The microservice architecture has been widely deployed and applied, which improves the efficiency of software system development, reduces the cost of system update and maintenance, and improves the scalability of the system. However, the characteristics of microservices such as frequent changes and heterogeneous integration make microservices Faults occur frequently, and their faults propagate quickly and have a great impact. At the same time, the complex call dependencies or logical dependencies between microservices make it difficult to locate and diagnose faults in a timely and accurate manner. For the intelligent operation and maintenance of microservice architecture systems, a proposal is proposed. Challenge. Service dependency discovery technology identifies and infers call dependencies or logical dependencies between services from system runtime data, and builds a service dependency graph, which helps to timely and accurately discover, locate and diagnose faults when the system is running It is also conducive to intelligent operation and maintenance requirements such as resource scheduling and change management. First, the service dependency discovery problem in the microservice system is analyzed. Secondly, based on three types of runtime data such as monitoring data, system log data, and tracking This paper summarizes and analyzes the technical status of service dependency discovery technology; then, taking the fault root cause location, resource scheduling and change management based on service dependency graph as examples, discusses the related research of service dependency discovery technology applied to intelligent operation and maintenance. . Finally, how to accurately discover invocation dependencies and logic dependencies by service dependency discovery technology, how to use service dependency graph for change governance is discussed, and the future research direction is prospected.
Table of contents
2 Service Dependency Discovery
2.1 Service dependency discovery based on monitoring data
2.1.1 Service dependency discovery based on network communication packet data
2.1.2 Service dependency discovery based on resource usage data
2.1.3 Service dependency discovery based on statistical indicators
2.2 Service dependency discovery based on system logs
2.2.1 Service dependency discovery based on unified identification
2.2.2 Service dependency discovery based on co-occurrence probability
2.2.3 Service dependency discovery based on log frequency
2.3 Service dependency discovery based on tracking data
1 Problem description
● Service. In the microservice architecture software system, service refers to microservice. However, in the existing research work on service dependency discovery, there is no general and standard definition of service, so in different research work, The specific meaning of "service" in service dependency discovery may vary, but it can basically be divided into three categories: services represented by IP and Port, components or applications, and virtual machines. In the literature, services may be defined as <IP , Port>, or a triple defined as <IP, Port, Protocol>. In the literature, a service is a component/application, and a component is the smallest unit that can be independently deployed in a distributed software system. When using virtual machines as the research object of service dependency discovery, it is usually based on the assumption that only one service is deployed in each virtual machine, so the dependencies between virtual machines also represent the dependencies between services. In a pair of services In the dependency relationship, services can be divided into depending services and dependent services according to whether they are the relying party or the dependent party.
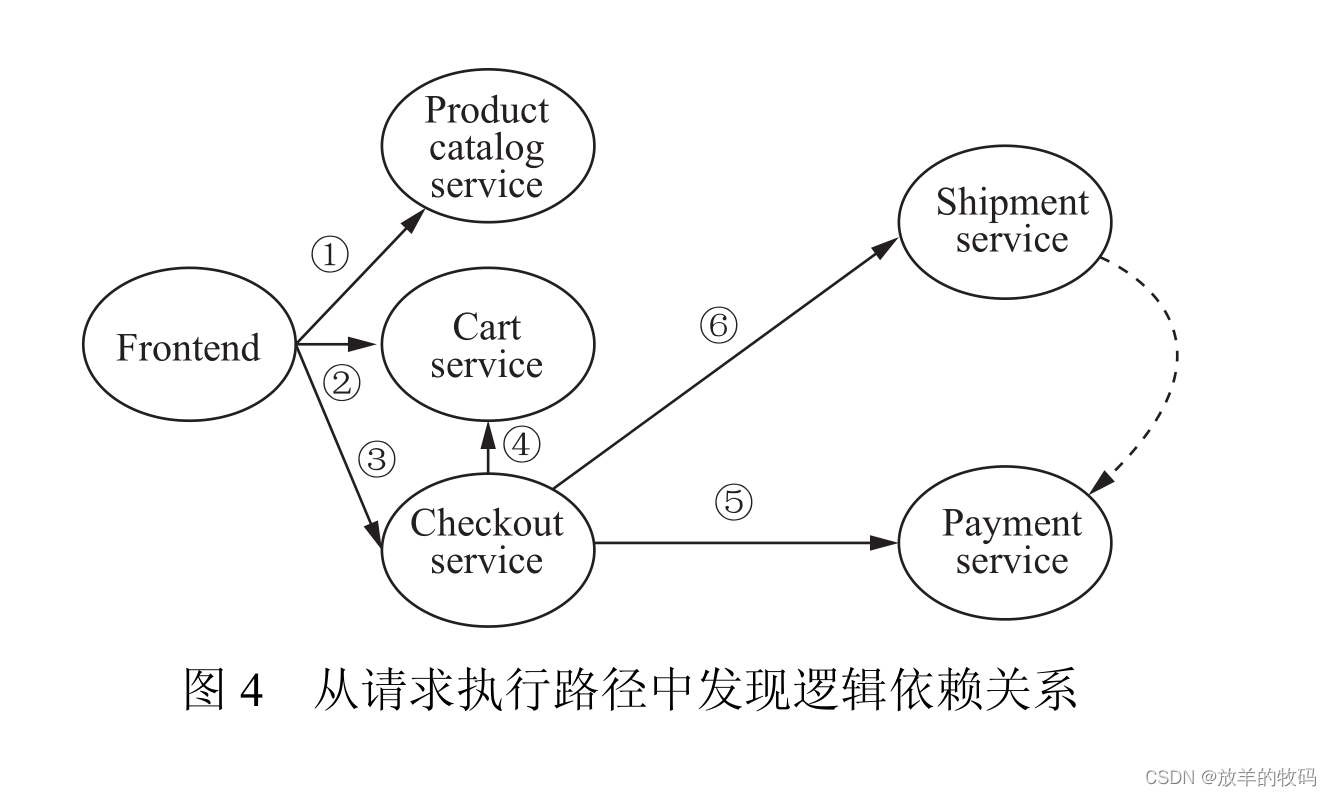
● Dependency. There are two types of dependencies in service dependency discovery, local-remote dependency and remote-remote dependency. The call relationship to other services, such as, is the most common dependency relationship in a microservice system. As shown in Figure 2, among the partial service dependencies found in a typical open source microservice system, CheckoutService will complete the checkout service, respectively Call CartService, PaymentService and ShipmentService to complete the order, payment and mailing functions, then CheckoutService depends on CartService, PaymentService and ShipmentService, and the dependency type is call dependency. Logical dependency means that one service completes the request response to the service with another service Completing the logical sequence relationship based on the premise of specifying please respond. In the service dependency relationship shown in Figure 2, ShipmentService needs to call PaymentService to complete the payment in order to complete the mailing service, so ShipmentService depends on PaymentService, and the dependency type is logical dependency. Dependency It is transitive, that is, depending on whether the dependency is derived from the transfer of other dependencies, the dependency can be divided into direct dependency and indirect dependency, and all indirect dependencies can be Obtained through direct dependency transfer, so in order to maintain the unity and simplicity of the service dependency graph, the dependency in the service dependency graph is regarded as a direct dependency. In addition, the service dependency discovery method usually assigns a value to the dependency based on different algorithms Measures the strength of dependencies or the confidence that dependencies exist.

2 Service Dependency Discovery
This paper reviews and analyzes service dependency discovery methods from the perspective of multi-source runtime data. System runtime data can be divided into three categories: monitoring data, system log data, and tracking data. Monitoring data is obtained by monitoring tools when the system is running. Data that characterizes system operation, including network communication packet (packet) data, resource usage data such as CPU/memory usage, business statistical indicators such as request response time and throughput, etc. System log data is provided by developers during development The added log print statement is used to record the semi-structured text data of the program running status and related variable information when the system is running. The trace data is generated by the distributed trace technology to describe the end-to-end of the request in the distributed software system. It shows the basic process of service dependency discovery. First, most service dependency discovery methods rely on the distribution change correlation of runtime data. In order to accelerate and intensify the distribution change, it is necessary to use fault or disturbance injection tools to microservices The system performs fault and disturbance injection. Then, collect monitoring, system log and trace data generated by the microservice system and use these data to discover microservice instances and microservice dependencies. Finally, build a service dependency graph based on service dependencies. Related research The work is based on three different types of runtime data, and proposes different methods for automatically constructing service dependency graphs.
2.1 Service dependency discovery based on monitoring data
2.1.1 Service dependency discovery based on network communication packet data
The service dependency discovery method based on network communication packet data takes advantage of the characteristics of specific interaction patterns and temporal and spatial correlations in the network communication messages of two microservices that have dependencies, by monitoring and analyzing network transport layer network packet data, using statistical methods From which dependencies between services are inferred.
Service dependency discovery based on network communication packet data first uses network packet monitoring tools to obtain all TCP packets and UDP packets on each node, and extracts a quintuple <SrcIP, SrcPort, DestIP, DestPort, Protocol> from each packet, where SrcIP , SrcPort, DestIP, DestPort, and Protocol represent the source IP, source port, destination IP, destination port and transport layer protocol of a packet respectively; then all intercepted packets within a certain time window are divided into different groups according to the five-tuple Flow (flow)/channel (channel)/session (session), SrcIP, SrcPort, DestIP, DestPort in the same flow are the same (or the source IP and source port are exchanged with the destination IP and destination port), and then it is characterized The 7-tuple of each flow <SrcIP, SrcPort, DestIP, DestPort, Protocol, startTime, endTime>, the startTime of the TCP flow is the timestamp of the first packet when the TCP connection is established for the 3-way handshake, and the endTime is the 4 times of closing the TCP connection The timestamp of the last packet during the handshake, the startTime of the UDP stream is the timestamp of the earliest quintuple pakcet, and the endTime is the timestamp of the last packet that does not appear in the quintuple packet within the specified time interval; After constructing all flows of each node in the system, different literatures use different methods to calculate whether two services represented by <IP1, Port1> and <IP2, Port2> have a dependency relationship and the probability of the dependency relationship being established.
2.1.2 Service dependency discovery based on resource usage data
The service dependency discovery technology based on resource usage data takes advantage of the similarity of resource usage in time series between two services that have dependencies, and uses different algorithms to calculate the similarity of different services in one-dimensional or multi-dimensional resource usage time series data. Degree, to infer the similarity between any two services is the strength of service dependence.
2.1.3 Service dependency discovery based on statistical indicators
The service dependency discovery method based on statistical indicators takes advantage of the fact that there are certain rules in the execution time difference (delay) and response time (response time) of two services that have dependencies. By analyzing the relationship between the execution and response time of the two services, the two Dependency between services. By intercepting all network packets of each service within a certain time window, delaying delivery for a certain time and monitoring the response time of all other services, according to whether the response time of the service is affected, and the response To judge the service dependence and strength of each service and the intercepted network packet by the degree of time impact. The correlation characteristics of the response time are different. By learning and using the response time of the dependent service to predict the response time of the dependent service The model can determine whether there is a dependency relationship between services, and the type of invocation dependency relationship that exists. The invocation relationship between services is divided into four categories: monotonous dependency (single dependency), composite dependency (composite dependency), parallel dependency (concurrent dependency) and shunt dependency (distrbuted ddependency), respectively represent the direct call relationship between two services, one service depends on the serial calls of multiple services, one service depends on the parallel calls of multiple services, and one service is in load balancing Calling multiple services in a scenario. For the four types of calling relationships, the author analyzes the relationship between the response time of the dependent service and the response time of the dependent service, and gives a prediction model. By using historical data to train the prediction model, a certain The response time of the service, by comparing which type of call relationship the predicted response time conforms to, the type of call dependency between services can be judged.
2.2 Service dependency discovery based on system logs
Microservice dependency discovery based on system log data uses different log data content or characteristics to discover or infer the call paths, logical dependencies, or associations of different microservices. According to the log content or characteristics that depend on, related research work can be divided into three types: Types: service dependency discovery based on unified identification, service dependency discovery based on co-occurrence probability, and service dependency discovery based on log frequency. Service dependency discovery based on unified identification assumes that there are identification information for different microservices in the log text (such as IP, etc. ) or requested identification information (such as Request ID, Block ID, etc.), by parsing the log text, extracting the identification information and then correlating different microservices by indicating the identification. Service dependency discovery based on co-occurrence probability assumes that if two microservices output some If there is a frequent co-occurrence relationship between logs, there is a service dependency between two microservices. Service dependency discovery based on log frequency counts the log frequency output by different microservices in a continuous time window, and takes log frequency as a core indicator. The distribution relationship between the indicators of the service, the causality and correlation relationship are mined, and finally the service dependency of the microservice is obtained.
2.2.1 Service dependency discovery based on unified identification
Service dependency discovery based on unified identification is the mainstream method of microservice dependency discovery based on system log data. This method assumes that the log text contains identification information that can characterize the request. If the identification information of the output logs of two microservices is the same and has a sequence relationship, it means that there is a call relationship between the two microservices during the request execution process, that is, there is a dependency relationship. Literature [36] uses the resource ID and request ID in the log to associate the logs of different microservices to construct the request execution path. In the HDFS log text Extract block ID and IP information, IP information is used to discover and identify each microservice, block ID is used to construct the request execution path, and discover microservice dependencies by associating continuous logs in the execution path. In many cases, the log text There is no special identifier that can identify a request execution path. To solve this problem, literature [37,38] assumes that the log text contains a variety of ID information, and connects the request execution path through a variety of ID information, and finally finds the dependency between microservices relationship. The main contribution of literature [39] is to find the most critical IDs from the system source code, and finally use these IDs to discover the dependencies of microservices. Specifically, firstly, through the static code analysis method, the absolutely accurate The transfer relationship between logs and the key identifiers in the logs. Then, these key identifiers are used to connect logs that span different components but belong to the same request, thus forming a complete cross-service request execution path with logs as nodes .
2.2.2 Service dependency discovery based on co-occurrence probability
The core idea of service dependency discovery based on co-occurrence probability is to judge the dependency between services that output logs based on the co-occurrence probability between individual logs. This method assumes that if there is a frequent sequence between two logs output by different microservices The co-occurrence relationship indicates that there may be a logical causality or correlation between two microservices, and based on this, the dependencies between services are discovered.
2.2.3 Service dependency discovery based on log frequency
The core idea of service dependency discovery based on log frequency is to convert logs into numerical indicators, and discover the dependencies between microservices by analyzing the distribution differences or trends of indicators. This method assumes that with load changes, different microservices output The number or frequency of logs also changes accordingly. If there is a correlation between the number or frequency of logs output by two microservices, it means that the two microservices may work together to process the same request, so there is some causality or Association relationship, and based on this, service dependencies are discovered.
2.3 Service dependency discovery based on tracking data
The service dependency discovery technology based on tracking data is supported by distributed tracking technology, and the request execution path of a service request in a distributed software system is generated through distributed tracking technology. There is a causal relationship between events in the request execution path. When the event When the granularity is method/service, the causal relationship between events is the invocation relationship between methods/services. Each request execution path contains part of the service dependency (causal relationship between events) information, and more Merging the service dependency information in the request execution path can directly and accurately obtain the call dependency information between the complete services of the distributed software system. When the event in the request execution path is a fine-grained system call or method call, from To build a service dependency graph in the request execution path, it is necessary to abstract the request execution path first, aggregate fine-grained events into services, and then judge the call dependencies between services according to the causal relationship between services.
Although only service invocation dependencies are directly reflected in the request execution path, the logical dependencies between services can also be obtained directly from the request execution path. For example, in the request execution path shown in Figure 4, the relationship between events Causality is the invocation dependency between services. The invocation sequence between services can be determined according to the timestamp of each service invocation. In order to discover the logical dependency between ShipmentService and PaymentService from the request execution path, it is first necessary to determine the In the execution path, whether the PaymentService is called before the ShipmentSerice; and then judge whether the failure to call the PaymentService will cause the failure of the ShipmentService call, and if the failure of the PaymentService will also cause the failure of the ShipmentService (or the probability of failure exceeds a certain threshold), then you can Judging that there is a logical dependency between ShipmentService and PaymentService.