Article directory
0 Ideas for the competition
(Share on CSDN as soon as the competition questions come out)
https://blog.csdn.net/dc_sinor?type=blog
1 Algorithm introduction
The full name of the FP-Tree algorithm is the FrequentPattern Tree algorithm, which is the frequent pattern tree algorithm. Like the Apriori algorithm, it is also used to mine frequent itemsets, but the difference is that the FP-Tree algorithm is an optimization process of the Apriori algorithm. It solves the Apriori The algorithm will generate a large number of candidate sets in the process, while the FP-Tree algorithm finds frequent patterns without generating candidate sets. But after the frequent patterns are mined, the steps to generate association rules are still the same as Apriori.
There are two common algorithms for mining frequent itemsets, one is Apriori algorithm and the other is FP-growth. Apriori mines frequent itemsets by continuously constructing candidate sets and screening candidate sets. It needs to scan the original data multiple times. When the original data is large, the disk I/O times are too many and the efficiency is relatively low. FPGrowth is different from Apriori's "probing" strategy. The algorithm only needs to scan the original data twice, and compress the original data through the FP-tree data structure, which is more efficient.
FP stands for Frequent Pattern, and the algorithm is mainly divided into two steps: FP-tree construction and mining of frequent itemsets.
2 FP tree representation
The FP tree is constructed by reading in transactions one by one and mapping the transactions to a path in the FP tree. Since different transactions may have several identical items, their paths may partially overlap. The more the paths overlap each other, the better the compression effect obtained by using the FP tree structure; if the FP tree is small enough to be stored in memory, frequent itemsets can be extracted directly from the structure in memory without having to repeatedly scan the stored in data on the hard drive.
An FP tree is shown in the figure below:
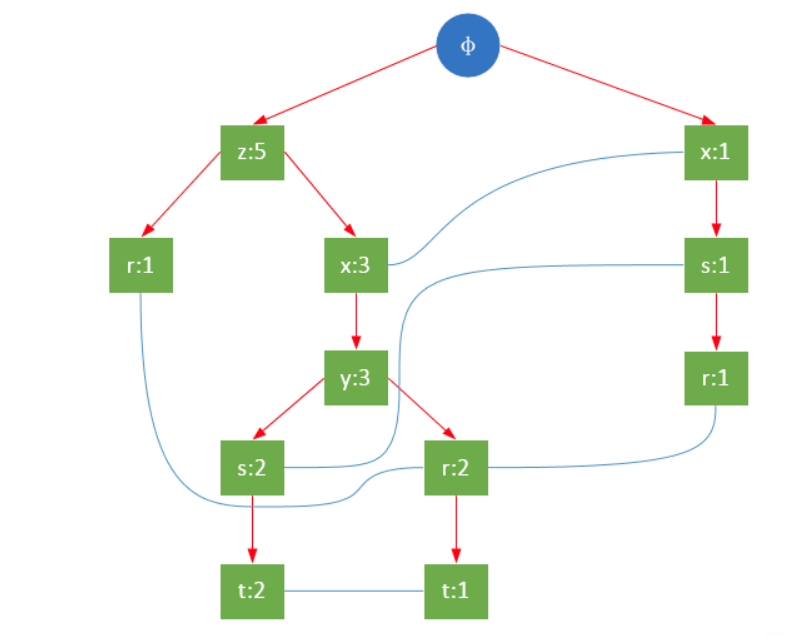
Usually, the size of the FP tree is smaller than that of uncompressed data, because the transactions of the data often share some common items. In the best case, all transactions have the same item set, FP The tree contains only one node path; when each transaction has a unique itemset, leading to the worst case, since the transactions do not contain any common items, the size of the FP tree is effectively the same as the size of the original data.
The root node of the FP tree is represented by φ, and the remaining nodes include a data item and the support of the data item on this path; each path is a data item set that meets the minimum support in the training data; the FP tree also includes all The same items are connected into a linked list, which is represented by a blue line in the above figure.
In order to quickly access the same item in the tree, it is also necessary to maintain a pointer list (headTable) that connects nodes with the same item. Each list element includes: data item, the global minimum support of the item, and a link list pointing to the item in the FP tree pointer of the header.
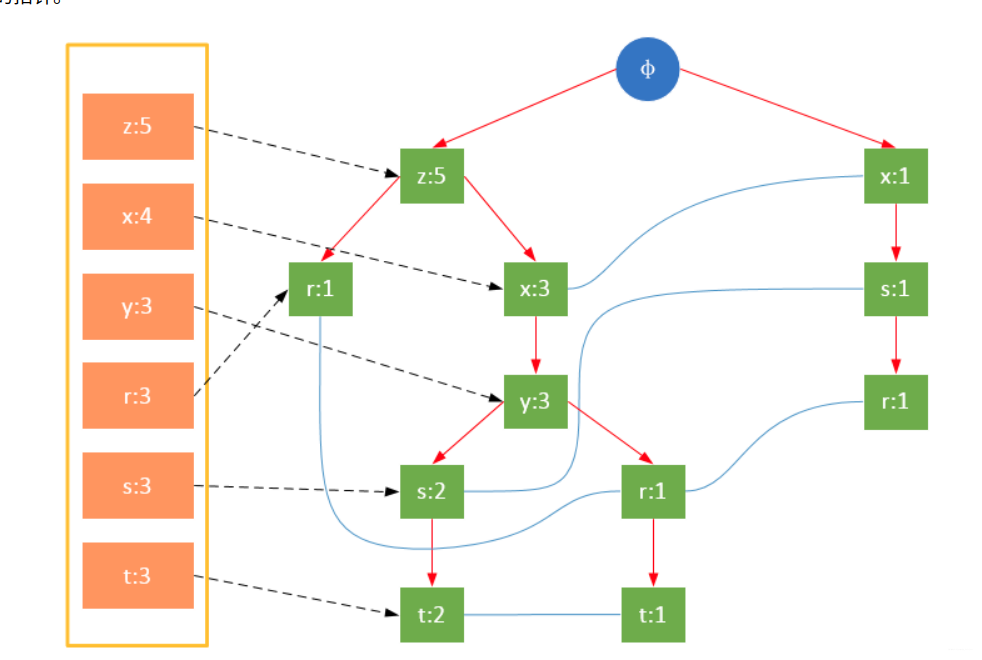
3 Build FP tree
Now have the following data:
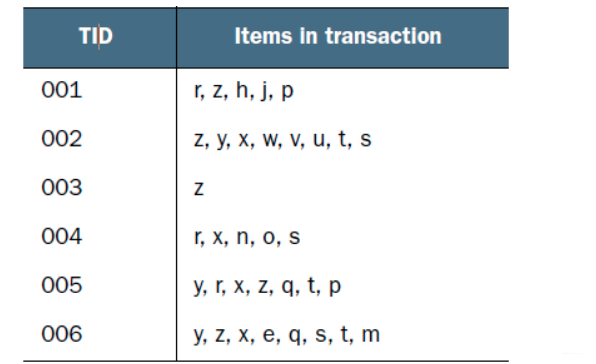
The FP-growth algorithm needs to scan the original training set twice to build the FP tree.
In the first scan, all items that do not meet the minimum support are filtered out; for items that meet the minimum support, they are sorted according to the global minimum support. On this basis, for the convenience of processing, they can also be sorted again according to the keywords of the items.
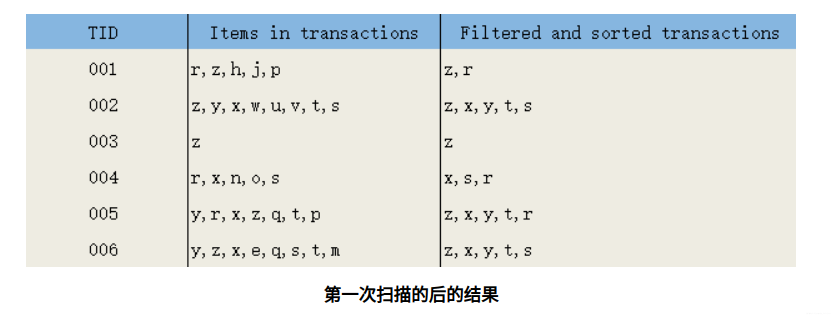
The second scan constructs the FP tree.
Participate in the scanning is the filtered data. If a data item is encountered for the first time, create the node and add a pointer to the node in the headTable; otherwise find the node corresponding to the item according to the path and modify the node information. The specific process is as follows:
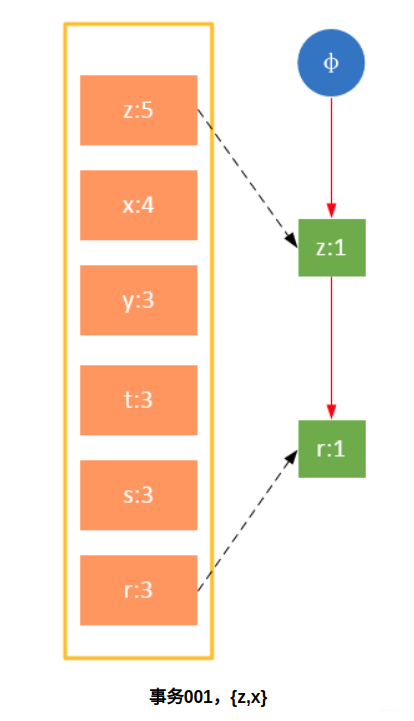
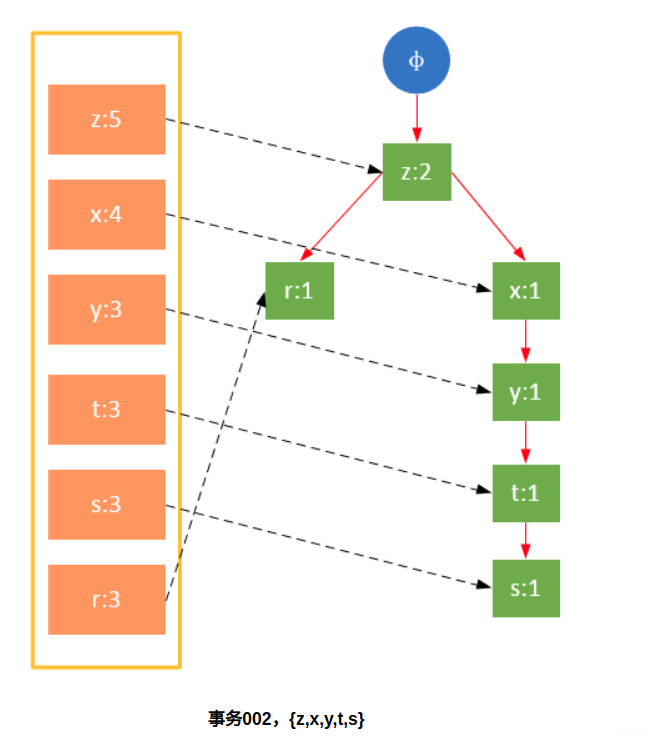
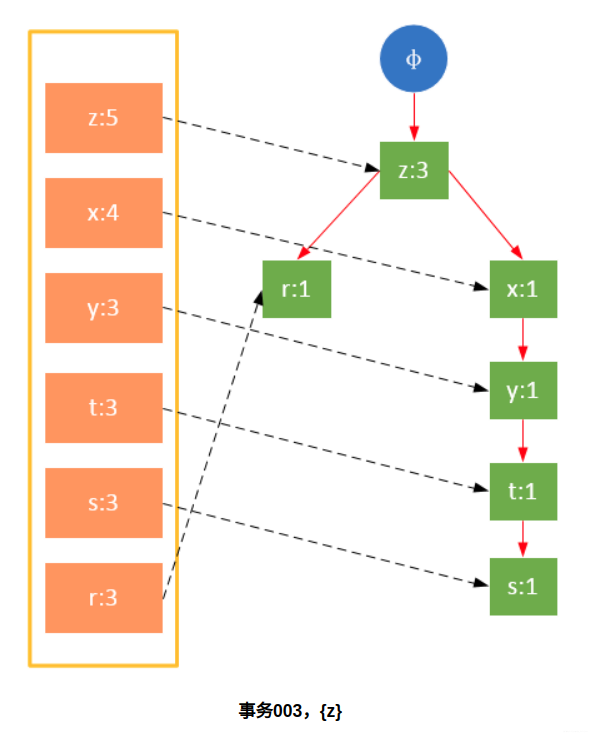
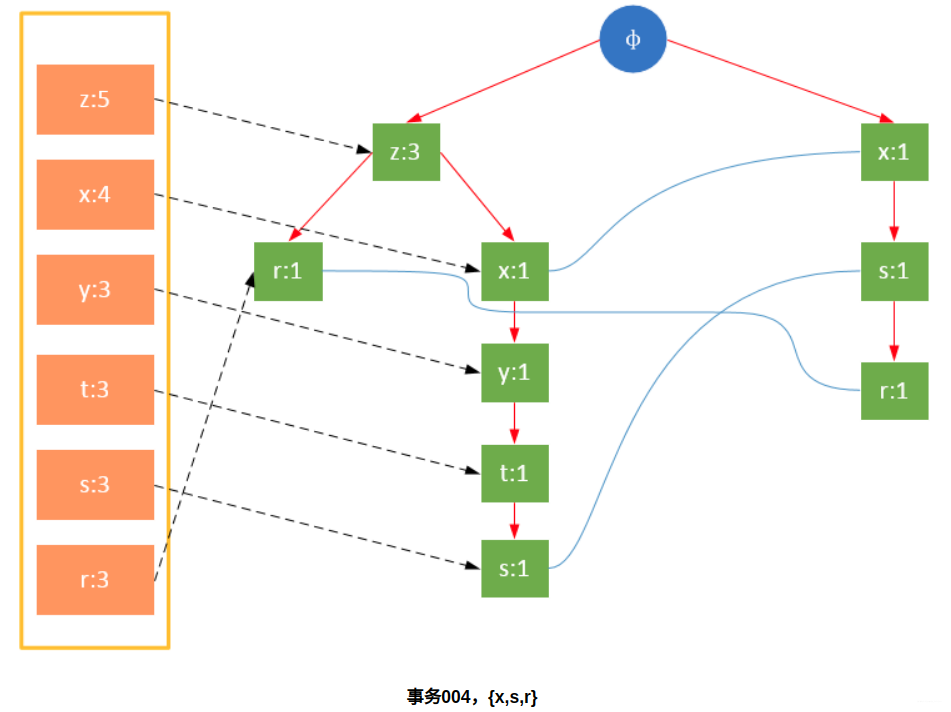
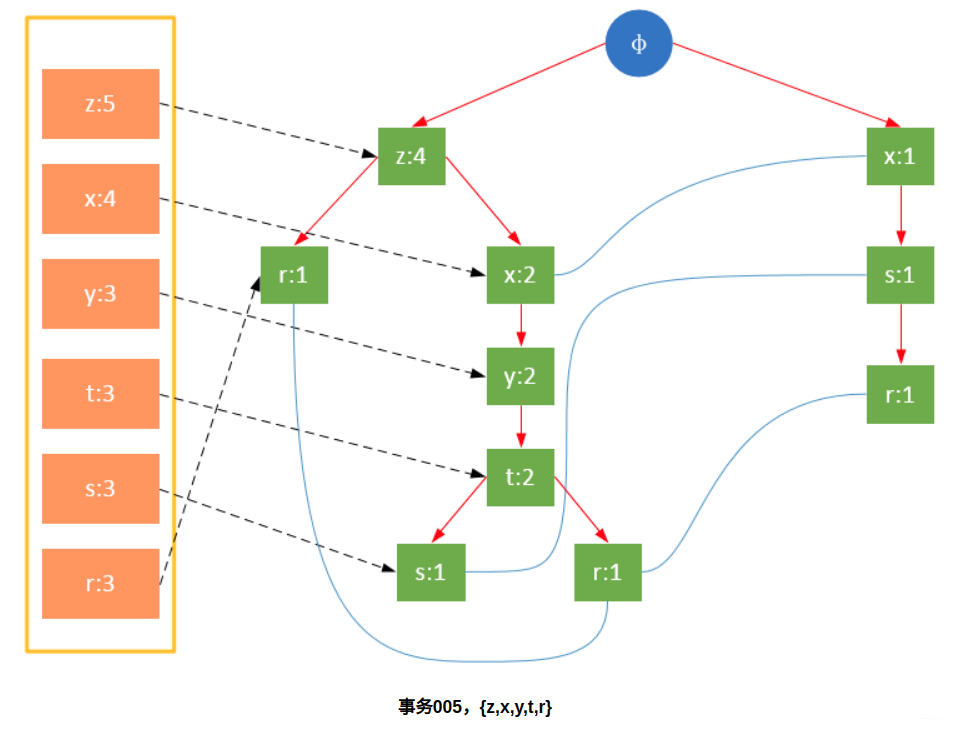
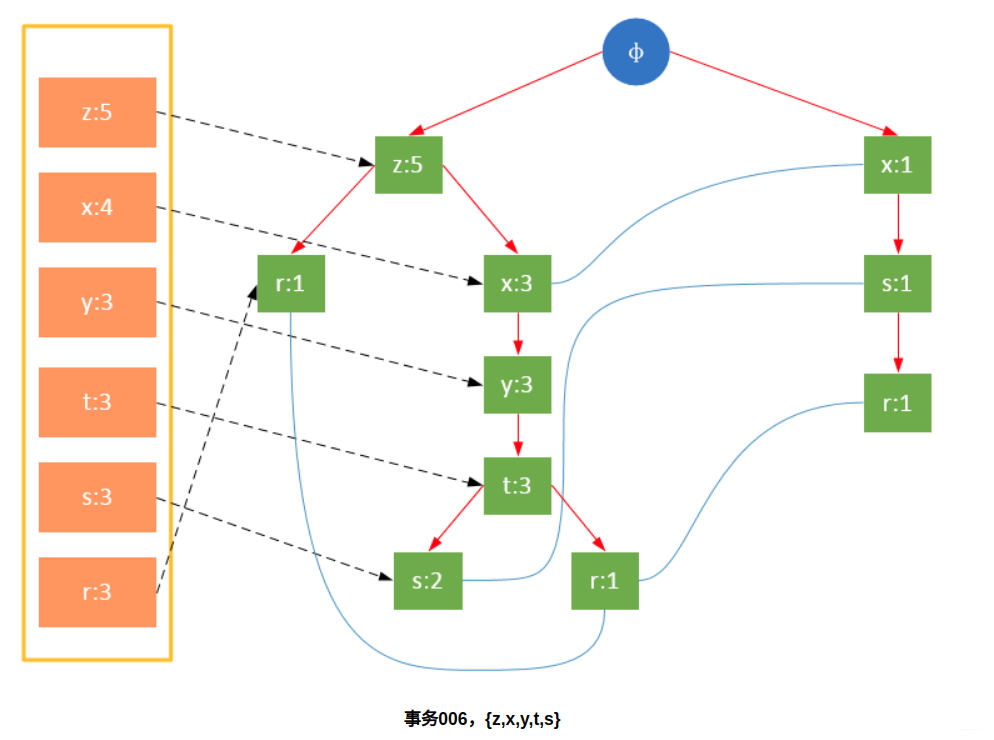
It can be seen from the above that the headTable is not created together with the FPTree, but has been created during the first scan. When creating the FPTree, you only need to point the pointer to the corresponding node. Starting from transaction 004, it is necessary to create a connection between nodes so that the same items on different paths are connected into a linked list.
4 Implementation code
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {
}
for trans in dataSet:
fset = frozenset(trans)
retDict.setdefault(fset, 0)
retDict[fset] += 1
return retDict
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {
}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print(' ' * ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind + 1)
def createTree(dataSet, minSup=1):
headerTable = {
}
#此一次遍历数据集, 记录每个数据项的支持度
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + 1
#根据最小支持度过滤
lessThanMinsup = list(filter(lambda k:headerTable[k] < minSup, headerTable.keys()))
for k in lessThanMinsup: del(headerTable[k])
freqItemSet = set(headerTable.keys())
#如果所有数据都不满足最小支持度,返回None, None
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None]
retTree = treeNode('φ', 1, None)
#第二次遍历数据集,构建fp-tree
for tranSet, count in dataSet.items():
#根据最小支持度处理一条训练样本,key:样本中的一个样例,value:该样例的的全局支持度
localD = {
}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
#根据全局频繁项对每个事务中的数据进行排序,等价于 order by p[1] desc, p[0] desc
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: (p[1],p[0]), reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children: # check if orderedItems[0] in retTree.children
inTree.children[items[0]].inc(count) # incrament count
else: # add items[0] to inTree.children
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None: # update header table
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1: # call updateTree() with remaining ordered items
updateTree(items[1:], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode): # this version does not use recursion
while (nodeToTest.nodeLink != None): # Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()
The above code does not sort the filtered items of each training data after the first scan, but puts the sorting in the second scan, which can simplify the complexity of the code.
Console information:
