- Shang Silicon Valley Big Data Technology-Tutorial-Learning Route-Notes Summary Sheet【Course Download】
- Video address: Shang Silicon Valley big data Spark tutorial from entry to master_哔哩哔哩_bilibili
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 01 [SparkCore (Overview, Quick Start, Operating Environment, Operating Architecture)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 02 [SparkCore (Core Programming, RDD-Core Attributes-Execution Principle-Basic Programming-Parallelism and Partitioning-Conversion Operator)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 03 [SparkCore (core programming, RDD-conversion operator-case operation)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 04 [SparkCore (core programming, RDD-action operator-serialization-dependency-persistence-partitioner-file reading and saving)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 05 [SparkCore (core programming, accumulator, broadcast variable)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 06 [SparkCore (case practice, e-commerce website)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 07 [Spark Kernel & Source Code (Environment Preparation, Communication Environment, Application Execution, Shuffle, Memory Management)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 08 [SparkSQL (Introduction, Features, Data Model, Core Programming, Case Practice, Summary)]
- Shang Silicon Valley Big Data Technology Spark Tutorial-Notes 09 [SparkStreaming (concept, introduction, DStream introduction, case practice, summary)]
Table of contents
03_SparkStreaming of Silicon Valley Big Data Technology.pdf
P185 [185. Shang Silicon Valley_SparkStreaming - Concept - Introduction] 09:25
Chapter 1 Spark Streaming Overview
P186 [186. Shang Silicon Valley_SparkStreaming - Concept - Principle & Features] 10:24
Chapter 2 Getting Started with Dstream
P187 [187. Shang Silicon Valley_SparkStreaming - Getting Started - WordCount - Implementation] 14:40
P188 [188. Shang Silicon Valley_SparkStreaming - Getting Started - WordCount - Analysis] 03:11
P189 [189. Shang Silicon Valley_SparkStreaming - DStream Creation - Queue] 02:39
P190 [190. Shang Silicon Valley_SparkStreaming - DStream Creation - Custom Data Collector] 07:36
P192 [192. Shang Silicon Valley_SparkStreaming - DStream creation - Kafka data source] 10:51
P193 [193. Shang Silicon Valley_SparkStreaming - DStream Conversion - State Operation] 16:09
P198 [198. Shang Silicon Valley_SparkStreaming - DStream Output] 04:43
P199【199.Silicon Valley_SparkStreaming - Shut Down Gracefully】15:45
P200 [200.Silicon Valley_SparkStreaming - Graceful Shutdown - Restoring Data] 03:30
Chapter 7 SparkStreaming Case Practice
P202 [202. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 1 - Analysis] 10:20
P210 [210.Silicon Valley_SparkStreaming - Summary - Courseware Review] 08:12
03_SparkStreaming of Silicon Valley Big Data Technology.pdf
P185 [185. Shang Silicon Valley_SparkStreaming - Concept - Introduction] 09:25
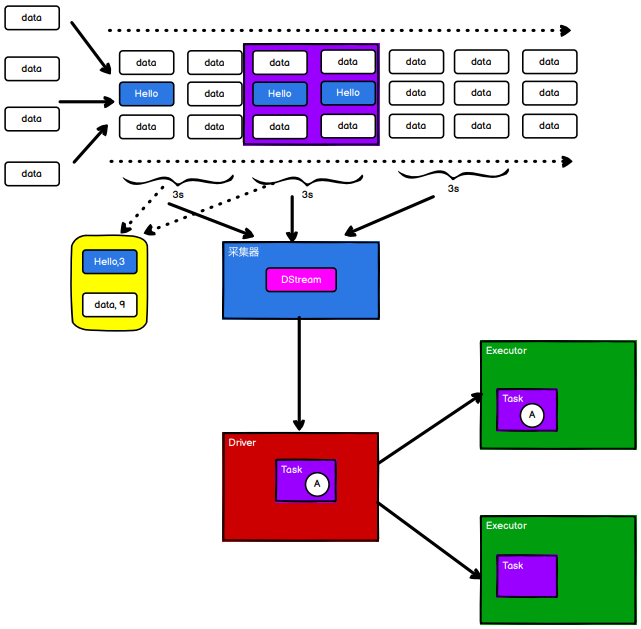
//数据处理的方式角度
流式(streaming)
数据处理批量(batch)数据处理
//数据处理延迟的长短
实时数据处理:毫秒级别
离线数据处理:小时or天 级别
Sparkstreaming:准实时(秒,分钟),微批次(时间)的数据处理框架。Chapter 1 Spark Streaming Overview
P186 [186. Shang Silicon Valley_SparkStreaming - Concept - Principle & Features] 10:24
Chapter 1 Spark Streaming Overview
1.1 What is Spark Streaming
Spark Streaming is used for streaming data processing. Spark Streaming supports many data input sources, such as Kafka, Flume, Twitter, ZeroMQ and simple TCP sockets, etc. After data input, highly abstract primitives of Spark, such as: map, reduce, join, window, etc. can be used for calculation, and the results can also be stored in many places, such as HDFS, database, etc.
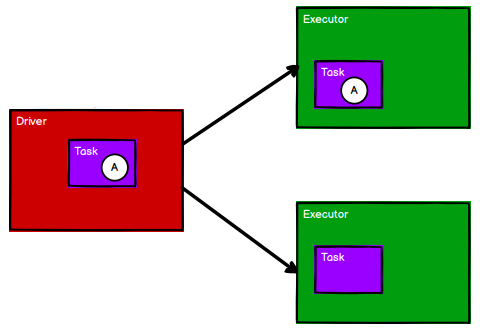
Chapter 2 Getting Started with Dstream
P187 [187. Shang Silicon Valley_SparkStreaming - Getting Started - WordCount - Implementation] 14:40
Chapter 2 Getting Started with Dstream
2.1 WordCount case practice
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming01_WordCount {
def main(args: Array[String]): Unit = {
// TODO 创建环境对象
// StreamingContext创建时,需要传递两个参数
// 第一个参数表示环境配置
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
// 第二个参数表示批量处理的周期(采集周期)
val ssc = new StreamingContext(sparkConf, Seconds(3))
// TODO 逻辑处理
// 获取端口数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_, 1))
val wordToCount: DStream[(String, Int)] = wordToOne.reduceByKey(_ + _)
wordToCount.print()
// TODO 关闭环境
// 由于SparkStreaming采集器是长期执行的任务,所以不能直接关闭。
// 如果main方法执行完毕,应用程序也会自动结束,所以不能让main执行完毕。
//ssc.stop()
// 1. 启动采集器
ssc.start()
// 2. 等待采集器的关闭
ssc.awaitTermination()
}
}P188 [188. Shang Silicon Valley_SparkStreaming - Getting Started - WordCount - Analysis] 03:11
2.2 WordCount Analysis
Discretized Stream is the basic abstraction of Spark Streaming, which represents continuous data flow and the resulting data flow after various Spark primitive operations. Internally, DStream is represented by a series of continuous RDDs. Each RDD contains data for a time interval.
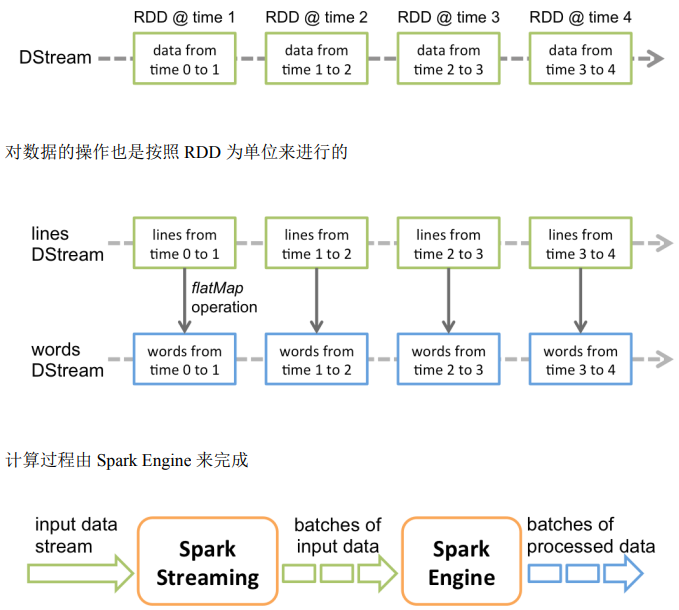
Chapter 3 DStream Creation
P189 [189. Shang Silicon Valley_SparkStreaming - DStream Creation - Queue] 02:39
Chapter 3 DStream Creation
3.1 RDD queue
3.1.1 Usage and instructions
During the test, you can create a DStream by using ssc.queueStream(queueOfRDDs), and each RDD pushed to this queue will be processed as a DStream.
3.1.2 Case Practice
➢ Requirements: Create several RDDs in a loop, and put the RDDs into the queue. Create Dstream through SparkStream and calculate WordCount.
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming02_Queue {
def main(args: Array[String]): Unit = {
// TODO 创建环境对象
// StreamingContext创建时,需要传递两个参数
// 第一个参数表示环境配置
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
// 第二个参数表示批量处理的周期(采集周期)
val ssc = new StreamingContext(sparkConf, Seconds(3))
val rddQueue = new mutable.Queue[RDD[Int]]()
val inputStream = ssc.queueStream(rddQueue, oneAtATime = false)
val mappedStream = inputStream.map((_, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}P190 [190. Shang Silicon Valley_SparkStreaming - DStream Creation - Custom Data Collector] 07:36
3.2 Custom data source
3.2.1 Usage and instructions
3.2.2 Case Practice
Requirements: Customize the data source to monitor a certain port number and obtain the content of the port number.
package com.atguigu.bigdata.spark.streaming
import java.util.Random
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming03_DIY {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())
messageDS.print()
ssc.start()
ssc.awaitTermination()
}
/*
自定义数据采集器
1.继承Receiver,定义泛型, 传递参数
2.重写方法
*/
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY) {
private var flg = true
override def onStart(): Unit = {
new Thread(new Runnable {
override def run(): Unit = {
while (flg) {
val message = "采集的数据为:" + new Random().nextInt(10).toString
store(message)
Thread.sleep(500)
}
}
}).start()
}
override def onStop(): Unit = {
flg = false;
}
}
}P191 [191. Shang Silicon Valley_SparkStreaming - DStream creation - Socket data collector source code interpretation] 03:26
3.2.2 Case Practice
Requirements: Customize the data source to monitor a certain port number and obtain the content of the port number.
P192 [192. Shang Silicon Valley_SparkStreaming - DStream creation - Kafka data source] 10:51
3.3 Kafka data source (interview, development focus)
3.3.1 Version selection
3.3.2 Kafka 0-8 Receiver mode (not applicable to the current version)
3.3.3 Kafka 0-8 Direct mode (not applicable to the current version)
3.3.4 Kafka 0-10 Direct mode
package com.atguigu.bigdata.spark.streaming
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming04_Kafka {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}Chapter 4 DStream Conversion
P193 [193. Shang Silicon Valley_SparkStreaming - DStream Conversion - State Operation] 16:09
Chapter 4. DStream Transformation
The operations on DStream are similar to those of RDD, which are divided into Transformations (transformation) and Output Operations (output). In addition, there are some special primitives in transformation operations, such as: updateStateByKey(), transform() and various Window related primitives.
4.1 Stateless conversion operation
package com.atguigu.bigdata.spark.streaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming05_State {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
// 无状态数据操作,只对当前的采集周期内的数据进行处理
// 在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
// 使用有状态操作时,需要设定检查点路径
val datas = ssc.socketTextStream("localhost", 9999)
val wordToOne = datas.map((_, 1))
//val wordToCount = wordToOne.reduceByKey(_+_)
// updateStateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值
// 第一个值表示相同的key的value数据
// 第二个值表示缓存区相同key的value数据
val state = wordToOne.updateStateByKey(
(seq: Seq[Int], buff: Option[Int]) => {
val newCount = buff.getOrElse(0) + seq.sum
Option(newCount)
}
)
state.print()
ssc.start()
ssc.awaitTermination()
}
}P194 [194. Shang Silicon Valley_SparkStreaming - DStream Transformation - Stateless Operation - transform] 09:06
4.1.1 Transform
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
// transform方法可以将底层RDD获取到后进行操作
// 1. DStream功能不完善
// 2. 需要代码周期性地执行
// Code : Driver端
val newDS: DStream[String] = lines.transform(
rdd => {
// Code : Driver端,(周期性执行)
rdd.map(
str => {
// Code : Executor端
str
}
)
}
)
// Code : Driver端
val newDS1: DStream[String] = lines.map(
data => {
// Code : Executor端
data
}
)
ssc.start()
ssc.awaitTermination()
}
}P195 [195. Shang Silicon Valley_SparkStreaming - DStream conversion - stateless operation - join] 03:59
4.1.2 join
The join between two streams requires the batch size of the two streams to be the same, so that calculations can be triggered at the same time. The calculation process is to join the respective RDDs in the two streams of the current batch, which has the same effect as the join of two RDDs.
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val data9999 = ssc.socketTextStream("localhost", 9999)
val data8888 = ssc.socketTextStream("localhost", 8888)
val map9999: DStream[(String, Int)] = data9999.map((_, 9))
val map8888: DStream[(String, Int)] = data8888.map((_, 8))
// 所谓的DStream的Join操作,其实就是两个RDD的join
val joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888)
joinDS.print()
ssc.start()
ssc.awaitTermination()
}
}P196 [196. Shang Silicon Valley_SparkStreaming - DStream Conversion - Stateful Operation - window] 12:17
4.2.2 WindowOperations
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Window {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
// 窗口的范围应该是采集周期的整数倍
// 窗口可以滑动的,但是默认情况下,一个采集周期进行滑动
// 这样的话,可能会出现重复数据的计算,为了避免这种情况,可以改变滑动的幅度(步长)
val windowDS: DStream[(String, Int)] = wordToOne.window(Seconds(6), Seconds(6))
val wordToCount = windowDS.reduceByKey(_ + _)
wordToCount.print()
ssc.start()
ssc.awaitTermination()
}
}P197 [197. Shang Silicon Valley_SparkStreaming - DStream Conversion - Stateful Operation - window - Supplement] 08:39
4.2.2 WindowOperations
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Window1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
// reduceByKeyAndWindow : 当窗口范围比较大,但是滑动幅度比较小,那么可以采用增加数据和删除数据的方式
// 无需重复计算,提升性能。
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x: Int, y: Int) => {
x + y
},
(x: Int, y: Int) => {
x - y
},
Seconds(9), Seconds(3))
windowDS.print()
ssc.start()
ssc.awaitTermination()
}
}Chapter 5 DStream Output
P198 [198. Shang Silicon Valley_SparkStreaming - DStream Output] 04:43
Chapter 5 DStream Output
The output operation specifies the operation to be performed on the data obtained by the transformation operation on the streaming data (such as pushing the result to an external database or outputting it to the screen). Similar to lazy evaluation in RDD, if neither a DStream nor its derived DStreams have been output, then none of these DStreams will be evaluated. If no output operation is set in the StreamingContext, the entire context will not be started.
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming07_Output {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x: Int, y: Int) => {
x + y
},
(x: Int, y: Int) => {
x - y
},
Seconds(9), Seconds(3))
// SparkStreaming如何没有输出操作,那么会提示错误
//windowDS.print()
ssc.start()
ssc.awaitTermination()
}
}package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming07_Output1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x: Int, y: Int) => {
x + y
},
(x: Int, y: Int) => {
x - y
},
Seconds(9), Seconds(3))
// foreachRDD不会出现时间戳
windowDS.foreachRDD(
rdd => {
}
)
ssc.start()
ssc.awaitTermination()
}
}Chapter 6 Graceful Shutdown
P199【199.Silicon Valley_SparkStreaming - Shut Down Gracefully】15:45
Chapter 6. Graceful shutdown
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object SparkStreaming08_Close {
def main(args: Array[String]): Unit = {
/*
线程的关闭:
val thread = new Thread()
thread.start()
thread.stop(); // 强制关闭
*/
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
wordToOne.print()
ssc.start()
// 如果想要关闭采集器,那么需要创建新的线程
// 而且需要在第三方程序中增加关闭状态
new Thread(
new Runnable {
override def run(): Unit = {
// 优雅地关闭
// 计算节点不在接收新的数据,而是将现有的数据处理完毕,然后关闭
// Mysql : Table(stopSpark) => Row => data
// Redis : Data(K-V)
// ZK : /stopSpark
// HDFS : /stopSpark
/*
while ( true ) {
if (true) {
// 获取SparkStreaming状态
val state: StreamingContextState = ssc.getState()
if ( state == StreamingContextState.ACTIVE ) {
ssc.stop(true, true)
}
}
Thread.sleep(5000)
}
*/
Thread.sleep(5000)
val state: StreamingContextState = ssc.getState()
if (state == StreamingContextState.ACTIVE) {
ssc.stop(true, true)
}
System.exit(0)
}
}
).start()
ssc.awaitTermination() // block 阻塞main线程
}
}P200 [200.Silicon Valley_SparkStreaming - Graceful Shutdown - Restoring Data] 03:30
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object SparkStreaming09_Resume {
def main(args: Array[String]): Unit = {
val ssc = StreamingContext.getActiveOrCreate("cp", () => {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
wordToOne.print()
ssc
})
ssc.checkpoint("cp")
ssc.start()
ssc.awaitTermination() // block 阻塞main线程
}
}Chapter 7 SparkStreaming Case Practice
P201 [201. Shang Silicon Valley_SparkStreaming - Case Practice - Environment and Data Preparation] 16:43
Chapter 7 SparkStreaming Case Practice
7.1 Environment preparation
package com.atguigu.bigdata.spark.streaming
import java.util.{Properties, Random}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming10_MockData {
def main(args: Array[String]): Unit = {
// 生成模拟数据
// 格式 :timestamp area city userid adid
// 含义: 时间戳 区域 城市 用户 广告
// Application => Kafka => SparkStreaming => Analysis
val prop = new Properties()
// 添加配置
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "linux1:9092")
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](prop)
while (true) {
mockdata().foreach(
data => {
// 向Kafka中生成数据
val record = new ProducerRecord[String, String]("atguiguNew", data)
producer.send(record)
println(data)
}
)
Thread.sleep(2000)
}
}
def mockdata() = {
val list = ListBuffer[String]()
val areaList = ListBuffer[String]("华北", "华东", "华南")
val cityList = ListBuffer[String]("北京", "上海", "深圳")
for (i <- 1 to new Random().nextInt(50)) {
val area = areaList(new Random().nextInt(3))
val city = cityList(new Random().nextInt(3))
var userid = new Random().nextInt(6) + 1
var adid = new Random().nextInt(6) + 1
list.append(s"${System.currentTimeMillis()} ${area} ${city} ${userid} ${adid}")
}
list
}
}P202 [202. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 1 - Analysis] 10:20
7.3 Requirement 1: Advertising Blacklist

P203 [203. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 1 - Function Realization - Blacklist Judgment] 19:28
package com.atguigu.bigdata.spark.streaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming11_Req1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}package com.atguigu.bigdata.spark.streaming
import java.sql.ResultSet
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming11_Req1_BlackList {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
val ds = adClickData.transform(
rdd => {
// TODO 通过JDBC周期性获取黑名单数据
val blackList = ListBuffer[String]()
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement("select userid from black_list")
val rs: ResultSet = pstat.executeQuery()
while (rs.next()) {
blackList.append(rs.getString(1))
}
rs.close()
pstat.close()
conn.close()
// TODO 判断点击用户是否在黑名单中
val filterRDD = rdd.filter(
data => {
!blackList.contains(data.user)
}
)
// TODO 如果用户不在黑名单中,那么进行统计数量(每个采集周期)
filterRDD.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date(data.ts.toLong))
val user = data.user
val ad = data.ad
((day, user, ad), 1) // (word, count)
}
).reduceByKey(_ + _)
}
)
ds.foreachRDD(
rdd => {
rdd.foreach {
case ((day, user, ad), count) => {
println(s"${day} ${user} ${ad} ${count}")
if (count >= 30) {
// TODO 如果统计数量超过点击阈值(30),那么将用户拉入到黑名单
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement(
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin)
pstat.setString(1, user)
pstat.setString(2, user)
pstat.executeUpdate()
pstat.close()
conn.close()
} else {
// TODO 如果没有超过阈值,那么需要将当天的广告点击数量进行更新。
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement(
"""
| select
| *
| from user_ad_count
| where dt = ? and userid = ? and adid = ?
""".stripMargin)
pstat.setString(1, day)
pstat.setString(2, user)
pstat.setString(3, ad)
val rs = pstat.executeQuery()
// 查询统计表数据
if (rs.next()) {
// 如果存在数据,那么更新
val pstat1 = conn.prepareStatement(
"""
| update user_ad_count
| set count = count + ?
| where dt = ? and userid = ? and adid = ?
""".stripMargin)
pstat1.setInt(1, count)
pstat1.setString(2, day)
pstat1.setString(3, user)
pstat1.setString(4, ad)
pstat1.executeUpdate()
pstat1.close()
// TODO 判断更新后的点击数据是否超过阈值,如果超过,那么将用户拉入到黑名单。
val pstat2 = conn.prepareStatement(
"""
|select
| *
|from user_ad_count
|where dt = ? and userid = ? and adid = ? and count >= 30
""".stripMargin)
pstat2.setString(1, day)
pstat2.setString(2, user)
pstat2.setString(3, ad)
val rs2 = pstat2.executeQuery()
if (rs2.next()) {
val pstat3 = conn.prepareStatement(
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin)
pstat3.setString(1, user)
pstat3.setString(2, user)
pstat3.executeUpdate()
pstat3.close()
}
rs2.close()
pstat2.close()
} else {
// 如果不存在数据,那么新增
val pstat1 = conn.prepareStatement(
"""
| insert into user_ad_count ( dt, userid, adid, count ) values ( ?, ?, ?, ? )
""".stripMargin)
pstat1.setString(1, day)
pstat1.setString(2, user)
pstat1.setString(3, ad)
pstat1.setInt(4, count)
pstat1.executeUpdate()
pstat1.close()
}
rs.close()
pstat.close()
conn.close()
}
}
}
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P204 [204. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 1 - Function Realization - Statistical Data Update] 16:26
SparkStreaming11_Req1_BlackList
P205 [205. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 1 - Function Realization - Testing & Simplification & Optimization] 19:30
package com.atguigu.bigdata.spark.streaming
import java.sql.ResultSet
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming11_Req1_BlackList1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
val ds = adClickData.transform(
rdd => {
// TODO 通过JDBC周期性获取黑名单数据
val blackList = ListBuffer[String]()
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement("select userid from black_list")
val rs: ResultSet = pstat.executeQuery()
while (rs.next()) {
blackList.append(rs.getString(1))
}
rs.close()
pstat.close()
conn.close()
// TODO 判断点击用户是否在黑名单中
val filterRDD = rdd.filter(
data => {
!blackList.contains(data.user)
}
)
// TODO 如果用户不在黑名单中,那么进行统计数量(每个采集周期)
filterRDD.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date(data.ts.toLong))
val user = data.user
val ad = data.ad
((day, user, ad), 1) // (word, count)
}
).reduceByKey(_ + _)
}
)
ds.foreachRDD(
rdd => {
// rdd. foreach方法会每一条数据创建连接
// foreach方法是RDD的算子,算子之外的代码是在Driver端执行,算子内的代码是在Executor端执行
// 这样就会涉及闭包操作,Driver端的数据就需要传递到Executor端,需要将数据进行序列化
// 数据库的连接对象是不能序列化的。
// RDD提供了一个算子可以有效提升效率 : foreachPartition
// 可以一个分区创建一个连接对象,这样可以大幅度减少连接对象的数量,提升效率
rdd.foreachPartition(iter => {
val conn = JDBCUtil.getConnection
iter.foreach {
case ((day, user, ad), count) => {
}
}
conn.close()
}
)
rdd.foreach {
case ((day, user, ad), count) => {
println(s"${day} ${user} ${ad} ${count}")
if (count >= 30) {
// TODO 如果统计数量超过点击阈值(30),那么将用户拉入到黑名单
val conn = JDBCUtil.getConnection
val sql =
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql, Array(user, user))
conn.close()
} else {
// TODO 如果没有超过阈值,那么需要将当天的广告点击数量进行更新。
val conn = JDBCUtil.getConnection
val sql =
"""
| select
| *
| from user_ad_count
| where dt = ? and userid = ? and adid = ?
""".stripMargin
val flg = JDBCUtil.isExist(conn, sql, Array(day, user, ad))
// 查询统计表数据
if (flg) {
// 如果存在数据,那么更新
val sql1 =
"""
| update user_ad_count
| set count = count + ?
| where dt = ? and userid = ? and adid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql1, Array(count, day, user, ad))
// TODO 判断更新后的点击数据是否超过阈值,如果超过,那么将用户拉入到黑名单。
val sql2 =
"""
|select
| *
|from user_ad_count
|where dt = ? and userid = ? and adid = ? and count >= 30
""".stripMargin
val flg1 = JDBCUtil.isExist(conn, sql2, Array(day, user, ad))
if (flg1) {
val sql3 =
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql3, Array(user, user))
}
} else {
val sql4 =
"""
| insert into user_ad_count ( dt, userid, adid, count ) values ( ?, ?, ?, ? )
""".stripMargin
JDBCUtil.executeUpdate(conn, sql4, Array(day, user, ad, count))
}
conn.close()
}
}
}
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P206 [206. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 2 - Function Realization] 09:26
7.4 Requirement 2: Real-time statistics of advertising clicks
package com.atguigu.bigdata.spark.streaming
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.streaming.SparkStreaming11_Req1_BlackList.AdClickData
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming12_Req2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
val reduceDS = adClickData.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date(data.ts.toLong))
val area = data.area
val city = data.city
val ad = data.ad
((day, area, city, ad), 1)
}
).reduceByKey(_ + _)
reduceDS.foreachRDD(
rdd => {
rdd.foreachPartition(
iter => {
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement(
"""
| insert into area_city_ad_count ( dt, area, city, adid, count )
| values ( ?, ?, ?, ?, ? )
| on DUPLICATE KEY
| UPDATE count = count + ?
""".stripMargin)
iter.foreach {
case ((day, area, city, ad), sum) => {
pstat.setString(1, day)
pstat.setString(2, area)
pstat.setString(3, city)
pstat.setString(4, ad)
pstat.setInt(5, sum)
pstat.setInt(6, sum)
pstat.executeUpdate()
}
}
pstat.close()
conn.close()
}
)
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P207 [207. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 2 - Garbled Code Problem] 06:11
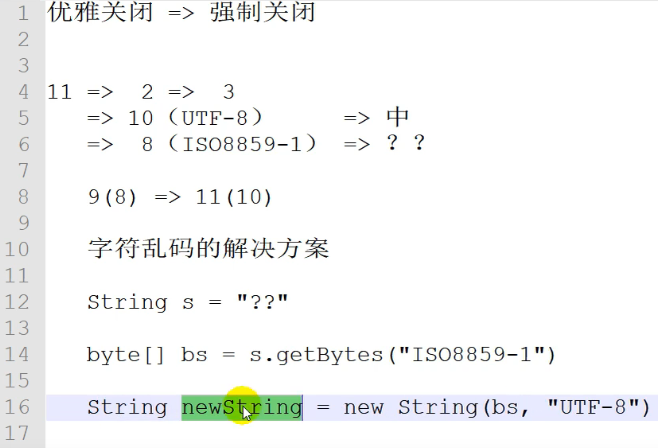
P208 [208. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 3 - Introduction & Function Realization] 15:51
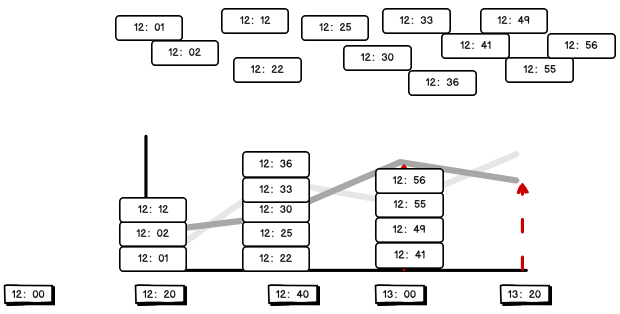
7.5 Requirement 3: Ad clicks in the last hour
package com.atguigu.bigdata.spark.streaming
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming13_Req3 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
// 最近一分钟,每10秒计算一次
// 12:01 => 12:00
// 12:11 => 12:10
// 12:19 => 12:10
// 12:25 => 12:20
// 12:59 => 12:50
// 55 => 50, 49 => 40, 32 => 30
// 55 / 10 * 10 => 50
// 49 / 10 * 10 => 40
// 32 / 10 * 10 => 30
// 这里涉及窗口的计算
val reduceDS = adClickData.map(
data => {
val ts = data.ts.toLong
val newTS = ts / 10000 * 10000
(newTS, 1)
}
).reduceByKeyAndWindow((x: Int, y: Int) => {
x + y
}, Seconds(60), Seconds(10))
reduceDS.print()
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P209 [209. Shang Silicon Valley_SparkStreaming - Case Practice - Requirement 3 - Effect Demonstration] 09:54
package com.atguigu.bigdata.spark.streaming
import java.io.{File, FileWriter, PrintWriter}
import java.text.SimpleDateFormat
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming13_Req31 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
// 最近一分钟,每10秒计算一次
// 12:01 => 12:00
// 12:11 => 12:10
// 12:19 => 12:10
// 12:25 => 12:20
// 12:59 => 12:50
// 55 => 50, 49 => 40, 32 => 30
// 55 / 10 * 10 => 50
// 49 / 10 * 10 => 40
// 32 / 10 * 10 => 30
// 这里涉及窗口的计算
val reduceDS = adClickData.map(
data => {
val ts = data.ts.toLong
val newTS = ts / 10000 * 10000
(newTS, 1)
}
).reduceByKeyAndWindow((x: Int, y: Int) => {
x + y
}, Seconds(60), Seconds(10))
//reduceDS.print()
reduceDS.foreachRDD(
rdd => {
val list = ListBuffer[String]()
val datas: Array[(Long, Int)] = rdd.sortByKey(true).collect()
datas.foreach {
case (time, cnt) => {
val timeString = new SimpleDateFormat("mm:ss").format(new java.util.Date(time.toLong))
list.append(s"""{"xtime":"${timeString}", "yval":"${cnt}"}""")
}
}
// 输出文件
val out = new PrintWriter(new FileWriter(new File("D:\\mineworkspace\\idea\\classes\\atguigu-classes\\datas\\adclick\\adclick.json")))
out.println("[" + list.mkString(",") + "]")
out.flush()
out.close()
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P210 [210.Silicon Valley_SparkStreaming - Summary - Courseware Review] 08:12
03_SparkStreaming of Silicon Valley Big Data Technology.pdf