Deep learning paper sharing (6) Simple Baselines for Image Restoration
foreword
Original paper: https://arxiv.org/abs/2204.0467
Paper code: https://github.com/megvii-research/NAFNet
Title: Simple Baselines for Image Restoration
Authors: Liangyu Chen ⋆ , Xiaojie Chu ⋆ , Xiangyu Zhang, and Jian Sun
MEGVII Technology, Beijing, CN
only for translation
Abstract
Although significant progress has been made in the field of image restoration in recent years, the system complexity of state-of-the-art (SOTA) methods is also increasing, which may hinder the convenient analysis and comparison of methods. In this paper, we propose a simple baseline that outperforms SOTA methods and is computationally efficient. To further simplify the baseline, we reveal that non-linear activation functions such as Sigmoid, ReLU, GELU, Softmax, etc. are unnecessary: they can be replaced by multiplication or removed. Therefore, we derive a nonlinear activation free network, NAFNet, from the baseline. SOTA results are achieved on various challenging benchmarks, such as 33.69 dB PSNR on GoPro (for image deblurring), surpassing the previous SOTA by 0.38 dB at only 8.4% of its computational cost; denoising) is 40.30 dB, surpassing the previous SOTA by 0.28 dB, and the computational cost is less than half. Code and pretrained models are released at github.com/megvii-research/NAFNet.
Keywords: image restoration, image denoising, image deblurring
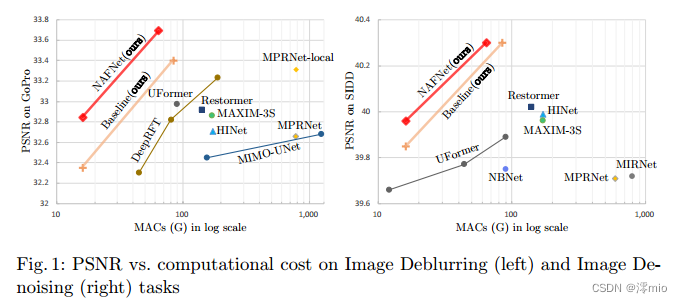
Figure 1: PSNR and computational cost on image deblurring (left) and image denoising (right) tasks
1 Introduction
With the development of deep learning, the performance of image restoration methods has been greatly improved. Deep learning based methods [5, 37, 39, 36, 6, 7, 32, 8, 25] have achieved great success. Examples [39] and [8] achieve PSNR denoising/deblurring of 40.02/33.31 dB on SIDD[1]/GoPro[26], respectively.
Although these methods have good performance, their system complexity is high. For ease of discussion, we decompose the system complexity into two parts: inter-block complexity and intra-block complexity. The first is inter-block complexity, as shown in Figure 2. [7,25] introduce connections between feature maps of different sizes; [5,37] are multi-stage networks, where the latter stage refines the results of the previous stage. Second, intra-block complexity, that is, various design choices within a block. For example, the multi-Dconv head-transposed attention module and gated Dconv feed-forward network in [39] (as shown in Fig. 3a), the Swin transformer block in [22], the HINBlock in [5], etc. It is not practical to evaluate design choices individually.
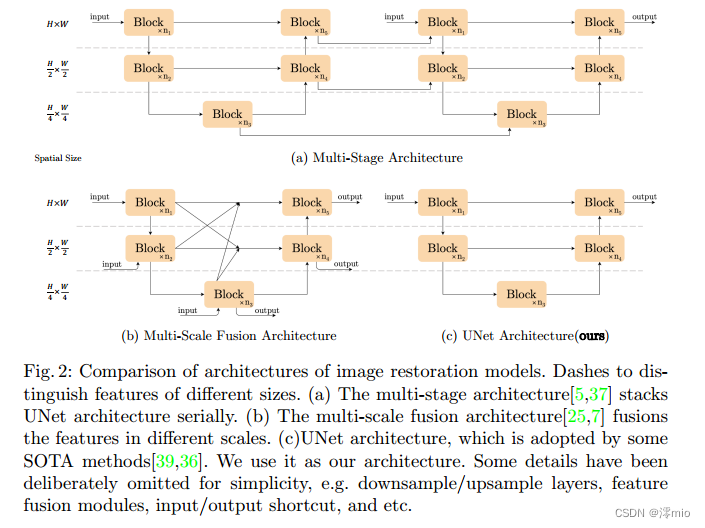
Figure 2: Architecture comparison of image restoration models. Use dashes to distinguish features of different sizes. (a) Multi-stage architectures [5, 37] stack UNet architectures sequentially. (b) Multi-scale fusion architectures [25, 7] fuse features from different scales. © UNet architecture, some SOTA methods adopt UNet architecture [39, 36]. We use it as our schema. For simplicity, we have intentionally omitted some details, such as downsampling/upsampling layers, feature fusion modules, input/output shortcuts, etc.
Based on the above facts, a natural question arises: Is it possible for a network with low inter-block and low intra-block complexity to achieve SOTA performance? To achieve the first condition (low inter-block complexity), this paper adopts a single-stage UNet as the architecture (following some SOTA methods [39,36]), focusing on the second condition. To this end, we start with a common block containing the most common components, namely convolutions, ReLUs, and shortcuts [14]. From common blocks, we add/replace components of the SOTA approach and verify how much performance gain these components bring. Through extensive ablation studies, we propose a simple baseline, shown in Figure 3c, that outperforms SOTA methods and is computationally efficient. It has the potential to spark new ideas and make them easier to test. The baseline containing GELU [15] and Channel Attention Module [16] (CA) can be further simplified: we find that GELU in the baseline can be regarded as a special case of Gated Linear Unit10, and thus empirically prove that it can be simplified by a simple Gates (i.e. element-wise product of feature maps) are replaced. Furthermore, we also reveal the formal similarity between CA and GLU, and the non-linear activation function in CA can also be removed. In summary, the simple baseline can be further reduced to a nonlinear activation-free network, called NAFNet. We mainly conduct image denoising experiments on SIDD [1], image deblurring experiments on GoPro [26], and sequentially [5, 39, 37]. The main results are shown in Fig. 1. Our proposed baseline and NAFNet are computationally efficient while reaching SOTA results: 33.40/33.69 dB on GoPro, which outperform the previous SOTA [8] by 0.09/0.38 dB, respectively, at a computational cost of 8.4%; 40.30 dB on SIDD, outperforming [39] by 0.28 dB at less than half the computational cost. Extensive and high-quality experiments are performed to illustrate the effectiveness of our proposed baseline.
The contributions of this paper are summarized as follows:
- By decomposing the SOTA method and extracting its basic components, we form a baseline with lower system complexity (Fig. 3c), which can outperform previous SOTA methods with lower computational cost, as shown in Fig. 1. It allows researchers to generate new ideas and evaluate them easily.
- By revealing the connection between GELU (Channel Attention to Gated Linear Unit), we further simplify the baseline by removing or replacing nonlinear activation functions such as Sigmoid, ReLU and GELU, and propose a nonlinear activation-free network, NAFNet . Although simplified, the baseline can be met or exceeded. To our knowledge, this is the first work to demonstrate that non-linear activation functions may not be necessary for SOTA computer vision methods. This work may have the potential to expand the design space of SOTA computer vision methods.
2 Related Works
2.1 Image Restoration
The goal of image restoration tasks is to restore degraded images (e.g., noise, blur) to clean images. Recently, deep learning based methods [5, 37, 39, 36, 6, 7, 32, 8, 25] have achieved SOTA results on these tasks, and most of them can be regarded as Variants. It stacks blocks into a U-shaped configuration and employs jump connections. These variants bring performance improvements, as well as system complexity, which we broadly categorize as inter-block complexity and intra-block complexity.
Inter-block Complexity :
[37,5] is a multi-stage network, that is, the latter stage refines the results of the previous stage, and each stage is a u-shaped architecture. The design is based on the assumption that breaking down the difficult image restoration task into several subtasks helps improve performance. Differently, [7, 25] employ a single-stage design, which achieves competitive results, but they introduce complex connections between feature maps of different sizes. Some methods adopt both of the above strategies at the same time, such as [32]. Other SOTA methods, such as: [39, 36] maintain the simple structure of single-stage UNet, but they introduce intra-block complexity, which we discuss next.
Intra-block Complexity : There are many different intra-block design schemes, we pick some examples here. [39] reduce the memory and temporal complexity of self-attention via channel attention maps instead of spatial attention maps [34]. In addition, feedforward networks employ gated linear units [10] and depthwise convolutions. [36] introduced window-based multi-head self-attention, similar to [22]. In addition, a locally enhanced feed-forward network is introduced in its block, and deep convolution is added to the feed-forward network to enhance the local information capture ability. Differently, we reveal that increasing system complexity is not the only way to improve performance: SOTA performance can be achieved with simple baselines.
2.2 Gated Linear Units
Gated linear unit 10 can be explained by the element-wise generation of two linear transformation layers, one of which is activated by a nonlinearity. GLU and its variants have proven their effectiveness in NLP [30, 10, 9] and are also flourishing in computer vision [32, 39, 17, 20]. In this paper, we reveal important improvements brought by GLU. Unlike [30], we remove the non-linear activation function in GLU without performance drop. Furthermore, based on the fact that nonlinear activation-free GLU inherently contains nonlinearity (as the product of two linear transformations induces nonlinearity), our baseline can be simplified by replacing the nonlinear activation function with the multiplication of two feature maps. To the best of our knowledge, this is the first computer vision model to achieve SOTA performance without nonlinear activation functions.
3 Build A Simple Baseline
In this section, we construct a simple baseline for the image restoration task from scratch. In order to keep the structure simple, our principle is not to add unnecessary entities. Through the empirical evaluation of the recovery task, the necessity of the recovery task is verified. We mainly use HINet Simple [5] to conduct experiments with a model size around 16 gmac, estimating mac through an input with a spatial size of 256 × 256. The calculation results of different capacity models are shown in the experimental part. We mainly validate the results (PSNR) on two popular datasets for denoising (i.e. SIDD [1]) and deblurring (i.e. GoPro [26] dataset), based on the fact that these tasks are fundamental for low-level vision. Design choices are discussed in the following subsections.
3.1 Architecture
To reduce inter-block complexity, we adopt a classic single-stage U-architecture with skip connections, as shown in Fig. 2c [39, 36]. We believe that architecture should not be an obstacle to performance. The experimental results confirmed our conjecture, as shown in Table 6, 7 and Figure 1.
3.2 A Plain Block
Neural networks are stacked in blocks. We have determined how to stack blocks on top of it (i.e., in the UNet architecture), but how to design the internal structure of the blocks is still a problem. We start with a common block containing the most common components, namely convolution, ReLU and shortcut [14], and the arrangement of these components follows [13, 22], as shown in Figure 3b. For simplicity, we denote it as PlainNet. The use of convolutional networks instead of transformers is based on the following considerations. First, although transformers perform well in computer vision, some works [13, 23] claim that they may not be necessary to achieve SOTA results. Second, depthwise convolution is simpler than self-attention mechanism [34]. Third, this article does not intend to discuss the advantages and disadvantages of transformers and convolutional neural networks, but only provides a simple baseline. Discussion on the attention mechanism will be presented in the next subsection.
3.3 Normalization
Normalization is widely adopted in high-level computer vision tasks, and it is also popular in low-level vision. While [26] abandoned Batch Normalization [18] because small batches may bring unstable statistics [38], [5] reintroduced Instance Normalization [33] to avoid the small batch problem. However, [5] showed that adding instance normalization does not always lead to performance gains and requires manual tuning. The difference is that under the boom of transformers, layer normalization [3] is used by more and more methods, including SOTA methods [32, 39, 36, 23, 22]. Based on these facts, we speculate that layer normalization may be crucial for SOTA recovery, so we add layer normalization to the normal blocks described above. This change makes the training smoother, even with a 10x higher learning rate. Larger learning rates lead to significant performance gains: +0.44 dB (39.29 dB to 39.73 dB) on SIDD [1] and +3.39 dB (28.51 dB to 31.90 dB) on the GoPro [26] dataset. To sum up, we add layer normalization to common blocks because it stabilizes the training process.
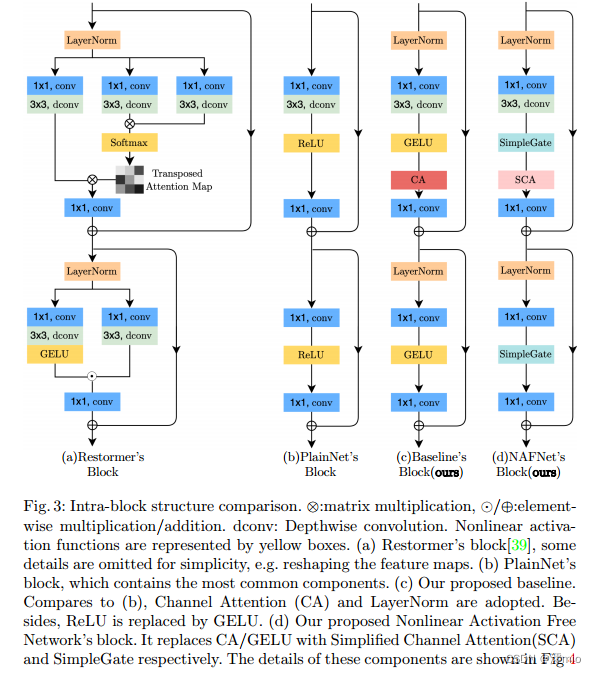
Figure 3: Intra-block structure comparison. ⊗: matrix multiplication, ⊙/⊕: element multiplication/addition. dconv: depthwise convolution. Nonlinear activation functions are indicated by yellow boxes. (a) Restormer's block [39], some details such as reshaping feature maps are omitted for simplicity. (b) Blocks of PlainNet, which contain the most common components. © Our proposed baseline. Compared with (b), CA (Channel Attention) and LayerNorm are adopted. Furthermore, ReLU is replaced by GELU. (d) Our proposed nonlinear activation free network block. It replaces CA/GELU with Simplified Channel Attention (SCA) and SimpleGate, respectively. The details of these components are shown in Figure 4
3.4 Activation
The activation function in the common block, the rectified linear unit28 , is widely used in computer vision. However, there is a tendency to replace ReLU with GELU in SOTA methods [23, 39, 32, 22, 12] [15]. This substitution is also implemented in our model. The performance remains comparable on SIDD (from 39.73 dB to 39.71 dB), which is consistent with [23], but brings a performance gain of 0.21 dB on GoPro (31.90 dB to 32.11 dB). In short, we replace ReLU with GELU in pure blocks because it brings a non-trivial gain in image deblurring while maintaining image denoising performance.
3.5 Attention
In view of the popularity of transformers in the field of computer vision in recent years, its attention mechanism is an unavoidable topic in the internal structure design of blocks. There are many variants of attention mechanisms, we only discuss some of them here. The vanilla self-attention mechanism [34] employed in [12, 4] generates target features by linearly combining all features and weighting them according to the similarity between features. Therefore, each feature contains global information, but its computational complexity is quadratic with the size of the feature map. The data processed by some image restoration tasks are of high resolution, which makes traditional self-attention methods impractical. Alternatively, [22, 21, 36] apply self-attention only in fixed-sized local windows to alleviate the problem of increased computation. Although it lacks global information. We do not adopt window-based attention because in ordinary blocks, depthwise convolutions can capture local information well [13, 23].
The difference is that [39] changes spatial attention to channel attention, which avoids computational problems while maintaining the global information of each feature. It can be viewed as a special variant of channel attention [16]. Inspired by [39], we realize that vanilla channel attention satisfies the requirement of computational efficiency and brings global information to feature maps. Moreover, the effectiveness of channel attention has been verified in image restoration tasks [37, 8], so we add channel attention to the plain block. 0.14 dB is obtained on the SIDD [1] dataset (39.71 ~ 39.85 dB), and 0.24 dB (32.11 ~ 32.35 dB) on the GoPro [26] dataset.
3.6 Summary
So far, we have constructed a simple baseline from scratch, as shown in Table 1. The architecture and modules are shown in Figure 2c and Figure 3c, respectively. Each component in the baseline is trivial, such as layer normalization, convolution, GELU and channel attention. However, the combination of these trivial components leads to a strong baseline: it can surpass previous SOTA results on SIDD and GoPro datasets at a fraction of the computational cost, as shown in Fig. 1 and Tables 6, 7. We believe simple baselines can help researchers evaluate their ideas.
4 Nonlinear Activation Free Network
The baseline described above is simple and competitive, but is it possible to further improve performance while ensuring simplicity? Can it be made simpler without losing performance? We try to find some SOTA methods by commonality to answer these questions [32,39,20,17]. We found that in these methods, a gated linear unit 10 is employed . That means GLU could be promising. We'll discuss that later. Figure 4: Schematic of
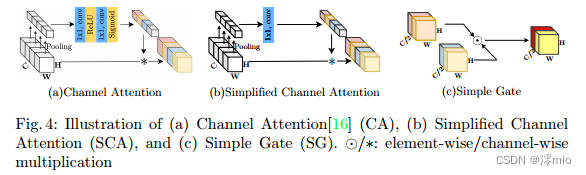
(a) Channel Attention16 , (b) Simplified Channel Attention (SCA) and © Simple Gate (SG). ⊙/ *: element/channel multiplication
Gated Linear Units : Gated linear units can be expressed as:
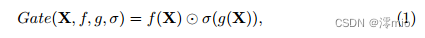
where X represents the feature map, f and g are linear transformers, σ is a nonlinear activation function, such as Sigmoid, and ⊙ represents element-wise multiplication. As mentioned above, adding GLU to our baseline may improve performance, but also increases intra-block complexity. This is not what we expected. To address this issue, we revisit the activation function in the baseline, namely GELU [15]:

where Φ is the cumulative distribution function of the standard normal distribution. Based on [15], GELU can be approximated as:
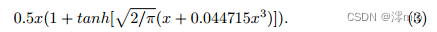
From Eqn. 1 and Eqn. 2, GELU is a special case of GLU, that is, f and g are identity functions, and σ is Φ. Through the similarity, we speculate from another perspective that GLU can be regarded as a generalization of the activation function, which can replace the nonlinear activation function. Furthermore, we note that GLU itself contains nonlinearity and does not depend on σ: Gate(X) = f(X)⊙g(X) contains nonlinearity even if σ is removed. Based on this, we propose a simple GLU variant: directly divide the feature map into two parts in the channel dimension and multiply them, as shown in Figure 4c, called SimpleGate. Compared to the complex implementation of GELU in Eqn.3, our SimpleGate can be implemented by element-wise multiplication and nothing more:
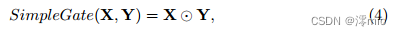
where X and Y are feature maps of the same size.
By replacing GELU in the baseline with the proposed SimpleGate, the performance of image denoising (on SIDD [1]) and image deblurring (on GoPro [26] dataset) is improved by 0.08 dB (39.85 dB to 39.93 dB ) and 0.41 dB (32.35 dB to 32.76 dB). The results show that our proposed SimpleGate can replace GELU. At this point, only a few types of non-linear activations remain in the network: Sigmoid and ReLU [16] in the channel attention module, the simplifications of which we discuss next.
Simplified Channel Attention : In Section 3, we introduce channel attention [16] into our block because it captures global information and is computationally efficient. As shown in Figure 4a: it first compresses spatial information into channels, then applies multi-layer perception to it to compute channel attention, and uses it for weighted feature maps. It can be expressed as:
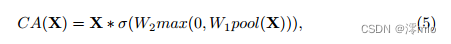
where X represents the feature map and pool represents the global average pooling operation that aggregates spatial information into channels. σ is a nonlinear activation function, Sigmoid, W1, and W2 are fully connected layers, and ReLU is used between fully connected layers. Finally, * is a channel-wise product operation. If we regard the channel attention calculation as a function, denoted as Ψ, and the input is X, then Eqn. 5 can be rewritten as:

It can be noticed that Eqn. 6 is very similar to Eqn. 1. This inspires us to consider channel attention as a special case of GLU, which can be simplified like GLU in the previous subsection. By preserving the two most important roles of channel attention, i.e., aggregating global information and channel information interaction, we propose simplified channel attention: the
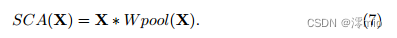
notation follows Equation 5. Obviously, the simplified channel attention (Eqn. 7) is simpler than the original channel attention (Eqn. 5), as shown in Fig. 4a and Fig. 4b. While it's simpler, there's no performance penalty: +0.03 dB (39.93 dB to 39.96 dB) on SIDD and +0.09 dB (32.76 dB to 32.85 dB) on GoPro.
Summary : Starting from the baseline proposed in Section 3, we further simplify it by replacing GELU with SimpleGate and simplified channel attention without loss of performance. We emphasize the absence of non-linear activation functions (such as ReLU, GELU, Sigmoid, etc.) in the simplified network. So we call it the baseline nonlinear activation free network, or NAFNet. It can match or exceed the baseline, despite having no non-linear activation function, as shown in Figure 1 and Tables 6,7. Thanks to the simplicity and effectiveness of NAFNet, we can now answer the question at the beginning of this section
5 Experiments
In this section, we analyze in detail the impact of the NAFNet design choices described in the previous sections. Next, we apply the proposed NAFNet to various image restoration applications, including RGB image denoising, image deblurring, raw image denoising and JPEG artifact image deblurring.

Figure 5 Qualitative comparison of image denoising methods based on SIDD [1]
5.1 Ablations
Ablation research mainly focuses on image denoising (SIDD [1]) and deblurring (GoPro [26]) tasks. If not specified, we follow the experimental settings of [5], such as 16 gmacs for computation budget, gradient clipping, and PSNR loss. We train the model using the Adam [19] optimizer (β1 = 0.9, β2 = 0.9, weight decay 0) with a total iteration number of 200K, an initial learning rate of 1e−3 gradually reduced to 1e−6, and a cosine annealing schedule [24] . The training patch size is 256 × 256 and the batch size is 32. Passing patch training and full-image testing will lead to performance degradation [8], we adopt TLC [8] after MPRNet-local [8] to solve this problem. The effect of TLC on GoPro1 is shown in Table 4. We mainly compare TLC with the "patch detection" strategy adopted by [5], [25], etc. It brings performance gains and avoids artifacts from patches. Furthermore, we use skip-init [11] to stabilize the training follow-up [23]. The default width and number of blocks are 32 and 36 respectively. If the number of blocks changes, we adjust the width to keep the computational budget constant. We report peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) in our experiments. Speed/memory/computational complexity evaluations are performed on an NVIDIA 2080Ti GPU with an input size of 256 × 256.
From PlainNet to the simple baseline: PlainNet is defined in Section 3 and its modules are shown in Figure 3b. We found that the training of PlainNet is unstable under default settings. As an alternative, we reduced the learning rate (lr) by a factor of 10 to make the model trainable. This problem is solved by introducing layer normalization (LN): the learning rate can be increased from 1e−4 to 1e−3, and the training process is more stable. On PSNR, LN brings 0.46 dB and 3.39 dB on SIDD and GoPro, respectively. In addition, GELU and Channel Attention (CA) are also shown in Table 1 for their effectiveness.
From the simple baseline to NAFNet:
As described in Section 3, NAFNet can be obtained by simplifying the baseline. In Table 2, we show that there is no performance penalty for this simplification. In contrast, PSNR improves by 0.11 dB and 0.50 dB in SIDD and GoPro, respectively. For a fair comparison, the computational complexity is consistent, see Supplementary Material for details. Provides a modified speedup compared to the baseline. Furthermore, in inference, there is no significant additional memory consumption compared to Baseline.

Table 1: Building a simple baseline from PlainNet. The effectiveness of Layer Normalization (LN), GELU and Channel Attention (CA) is verified. * indicates that the training is unstable due to the large learning rate (lr).
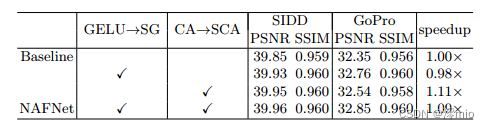
Table 2: NAFNet is derived from the simplification of the baseline by replacing GELU with SimpleGate (SG) and Channel Attention (CA) with Simplified Channel Attention (SCA).
Number of blocks: We verify the effect of the number of blocks on NAFNet in Table 3. We mainly consider delays at the 720 × 1280 spatial size, since that is the size of the entire GoPro image. In increasing the number of blocks to 36, the performance of the model is greatly improved without a significant increase in latency (+14.5% compared to 9 blocks). When the number of blocks is further increased to 72, the performance improvement of the model is not obvious, but the latency is significantly increased (30.0% increase compared to 36 blocks). Because 36 blocks allows for a better performance/latency balance, we use that as the default option.
Variants of σ in SimpleGate:
The Vanilla Gated Linear Unit (GLU) contains a non-linear activation function σ, as shown in Eqn. 1. Our proposed SimpleGate, shown in Figure 4 and Figure 4c, removes it. In other words, σ in SimpleGate is set as the identity function. We vary the σ in the unit function into different nonlinear activation functions in Table 5 to judge the importance of nonlinearity in σ. PSNR on SIDD is largely unaffected (fluctuating from 39.96 dB to 39.99 dB), while PSNR on GoPro drops significantly (from -0.11 dB to -0.35 dB), suggesting that in NAFNet, σ in SimpleGate may not need.
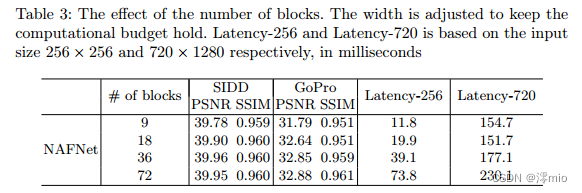
Table 3: Effect of number of blocks. Adjust the width to keep the compute budget constant. Latency-256 and Latency-720 are based on input sizes 256 × 256 and 720 × 1280 respectively in milliseconds
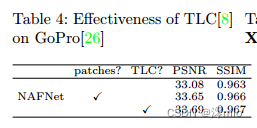
Table 4: Effectiveness of TLC on GoPro [8][26]
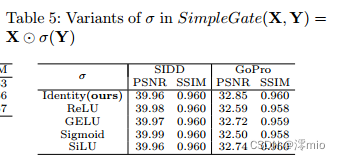
Table 5: Variables of σ in SimpleGate(X, Y) = X⊙σ(Y)
5.2 Applications
We apply NAFNet to various image restoration tasks, and if not specified, follow the training settings from the ablation study, except increasing its width from 32 to 64. The batch size and total number of training iterations are 64 and 400K, respectively, as follows [5]. Applies a random crop boost. We report the average of the results of three experiments. For better results, the baseline is enlarged, see Appendix for details.
RGB Image Denoising We compare RGB image denoising results with other SOTA methods on SIDD, as shown in Table 6. Baseline and its simplified version, NAFNet, surpass the previous best result Restorer by 0.28 dB at a fraction of its computational cost, as shown in Figure 1. Qualitative results are shown in Figure 5. Compared with other methods, our proposed baseline can recover finer details. Furthermore, we achieve a SOTA result of 40.15 dB on an online benchmark, surpassing the previous top-ranked method by 0.23 dB.
Image Deblurring We compare the deblurring results of SOTA methods on the GoPro [26] dataset with flip and rotation augmentation. As shown in Table 7 and Figure 1, the PSNR of our baseline and NAFNet outperforms the previous best method MPRNet-local [8] by 0.09 dB and 0.38 dB respectively, while only 8.4% of its computational cost. The visualization results are shown in Fig. 6, and our baseline can recover clearer results compared to other methods.

Figure 6 Qualitative comparison of image deblurring methods on GoPro [26]

Table 6 SIDD image denoising results [1]
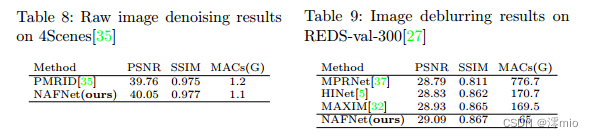
Raw Image Denoising We apply NAFNet to the task of raw image denoising. The training and testing settings follow PMRID [35], and for simplicity, we denote the testing set as 4Scenes (since the dataset contains 39 raw images of 4 different scenes under different lighting conditions). Furthermore, we make the computational cost lower than PMRID by changing the width and number of blocks of NAFNet from 32 to 16 and 36 to 7 for a fair comparison, respectively. The results shown in Table 8 and Figure 7 show that NAFNet can outperform PMRID quantitatively and qualitatively. Furthermore, this experiment shows that our NAFNet can be flexibly scaled (from 1.1 gmac to 65 gmac).
Image Deblurring with JPEG artifacts We conduct experiments on the REDS [27] dataset, the training set is as follows [5, 32], and we evaluate the results on 300 images in the validation set (denoted as red-val-300) [5, 32]. As shown in Table 9, our method outperforms other competing methods, including the previous winning scheme (HINet) [27] on the red dataset of the NTIRE 2021 image deblurring challenge Track2 JPEG artifacts.

Table 7 GoPro image deblurring effect [26]

Figure 7: Qualitative comparison of the denoising performance of PMRID [35] and our NAFNet. zoom in for details
6 Conclusions
By decomposing the SOTA method, the basic components are extracted and applied to the plain PlainNet. The resulting baseline achieves state-of-the-art performance on image denoising and deblurring tasks. Through the analysis of the baseline, we found that it can be further simplified: the non-linear activation function can be completely replaced or removed. On this basis, we propose a nonlinear non-activation network - NAFNet. Although simplified, its performance is equal to or better than the baseline. The baseline we propose may help researchers evaluate their ideas. Furthermore, this work has the potential to influence future computer vision model design, as we demonstrate that non-linear activation functions are not necessary to achieve SOTA performance.
Acknowledgments: This research was supported by the National Key Research and Development Program (No. 2017YFA0700800) and the Beijing Institute of Artificial Intelligence (BAAI).
Appendix
A Other Details
A.1 Inverted Bottleneck
Following [23], we adopt the inverted bottleneck design in the baseline and NAFNet. We first discuss the background of ablation studies. In the baseline, the channel width in the first skip connection is always the same as the input, and its computational cost can be approximated as:
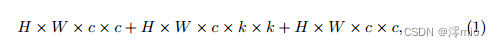
where H, W are the spatial size of the feature map, c is the input dimension, and k is the kernel size of the depthwise convolution (3 in our experiment). In practice, c is higher than k, so it is Eqn. (1)≈2 × H × W × c × c, the hidden dimension of the second job-hopping connection is twice the input dimension, and the calculation cost is:
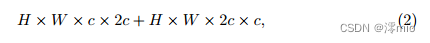
notations following Eqn. (1). Therefore, a baseline block’s The total calculation cost ≈6 × H × W × c × c
As for the blocks of NAFNet, the SimpleGate module reduces the channel width by half. We double the hidden dimension of the first skip connection with a computational cost approximated by:
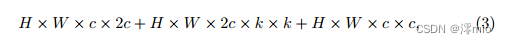
notations following Eqn. (1)... and the hidden dimension of the second skip connection follows the baseline. Its computational cost is:
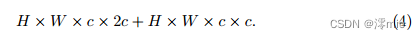
Therefore, the total computational cost of a NAFNet block is ≈6 × H × W × c × c, which is consistent with the block of the baseline. The advantage of this is that the baseline and NAFNet can share hyperparameters, such as the number of blocks, learning rate, etc.
For the application, the hidden dimension of the first skip connection of the baseline is extended for better results. In addition, it should be noted that the above discussion omits the calculation of some modules, such as layer normalization, GELU, channel attention, etc., because their computational cost is negligible compared with convolution.

A.2 Channel Attention and Simplified Channel Attention
For a feature map of width c, the channel attention module downscales it by a factor of r and then projects it back to c (via a fully connected layer). The computational cost can be approximated as c × c/r + c/r × c. For the simplified channel attention module, the computational cost is c × c. For a fair comparison, we choose r = 2 so that their computational cost in experiments The cost is consistent.
A.3 Feature Fusion
There are skip connections from the encoder block to the decoder block, and there are several ways to fuse encoder/decoder features. In [5], the encoder features are transformed by convolution and then concatenated with the decoder features. In [39], the features are first concatenated and then transformed by convolution. The difference is that we simply add encoder and decoder features element-wise as a feature fusion method.
A.4 Downsample/Upsample Layer
For the downsample layer, we use a convolution with a kernel size of 2 and a stride of 2. This design choice was inspired by [2]. For the upsampling layer, we first double the channel width by pointwise convolution, and then follow the pixel scrubbing module [31].
B More Visualization Results
We provide additional visualization results for raw image denoising, image deblurring, and RGB image denoising tasks, as shown in Figures 1, 2, and 3. Compared with other methods, our baseline can recover finer details. It is recommended to zoom in and compare the details in the red box.
References
-
Abdelhamed, A., Lin, S., Brown, M.S.: A high-quality denoising dataset for smartphone cameras. In: IEEE Conference on Computer Vision and Pattern Recognition
(CVPR) (June 2018) -
Alsallakh, B., Kokhlikyan, N., Miglani, V., Yuan, J., Reblitz-Richardson, O.: Mind
the pad–cnns can develop blind spots. arXiv preprint arXiv:2010.02178 (2020) -
Ba , JL , Kiros , JR , Hinton , GE : Layer normalization . arXiv preprint
arXiv:1607.06450 (2016) -
Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao,
W.: Pre-trained image processing transformer. In: Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition. pp. 12299–12310 (2021) -
Chen, L., Lu, X., Zhang, J., Chu, X., Chen, C.: Hinet: Half instance normalization
network for image restoration. In: Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition. pp. 182–192 (2021) -
Cheng, S., Wang, Y., Huang, H., Liu, D., Fan, H., Liu, S.: Nbnet: Noise basis learning for image denoising with subspace projection. In: Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4896–
4906 (2021) -
Cho, S.J., Ji, S.W., Hong, J.P., Jung, S.W., Ko, S.J.: Rethinking coarse-to-fine approach in single image deblurring. In: Proceedings of the IEEE/CVF International
Conference on Computer Vision. pp. 4641–4650 (2021) -
Chu, X., Chen, L., , Chen, C., Lu, X.: Improving image restoration by revisiting
global information aggregation. arXiv preprint arXiv:2112.04491 (2021) -
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q.V., Salakhutdinov, R.:
Transformer-xl: Attentive language models beyond a fixed-length context. arXiv
preprint arXiv:1901.02860 (2019) -
Dauphin, Y.N., Fan, A., Auli, M., Grangier, D.: Language modeling with gated
convolutional networks. In: International conference on machine learning. pp. 933– -
PMLR (2017)
-
De, S., Smith, S.: Batch normalization biases residual blocks towards the identity
function in deep networks. Advances in Neural Information Processing Systems
33, 19964–19975 (2020) -
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner,
T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is
worth 16x16 words: Transformers for image recognition at scale. arXiv preprint
arXiv:2010.11929 (2020) -
Han, Q., Fan, Z., Dai, Q., Sun, L., Cheng, M.M., Liu, J., Wang, J.: Demystifying
local vision transformer: Sparse connectivity, weight sharing, and dynamic weight.
arXiv preprint arXiv:2106.04263 (2021) -
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In:
Proceedings of the IEEE conference on computer vision and pattern recognition.
pp. 770–778 (2016) -
Hendrycks, D., Gimpel, K.: Gaussian error linear units (gelus). arXiv preprint
arXiv:1606.08415 (2016) -
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the
IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018) -
Hua, W., Dai, Z., Liu, H., Le, Q.V.: Transformer quality in linear time. arXiv
preprint arXiv:2202.10447 (2022) -
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by
reducing internal covariate shift. In: International conference on machine learning.
pp. 448–456. PMLR (2015) -
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint
arXiv:1412.6980 (2014) -
Liang, J., Cao, J., Fan, Y., Zhang, K., Ranjan, R., Li, Y., Timofte, R., Van Gool,
L.: Vrt: A video restoration transformer. arXiv preprint arXiv:2201.12288 (2022) -
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image
restoration using swin transformer. In: Proceedings of the IEEE/CVF International
Conference on Computer Vision. pp. 1833–1844 (2021) -
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin
transformer: Hierarchical vision transformer using shifted windows. In: Proceedings
of the IEEE/CVF International Conference on Computer Vision. pp. 10012–10022
(2021) -
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for
the 2020s. arXiv preprint arXiv:2201.03545 (2022) -
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts.
arXiv preprint arXiv:1608.03983 (2016) -
Mao, X., Liu, Y., Shen, W., Li, Q., Wang, Y.: Deep residual fourier transformation
for single image deblurring. arXiv preprint arXiv:2111.11745 (2021) -
Nah, S., Hyun Kim, T., Mu Lee, K.: Deep multi-scale convolutional neural network
for dynamic scene deblurring. In: Proceedings of the IEEE conference on computer
vision and pattern recognition. pp. 3883–3891 (2017) -
Nah, S., Son, S., Lee, S., Timofte, R., Lee, K.M.: Ntire 2021 challenge on image
deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition. pp. 149–165 (2021) -
Nair, V., Hinton, G.E.: Rectified linear units improve restricted boltzmann machines. In: Icml (2010)
-
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing
and computer-assisted intervention. pp. 234–241. Springer (2015) -
Shazeer, N.: Glu variants improve transformer. arXiv preprint arXiv:2002.05202
(2020) -
Shi, W., Caballero, J., Husz´ar, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert,
D., Wang, Z.: Real-time single image and video super-resolution using an efficient
sub-pixel convolutional neural network. In: Proceedings of the IEEE conference on
computer vision and pattern recognition. pp. 1874–1883 (2016) -
Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik, A., Li, Y.: Maxim:
Multi-axis mlp for image processing. arXiv preprint arXiv:2201.02973 (2022) -
Ulyanov, D., Vedaldi, A., Lempitsky, V.: Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022 (2016)
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser,
ÙL., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017) -
Wang, Y., Huang, H., Xu, Q., Liu, J., Liu, Y., Wang, J.: Practical deep raw image
denoising on mobile devices. In: European Conference on Computer Vision. pp.
1–16. Springer (2020) -
Wang, Z., Cun, X., Bao, J., Liu, J.: Uformer: A general u-shaped transformer for
image restoration. arXiv preprint arXiv:2106.03106 (2021) -
Waqas Zamir, S., Arora, A., Khan, S., Hayat, M., Shahbaz Khan, F., Yang, M.H.,
Shao, L.: Multi-stage progressive image restoration. arXiv e-prints pp. arXiv–2102
(2021) -
Yan, J., Wan, R., Zhang, X., Zhang, W., Wei, Y., Sun, J.: Towards stabilizing
batch statistics in backward propagation of batch normalization. arXiv preprint
arXiv:2001.06838 (2020) -
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.:
Restormer: Efficient transformer for high-resolution image restoration. arXiv
preprint arXiv:2111.09881 (2021) -
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.:
Learning enriched features for real image restoration and enhancement. In: European Conference on Computer Vision. pp. 492–511. Springer (2020)