1 Introduction
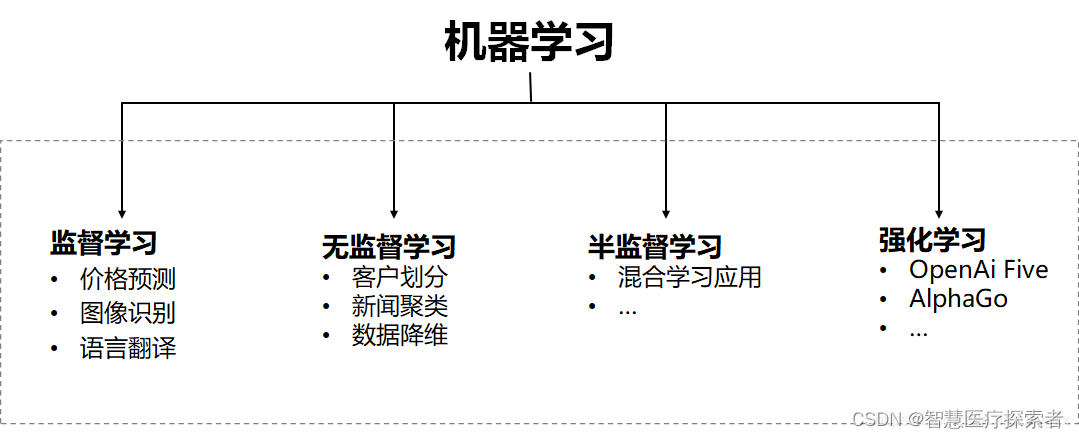
Machine learning is a technique in the field of artificial intelligence that aims to allow computers to perform tasks by learning from data and patterns, rather than being explicitly programmed. Machine learning is divided into four types: Supervised Learning, Unsupervised Learning, Semi-supervised Learning, and Reinforcement Learning. The following describes each learning method in detail.
2 Supervised learning
2.1 What is supervised learning
Definition: According to the existing data set, know the relationship between the input and output results. According to this known relationship, an optimal model is obtained through training.
In supervised learning, the training data has both features and labels . Through training, the machine can find the connection between features and labels by itself. When faced with data with only features and no labels, it can judge the labels. .
Simple understanding: Supervised learning can be understood as we teach machines how to do things .

2.2 Categories of Supervised Learning
Supervised learning tasks mainly include two types of classification and regression. In supervised learning, the samples in the data set are called "training samples", and each sample has an input feature and a corresponding label (classification task) or target value ( return task). .
-
Classification: In classification tasks, the goal is to classify input data into predefined categories. Each category has a unique label. During the training phase, the algorithm builds a model by learning the relationship between the features of the data and the labels. Then, during the testing phase, the model is used to predict class labels on unseen data. For example, label emails as "spam" or "not spam," and recognize images as "cat" or "dog."
-
Regression: In a regression task, the goal is to predict a continuous numerical output. Unlike classification, output labels are continuous in regression tasks. Algorithms build models during the training phase by learning the relationship between input features and corresponding continuous outputs. During the testing phase, the model is used to predict output values on unseen data. For example, predicting the selling price of houses, predicting sales volume, etc.
2.3 Common Supervised Learning Algorithms
There are many types of supervised learning algorithms, which have extremely wide applications. The following are some common supervised learning algorithms:
-
Support Vector Machine (SVM): SVM is a powerful algorithm for binary and multi-classification tasks. It separates different classes of data by finding an optimal hyperplane. SVMs perform well in high-dimensional spaces and can be applied to both linear and nonlinear classification problems.
-
Decision Trees: A decision tree is a classification and regression algorithm based on a tree structure. It performs classification or prediction by making recursive binary decisions on features. Decision trees are easy to understand and interpret, and have good adaptability to data processing.
-
Logistic Regression: Logistic regression is a linear model widely used in binary classification problems. Despite the "regression" in the name, it is mainly used for classification tasks. Logistic regression outputs predicted probabilities and uses a logistic function to map the continuous output to the range [0, 1].
-
K-Nearest Neighbors (KNN): KNN is an instance-based learning method. It classifies or regresses new samples according to the distance metric. KNN uses the labels of the closest K training samples to determine the category of new samples.
1.4 Application scenarios of supervised learning
Supervised learning is one of the most common machine learning methods and has a wide range of applications in various fields. Its success is largely due to its ability to learn from labeled data and learn from unseen data. Make predictions and generalize.
-
Image recognition: Supervised learning is very common in image recognition tasks. For example, classifying images into different objects, scenes, or actions, or doing object detection to find out where a specific object is in an image.
-
Natural Language Processing: In natural language processing tasks, supervised learning is used for text classification, sentiment analysis, machine translation, named entity recognition, etc.
-
Speech Recognition: Supervised learning is widely used in the field of speech recognition, such as converting speech to text, speaker identification, etc.
-
Medical diagnosis: In the medical field, supervised learning can be used for disease diagnosis, image analysis, drug discovery, etc.
3 Unsupervised Learning
3.1 What is unsupervised learning
Definition: We don't know the relationship between the data and features in the dataset, but we need to get the relationship between the data according to clustering or a certain model.
In unsupervised learning, the data has only features (feature) and no label (label) , which is a training method of machine learning. It is essentially a statistical method, and a training method in which some potential structures can be found in unlabeled data. Way.
Simple understanding: Compared with supervised learning, unsupervised learning is more like self-study, allowing machines to learn to do things by themselves.

3.2 Categories of Unsupervised Learning
Unsupervised learning is characterized by having no labels or target values in the training data. The goal of unsupervised learning is to discover hidden structures and patterns from data, not to predict specific labels or targets. The main categories of unsupervised learning include the following:
-
Clustering: Clustering is the process of dividing data samples into similar groups or clusters. It clusters similar samples together by computing a similarity measure between samples. Clustering is one of the most common tasks in unsupervised learning, often used in data analysis, market segmentation, image segmentation, etc.
-
Dimensionality Reduction: Dimensionality reduction is the process of converting high-dimensional data into a low-dimensional representation while preserving the characteristics of the data as much as possible. Dimensionality reduction techniques can reduce the complexity of data, remove redundant information, and can be used for data visualization, feature extraction, etc. Common dimensionality reduction methods include principal component analysis (PCA) and t-SNE.
-
Association Rule Mining: Association rule mining is used to discover associations and frequent itemsets between items in a dataset. These rules describe the correlation between different items in the data set, and are usually widely used in market basket analysis, shopping recommendation, etc.
-
Anomaly Detection: Anomaly detection is used to identify rare or unusual data points that differ from the majority of samples. It has important applications in detecting anomalous events, fraud detection, fault detection, etc.
Unsupervised learning plays an important role in data mining, pattern recognition, feature learning and other fields. By discovering structures and patterns in data, unsupervised learning helps us better understand data, extract useful information from it, and provide a beneficial preprocessing step for other tasks.
3.3 Common Unsupervised Learning Algorithms
Unsupervised learning algorithms have a wide range of applications on different problems and datasets. They help us discover useful structures and patterns from unlabeled data, and play an important role in data processing, visualization, clustering, dimensionality reduction, and other tasks. Here are some common unsupervised learning algorithms:
-
K-Means Clustering (K-Means Clustering): K-Means clustering is a commonly used clustering algorithm, which divides data samples into K clusters so that the distance between each sample and the center of the cluster it belongs to is minimized.
-
Principal Component Analysis (PCA): PCA is a commonly used dimensionality reduction algorithm that projects high-dimensional data into a low-dimensional space through linear transformation to preserve the most important features.
-
Association Rule Mining (Association Rule Mining): Association rule mining is a method to discover the correlation between items in a data set. It is often used in market basket analysis, shopping recommendation and other fields.
-
Anomaly Detection: Anomaly detection algorithms are used to identify rare or unusual data points that differ from the majority of samples. Common methods include statistics-based methods, cluster-based methods, and generative model-based methods.
3.4 Application scenarios of unsupervised learning
Unsupervised learning plays an important role in data mining, pattern recognition, feature learning and other application scenarios. Through unsupervised learning, we can gain useful information and insights from unlabeled data, provide beneficial preprocessing steps for other tasks, and help to better understand and utilize data. :
-
Clustering and grouping: Clustering algorithms in unsupervised learning can help divide data samples into similar groups or clusters, such as dividing customers into different groups in market segmentation, dividing image regions into different groups in image segmentation objects etc.
-
Feature Learning and Dimensionality Reduction: Dimensionality reduction algorithms for unsupervised learning such as PCA and t-SNE can be used for feature learning and visualization of high-dimensional data, such as in image, audio, and natural language processing, as well as for data compression and visualization.
-
Anomaly Detection: Anomaly detection algorithms in unsupervised learning can be used to find rare or unusual data points that are different from the majority of data samples. This has important applications in scenarios such as fraud detection, fault detection, and abnormal event monitoring.
-
Association rule mining: The unsupervised learning association rule mining algorithm can be used to discover the correlation between items in the data set, and is often used in market basket analysis, shopping recommendation and other fields.
4 Semi-supervised learning
4.1 What is semi-supervised learning
Definition: The goal of semi-supervised learning is to use both labeled and unlabeled data to build a model that enables the model to generalize better to new, unseen data during the testing phase.
Semi-supervised learning is between supervised learning and unsupervised learning. In semi-supervised learning, the training data contains both labeled and unlabeled data.
Different from supervised learning, only a small part of the training data in semi-supervised learning is labeled, while most of the samples are unlabeled. Typically, it can be expensive or time-consuming to acquire labeled data, whereas it is relatively easy and cheap to acquire unlabeled data.
In semi-supervised learning, unlabeled data can play two important roles:
-
Leverage information from unlabeled data: Unlabeled data may contain useful information about data distribution, structure, and hidden features, which can help the model generalize better.
-
Exploiting the propagation effect of labeled data: By exploiting the data distribution similarity between labeled data and unlabeled data, the performance of the model can be enhanced by propagating label information to unlabeled samples.
Semi-supervised learning is a very interesting and challenging problem that has practical applications in many real-world scenarios. By making full use of unlabeled data, semi-supervised learning can significantly improve the performance of models in some cases, and it helps to build more robust and generalizable machine learning models with limited data.

4.2 Categories of Semi-Supervised Learning
Semi-supervised learning is a learning method between supervised learning and unsupervised learning. It uses a training set that contains both labeled and unlabeled data to build a model. The categories of semi-supervised learning are mainly divided into the following categories:
-
Semi-supervised classification (Semi-supervised Classification): In semi-supervised classification, the training data contains both labeled samples and unlabeled samples. The goal of the model is to use this label information and the distribution information of the unlabeled data to improve the classification performance. Semi-supervised classification algorithms can use unlabeled data in classification tasks to expand the labeled data set, thereby improving the accuracy of the model.
-
Semi-supervised Regression: Semi-supervised regression tasks are similar to semi-supervised classification, but applied to regression problems. The model is trained on both labeled and unlabeled data to improve regression prediction accuracy on unlabeled data.
-
Semi-supervised Clustering: Semi-supervised clustering algorithms use both labeled and unlabeled data for clustering tasks. They can better identify potential cluster structures by combining similarity information and label information of data.
-
Semi-supervised Anomaly Detection: The semi-supervised anomaly detection task aims to detect anomalies with limited label information from data containing both normal and abnormal samples. This is especially useful when there are few outlier samples.
-
Semi-supervised learning in Generative Adversarial Networks (GANs): GANs can be used to implement semi-supervised learning. In this case, the generator and discriminator networks can use both labeled and unlabeled samples to improve the performance of the generative model.
Semi-supervised learning is a challenging learning paradigm because it needs to make full use of unlabeled data while also preventing overfitting on unlabeled data. In practical applications, according to the nature of the problem and the available data, selecting appropriate semi-supervised learning methods and techniques can help improve model performance and generalization capabilities.
4.3 Common semi-supervised learning algorithms
Semi-supervised learning algorithms can work on different problems and datasets. Choosing an appropriate semi-supervised learning algorithm depends on the nature of the problem, the amount of labeled and unlabeled data available, and the performance and complexity requirements of the algorithm. Semi-supervised learning has important application value in scenarios where processing data is limited or data labeling is expensive. Here are some common semi-supervised learning algorithms:
-
Self-Training: Self-training is a simple semi-supervised learning method. It works by training an initial model with labeled data, then using that model to make predictions on unlabeled data, using the more confident predictions as pseudo-labels, adding the unlabeled data to the labeled data, and then retraining the model .
-
Co-Training: Co-Training is a semi-supervised learning method that uses multiple views or features. It works by partitioning the data into two or more views and training a model on each view independently. The models then interact with each other and use each other's predictions to augment training.
-
Semi-Supervised Support Vector Machines (Semi-Supervised Support Vector Machines): Semi-supervised support vector machines are semi-supervised learning methods based on support vector machines. It exploits the relationship between labeled and unlabeled data to learn a better classifier.
-
Generative Semi-Supervised Learning: These methods try to use generative models to model the distribution of data, and use labeled and unlabeled data to jointly train the generative model to improve the prediction of unlabeled data.
-
Semi-supervised deep learning: In recent years, many deep learning methods have been extended to semi-supervised learning. These methods exploit the information of unlabeled data by introducing semi-supervised properties in deep neural networks, such as semi-supervised autoencoders (Semi-Supervised Autoencoders).
-
Graph-based Semi-Supervised Learning: Graph-based Semi-Supervised Learning methods use the relationship between data samples to assist semi-supervised learning. These methods typically utilize graphical models or graph convolutional neural networks (GCNs) to exploit the topology of the data.
4.4 Application scenarios of semi-supervised learning
Semi-supervised learning has important application value in many practical application scenarios, especially when the data is limited or the cost of data labeling is high. Here are some application scenarios of semi-supervised learning:
-
Natural Language Processing: In natural language processing tasks, obtaining large-scale labeled data is very expensive and time-consuming many times. Semi-supervised learning can utilize a small amount of labeled text data and a large amount of unlabeled text data to improve the performance of tasks such as text classification, sentiment analysis, and named entity recognition.
-
Image recognition and computer vision: In the field of image recognition and computer vision, it can also be difficult to obtain large-scale labeled image data. Semi-supervised learning can be trained on a small number of labeled images and a large number of unlabeled images to improve the accuracy of tasks such as image classification and object detection.
-
Data clustering: In clustering tasks, semi-supervised learning can combine labeled and unlabeled data for clustering, thereby improving the accuracy and stability of clustering results.
-
Medical Image and Diagnosis: In medical image analysis and diagnosis, obtaining large amounts of labeled medical image data can be difficult. Semi-supervised learning can be trained on a small number of labeled medical images and a large number of unlabeled medical images to improve the performance of tasks such as medical image segmentation and lesion detection.
-
Robot control: In the field of robot control, semi-supervised learning can help robots make autonomous decisions and learn in unknown environments, thereby improving their ability to perform tasks.
-
Image generation and data augmentation: In generative models, semi-supervised learning can combine labeled and unlabeled data to train models to improve the quality and diversity of generative models.
In these scenarios, semi-supervised learning can effectively use the information of unlabeled data to help improve model performance and generalization ability. However, semi-supervised learning also faces challenges, such as how to effectively utilize unlabeled data and avoid overfitting and imbalance problems. In practical applications, it is necessary to select a suitable semi-supervised learning method according to the specific problem and data situation.
5 Reinforcement Learning
5.1 What is Reinforcement Learning
Definition: Reinforcement learning is the process of having an agent (agent) learn behavioral strategies through trial and error in an environment. The agent adjusts its behavioral strategy according to the reward signal by interacting with the environment to achieve the goal of maximizing the cumulative reward.
In reinforcement learning, the agent is not explicitly told how to perform a task, but learns by trial and error. When the agent takes an action in the environment, the environment returns a reward signal indicating how good or bad the action was. The goal of the agent is to learn an optimal strategy by interacting with the environment to maximize its long-term accumulated rewards.
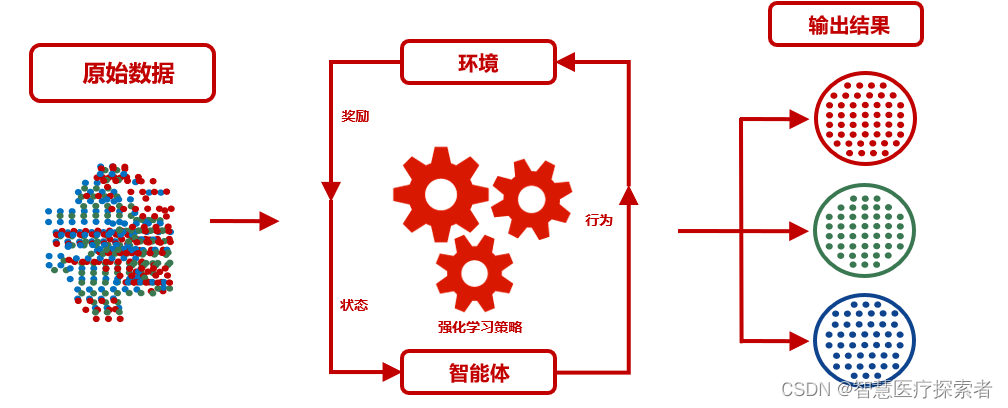
The process of reinforcement learning can be described as a continuous interaction process between the agent and the environment
(1) The agent observes the current state of the environment (state).
(2) Based on the current state, the agent chooses an action.
(3) The environment transitions to a new state according to the agent's actions and returns a reward signal (reward).
(4) The agent updates its policy based on the reward signal in order to obtain better rewards in future decisions.
(5) Repeat the above steps until the agent learns a strategy that enables it to obtain the maximum cumulative reward.
5.2 Categories of Reinforcement Learning
Reinforcement learning is a machine learning method that learns appropriate behavioral strategies to maximize cumulative rewards based on the agent's interactions with the environment. The categories of reinforcement learning can be mainly divided into the following categories:
-
Value-Based Reinforcement Learning (Value-Based Reinforcement Learning): Value-based reinforcement learning methods aim to learn the value function, that is, the value of a given state or state-action pair, representing the state or state-action pair of the agent. An estimate of the cumulative rewards that can be earned. These methods usually update the value function by using the Bellman equation or its variants, and use it to select actions.
-
Policy-Based Reinforcement Learning (Policy-Based Reinforcement Learning): Policy-based reinforcement learning methods directly learn the policy function, that is, the mapping from state to action. Policies can be deterministic (output only one action for each state) or probabilistic (output a probability distribution of actions for each state). These methods usually update the policy parameters through gradient ascent methods to maximize the cumulative reward.
-
Model-Based Reinforcement Learning (Model-Based Reinforcement Learning): Model-based reinforcement learning methods learn a model of the environment, that is, predict the next state and reward from the state and action. It can then use the learned model for planning and decision-making without actually interacting with the environment. This improves sample efficiency and planning efficiency.
-
Deep Reinforcement Learning: Deep reinforcement learning combines deep neural networks with reinforcement learning. It usually uses deep neural networks to approximate the value function or the policy function. Deep reinforcement learning excels at tasks in high-dimensional state and action spaces.
-
Multi-Agent Reinforcement Learning: Multi-Agent Reinforcement Learning studies the learning problems of multiple agents in an interactive environment. In this case, each agent's policy and actions affect the states and rewards of other agents, so learning becomes more complicated.
These are the main categories of reinforcement learning, and within each category there are many different algorithms and methods. Reinforcement learning has a wide range of applications in problems of autonomous decision-making and learning, such as autonomous driving, robot control, game play, etc.
5.3 Common Reinforcement Learning Algorithms
Reinforcement learning algorithms excel at different types of tasks and problems and play an important role in the field of autonomous decision-making and learning. They are commonly used to solve autonomous driving, robot control, game play, and other tasks that require decision-making and learning. Here are some common reinforcement learning algorithms:
-
Q-Learning: Q-Learning is a value-based reinforcement learning algorithm. It learns a value function (Q-function) to represent the cumulative reward of taking a certain action in a given state. Q-Learning uses the Bellman equation to update the Q value and uses a greedy strategy to select actions.
-
SARSA: SARSA is another value-based reinforcement learning algorithm. It is similar to Q-Learning, but the difference is that it uses the current policy's actions to update the Q value during both the learning and decision phases.
-
DQN (Deep Q Network): DQN is a deep reinforcement learning algorithm that combines deep neural networks and Q-Learning. It uses a deep neural network to approximate the Q function, and stabilizes the training with experience replay and a target network.
-
A3C (Asynchronous Advantage Actor-Critic): A3C is a policy-based reinforcement learning algorithm that combines Actor-Critic methods and asynchronous training. A3C uses multiple agents to train in parallel to improve sample efficiency.
-
PPO (Proximal Policy Optimization): PPO is a policy-based reinforcement learning algorithm that stabilizes training by limiting the update range. PPO has performed well in deep reinforcement learning and has been widely used in various tasks.
-
TRPO (Trust Region Policy Optimization): TRPO is another policy-based reinforcement learning algorithm that uses a method of limiting the step size to ensure that the update policy does not deteriorate performance.
5.4 Application Scenarios of Reinforcement Learning
Reinforcement learning has broad applications in many practical application scenarios, especially those tasks that require autonomous decision-making and learning. Reinforcement learning enables agents to learn from their interactions with the environment and make appropriate decisions based on the learned knowledge to achieve predetermined goals or maximize cumulative rewards. Due to the autonomous learning and decision-making properties of reinforcement learning, it has important application potential in many autonomous and intelligent systems. Here are some application scenarios of reinforcement learning:
-
Autonomous Driving: Reinforcement learning can be applied in the field of autonomous driving, enabling vehicles to make decisions based on the environment and traffic conditions, such as planning paths, avoiding obstacles, and obeying traffic rules.
-
Robot control: Reinforcement learning can help robots autonomously explore and learn in unknown environments to complete complex tasks such as navigation, grasping objects, and human-robot interaction.
-
Games: Reinforcement learning has a wide range of applications in game play. For example, using reinforcement learning to train an agent to play video games, Go, poker, etc., so that it can match or even surpass human players.
-
Medical treatment: Reinforcement learning can be applied in the medical field to personalize treatment and drug treatment decisions, making appropriate treatment plans based on the patient's condition and condition.
-
Speech recognition and natural language processing: Reinforcement learning can be applied to speech recognition and natural language processing tasks, enabling agents to better understand and generate natural language.