-H image encoder requires 68 hours of running on 256 A100 GPUs. Replacing ViT-H with ViT-L or ViT-B will reduce the required GPUs to 128, but it will still be a significant burden for many researchers in the community to replicate or improve their results. Following their approach, we can take a smaller image encoder and retrain a new SAM using the segmentation dataset (11-T) they provided . It is important to note that the masks provided in the dataset are given by pre-trained SAM (with ViT image encoder). Essentially, this retraining process is knowledge distillation (Hinton et al., 2015), which transfers knowledge from a ViT-H based SAM to a SAM with a smaller image encoder (see Figure 2 left).

Figure 2: Coupling knowledge extraction of SAM. The left image represents a fully coupled refinement, while the right image represents a semi-coupled refinement.
3.2 From semi-coupling to decoupling and refining
When performing KD (knowledge distillation) from the original SAM to a SAM with a smaller image encoder, the main difficulty lies in the coupling optimization of the image encoder and the combined decoder . Intuitively, the optimization of the image encoder depends on the quality of the image decoder and vice versa. When both modules in SAM are in a bad state, training them both to a good state is more challenging. Inspired by the divide-and-conquer algorithm (Zhang et al., 2022c), we propose to divide the KD task into two subtasks: image encoder refinement and mask decoder fine-tuning . Specifically, we first perform KD on the image encoder to transfer the knowledge from ViT-H to a smaller encoder. Since the mask decoder in the original SAM is already lightweight, we plan to retain its architecture. This brings the benefit that off-the-shelf combinatorial decoders can be directly used for fine-tuning rather than training them from scratch. To alleviate the optimization problem of coupled refinement, a straightforward approach is to optimize the image encoder using a copied and frozen mask decoder (see Figure 2 right). The freezing operation can help prevent the quality of the mask decoder from being deteriorated by a poor image encoder. We call this refinement semi-coupled because the optimization of the image encoder is still not fully decoupled from the mask decoder . In practice, we find that this optimization is still challenging because the selection of cues is random, which makes the mask decoder variable, thus increasing the difficulty of optimization. Therefore, we propose to refine the small image encoder directly from ViT-H in the original SAM without relying on the combined decoder, which is called decoupled refinement (see Figure 3). Another advantage of performing refinement on image embeddings is that we can adopt a simple MSE (Mean Squared Error) loss instead of using a focal loss for making mask predictions as in Kirillov et al. [2023] (Lin et al., 2017 ) and dice loss (Milletari et al., 2016).
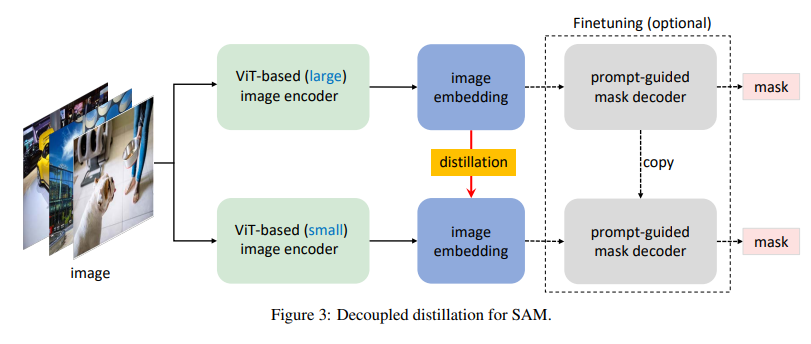
Figure 3: Decoupled knowledge extraction for SAM
3.3 About the necessity of fine-tuning the mask decoder
Different from semi-coupled distillation, the lightweight Encoder trained by decoupled distillation may have misalignment issues with the frozen Decoder. **Based on experience, we found that this phenomenon does not exist. This is because the latent features generated by the student Encoder are very close to the latent features generated by the original teacher Encoder, so there is no need for combined fine-tuning with the Decoder. Of course, further fine-tuning of the combination may help improve performance further.