Table of contents
0. Learning objectives of this section
1. Use RDD to calculate the total score and average score
3. Create a score file locally
4. Upload the score file to HDFS
1. Open the RDD project SparkRDDDemo
2. Create an object to calculate the average score of the total score
3. Run the program and view the results
2. Use RDD to count new users every day
2. Upload user files to HDFS specified location
1. Complete tasks in Spark Shell
2. Complete the task in IntelliJ IDEA
3. Use RDD to realize the group leaderboard
1. Create a score file locally
2. Upload the score file to the specified directory on HDFS
1. Complete tasks in Spark Shell
2. Complete the task in IntelliJ IDEA
0. Learning objectives of this section
- Use RDD to calculate total score and average score
- Use RDD to count new users every day
- Use RDD to realize group leaderboard
1. Use RDD to calculate the total score and average score
(1) Propose a task
- For the grade table, calculate the total score and average score of each student
| Name | language | math | English |
|---|---|---|---|
| Zhang Qinlin | 78 | 90 | 76 |
| Chen Yanwen | 95 | 88 | 98 |
| Lu Zhigang | 78 | 80 | 60 |
(2) Preparatory work
1. Start the HDFS service
- Excuting an order:
start-dfs.sh
2. Start the Spark service
- Enter the Spark
sbindirectory and execute the command:./start-all.sh
3. Create a score file locally
/homecreatescores.txtfile in
4. Upload the score file to HDFS
- Create a directory on HDFS
/scoresumavg/inputand upload the score file to this directory
(3) Implementation steps
1. Open the RDD projectSparkRDDDemo

2. Create an object to calculate the average score of the total score
net.huawei.rddCreateday07subpackages in the package, and then createCalculateSumAvgobjects in the subpackages
package net.huawei.rdd.day07
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object CalculateSumAvg {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateSumAvg") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/scoresumavg/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 遍历lines,填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores.append(Tuple2(fields(0), fields(1).toInt))
scores.append(Tuple2(fields(0), fields(2).toInt))
scores.append(Tuple2(fields(0), fields(3).toInt))
})
// 基于二元组成绩列表创建RDD
val rdd = sc.makeRDD(scores)
// 对rdd按键归约得到rdd1,计算总分
val rdd1 = rdd.reduceByKey(_ + _)
// 将rdd1映射成rdd2,计算总分与平均分
val rdd2 = rdd1.map(score => (score._1, score._2, (score._2 / 3.0).formatted("%.2f")))
// 在控制台输出rdd2的内容
rdd2.collect.foreach(println)
// 将rdd2内容保存到HDFS指定位置
rdd2.saveAsTextFile("hdfs://master:9000/scoresumavg/output")
}
}
3. Run the program and view the results
- Run the program
CalculateSumAvg, console results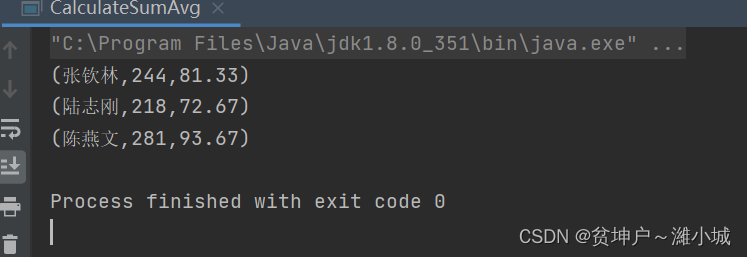
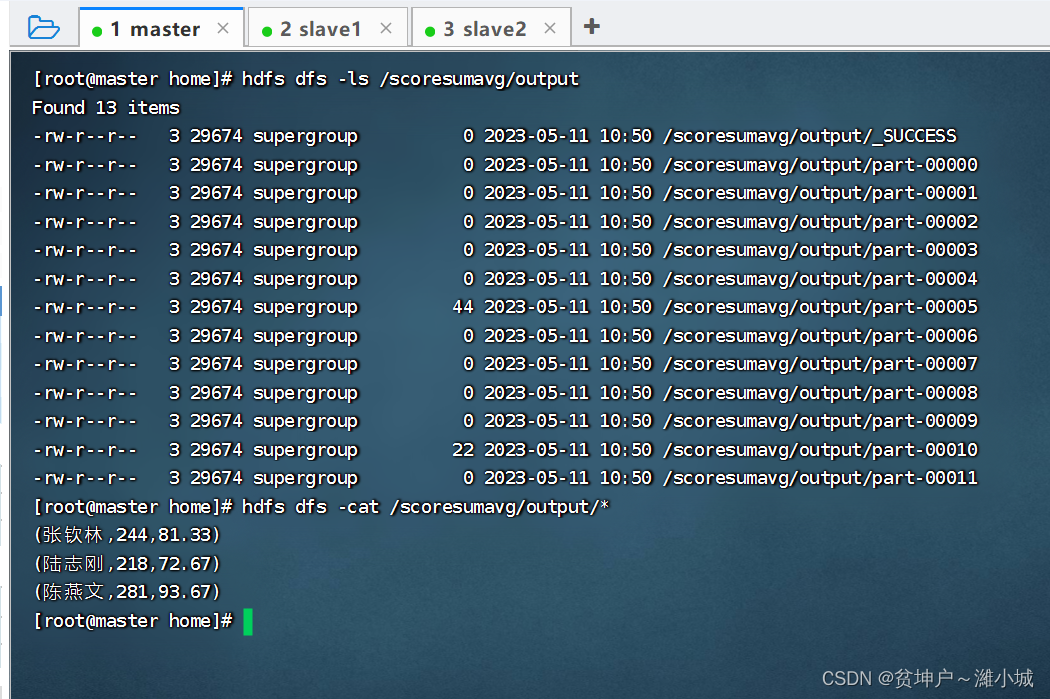
- View HDFS result files
2. Use RDD to count new users every day
(1) Propose a task
- It is known that the following user access history data is available. The first column is the date when the user visits the website, and the second column is the user name.
2023-05-01,mike
2023-05-01,alice
2023-05-01,brown
2023-05-02,mike
2023-05-02,alice
2023-05-02,green
2023-05-03,alice
2023-05-03,smith
2023-05-03,brian
| 2023-05-01 | mike | alice | brown |
| 2023-05-02 | mike | alice | green |
| 2023-05-03 | alice | smith | brian |
- Now it is necessary to count the number of new users added every day based on the above data, and expect the statistical results.
2023-05-01新增用户数:3
2023-05-02新增用户数:1
2023-05-03新增用户数:2
- That is, 3 new users were added on 2023-05-01 (respectively mike, alice, and brown), 1 new user (green) was added on 2023-05-02, and two new users were added on 2023-05-03 (respectively for smith and brian).
(2) Implementation ideas
- Using the inverted index method , if the user name is regarded as a keyword and the access date is regarded as a document ID, the mapping relationship between the user name and the access date is shown in the figure below.
| 2023-05-01 | 2023-05-02 | 2023-05-3 | |
|---|---|---|---|
| mike | √ | √ | |
| alice | √ | √ | √ |
| brown | √ | ||
| green | √ | ||
| smith | √ | ||
| brian | √ |
- If the same user corresponds to multiple visit dates, the smallest date is the registration date of the user, that is, the new date, and other dates are repeated visit dates and should not be counted. Therefore, each user should only calculate the minimum date that the user visits . As shown in the figure below, move the minimum date of each user's visit to the first column. The first column is valid data. Only the number of occurrences of each date in the first column is counted, which is the number of new users on the corresponding date.
| column one | column two | column three | |
|---|---|---|---|
| mike | 2023-05-01 | 2023-05-02 | |
| alice | 2023-05-01 | 2022-01-02 | 2022-01-03 |
| brown | 2023-05-01 | ||
| green | 2023-05-02 | ||
| smith | 2023-05-03 | ||
| brian | 2023-05-03 |
(3) Preparations
1. Create user files locally
/homecreateusers.txtfiles in directory
2. Upload user files to HDFS specified location
- Create
/newusers/inputa directory first, then upload user files to that directory
(4) Complete the task
1. Complete tasks in Spark Shell
- Excuting an order:
val rdd1 = sc.textFile("hdfs://master:9000/newusers/input/users.txt")
(2) Reversing, swapping the element order of the tuples in the RDD
val rdd2 = rdd1.map(
line => {
val fields = line.split(",")
(fields(1), fields(0))
}
)
rdd2.collect.foreach(println)
- Execute the above statement

(3) RDD key grouping after inversion
- Excuting an order:
val rdd3 = rdd2.groupByKey()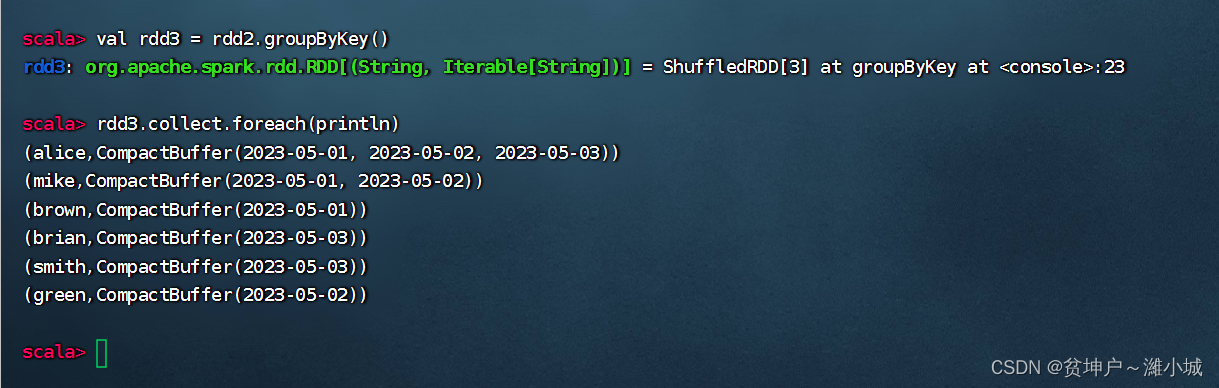
(4) Take the minimum value of the date set after grouping, and the count is 1
- Excuting an order:
val rdd4 = rdd3.map(line => (line._2.min, 1))
(5) Count the keys to get the number of new users per day
- Excuting an order:
val result = rdd4.countByKey()
- Excuting an order:
result.keys.foreach(key => println(key + "新增用户:" + result(key)))
(6) Let the output results be sorted by date in ascending order
- The mapping cannot be sorted directly, but the key set can only be converted into a list and sorted first, and then traverse the key set to output the map
- Execute the command:
val keys = result.keys.toList.sorted, so that the key set is sorted in ascending order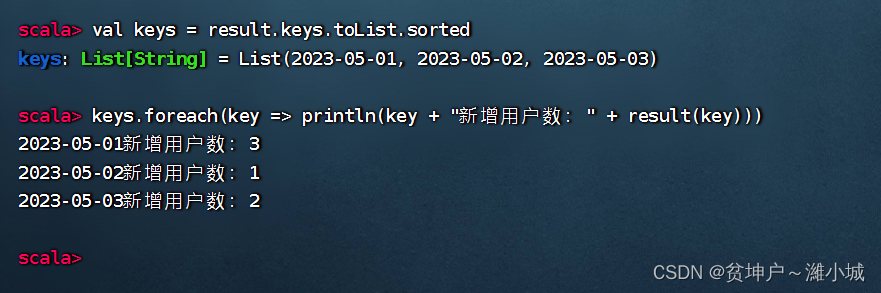
2. Complete the task in IntelliJ IDEA
SparkRDDDemo
(2) Create statistical new user objects
net.huawei.day07CreateCountNewUsersobjects in the package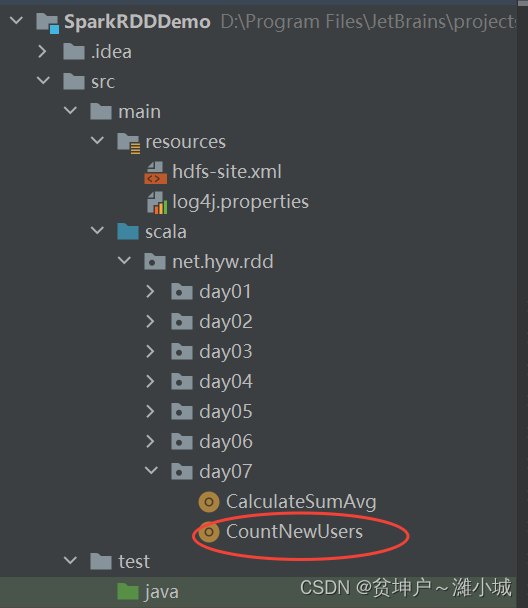
package net.huawei.rdd.day07
import org.apache.spark.{SparkConf, SparkContext}
object CountNewUsers {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CountNewUsers") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取文件,得到RDD
val rdd1 = sc.textFile("hdfs://master:9000/newusers/input/users.txt")
// 倒排,互换RDD中元组的元素顺序
val rdd2 = rdd1.map(
line => {
val fields = line.split(",")
(fields(1), fields(0))
}
)
// 倒排后的RDD按键分组
val rdd3 = rdd2.groupByKey()
// 取分组后的日期集合最小值,计数为1
val rdd4 = rdd3.map(line => (line._2.min, 1))
// 按键计数,得到每日新增用户数
val result = rdd4.countByKey()
// 让统计结果按日期升序
val keys = result.keys.toList.sorted
keys.foreach(key => println(key + "新增用户:" + result(key)))
// 停止Spark容器
sc.stop()
}
}
(3) Run the program and view the results
- Run the program
CountNewUsers, console results
3. Use RDD to realize the group leaderboard
(1) Propose a task
- Finding TopN by grouping is a common requirement in the field of big data. It is mainly grouped according to a certain column of the data, and then sort each grouped data according to the specified column, and finally get the top N rows of data in each group.
- There is a set of student grade data
张三丰 90
李孟达 85
张三丰 87
王晓云 93
李孟达 65
张三丰 76
王晓云 78
李孟达 60
张三丰 94
王晓云 97
李孟达 88
张三丰 80
王晓云 88
李孟达 82
王晓云 98
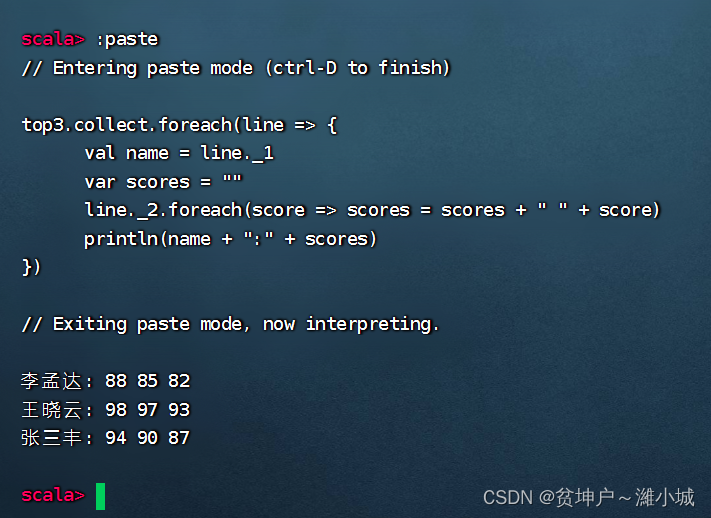
- The same student has multiple grades, now it is necessary to calculate the top 3 grades with the highest scores for each student, the expected output is as follows
张三丰:94 90 87
李孟达:88 85 82
王晓云:98 97 93
(2) Implementation ideas
groupByKey()The operator of Spark RDD can be used(key, value)to group the RDD of the form according to the key, and the values of the elements with the same key will be aggregated together to form, and the(key, value-list)first Nvalue-listelements can be arranged in descending order .
(3) Preparations
1. Create a score file locally
/homecreategrades.txtfiles in directory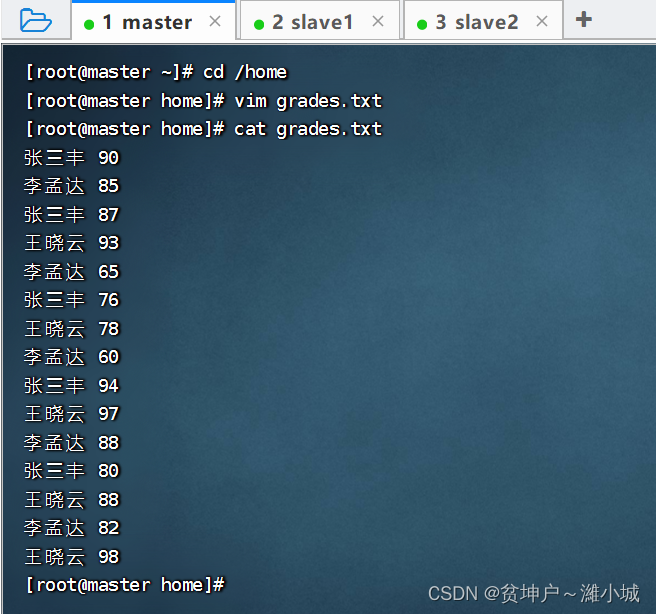
2. Upload the score file to the specified directory on HDFS
- The directory that will be
grades.txtuploaded to HDFS/topn/input
(4) Complete the task
1. Complete tasks in Spark Shell
(1) Read the score file to get RDD
- Excuting an order:
val lines = sc.textFile("hdfs://master:9000/topn/input/grades.txt")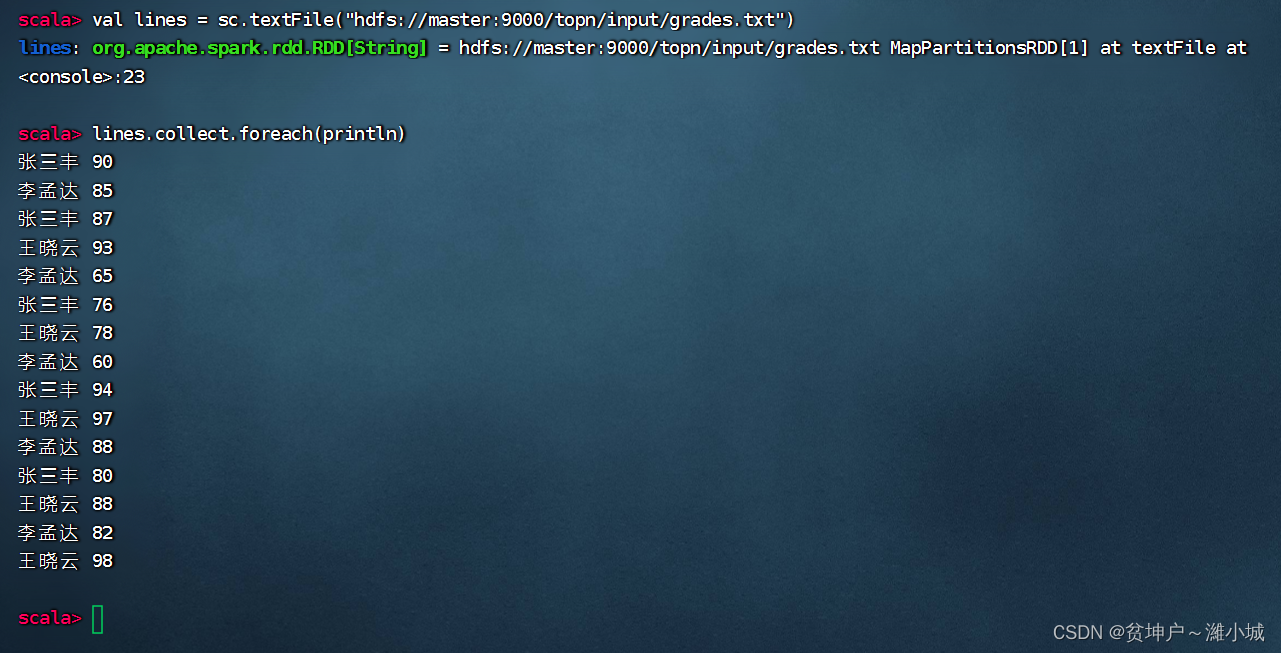
(2) Use the mapping operator to generate an RDD composed of two tuples
val grades = lines.map(line => {
val fields = line.split(" ")
(fields(0), fields(1))
})
grades.collect.foreach(println)
- Execute the above code

(3) Group by key to get a new RDD composed of two tuples
- Excuting an order:
val groupGrades = grades.groupByKey()
(4) Sort by value, take the first three
val top3 = groupGrades.map(item => {
val name = item._1
val top3 = item._2.toList.sortWith(_ > _).take(3)
(name, top3)
})
top3.collect.foreach(println)
- Execute the above code

(5) Output the result in the specified format
top3.collect.foreach(line => {
val name = line._1
var scores = ""
line._2.foreach(score => scores = scores + " " + score)
println(name + ":" + scores)
})
- Execute the above code
2. Complete the task in IntelliJ IDEA
SparkRDDDemo
(2) Create a group leaderboard singleton object
net.huawei.rdd.day07CreateGradeTopNa singleton object in the package
package net.huawei.rdd.day07
import org.apache.spark.{SparkConf, SparkContext}
object GradeTopN {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("GradeTopN") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 实现分组排行榜
val top3 = sc.textFile("hdfs://master:9000/topn/input/grades.txt")
.map(line => {
val fields = line.split(" ")
(fields(0), fields(1))
}) // 将每行成绩映射成二元组(name, grade)
.groupByKey() // 按键分组
.map(item => {
val name = item._1
val top3 = item._2.toList.sortWith(_ > _).take(3)
(name, top3)
}) // 值排序,取前三
// 输出分组排行榜结果
top3.collect.foreach(line => {
val name = line._1
var scores = ""
line._2.foreach(score => scores = scores + " " + score)
println(name + ":" + scores)
})
// 停止Spark容器,结束任务
sc.stop()
}
}
(3) Run the program and view the results
- View the output on the console
