Column introduction
Recently, I am building a judicial model, and now I am in the stage of data processing. Later, when discussing with my seniors, I said that attention should be used. After all, the judicial sector still has relatively high requirements for interpretation. Although I know something about it before, I always feel that I have not been able to get the essence of attention, and I have somewhat forgotten it, so starting this column from the beginning is equivalent to making a note for myself.
RNN
appear background
RNN (Recurrent Neural Network) cyclic neural network is a type of deep learning model that can handle inputs of different lengths. The output pressure mainly lies in NLP tasks, such as translation tasks. As far as Chinese-English translation is concerned, the English we get may be of any length, as short as a person's name, as long as the translation of long and difficult sentences in reading. At that time, many people truncated this kind of data, but obviously this would sacrifice the input content, which is not an ideal solution, so RNN appeared with hope.
model architecture
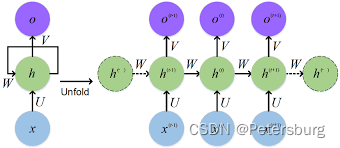
The situation can be easily explained through this picture. First, the parameters of the entire RNN code are in the h block (left side of the arrow), x is the input, and o is the output. Specifically, the green block on the left of the arrow can be just two matrices W and U. Let's now talk about how the entire data passes through this model.
We might as well assume that our input x = Where have you been recently?is a sentence with five words. First of all, we will of course use some methods to vectorize these words. We will not go into details here. By default, the five words of this sentence have been converted into five Fixed-length vectors
v 1 , v 2 , v 3 , v 4 , v 5 v_1, v_2, v_3, v_4, v_5v1,v2,v3,v4,v5
Each of them is a vector of English words corresponding to the position, such as v 1 v_1v1Correspondingly where, v 3 v_3v3The corresponding is you. So now our input has changed from five easy-to-read English words to five fixed-length vectors that are easy for computers to process. Below we describe how the RNN handles these five vectors.
model calculation
first step
Randomly initialize a hidden layer vector h 1 h_1h1, calculate the vector W ∗ h 1 W * h_1W∗h1, the sum U ∗ v 1 U * v_1U∗v1, get two vectors s 1 and e 1 s_1 and e_1s1and e1, here for simplicity, with s 1 + e 1 s_1 + e_1s1+e1as output o 1 o_1o1, with s 1 s_1s1as h 2 h_2h2. So far, we have completed the first step, input: random vector and the first word vector; output: the first output vector and the second hidden layer vector.
second step
Use h 2 , v 2 h_2, v_2 obtained aboveh2,v2Repeat the operation of the previous step, specifically, calculate s 2 = W ∗ h 2 , e 2 = U ∗ v 2 s_2 = W * h_2, e_2 = U * v_2s2=W∗h2,e2=U∗v2. Let the output o 2 = s 2 + e 2 o_2 = s_2 + e_2o2=s2+e2, the new hidden layer vector h 3 = s 2 h_3 = s_2h3=s2。
third step
利用 h 3 , v 3 h_3, v_3 h3,v3, continue to repeat, calculate s 3 = W ∗ h 3 , e 3 = U ∗ v 3 s_3 = W * h_3, e_3=U*v_3s3=W∗h3,e3=U∗v3。令o 3 = s 3 + e 3 , h 4 = s 3 o_3 = s_3 + e_3, h_4 = s_3o3=s3+e3,h4=s3。
the fourth step
Input: h 4 , v 4 h_4, v_4h4,v4. Output: o 4 , h 5 o_4, h_5o4,h5
the fifth step
Input: h 5 , v 5 h_5, v_5h5,v5. Output: o 5 , h 6 o_5, h_6o5,h6. Finish
So far we have obtained h and o. Generally, we will use the hidden layer h to represent the meaning of the sentence.
model evaluation
Let me briefly say here, first of all, the most obvious thing is that we have solved the problem of input of different lengths. By making each word perform repeated operations, we have achieved the initial goal; secondly, we have noticed that we have calculated each step Two input vectors are involved, one is the hidden layer vector h, which synthesizes the information of all the previous words. To some extent, h in each step represents the semantics of the previous words put together, and the other is the current new word x , can be understood as the modification of the overall sentence meaning by the new word.
On the whole, RNN not only solved the data length problem that plagued researchers at the time, but also provided an intuitive model design method. However, this kind of beggar’s version of RNN also has its own problems. For example, if the sentence is very long, the semantics of the first few words may be attenuated with continuous calculation, thus affecting the representation of the entire sentence.
Model promotion
In order to further solve the shortcomings of the beggar’s version of RNN, researchers have also successively proposed models such as LSTM and GRU. The essence of which is RNN. The difference lies in the calculation of each step. Through their own design, the information in front of the sentence can be partially retained. , thereby alleviating this "inattention" problem. But despite this, when the translation task encounters extremely long input, it is still possible to ignore the previous information, and the situation of translation before and after is reversed, so we need to further study better methods.