0. Kafka common commands
Kafka is a distributed stream processing platform, which is highly scalable and fault-tolerant. Here are some commands commonly used in the latest version of Kafka:
-
Create a topic:
bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092 -
View the list of topics:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092 -
View topic details:
bin/kafka-topics.sh --describe --topic my-topic --bootstrap-server localhost:9092 -
Send a message to a topic:
bin/kafka-console-producer.sh --topic my-topic --bootstrap-server localhost:9092 -
Consume messages from a topic:
bin/kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server localhost:9092 -
View the offset of the consumer group (offset):
bin/kafka-consumer-groups.sh --describe --group my-group --bootstrap-server localhost:9092 -
Start the Kafka service:
bin/kafka-server-start.sh config/server.properties
1. Kafka optimal configuration
There are several nodes to write several nodes
vim /srv/app/kafka/config/server.properties
Remember to change broker.id
broker.id=0
listeners=PLAINTEXT://10.53.32.126:9092
advertised.listeners=PLAINTEXT://10.53.32.126:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/srv/data/kafka-data
num.partitions=3
num.recovery.threads.per.data.dir=3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
log.retention.hours=4
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connection.timeout.ms=6000
zookeeper.connect=10.53.32.126:2181,10.53.32.153:2181,10.53.32.134:2181
group.initial.rebalance.delay.ms=0
default.replication.factor=22 best configuration of zookeeper
There are several nodes to write several nodes
vim conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/srv/data/zookeeper-data
dataLogDir=/srv/data/zookeeper-datalog
clientPort=2181
autopurge.snapRetainCount=10
autopurge.purgeInterval=1
maxClientCnxns=1200
leaderServes=yes
minSessionTimeout=4000
maxSessionTimeout=40000
server.1=10.53.32.126:2888:3888
server.2=10.53.32.153:2888:3888
server.3=10.53.32.134:2888:3888
## Metrics Providers
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true1. If it is a zk single node
- Download and start zk http://bit.ly/2sDWSgJ. The following example of stand-alone service demonstrates how to install Zookeeper with basic configuration, the installation directory is /usr/local/zookeeper, and the data directory is /var/lib/zookeeper.
- start zk
-
# tar -zxf zookeeper-3.4.6.tar.gz # mv zookeeper-3.4.6 /usr/local/zookeeper # mkdir -p /var/lib/zookeeper # cat > /usr/local/zookeeper/conf/zoo.cfg << EOF tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 > EOF # export JAVA_HOME=/usr/java/jdk1.8.0_51 # /usr/local/zookeeper/bin/zkServer.sh start JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED - Confirm that port 2181 is open
telnet localhost 2181
ss -luntp|grep 21812. If it is a zk cluster
Generally choose 3 or 5 base nodes
Modify the group configuration file, add my.id file and configuration items
vim /usr/local/zookeeper/conf/zoo.cfg
myid=1
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=20
syncLimit=5
server.1=zoo1.example.com:2888:3888
server.2=zoo2.example.com:2888:3888
server.3=zoo3.example.com:2888:3888Among them, initLimit indicates the upper limit of the time used to establish an initial connection between the slave node and the master node, and syncLimit indicates the upper limit of the time allowed for the slave node and the master node to be out of sync. Both values are multiples of tickTime, so initLimit is 20*2000ms, which is 40s
The configuration also lists the addresses of all servers in the group. The server address follows server.X=hostname:peerPort:leaderPort
In addition to the public configuration file, each server must create a file called myid in the data Dir directory, which must contain the server ID, which must be consistent with the ID configured in the configuration file Sincerely. After completing these steps, it's time to start the servers and let them communicate with each other.
3. Install kafka
Download kafka Apache Kafka Download the latest version of Kafka https://downloads.apache.org/kafka/3.5.1/kafka_2.12-3.5.1.tgz
# tar -zxvf kafka_2.12-3.5.1.tgz
mv kafka_2.12-3.5.1 /usr/local/kafka
mkdir /tmp/kafka-logs
# export JAVA_HOME=/usr/java/jdk1.8.0_51
/usr/local/kafka/bin/kafka-server-start.sh -daemon
/usr/local/kafka/config/server.properties
Check whether kafka is started
Check whether kafka reports an error
ps -ef|grep kafka
Test whether the installation is normal, note that the new version does not need to rely on zook
The kafka version is too high. The 2.2+ = version does not need to rely on zookeeper to view/create topics . The new version uses --bootstrap-server to replace the old version --zookeeper-server .
create topic
老版本kafka
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
新版本kafka
[root@kafka bin]# /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server 172.18.207.104:9092 --create --replication-factor 1 --partitions 1 --topic test
Created topic test.
list topics
[root@kafka bin]# /usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 172.18.207.104:9092
test
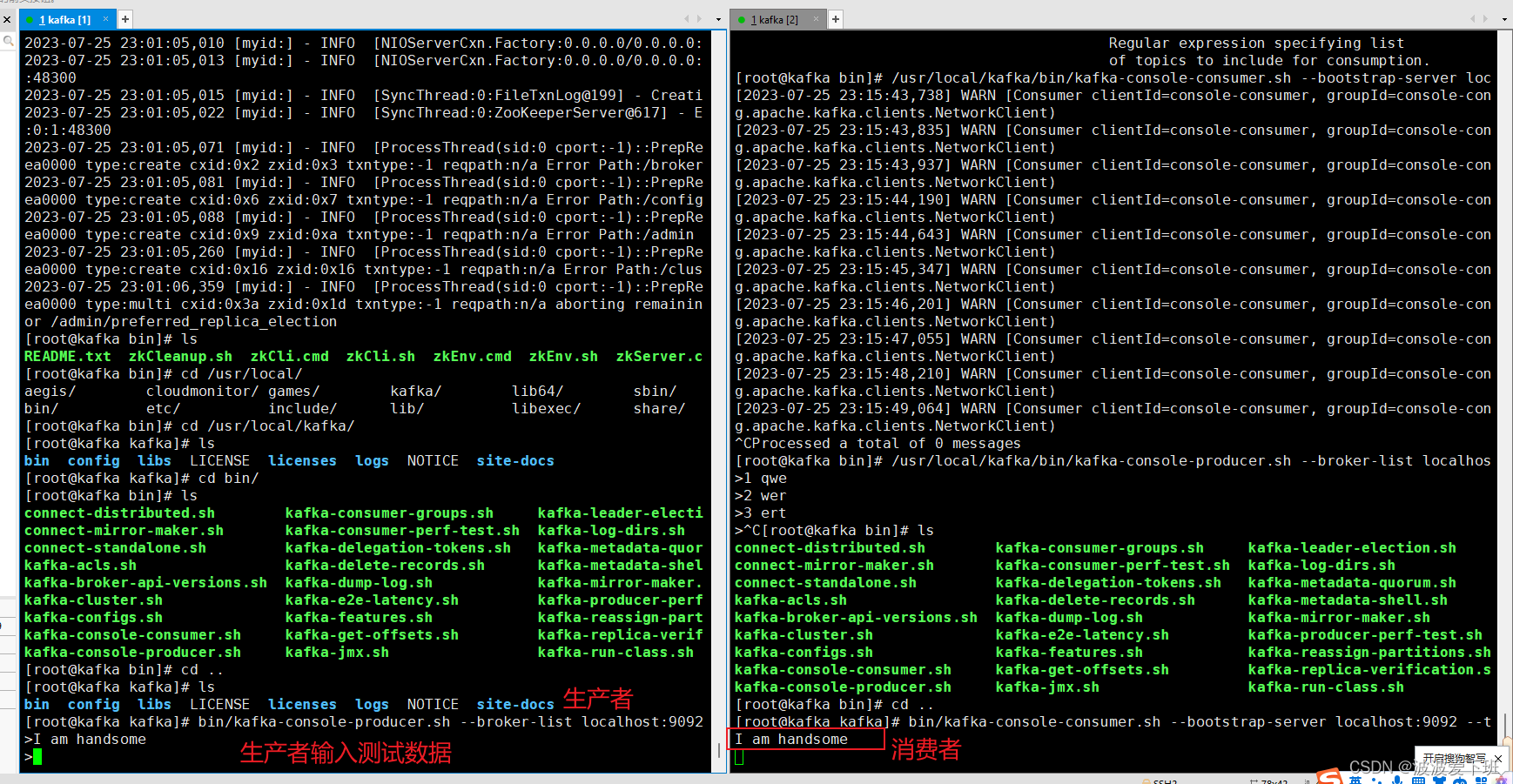
4 Start the consumer to receive messages
Order:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testExecute the above command red do not close the window, continue and execute the following production command
5 The producer sends a message
Order:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testEnter the message on the production side: I am handsome and press Enter, and you will find that consumption is implemented when you check it on the consumer side 4, provided that it is under the same topic
3. Kafka cluster configuration
3.1 broker configuration (take a good look)
3.1.1 broker.id
Each broker needs to have an identifier, represented by broker.id. Its default value is 0, and can also be set to any other integer. This value must be unique across the entire Kafka cluster . This value can be selected arbitrarily, and these IDs can be exchanged between server nodes for maintenance purposes. It is recommended to set them to integers related to the machine name, so that it is less troublesome to map ID numbers to machine names during maintenance. For example, if the machine name contains unique numbers (such as host1.example.com, host2.example.com), then it is good to use these numbers to set broker.id.
02. port If the configuration sample is used to start Kafka, it will listen on port 9092. Modify the port configuration parameter to set it to any other available port. It should be noted that if you use a port below 1024, you need to start Kafka with root privileges, but this is not recommended.
03 zookeeper.connect The Zookeeper address used to save broker metadata is specified through zookeeper.connect. localhost:2181 indicates that the Zookeeper is running on the local port 2181. This configuration parameter is a set of hostname:port/path lists separated by colons. The meaning of each part is as follows: hostname is the machine name or IP address of the Zookeeper server; port is the client connection port of Zookeeper; /path is optional The Zookeeper path, as the chroot environment of the Kafka cluster. If not specified, the root path is used by default. If the specified chroot path does not exist, the broker will create it at startup.
It is a best practice to use the chroot path in the Kafka cluster. The Zookeeper group can be shared with other applications, even if there are other Kafka clusters, there will be no conflicts. It is best to specify a set of Zookeeper servers in the configuration file, separating them with semicolons. Once a Zookeeper server goes down, the broker can connect to another node in the Zookeeper group.
04. log.dirs Kafka saves all messages on disk, and the directory for storing these log fragments is specified by log.dirs. It is a comma-separated set of local file system paths. If multiple paths are specified, the broker will save the log segments of the same partition to the same path according to the principle of "least use". Note that the broker adds partitions to the path with the least number of partitions, not the path with the least disk space.
05. num.recovery.threads.per.data.dir For the following three situations, Kafka will use a configurable thread pool to process log segments: The server starts normally and is used to open log segments for each partition ; Restart after a server crash, used to check and truncate log segments for each partition; Normal shutdown of the server, used to close log segments. By default, only one thread is used per log directory. Because these threads are only used when the server starts and shuts down, it is completely possible to set a large number of threads to achieve the purpose of parallel operation. Especially for servers with a large number of partitions, in the event of a crash, using parallel operations during recovery may save hours of time. When setting this parameter, it should be noted that the configured number corresponds to the single log directory specified by log.dirs. That is, if num.recovery.threads.per.data.dir is set to 8, and log.dir specifies 3 paths, then a total of 24 threads are required.
06. auto.create.topics.enable By default, Kafka will automatically create topics in the following situations: when a producer starts writing messages to the topic; when a consumer starts reading from the topic message; when any client sends a metadata request to the topic. Many times, these behaviors are not expected. Moreover, according to the Kafka protocol, if a topic is not created first, there is no way to know whether it already exists. If you are creating topics explicitly, either manually or through some other configuration system, you can set auto.create.topics.enable to false.
3.1.2 The default configuration of the theme (understand)
01. num.partitions
The num.partitions parameter specifies how many partitions the newly created topic will contain, and the default value of this parameter is 1. Note that we can increase the number of topic partitions, but not decrease the number of partitions. Therefore, if you want to have a topic with fewer partitions than the value specified by num.partitions, you need to manually create the topic
How to choose the number of partitions
Selecting the number of partitions for a topic is not optional. When selecting the number, the following factors need to be considered.
If you don't know this information, as a rule of thumb, you can get better results by limiting the size of the partition to 25GB.
02. log.retention.ms
Kafka usually uses time to determine how long data can be kept. By default, the log.retention.hours parameter is used to configure the time, and the default value is 168 hours, which is one week. In addition, there are two other parameters log.retention.minutes and log.retention.ms. The functions of these three parameters are the same, they all determine how long the message will be deleted, but it is recommended to use log.retention.ms. If more than one parameter is specified, Kafka will prefer the one with the smallest value
03. log.retention.bytes Another method is to judge whether the message expires by the number of retained message bytes. Its value is specified by the parameter log.retention.bytes and acts on each partition. That is, if there is a topic with 8 partitions, and log.retention.bytes is set to 1GB, then this topic can retain up to 8GB of data. Therefore, when the number of partitions of a topic increases, the data that can be retained by the entire topic also increases.
If both log.retention.bytes and log.retention.ms (or another time parameter) are specified, the message will be deleted as soon as either condition is met
04. The above settings of log.segment.bytes are applied to log segments, not to individual messages. As messages arrive at brokers, they are appended to the partition's current log segment. When the log segment size reaches the upper limit specified by log.segment.bytes (the default is 1GB), the current log segment will be closed and a new log segment will be opened. If a log segment is closed, it starts waiting for expiration. The smaller the value of this parameter, the more frequently new files will be closed and allocated, reducing the overall efficiency of disk writing.
The size of the log segment affects the use of timestamps to obtain offsets. When using the timestamp to obtain the log offset, Kafka will check the log segment (which has been closed) whose last modification time is greater than the specified timestamp in the partition, and the previous file of the log segment The last modified time is less than the specified timestamp. Kafka then returns the offset of the beginning of that log segment (that is, the filename). For operations that use timestamps to obtain offsets, the smaller the log segment, the more accurate the result.
3.2 How many brokers are needed
How many brokers a Kafka cluster needs depends on the following factors. First, how much disk space is required to hold the data, and how much space is available for a single broker. If the entire cluster needs to retain 10TB of data, and each broker can store 2TB, then at least 5 brokers are required. If data replication is enabled, at least twice as much space is required, but this depends on the configured replication factor (described in Chapter 6). In other words, if data replication is enabled, the cluster needs at least 10 brokers.
The second factor to consider is the capacity of the cluster to handle requests. This is usually related to the network interface's ability to handle client traffic, especially when there are multiple consumers or traffic fluctuates during data retention (such as traffic bursts during peak hours). If a single broker's network interface can reach 80% usage during peak hours, and there are two consumers, then the consumer cannot maintain the peak unless there are two brokers. This additional consumer is taken into account if the cluster has replication enabled. Performance problems caused by low disk throughput and insufficient system memory can also be solved by expanding multiple brokers.
3.2.1 broker configuration
To add a broker to the cluster, only two configuration parameters need to be modified. First, all brokers must be configured with the same zookeeper.connect , which specifies the Zookeeper group and path used to save metadata.
Second, each broker must set a unique value for the broker.id parameter .
3.2.2 Why not set vm.swappiness to zero?
Previously, it was recommended to try to set vm.swapiness to 0, which means "unless memory overflow occurs, do not perform memory swapping". It wasn't until the release of the Linux kernel 3.5-rc1 that the meaning of this value changed. This change was ported to other distributions, including Red Hat Enterprise kernel 2.6.32-303. After a change, 0 means "do not swap under any circumstances". So now it is recommended to set this value to 1.
3.2.3 Dirty pages
Dirty pages are flushed to disk, and we can benefit from adjusting how the kernel handles dirty pages. Kafka relies on I/O performance to provide fast response times for producers. This is why log fragments are generally kept on fast disks, either a single fast disk (such as SSD) or a disk subsystem with NVRAM cache (such as RAID). In this way, before the background flushing process writes dirty pages to disk, the number of dirty pages can be reduced. This can be achieved by setting vm.dirty_background_ratio to a value less than 10. This value refers to the percentage of system memory, and in most cases it is sufficient to set it to 5 . It should not be set to 0, as that would cause the kernel to flush pages frequently, reducing the kernel's ability to buffer disk writes to the underlying device.
The number of dirty pages before being flushed to disk by the kernel process can be increased by setting the vm.dirty_ratio parameter, which can be set to a value greater than 20 (this is also a percentage of system memory). This value can be set in a wide range, and 60~80 is a reasonable range. However, tuning this parameter brings some risks, including the number of unflushed disk operations and long I/O waits caused by synchronous flushes. If this parameter is set to a high value, it is recommended to enable Kafka's replication function to avoid data loss due to system crashes. In order to set proper values for these parameters, it is best to check the number of dirty pages while the Kafka cluster is running, both in live and simulated environments. You can view the current number of dirty pages in the /proc/vmstat file
cat /proc/vmstat | egrep "dirty|writeback"3.2.4 File system
Regardless of which file system is used to store log segments, it is best to properly set the noatime parameter of the mount point. File metadata includes three timestamps: creation time (ctime), last modification time (mtime), and last access time (atime). By default, atime is updated every time a file is read, which results in a lot of disk writes, and the atime attribute is not very useful unless some application wants to know that a file Has it been accessed since the last modification (use realtime in this case). Kafka does not use this property, so it can be disabled completely. Setting the noatime parameter for the mount point prevents atime from being updated, but does not affect ctime and mtime
3.2.5 Network, what should I do if I use Chaha
Network By default, the system kernel is not optimized for fast and large-traffic network transmission, so for applications, it is generally necessary to tune the network stack of the Linux system to achieve high-traffic support. In fact, tuning network configuration for Kafka is the same as tuning network configuration for most other web servers and network applications. First of all, you can adjust the memory size allocated to socket read and write buffers, which can significantly improve network transmission performance. The parameters corresponding to the socket read and write buffer are net.core.wmem_default and net.core.rmem_default, and the reasonable value is 131 072 (that is, 128KB). The parameters corresponding to the maximum value of the read and write buffer are net.core.wmem_max and net.core.rmem_max respectively, and the reasonable value is 2 097 152 (that is, 2MB). It should be noted that the maximum value does not mean that each socket must have such a large buffer space, it only means that this value will be reached when necessary. In addition to setting the socket, you also need to set the read and write buffer of the TCP socket, and their parameters are net.ipv4.tcp_wmem and net.ipv4.tcp_rmem. The values for these parameters consist of 3 integers separated by spaces, representing the minimum, default, and maximum values. The maximum value cannot be larger than the size specified by net.core.wmem_max and net.core.rmem_max. For example, "4096 65536 2048000" indicates that the minimum value is 4KB, the default value is 64KB, and the maximum value is 2MB. Depending on the actual traffic received by the Kafka server, you may need to set a higher maximum value to provide more buffer space for network connections. There are also some other useful network parameters. For example, setting net.ipv4.tcp_window_scaling to 1 and enabling TCP time window scaling can improve the efficiency of client data transmission, and the transmitted data can be buffered on the server side. Set net.ipv4.tcp_max_syn_backlog to a value larger than the default value of 1024 to accept more concurrent connections. put net.core.
It is still recommended to use the latest version of Kafka to allow consumers to submit offsets to the Kafka server and eliminate the dependence on Zookeeper.
Although multiple Kafka clusters can share a Zookeeper group, it is not recommended to share Zookeeper with other applications if possible. Kafka is sensitive to Zookeeper delays and timeouts, and a communication anomaly with the Zookeeper group may cause unpredictable behavior of the Kafka server. This makes it easy to take multiple brokers offline at the same time, and if they are disconnected from Zookeeper, it will also cause the partition to go offline
4. Kafka producer - write data to Kafka
In a credit card transaction processing system, there is a client application, which may be an online store, which is responsible for sending the transaction to Kafka whenever a payment occurs. Another application checks the transaction against a rules engine and decides whether to approve or deny it. Approval or rejection response messages are written back to Kafka and then sent to the online store that initiated the transaction. A third application reads transaction and audit state from Kafka, saves them to the database, and analysts can then analyze the results and perhaps improve the rules engine.
In this chapter, we will start with the design and components of Kafka producers, and learn how to use Kafka producers . We'll show how to create KafkaProducer and ProducerRecords objects, send records to Kafka, and handle errors returned from Kafka, then introduce important configuration options for controlling producer behavior, and finally dive into how to use different The partition method and serializer, and how to customize the serializer and partitioner.
In addition to the built-in client of the third-party client, Kafka also provides a binary connection protocol , that is, we can directly send the appropriate byte sequence to the Kafka network port to read messages from Kafka or Write messages to Kafka. There are also many Kafka clients implemented in other languages, such as C++, Python, Go, etc., all of which implement the Kafka connection protocol, making Kafka not limited to use in Java. These clients are not part of the Kafka project, but there is a list of all available clients on the Kafka project wiki.
4.1 Producer Overview
Use scenarios to differentiate needs
An application needs to write messages to Kafka in many cases: record user activities (for auditing and analysis), record metrics, save log messages, record information about smart home appliances, and communicate with other applications. communicate asynchronously, buffer data that is about to be written to the database, and so on. Diverse usage scenarios mean diverse requirements: Is every message important? Is it acceptable to lose a small fraction of messages? Is it acceptable to have occasional duplicate messages? Are there strict latency and throughput requirements? In the credit card transaction processing system mentioned above, message loss or message duplication is not allowed, and the acceptable delay is up to 500ms, which requires high throughput—we hope to process one million per second news.
Saving click information for websites is another use case. In this scenario, a small number of messages are allowed to be lost or repeated, and the delay can be higher, as long as the user experience is not affected. In other words, we don't mind that it takes a few seconds for the message to reach the Kafka server as long as the page loads immediately after the user clicks the link. Throughput depends on how frequently website users use the website. Different usage scenarios will have a direct impact on the usage and configuration of the producer API.
process
Send ProducerRecord object ------ serialization ------>> partitioner --->> launch to topic -->>
If the message is successfully written to Kafka, a RecordMetaData object is returned, which contains topic and partition information, as well as the offset of the record in the partition. If the write fails, an error is returned. The producer will try to resend the message after receiving an error, and if it still fails after several times, it will return an error message