basic structure
Semi-supervised learning pseudo-label learning
https://blog.csdn.net/weixin_42764932/article/details/112910467 is
similar to pseudo-label learning
-
The pictures are labeled and unlabeled.
-
Using labeled data and standard cross-entropy loss, an EfficientNet is trained as a teacher network.
-
Use a teacher network that does not add noise to generate pseudo labels on unlabeled data. The pseudo labels can be soft labels (continuous distribution) or hard labels (one-hot distribution). The article says that soft labels work better.
-
Under labeled and unlabeled data, use cross entropy to train a student network with noise.
-
By treating the student network as a teacher network, iterate the above steps to generate new pseudo labels and train the student network.
The effect of adding noise to student models:
-
Data noise: It is well known to improve generalization ability. For example, the invariant of the same class of different images encourages the student model to surpass the teacher to learn, and use more different images to make the same prediction.
-
Model noise: Improve model robustness and generalization ability
Specific settings:
-
Random depth : The survival probability factor is 0.8
-
dropout: The classification layer introduces a drop rate of 0.5
-
Random enhancement: Two random operations are applied and the magnitude is set to 27
-
Data filtering: Filter the images with low confidence in the teacher model, because they usually represent out-of-domain images
-
Data balance: balance the number of images in different categories
-
The labels output by the teacher model use 1) soft labels (eg: [0.1,0.2,0.6,0.9]) or 2) hard labels (eg: [1,0,1,0,0,1]), which is shown by experiments , The soft label has a stronger guiding effect on the images outside the domain, so the author uses the soft label as the pseudo label format
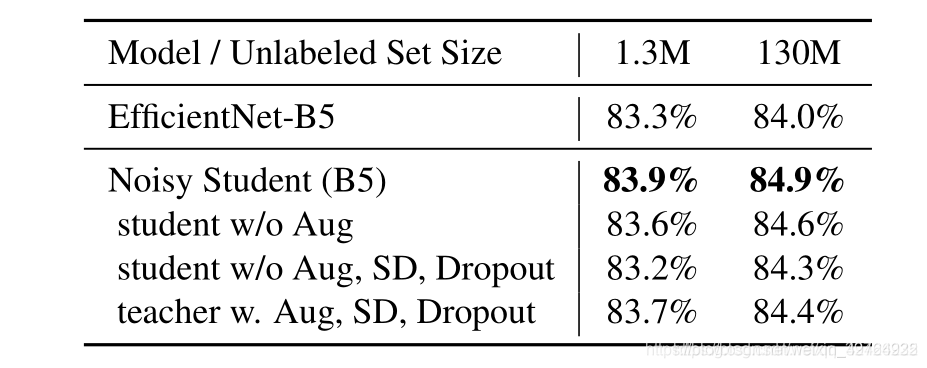
Noise, random depth, and data expansion play an important role in making the student model better than the teacher model. In this regard, some people asked whether to add a regular term to the unlabeled data to prevent overfitting instead of noise. The author explained in the experiment that this is wrong of. Because in the case of denoising, the training loss of the unlabeled image did not decrease much, which shows that the model did not overfit the unlabeled data.