BinGo: Cross-Architecture Cross-OS Binary Search [FSE 2016]
Mahinthan Chandramohan, Nanyang Technological University, Singapore
Yinxing Xue∗, Nanyang Technological University, Singapore
Zhengzi Xu, Nanyang Technological University, Singapore
Yang Liu, Nanyang Technological University, Singapore
Chia Yuan Cho, DSO National Laboratories, Singapore
Tan Hee Beng Kuan, Nanyang Technological University, Singapore
Binary code search has attracted extensive attention in recent years due to its applications in plagiarism detection, malware detection, software vulnerability auditing, etc. However, developing an effective binary code search tool is challenging because of the huge syntax and structure differences in binary codes caused by different compilers, architectures, and operating systems. In this paper, we present BINGO , a scalable and robust binary search engine that supports various architectures and operating systems. The key contribution is the selective inlining technique, which captures full function semantics by inlining dependent libraries and user-defined functions. In addition, architecture- and OS-neutral function filtering methods are proposed to significantly reduce irrelevant objective functions. Furthermore, we introduce variable-length partial traces to model binary functions in a program structure-agnostic way. Experimental results demonstrate that BINGO can find semantically similar functions across architecture and operating system boundaries in a scalable manner, even in the presence of program structure distortions. Using BINGO, we also discovered a zero-day vulnerability in Adobe PDF Reader (COTS binaries).
In a word - BinGo: Apply selective inlining technology to capture the complete semantics of functions and introduce variable-length partial traces to model binary functions, and complete binary function search tasks across architectures and operating systems.
introduction
Motivation
In recent years, binary code search has attracted much attention due to its important applications in software engineering and security fields, such as software plagiarism detection [28], reverse engineering [8], semantic recovery [25], malware detection [30] and in Bug (fragile) code identification in various software components for which the source code is not available, such as legacy applications [31,11]. We can even search for zero-day vulnerabilities in proprietary binaries by matching known vulnerabilities in open source software.
Traditional source code search relies on similarity analysis of some representation of source code, such as methods based on tokens [24], Abstract Syntax Tree (AST) [22] or Program Dependency Graph (PDG) [18]. All these representations capture the structural information of the program and provide accurate results for source code searches. However, binary code search is more challenging due to many factors (e.g., choice of architecture and operating system, compiler type, optimization level, and even obfuscation techniques) and the limited availability of high-level program information. These factors have a great influence on the assembly instructions and their final layout in the compiled binary executable.
In the literature, various methods have been proposed to detect similar binaries using static or dynamic analysis. Static analysis relies on syntactic and structural information about binaries, especially the control flow structure (i.e., the organization of basic blocks within functions) to perform matching. For example, TRACY [11] is a syntax-based function matching technique that uses similarity through decomposition; COP [28] is a plagiarism detection tool that combines procedural semantics with fuzzy matching based on longest common subsequence; [ 31] is a vulnerability matching tool that supports cross-architecture analysis through invariants of vulnerability signatures.
Recently, discovervre [37] was proposed to find bugs in binaries across architectures in a scalable manner, where it uses two filters (numerical and structural) to quickly locate functions similar to signature functions. In addition to static analysis, dynamic methods check the program's input-output invariants or intermediate values at runtime to check the equivalence of binary programs. For example, BLEX [16] is a state-of-the-art dynamic function matching tool that uses several semantic features (e.g., values read (written) from the program heap) obtained during function execution during the matching process.
To gain a better understanding of existing approaches, we identify three properties required for an accurate and scalable cross-architecture and cross-OS binary search tool: (1) Ability to adapt to differences due to
architecture, operating system, and compiler While the syntactic and structural differences introduced
(2) improve accuracy by taking into account the full function semantics
(3) are scalable to large-sized real-world binaries
Unfortunately, none of the existing technologies can achieve all the desired properties mentioned above. Structural information used by static methods, such as basic block structures and fixed-length tracelets, does not satisfy property (1). Most static analysis techniques cannot satisfy property (2), because they ignore the semantics of related library and user-defined function calls during the matching process. Finally, property (3) of scalability is the real challenge for semantic binary matching, and it took COP half a day to find the target function signature in firefox.
This paper proposes a binary search engine named BINGO , which addresses the above challenges by combining a set of key techniques to perform semantic matching. Given a binary function, BINGO first inlines the relevant library and user-defined functions to obtain the full semantics of the function (for property 2), then uses architecture- and OS-neutral filtering techniques (for property 3) to list candidate target functions, and finally extracts Partial traces of length variation are extracted from candidate target functions as function models (for attribute 1), and machine learning techniques are used for function similarity matching. To improve the scalability of our method, we propose an architecture- and OS- neutral filtering technique to narrow down the search space by listing candidate objective functions for binary semantic matching . Next, to overcome the challenges arising from distorted basic block structures, we generate function models that are agnostic to the underlying program structure through length-variable partial tracking. To this end, for each function, partial traces of length 1 to k are extracted to form function models such that they represent functions at different levels of granularity. Here, we also take steps to minimize the impact of infeasible paths and compiler-specific code when computing the function similarity score.
Contributions
(1) Proposes a selective inlining algorithm to capture the full semantics of binary functions
(2) Introduces an architecture- and operating-system-neutral function filtering process that helps narrow down the target function search space
(3) Utilizes variable-length Partial tracing to
model functions at different levels of granularity, independent of underlying program structure
Challenges
The same source code may have a different basic block structure after compilation. Taking the notorious Heartbleed vulnerability (CVE-2014-0160) as an example, Figure 1(a) and Figure 1(b) show the basic block structure of the same source code compiled with gcc and mingw, respectively. Apparently, the two binary code segments do not have the same basic block structure - in gcc, the vulnerable code is represented as a single basic block; with mingw, as several basic blocks. Detailed inspection shows that in the mingw version the library function memcpy is inlined; in gcc it is not. The huge syntax and program structure differences between these two binary codes pose the biggest challenge to existing binary code search tools.
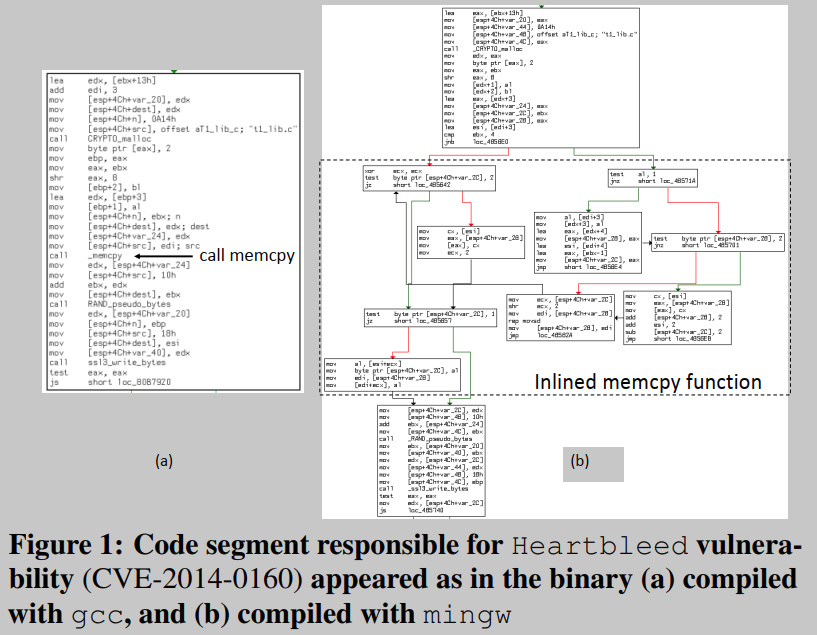
The challenge mainly consists of three aspects:
(C1) The challenge of using program structure properties: Existing methods assume that the basic block structure remains unchanged between different binaries. On this basis, the semantic features extracted by the signature function at the basic block level are combined with The semantic features extracted by the objective function are compared in pairs, but in fact this assumption does not apply to real-world scenarios.
(C2) The challenge of covering full function semantics: Most existing static techniques consider functions in isolation, that is, the semantics of the callee function are not considered part of the caller semantics. This leads to some semantic problems, especially when the programmer treats the most commonly used piece of code as a separate function or implements her own version of a standard C library function. To get around this, all called functions can be blindly inlined (e.g. all user-defined functions are inlined). Unfortunately, this approach does not work in practice for two main reasons: (1) massive inlining can lead to code size explosion, which does not scale to realistic binary analysis, and (2) not all called Functions are all closely related to calling functions in terms of functionality.
(C3) Challenges of scalable search in real-world large binary files: In general, grammar-based techniques are scalable. However, as discussed earlier, they fail in cross-architecture analysis. To solve this problem, semantic-based techniques are preferred, however, extracting semantic features entails significant overhead and is not scalable. Therefore, to facilitate scalable semantic matching, an efficient, architecture-, OS-, and compiler-independent function filtering step is required. However, the existing methods only consider the efficiency of the filter, for example, only the number of basic blocks is considered as the filtering standard. Although the filtering speed can be accelerated, this approach is not robust under cross-architecture and operating system conditions.
method
Overview
The workflow of BINGO is shown in Figure 2. First, given a signature function, BINGO will preprocess the binary, i.e. decompose and build a CFG from the function, for further analysis. Next, for each function, closely related libraries and other user-defined functions are identified and inlined in the target binary. Then, from these inlined target functions, three filters (considering different aspects of program semantics) are used to filter the list of candidate functions similar to the signature function. Next, from the signed and shortlisted objective functions, length-varying partial traces are generated, which are then grouped to form a function model. During the partial trace generation phase, trace pruning is performed to remove irrelevant and infeasible partial traces from the analysis. Then, semantic features are extracted from the functional model for semantic similarity matching. Finally, according to the obtained similarity scores, BINGO sequentially returns the objective functions that are semantically similar to the signature function.
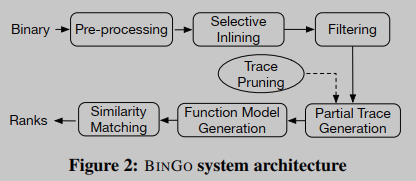
In summary, to address the syntax differences of instructions, we promote low-level assembly instructions to their corresponding intermediate representations (IRs) to facilitate cross-architecture analysis. To alleviate C1 (eg, a single basic block in the signature function in Figure 1 matches multiple basic blocks in the objective function), we borrow the idea of tracelets used in TRACY [11]. Instead of using fixed-length traces, we use variable-length partial traces. Next, to overcome C2 (e.g., whether to inline memcpy in Figure 1(a)), we propose a selective inlining strategy to strike a balance between the required contextual semantics and the overhead caused by inlining . Finally, to address the C3 problem, we employ three filters that consider different aspects of semantics to identify similar functions.
SELECTIVE INLINING
Inlining is a compiler technique used to optimize binaries for maximum speed and/or minimum size. The selective inlining technique described in this section has different goals and strategies than the compilation process.
To inline related functions, we use function call patterns to guide inlining decisions. Based on our research, we identified six common invocation patterns, which are summarized in Figure 3. Incoming (outgoing) edges in Figure 3 represent incoming (outgoing) calls to functions. Here, we elaborate these six modes as follows.

Case 1: Fig. 3(a) depicts a direct call of a standard C library function by the studied caller function.
Case 2: Fig. 3(b) depicts the recursive relationship between the caller and UD (user-defined) callee function f.
Case 3: Figure 3© depicts a common pattern of utility functions, e.g. a callee function f of a UD is called by many other UD functions, while f calls several library functions and very few (or zero) UD functions. This indicates that the behavior of f is a utility function (utility function), because f has some semantics that other functions usually need, so f is likely to need to be inlined.
Case 4: The called function f of the UD in Figure 3(d) is a variant of 3© in which it has several calls to library functions and zero calls to other UD functions.
Case 5: In Fig. 3(e), the called function f of UD is a variant of 3(d), which only calls library functions.
Case 6: Figure 3(f) depicts the scenario of a scheduler function, where a UD function f is called (i.e., passed in) by many other UD functions, and f itself calls many other UD and library functions. In this case, f seems to be a dispatcher function without much unique semantics, and thus, in most cases, not inlined.
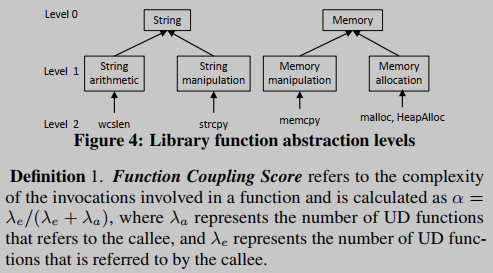
To identify the cases of commonly used functions (i.e., utility functions) to be inlined, we borrow the notion of coupling from the software quality and architectural restoration communities. In software metrics, the coupling between two software packages is measured by their dependencies, e.g., package instability metrics [29]. In this work, similarly, we measure functional coupling by a functional coupling score. The lower the alpha value, the more likely the called object is to be inlined. The rationale is that a low functional coupling score implies a high degree of independence of functions—a high probability of being a utility function.

Algorithm 1 presents the proposed selective inlining procedure. First, if the callee is one of the selected library functions (eg, memcpy and strlen in case 1), it will be inlined directly into the caller (lines 3-5), and the rest of the library functions will be neglect. Next, for other user-defined (UD) functions f, other UD functions that call the f function are expressed as I uf I_u^fIuf;The library function and UD function called by f are respectively identified as O lf O^f_l in lines 8-9Olfsum O uf O_u^fOuf. The f that only calls the library function of the termination type is not inlined (lines 11-12, whether the condition judgment here is equivalent to calling only the library function of the termination type needs to be studied). Finally, for the rest of the called functions, the function coupling score is calculated, and if it is below some threshold t, the called function is inlined (Lines 13-24). This recursive process continues until all relevant functions have been analyzed.
FUNCTION FILTERING
To handle the large number of objective functions in real-world binaries, an efficient filtering process can remove irrelevant objective functions before the expensive matching step. BINGO utilizes three types of filters, ranging from specific filters (fine-grained) to the most general filters (coarse-grained), to list candidate objective functions.
Filter 1: library function call
Filter 2: library call operation type, that is, the abstract function that matches the library call. For example, "String arithmetic", "String manipulation", "Memory manipulation", "Memory allocation"
Filter 3: The instruction type similarity between the signature and the target function. Under the Intel and ARM architectures, the instructions are divided into 14 types and 8 instruction types. For example, the mov instruction maps to a data movement instruction type, while push maps to a stack operation.

Filtering Algorithm Filter 1 is specific and operating system dependent. Filters 2 and 3 are generic, cross-OS and cross-architecture. The filtering process is shown in Algorithm 2. In lines 7, 9 and 11, we use Jaccard distance to measure the similarity between the signature and the target function, i.e., their similarity in the same library call, library call operation type, and instruction type. Set the weight (w1 > w2 > w3 > 0) to the similarity obtained by Filter 1 to Filter 3 following the design of applying filters one by one from the most specific filter to the general filter. On Line 12, we rank candidate functions based on the overall similarity across the three filters (computed on Line 10). Finally, on line 13, we get the top N sorted results and use them for function model matching.
SCALABLE FUNCTION MATCHING
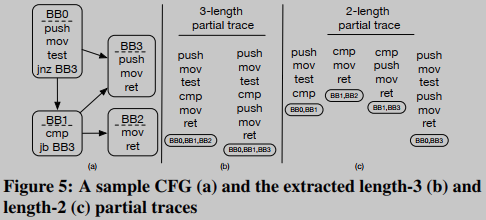
In BINGO, similarity matching is done at a granularity at the function and/or sub-function level. The proposed functional model consisting of length-varying partial traces is more flexible in comparing granularity than the basic-block-centric functional model. Part of the trace extraction in this paper is based on the technique proposed by David et al. [11]. The results are explained here using an example (see [11] for more information on partial trace extraction). Figure 5 depicts a CFG sample of a function and extracted length-2 and length-3 partial traces. It can be observed that the original control flow instructions (jnb and jb) are omitted because the execution flow is already determined.
From each partial trace is extracted a set of symbolic formulas (called symbolic expressions) that capture the effect of performing the partial trace on the state of the machine. In general, the machine state can be described by a triple X = ⟨ mem , reg , flag ⟩ \mathcal{X}=\langle\text { mem }, \text { reg }, \text { flag }\rangleX=⟨ mem , reg , flag ⟩ , the machine state before and after the execution of the partial trace can be set to the previous stateX \mathcal{X}X and poststateX ′ \mathcal{X}'X’ , and symbolic expressions are used to capture the relationship between the preceding and subsequent states.
To measure the similarity between the signature and the target function, a constraint solver such as Z3 can be used to compute the semantic equivalence between the symbolic expressions extracted from the signature and the target function. However, the cost of constraint solving is too high to be suitable for large-scale search. To solve the scalability problem, machine learning techniques are applied in [31]. Specifically, input/output (or I/O) samples are randomly generated from symbolic expressions and fed into a machine learning module to find semantically similar functions. Here, I/O instances are generated by assigning concrete values to pre-state variables and obtaining corresponding output values for post-state variables in symbolic expressions. However, one of the disadvantages of randomly generating I/O samples is that dependencies between symbolic expressions are ignored.
For this, we use the Z3 constraint solver to generate I/O samples. Generating I/O samples via Z3 is more scalable than using it to prove the equivalence of two symbolic expressions—the generation of I/O samples is a one-time job per part track, while the equivalence check is performed in Constraint solving is performed on each comparison.
In BINGO, the authors employ two tracking pruning methods to reduce the noise in the results and speed up the matching process. BINGO is a static analysis based tool, therefore, in practice it is difficult (or even impossible) to identify all infeasible partial traces.
(1) BINGO uses the constraint solver to trim the obvious infeasible traces. If the constraint solver is unable to find appropriate concrete values for the pre- and post-state variables, the associated partial tracking is considered infeasible.
(2) Identify and remove compiler-specific code from partial traces. Some optimization options will cause the compiler to add a lot of code that has nothing to do with the source code logic when compiling the binary, such as some security mechanism codes. Directly removing some codes from partial traces may lead to incorrect semantic features, since these features are very sensitive to the underlying code semantics. To this end, we propose a conservative approach to address this problem by generalizing compiler-specific code into some patterns and systematically pruning the partial traces that include these patterns. That is, if the compiler-specific code pattern accounts for a large portion of the code (50% or more), we only remove the partial trace itself, rather than removing the compiler-specific code from the partial trace (which is error-prone ).
BINGO utilizes partial tracking of varying lengths to model functions. Partial traces of three different lengths (i.e. k = 1, 2, 3) were generated from each function, which together constituted the function model. Take the signature ( M sig M_{sig} in Figure 7Ms i g)和target ( M t a r M_{tar} Mtar)函数为例,生成的函数模型如下:
M sig : { ⟨ 1 ⟩ , ⟨ 2 ⟩ , … , ⟨ 1 , 2 ⟩ , ⟨ 2 , 5 ⟩ , … , ⟨ 1 , 2 , 4 ⟩ , ⟨ 2 , 4 , 7 ⟩ , … } M tar : { ⟨ c ⟩ , ⟨ b ⟩ , … , ⟨ a , b ⟩ , ⟨ b , c ⟩ , … , ⟨ a , b , c ⟩ , ⟨ b , c , f ⟩ , … } \mathcal{M}_{\text {sig }}:\{\langle 1\rangle,\langle 2\rangle, \ldots,\langle 1,2\rangle,\langle 2,5\rangle, \ldots,\langle 1,2,4\rangle,\langle 2,4,7\rangle, \ldots\} \\ \mathcal{M}_{\text {tar }}:\{\langle\mathrm{c}\rangle,\langle\mathrm{b}\rangle, \ldots,\langle a, b\rangle,\langle\mathrm{b}, \mathrm{c}\rangle, \ldots,\langle a, b, c\rangle,\langle\mathrm{b}, \mathrm{c}, \mathrm{f}\rangle, \ldots\} Mhimself :{⟨1⟩,⟨2⟩,…,⟨1,2⟩,⟨2,5⟩,…,⟨1,2,4⟩,⟨2,4,7⟩,…}Mtar :{⟨c⟩,⟨b⟩,…,⟨a,b⟩,⟨b,c⟩,…,⟨a,b,c⟩,⟨b,c,f⟩,…}
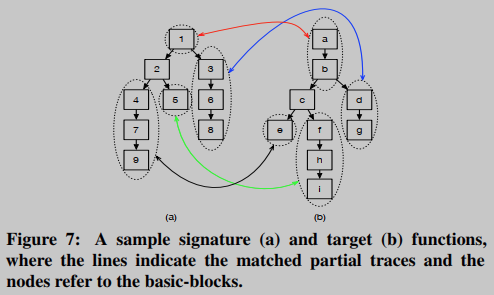
There are 4 matching modes, matching between traces of different lengths; matching between long 1 traces and long n traces; matching between long n and long 1 traces; matching between basic blocks

In BINGO, all the above 4 types of function matching are performed to cover all possible basic block structure differences due to architecture, operating system and compiler differences. Finally, the function model is regarded as a partially tracked set, and the Jaccard inclusive similarity is used to measure the similarity score between two different function models, which is defined as follows: sim ( M sig , M tar ) = M sig ⋂ M tar
M sig sim(\mathcal{M}_{\text {sig }},\mathcal{M}_{\text {tar}}) = \frac{\mathcal{M}_{\text {sig }} \bigcap \mathcal{M}_{\text {tar}}}{\mathcal{M}_{\text {sig }}}sim(Mhimself ,Mtar)=Mhimself Mhimself ⋂Mtar
experiment
IMPLEMENTATION
In BINGO, use IDA Pro to disassemble and generate the cfg from the functions in the binary. Generate partial traces from function CFGs using the IDA Pro plugin, where they have three different lengths (lengths 1, 2, and 3). Finally, to extract semantic features, similar to [31] and [28], low-level assembly instructions are lifted to an architecture- and OS-independent intermediate language REIL [14]. Initial experiments, in the selective inlining algorithm (Algorithm 1), set the function coupling score α to 0.01. Likewise, in Algorithm 2, the filter weights w1 (for filter 1), w2 (for filter 2) and w3 (for filter 3) are set to 1.0, 0.8 and 0.5, respectively. All experiments are performed on a machine equipped with Intel Core [email protected] and 32GB DDR3-RAM .
Through experiments, we aim to answer four research questions (RQs), grouped into three main themes, namely robustness (RQ1 and RQ2), application (RQ3) and scalability (RQ4):

In RQ1, we evaluate the selective inlining algorithm to demonstrate its effectiveness. In RQ2, we compared BINGO with BINDIFF [17] and TRACY [11], indirectly showing the advantage of using length-varying partial tracking in the modeling function. In RQ3, we evaluate the performance of BINGO in finding real-world vulnerabilities and compare it with discovervre [37] and [31]. Finally, in RQ4, we demonstrate the performance of BINGO by filtering with the proposed function.
Robustness
The robustness of BINGO lies in (1) matching semantically equivalent functions and (2) matching semantically similar functions. RQ1 falls under criterion one because our goal is to match all functions in binary A to all functions in binary B, where they all come from the same source code (i.e., have the same syntax at the source code level), but use different Compiler and code optimization options compile for different architectures. RQ2 focuses more on finding semantically similar functions (i.e., different syntax even with different programming styles and coding conventions at the source level) in binaries of different source codes. By answering RQ1 and RQ2, we evaluate how good BINGO is as a search engine that can find in-the-wild binary executables that do not share source code but perform semantically similar operations.
The first experiment was to match all functions in a coreutils binary compiled for one architecture (i.e., x86 32-bit, x86 64-bit, and ARM) with semantically equivalent functions in a binary compiled for another architecture. Considering that the coreutils binaries are relatively small, with about 250 functions (on average) per binary, we used a BusyBox (v1.21.1) containing 2410 functions for the second experiment. We observe that the obtained results are comparable to those of the coreutils binaries—in BusyBox, an average of 41.3% of the functions rank first, while the coreutils binaries rank 35% of the 16 experiments, as shown in Figure 8. This is a 27.5% improvement over the accuracy achieved by [31] for BusyBox.
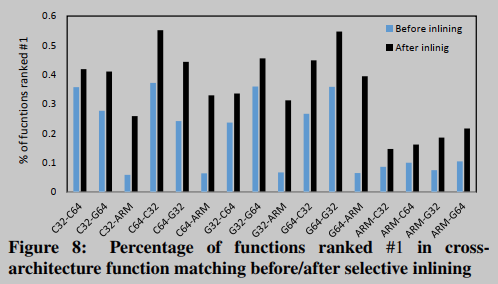
Selective inlining significantly improves overall matching accuracy by an average of 150%. In particular, selective inlining improves overall matching accuracy by an average of 400% when using the ARM architecture as the target. Table 1 summarizes the total number of functions inlined for each architecture. We noticed that coreutils compiled for ARM contained more functions (27,820 in 103 binaries) than coreutils compiled for x86 32-bit (average 24,397) and x86 64-bit (average 24,136). From the second row of Table 1, it can be seen that the functions selectively inlined by BINGO in ARM are 61% and 82% more than x86 32-bit and 64-bit architectures, respectively. In the ARM binaries, the large number of functions indicates that compiler inlining does not occur as frequently as it does in the other two architectures. Therefore, our selective inlining technique is needed to capture the full function semantics and thus improve matching accuracy.
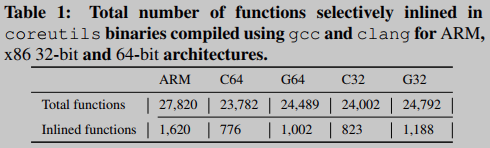
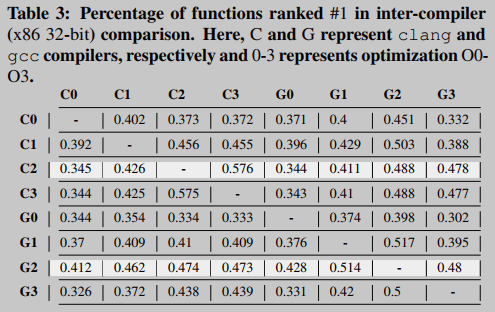
Table 3 summarizes the results obtained with BINGO for different compilers (gcc and clang) and different optimization levels (O0, O1, O2, and O3) for the x86 32-bit architecture. Here, each row and column of the table represents the compiler (including optimization level) used to compile the signature function and the target function, respectively. Interestingly, we found that regardless of the compiler type, matches between binaries compiled with high code optimization levels (i.e. O2 and O3) yielded better the result of. That is to say, the code optimization level is high, even if different compilers are used, the binary code will be similar, and without optimization, the influence of the compiler on the binary code is very obvious.
Furthermore, we repeated the experiments on different versions of the same compiler (gcc v4.8.3 vs. gcc v4.6), and Table 2 summarizes the results (for x86 32-bit architecture). As expected, the accuracy is highest when the signature function and the objective function have the same optimization level, but when the signature function is compiled with optimization level O1, in this case the objective function compiled with optimization level O2 has better precision.

Selective inlining improves the average matching accuracy of the cross-compiler analysis by about 140%. Many functions are inlined when the binary's optimization level is O0 instead of O3. In particular, optimization level O0 inlines 1473 functions (including gcc and clang) on average, while optimization level O3 only has 831.
The second experiment, performed with open source and closed source binaries. In this experiment, Windows mscvrt is selected as the binary file for obtaining search queries (closed source), and Linux libc is selected as the target binary file for searching (open source). In conducting this experiment, we were faced with the challenge of obtaining ground truth. Ideally, for each function in msvcrt, we would like to determine the corresponding semantically similar function in libc, so that we can faithfully compute BINGO. To reduce the bias in obtaining the ground truth by manual analysis, we rely on function names and high-level descriptions provided in official documentation, e.g., the strcpy function in msvcrt matches strcpy (or its variants) in libc. Furthermore, several variants of the same function are grouped together.
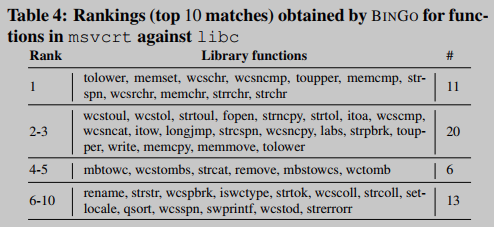
Overall, we build ground truth for 60 standard C library functions in msvcrt, and Table 4 summarizes the results obtained with BINGO. Among them, 11 functions (18.3%) ranked first, about 51.7% of the functions ranked within the top 5, and 83.3% of the functions ranked within the top 10. The results demonstrate the robustness of BINGO in identifying functions that do not share a codebase but are semantically similar.
Applications
The third experiment, using BINGO to perform vulnerability extrapolation, given a known vulnerable code, called a vulnerability signature, using BINGO, we try to find semantically similar vulnerable code segments in the target binary. However, there is little evidence of using this technique to find real-world vulnerabilities. One reason may be that these tools cannot handle large complex binary files. Due to program structure-agnostic function modeling and efficient filtering, BINGO is able to handle large binary files. We therefore evaluate the usefulness of our tool in finding real-world vulnerabilities.
Zero-day Vulnerability (CVE-2016-0933) Found: BinGo found a zero-day vulnerability in a 3D library used in adobepdf Reader. A network exploitable heap memory corruption vulnerability has been discovered in an unspecified component of the latest version of Adobe PDF Reader. The root cause of this vulnerability is a lack of buffer size validation, allowing an unauthenticated attacker to execute arbitrary code with low access complexity. We use previously known vulnerabilities as signatures, where the signature function consists of more than 100 basic blocks. Use BINGO to model the known vulnerable functions and all other "unknown" functions in the library, then use the known fragile function models as signatures to search for semantically similar functions. BINGO returned "potentially" vulnerable functions in suspected 3D libraries (#1). Finally, the 0day vulnerability was determined through manual inspection.
To evaluate whether BINGO is capable of finding cross-platform vulnerabilities, we repeated the two experiments reported in [31]. The first is the libpurple vulnerability (CVE-2013-6484), which is present in the Windows application (Pidgin) and its counterpart in Mac OSX (Adium). It is reported that in [31], matching from Windows to Mac OSX and vice versa without manually crafting vulnerability signatures achieved the rankings of 165th and 33rd, respectively. In BINGO, we have achieved number one ranking in both cases. Due to the use of filter 2 (i.e. library call abstraction technique) in our filtering algorithm, we identified four library calls (i.e. "string manipulation": strlcpy, "time": time, "input/output": ioctl and "internet address manipulation":inet_ntoa), which match vulnerable functions in the operating system.
Scalability
The fourth experiment verifies the scalability of BINGO. It takes only a few milliseconds for the coretutils binary to sift through candidate objective functions. For example, in the cross-architecture analysis comparing the entire coreutils suite compiled for one architecture (a total of 103 binaries containing an average of 250 functions each) takes an average of 91.8 ms, while in the cross-compiler analysis it reduces to 68.6 milliseconds. After filtering, for each signature function in the coreutils binary, an average of 21 target functions were shortlisted in the cross-architecture analysis, which was further reduced to 13 functions in the cross-compiler analysis. For a large binary like BusyBox (about 3250 functions, 39179 basic blocks), filtering objective functions takes an average of 6.16 seconds, and for each signature function, less than 40 objective functions are shortlisted. Similarly, for the SSL/Heartbleed vulnerability search in openssl (about 5700 functions, over 60K basic blocks), the filtering process takes 12.24 seconds, and only 53 functions are shortlisted.
The main overhead of BINGO is part of the trace generation and semantic feature extraction operations. For example, it takes 4469 seconds to extract semantic features from 2611 libc functions - an average of 1.7 seconds to extract semantic features from one libc function, but only 1123 seconds to extract semantic features from 1220 msvcrt functions (average 0.9 seconds per function ). With our filtering technique, the time-consuming step of semantic feature extraction is no longer available for all functions in the binary. In practical applications, semantic feature extraction is a one-time job that is easy to parallelize.
Threats to Validity
The main limitation of selective inlining is that functions that are called indirectly (i.e. indirectly called) cannot be inlined. However, this limitation is not specific to BINGO, but an inherent problem with all static analysis based techniques. As early as 2005, people have discovered this problem and proposed solutions, such as VSA (Value Set Analysis) [4]. However, we did not incorporate VSA into BINGO because it involves heavyweight program analysis, which may incur a heavy performance cost.
Summarize
Related Works
Binary Similarity Analysis
Saebjornsen et al. [35], one of the pioneers in binary code search, proposed a binary code clone detection framework that exploits normalized syntax (i.e. normalized operands) based on functional modeling techniques. Jang et al. [20] propose to use n-gram models to obtain complex families of binaries and normalize instruction mnemonics. Based on n-gram features, code search is done by checking symmetric distances. Binary control flow graphs are considered in the similarity check. [7] aims to detect infected viruses from executable files by CFG matching method. [27] proposed a primitive-based malware identification method that generates a connected k-subgraph of CFG and applies primitive coloring to detect common subgraphs between malware samples and suspicious samples. Besides, [34] and [33] also adopted CFG to recover compiler and even author information. Tracelet [11] is used to capture the grammatical similarity of the execution sequence, which is convenient for finding similar functions. In parallel to our work, Kam1n0 [13] was proposed to solve the problem of efficient subgraph search for assembly functions. Unfortunately, the aforementioned syntax-based binary similarity matching techniques fail in cross-architecture analysis.
Value-based equivalence checking
Utilizes input-output (I/O) and intermediate values to identify semantic clones regardless of source code availability. Jiang et al. [23] considered the problem of detection of semantic clones as a testing problem. They use random testing and then cluster code snippets based on I/O samples. [36] provides a way to compare x86 loop-free code segments to test the correctness of the conversion. Equivalence checking is based on the selected inputs, outputs and the state of the machine at the time of execution completion. Note that intermediate values are not considered in [23][36]. However, intermediate values are used to alleviate the problem of identifying I/O variables in binary code. In [21], Jhi et al state the importance of certain particular intermediate values that are unavoidable in various implementations of the same algorithm and thus qualify as good candidates for fingerprinting. Based on this assumption, the study of plagiarism detection [40] and program [41] matching execution history is proposed.
Difference-Based Equivalence Checking
BINDIFF [17] builds CFGs of two binaries, then employs heuristics to normalize and match the two CFGs. Essentially, BINDIFF solves the NP-hard graph isomorphism problem (matching CFG). BINHUNT [19] is a tool that extends BINDIFF by enhancing binary diff in two ways: treating matching CFGs as a maximum common induced subgraph isomorphism problem and applying symbolic execution and theorem proving to verify two fundamental Equivalence of code blocks. To solve the non-subgraph matching problem of CFG, BINSLAYER [6] models the CFG matching problem as a bipartite graph matching problem. For these tools, compiler optimization options may change the structure of the CFG, causing graph-based matching to fail. More recently, BLEX [15] was proposed to tolerate such optimization and obfuscation differences. Basically, BLEX borrows the idea from [23] to execute two functions of given binaries with the same input and compare the output behavior.
Vulnerability Detection Based on Binary Analysis
Dynamic analysis faces two challenges: the difficulty of setting up the execution environment, and scalability issues that prevent large-scale detection. According to Zaddach et al. [39], these dynamic methods are far from being practical for highly customized hardware such as mobile or embedded devices. Therefore, cross-architecture error detection is difficult for these methods. To address this issue, Pewny et al. [31] and discover [37] proposed a static analysis technique aimed at detecting vulnerabilities in multiple versions of the same program compiled for different architectures. Unfortunately, due to the heavy reliance on functional CFG structures, their approach is well suited for finding clones of the same program, but not for finding semantic binary clones between applications from entirely different source code bases.
References
[6] M. Bourquin, A. King, and E. Robbins. Binslayer: accurate comparison of binary executables. In Proceedings of the 2nd
ACM SIGPLAN Program Protection and Reverse Engineering Workshop 2013, PPREW@POPL 2013, January 26, 2013,
Rome, Italy, pages 4:1–4:10, 2013.
[7] D. Bruschi, L. Martignoni, and M. Monga. Detecting selfmutating malware using control-flow graph matching. In Detection of Intrusions and Malware & Vulnerability Assessment, Third International Conference, DIMVA 2006, Berlin, Germany, July 13-14, 2006, Proceedings, pages 129–143, 2006.
[8] J. Caballero, N. M. Johnson, S. McCamant, and D. Song. Binary code extraction and interface identification for security applications. Technical report, DTIC Document, 2009.
[11] Y. David and E. Yahav. Tracelet-based code search in executables. In ACM SIGPLAN Conference on Programming
Language Design and Implementation, PLDI ’14, Edinburgh, United Kingdom - June 09 - 11, 2014, page 37, 2014.
[13] S. H. Ding, B. C. Fung, and P. Charland. Kam1n0: Mapreducebased assembly clone search for reverse engineering. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD. ACM,
2016.
[14] T. Dullien and S. Porst. Reil: A platform-independent intermediate representation of disassembled code for static code
analysis. Proceeding of CanSecWest, 2009.
[15] M. Egele, M. Woo, P. Chapman, and D. Brumley. Blanket execution: Dynamic similarity testing for program binaries and components. In Proceedings of the 23rd USENIX Security Symposium, San Diego, CA, USA, August 20-22, 2014., pages
303–317, 2014.
[16] M. Egele, M. Woo, P. Chapman, and D. Brumley. Blanket execution: Dynamic similarity testing for program binaries and components. In USENIX Security Symposium, 2014.
[17] H. Flake. Structural comparison of executable objects. In Detection of Intrusions and Malware & Vulnerability Assessment, GI SIG SIDAR Workshop, DIMVA 2004, Dortmund, Germany, July 6.7, 2004, Proceedings, pages 161–173, 2004.
[18] M. Gabel, L. Jiang, and Z. Su. Scalable detection of semantic clones. In 30th International Conference on Software Engineering (ICSE 2008), Leipzig, Germany, May 10-18, 2008, pages 321–330, 2008
[19] D. Gao, M. K. Reiter, and D. X. Song. Binhunt: Automatically finding semantic differences in binary programs. In Information and Communications Security, 10th International Conference, ICICS 2008, Birmingham, UK, October 20-22, 2008, Proceedings, pages 238–255, 2008.
[21] Y. Jhi, X. Wang, X. Jia, S. Zhu, P. Liu, and D. Wu. Valuebased program characterization and its application to software
plagiarism detection. In Proceedings of the 33rd International Conference on Software Engineering, ICSE 2011, Waikiki, Honolulu , HI, USA, May 21-28, 2011, pages 756–765, 2011.
[22] L. Jiang, G. Misherghi, Z. Su, and S. Glondu. DECKARD: scalable and accurate tree-based detection of code clones. In
29th International Conference on Software Engineering (ICSE 2007), Minneapolis, MN, USA, May 20-26, 2007, pages 96–
105, 2007.
[23] L. Jiang and Z. Su. Automatic mining of functionally equivalent code fragments via random testing. In Proceedings of the
Eighteenth International Symposium on Software Testing and Analysis, ISSTA 2009, Chicago, IL, USA, July 19-23, 2009, pages 81–92, 2009.
[24] T. Kamiya, S. Kusumoto, and K. Inoue. Ccfinder: A multilinguistic token-based code clone detection system for large
scale source code. IEEE Trans. Software Eng., 28(7):654–670, 2002.
[25] D. Kim, W. N. Sumner, X. Zhang, D. Xu, and H. Agrawal. Reuse-oriented reverse engineering of functional components
from x86 binaries. In Proceedings of the 36th International Conference on Software Engineering, pages 1128–1139. ACM, 2014.
[27] C. Krügel, E. Kirda, D. Mutz, W. K. Robertson, and G. Vigna. Polymorphic worm detection using structural information
of executables. In Recent Advances in Intrusion Detection, 8th International Symposium, RAID 2005, Seattle, WA, USA,
September 7-9, 2005, Revised Papers, pages 207–226, 2005.
[28] L. Luo, J. Ming, D. Wu, P. Liu, and S. Zhu. Semantics-based obfuscation-resilient binary code similarity comparison with
applications to software plagiarism detection. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, pages 389–400. ACM, 2014.
[29] R. C. Martin. Agile software development: principles, patterns, and practices. Prentice Hall PTR, 2003.
[30] J. Ming, D. Xu, and D. Wu. Memoized semantics-based binary diffing with application to malware lineage inference.
In ICT Systems Security and Privacy Protection, pages 416–430. Springer, 2015.
[31] J. Pewny, B. Garmany, R. Gawlik, C. Rossow, and T. Holz. Cross-architecture bug search in binary executables. In 2015
IEEE Symposium on Security and Privacy, SP 2015, San Jose, CA, USA, May 17-21, 2015, pages 709–724, 2015.
[33] N. E. Rosenblum, B. P. Miller, and X. Zhu. Extracting compiler provenance from program binaries. In Proceedings of the 9th ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering, PASTE’10, Toronto, Ontario, Canada, June 5-6, 2010, pages 21–28, 2010
[34] N. E. Rosenblum, X. Zhu, and B. P. Miller. Who wrote this code? identifying the authors of program binaries. In Computer Security - ESORICS 2011 - 16th European Symposium on Research in Computer Security, Leuven, Belgium, September 12-14, 2011. Proceedings, pages 172–189, 2011.
[35] A. Sæbjørnsen, J. Willcock, T. Panas, D. Quinlan, and Z. Su. Detecting code clones in binary executables. In Proceedings
of the eighteenth international symposium on Software testing and analysis, pages 117–128. ACM, 2009.
[36] E. Schkufza, R. Sharma, and A. Aiken. Stochastic superoptimization. In Architectural Support for Programming Languages and Operating Systems, ASPLOS ’13, Houston, TX, USA - March 16 - 20, 2013, pages 305–316, 2013.
[37] E. Sebastian, Y. Khaled, and G.-P. Elmar. discovre: Efficient cross-architecture identification of bugs in binary code. In
In Proceedings of the 23nd Network and Distributed System Security Symposium. NDSS, 2016.
[39] J. Zaddach, L. Bruno, A. Francillon, and D. Balzarotti. AVATAR: A framework to support dynamic security analysis of embedded systems’ firmwares. In 21st Annual Network and Distributed System Security Symposium, NDSS 2014, San
Diego, California, USA, February 23-26, 2014, 2014.
Insights
(1) Can refer to selective inlining method to ensure function semantic integrity
(2) Utilize partial tracing to capture function semantic features as embedding of functions
(3) Value-based equivalence check already covers I/O samples and intermediate values A method for identifying functions.
(4) The difference-based equivalence check transforms the function matching problem into the graph isomorphism/maximum common induced subgraph isomorphism/bipartite graph matching problem of CFG graphs, and BinHunt has applied symbolic execution and theorem proving methods to detect basic blocks equivalence.
(5) The method of dynamic analysis is limited by the difficulty of the execution environment, and it is difficult to perform cross-architecture binary search tasks. Either solve the problem of execution environment settings, or only use static analysis methods.