B2SFinder: Detecting Open-Source Software Reuse in COTS Software [ASE 2019]
Muyue Feng, Zimu Yuan, Feng Li, Gu Ban, Yang Xiao, Shiyang Wang, Qian Tang, He Su, Chendong Yu, Jiahuan Xu, Aihua Piao Institute of Information Engineering, Chinese Academy of
Sciences
COTS software products are widely developed on top of OSS projects, leading to OSS reuse vulnerabilities. To detect these vulnerabilities, it has become imperative to find OSS reuse in COTS software. While scalable to tens of thousands of OSS projects, existing binary-to-source code matching methods are severely imprecise when analyzing COTS software products because they support only a limited number of code features and are only approximate when measuring OSS reuse. The match score is calculated and the code structure in the OSS project is ignored.
To address these limitations, we introduce a new binary-to-source matching method called B2SFINDER. First, B2SFINDER can infer seven code characteristics, which are traceable in both binary and source code. In order to accurately calculate the matching score, B2SFINDER uses a weighted feature matching algorithm, which combines three matching methods (used to deal with different code features) and two importance weighting methods (used to The specificity and frequency of occurrence to calculate the weight of its instance) combined. Finally, B2SFINDER identifies different types of code reuse based on the matching score and the code structure of the OSS project. We implemented B2SFINDER with an optimized data structure. We evaluate B2SFINDER using 21991 binaries from 1000 popular COTS software products and 2189 candidate OSS projects. Experimental results show that B2SFINDER not only has high accuracy, but also has scalability. Compared with the state-of-the-art, B2SFINDER finds up to 2.15 times more reuse cases per binary in 53.85 seconds on average. We also discuss how to exploit B2SFINDER to detect OSS reuse vulnerabilities in practice.
Bottom line: B2SFINDER uses a weighted feature matching algorithm for binary-to-source matching.
introduction
Background
When some vulnerable OSS codes are integrated into COTS software and reused in the software, OSS vulnerabilities may be introduced into COTS software. Such OSS vulnerabilities, known as OSS reuse vulnerabilities, are ubiquitous and can have serious implications for the security of COTS software. For example, both Adobe Reader[6] and Windows Defender[7] were found to be vulnerable because they both use some vulnerable open source projects Libxslt and UnRAR. In fact, most OSS reuse vulnerabilities still exist in COTS software, even if their vulnerable versions have been patched. According to a Synopsis report [8], 96% of audited COTS products reuse OSS projects as their components, and these components contain on average unpatched OSS vulnerabilities from OSS projects released six years ago.
In order to detect OSS reuse vulnerabilities, the OSS items included in COTS software must be identified as precisely as possible. Therefore, in this paper, we are motivated to address underlying OSS reuse detection for COTS software problems. While the number of mobile applications continues to increase, traditional COTS products running on desktop computers and servers are still widely used. Therefore, the research focus of this paper is COTS software. COTS products typically consist of dozens of stripped binaries, most of which are in Portable Executable (PE) format (for Windows) or Executable and Linkable Format (ELF) (for Linux).
Given the binaries of a target COTS software product and a set of candidate OSS projects, there are two representative OSS reuse detection methods. One approach is to compute the similarity between the binary code of a given target COTS product and the compiled binary code of a candidate OSS project. We see two challenges. First, fully automatic compilation of all candidate OSS projects is very important, often requiring manual work to find the appropriate compiler flags to make it compile successfully. In an experiment where we scraped 2189 OSS projects [12] from Ubuntu packages, we found that only about a quarter of the projects could be compiled automatically.
Problems
(1) How to select as many code features as possible while ensuring that all selected features are traceable in the compiled binary? The
key to binary-to-source matching lies in the considered code features. For example, BAT [1] only considers string literals and thus misses 39.7% of code reuse not related to string literals (calculated later). OSSPolice [2] considers not only string literals but also exported function names, which works well with libraries in elf format. However, PE files for COTS software often have these clues stripped, making it impossible for OSSPolice to perform the required code matching in stripped binaries.
(2) How to precisely calculate the matching scores of different code features and their feature instances?
Previous works [1, 2, 10, 11, 14] usually measure the degree of feature matching by calculating matching scores. However, their score calculations are imprecise for two reasons: (1) usually the same process is used to match different types of features; (2) different feature instances of the same feature are assumed to contribute equally in feature matching.
(3) How can the code structure of OSS projects be used to improve reuse identification?
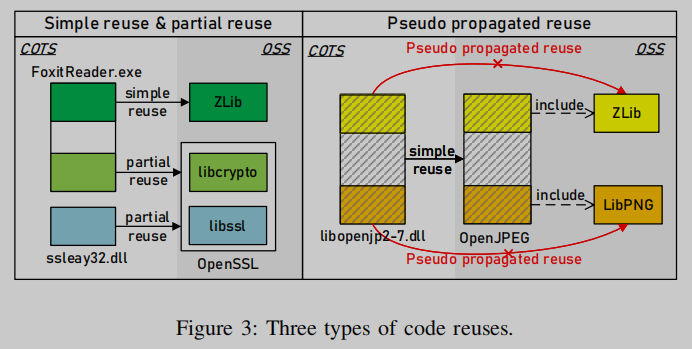
Generally speaking, a higher matching score does not always mean a higher possibility of code reuse, and vice versa. For example, as shown on the right side of Figure 3, every feature in LibPNG matches a feature of libopenjp2-7.dll, so the matching score is high. However, libopenjp2-7.dll only reuses OpenJPEG and not LibPNG. This suggests that in order to reduce the number of reported false reuse signatures and increase the number of true reuse signatures found, the complex code structure of OSS projects should also be considered.
Contributions
To address the above three issues, we propose a novel binary-to-source matching method, B2SFINDER, for detecting OSS reuse. As shown in Figure 1, B2SFINDER is divided into two stages: "matching score calculation" and "reuse type identification".
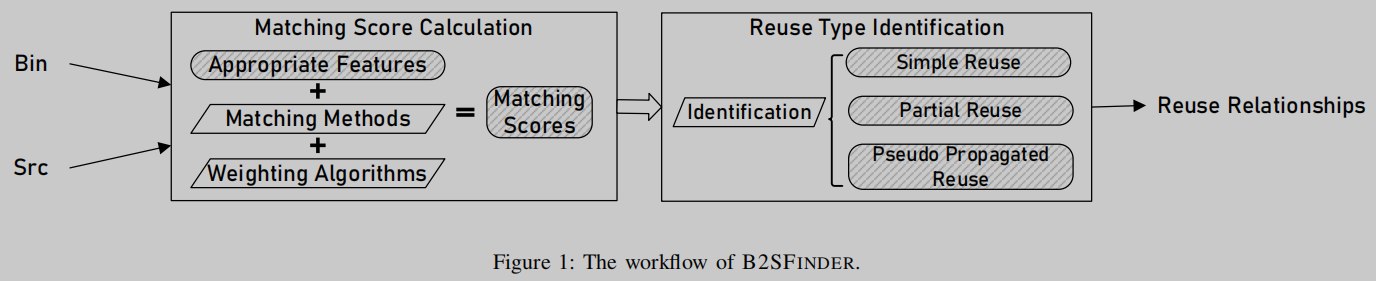
In order to accurately calculate the matching score in the first stage, we actively select 7 stable code features, 4 of which are not affected by compilation, and 3 are less affected during compilation. By dividing the seven features into three types: string type, integer type and control flow type, three corresponding matching methods are designed: exact matching, search-based matching and semantic-based matching. To describe the relative importance of different matching feature instances, we introduce two feature instance attributes, specificity and occurrence frequency. The specificity properties indicate that a special instance of the matching signature, such as 0x6a09e667, is more helpful in distinguishing an OSS item than a mundane item, such as 0x0001. The frequency of occurrence attribute represents the occurrence of a matching feature instance in all candidate OSS items. The lower the frequency, the more important it is in identifying reused OSS items. By combining the bitstream entropy algorithm with a tf-idf-like weighting algorithm, the impact of these two properties on code reuse can be captured in the weight calculation. Overall, we propose a new feature matching algorithm that combines three matching methods with two importance weighting methods.
To identify different types of code reuse, we consider the code structure of OSS projects to identify two types of file groups, self-implemented groups and OSS groups imported from third-party projects. By utilizing this information, we build precise reuse relationships between target COTS software binaries and OSS projects. We have identified three types of reuse relationships: simple reuse, partial reuse, and pseudopropagative reuse. The first two are real reuse cases, while the last one is a false reuse case and should be eliminated. It should be noted that BAT [1] and OSSPolice [2] usually ignore partial reuse due to low matching score, while BAT [1] usually misidentifies pseudo-propagated reuse due to high matching score.
Overall, this paper makes the following contributions
(1) We propose a new binary-to-source matching method by employing a weighted feature matching algorithm that combines three matching methods (for handling different code features) and two importance weighting methods (for computing the weight of instances of code features in a given software application according to their specificity and frequency of occurrence).
(2) This paper introduces a new concept of reuse types and utilizes this concept to improve the accuracy of code reuse detection.
(3) We have developed a prototype open source implementation for B2SFINDER and evaluated its efficiency and accuracy using 21991 binaries from 1000 popular COTS software products and 2189 OSS projects. Compared with the state-of-the-art, B2SFINDER finds up to 2.15 times more reuse cases per binary in 53.85 seconds on average. B2SFINDER has also been proven in practice to be capable of detecting OSS reuse vulnerabilities.
method
Motivation
We introduce the binary-to-source matching approach and illustrate our insights into detecting OSS reuse by using two real-world examples (Foxit Reader and GIMP). Foxit Reader is a well-known PDF file viewing and editing tool. These two binaries, the core executable FoxitReader.exe and the dynamic link library ssleay32.dll, are selected from FoxitReader, and they both reuse OpenSSL, a widely used OSS project that implements SSL. GIMP is a popular raster graphics editor used for image editing. Its dynamic library libopenjp2-7.dll reuses an OSS project OpenJPEG. Although both examples are in PE format, our approach is able to handle all other native binaries in a similar manner.
A. Matching Score Calculation
Since we directly compare the binary code of the COTS software application with the source code of the OSS project, the code characteristics selected from both must be matched. String literals and exported function names can be matched directly, since they are usually independent of compiler flags. However, these features are not available for many binaries in COTS software. A key observation in our approach is to identify ranges of code features that are unlikely to change during compilation.
As shown in Figure 2, there is no common export function name between FoxitReader.exe and OpenSSL. Furthermore, only 19.7% of common string literals are shared between the two. Given these two facts, BAT[1] and OSSPolice[2] are ineffective in analyzing FoxitReader.exe. To take advantage of the more stable code features present in the binary and source code, we examined FoxitReader.exe. In addition to .rdatastring literals in sections and exported function names in DOS headers, we discovered other features that are optional in the .rdata, .dataand , sections..text
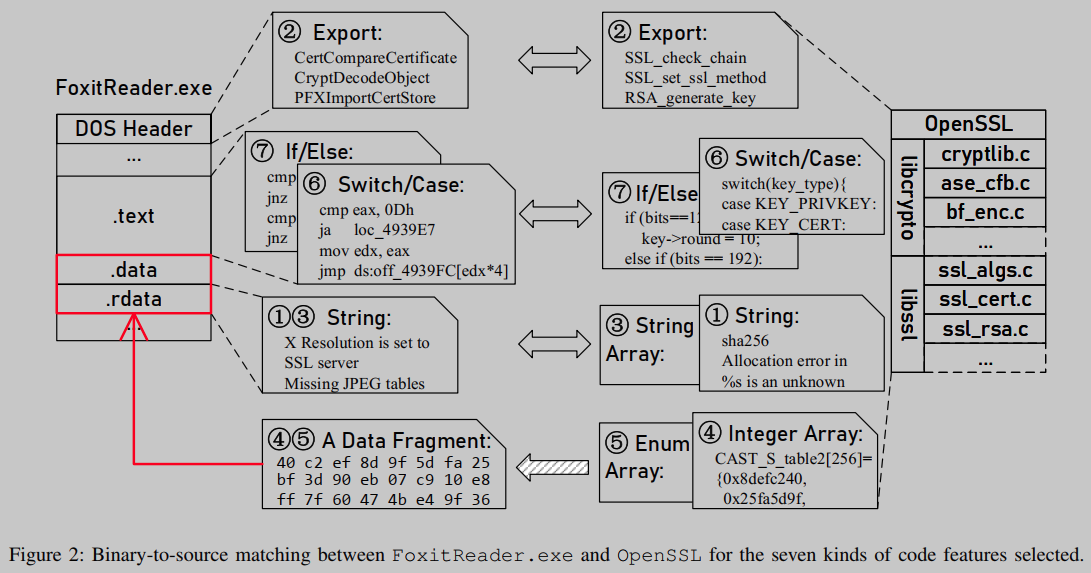
One of these newly selected features is numerical data. These data items are usually the initial values of global variables stored in the .data section (for non-constant variables) and .rdata sections (for constant variables). Global numerical arrays and global enumeration arrays, for example, in Figure 2, the global integer array CAST_S_table2[256] = {0x8defc240, 0x25fa5d9f, ...} in OpenSSL; in FoxitReader.exe, the bitstream prefixed with 0x40c2ef8d9f5dfa25.
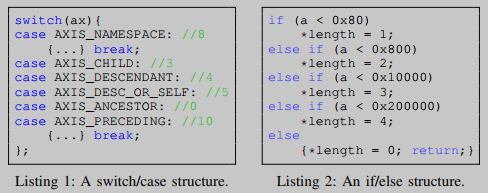
We observe that .textsome latent code features can also be found in segments. Although control flow information can be changed by some compiler optimizations, the branch sequences representing some complex logic are relatively stable. This is because such sequences are often complex and thus do not meet the required underlying optimization criteria. Therefore, for a given binary, we search its data or instruction sequences using encoded complex switch/case structures and continuous if/else conditional branch sequences extracted from its code segment. For example, FoxitReader.exe has a jump table [0,9,16,17,20] which was found to contain the same labels as the switch statement in the OpenSSL function aes_ccm_ctrl(). This suggests that FoxitReader.exe is likely to reuse OpenSSL.
We selected seven code features in total, as shown in Figure 2. However, how to match features in source code with the same features present in its compiled binary remains challenging, especially for those features that may change slightly during compilation.
For a given code feature, the reverse engineering method is used to extract the feature instance in the COTS software application binary file, and the program analysis method is used to extract the feature instance in the OSS project source code. A feature instance is a specific feature object belonging to a certain class of features, as shown in Figure 2. For different code features, we will use three different matching methods for identification. For different instances of code features, we will identify their relative importance by applying two different importance weighting methods.
For strings, string arrays, and exported functions , their feature instances are all in the form of strings, which can be directly identified by string matching algorithms. Specifically, since there are a large number of strings in reality, an inverted index is used to speed up string matching.
On the other hand, instances of two numeric attributes , the global array of integers and the global array of enumerations, are handled differently. Due to the lack of data structure information in binaries, we encode these feature instances found in binaries as bitstreams of specific lengths in specific data types. For each candidate OSS project, each bitstream is then searched in its source code for instances of it being in big- or little-endian byte order.
Finally, matching control flow types for attribute instances , constants in switch/case attributes, and constants in if/else attributes is more complicated. We will semantically compare the corresponding constants in one trait instance of a control flow type in a COTS software application binary and another trait instance of a control flow type in an OSS project source code.
B. Reuse Type Identification
When we do feature matching between COTS software applications and candidate OSS projects, high matching scores may not always indicate true reuse, and low matching scores may not always indicate false reuse. To improve the accuracy of reuse detection, we distinguish different types of code reuse by exploiting the code structure of OSS projects.
In many cases, a high match score indicates true reuse. We define this reuse as simple reuse, which can also be discovered by existing methods [1,2]. However, we found two other types of reuse that exhibit inconsistencies between the actual reuse relationship and the obtained matching scores, as shown in Figure 3. For example, libssl (aka ssleay), one of the OpenSSL libraries, is generated by only 7.6% of the OpenSSL source files. Any binaries that reuse libssl, such as ssleay32.dll in Foxit Reader, partially reuse OpenSSL, despite their relatively low match scores. In contrast, libopenjp2-7.dll in GIMP has a fairly high matching score with LibPNG because the code snippets in libopenjp2-7.dll are similar to those in LibPNG. However, this code snippet is actually compiled by OpenJPEG's libpng module, which may be a variant of the original libpng. Therefore, the reuse between libopenjp2-7.dll and LibPNG should be eliminated, which is called pseudo propagated reuse.
We observe that in order to identify partial reuse and pseudo-propagated reuse, it is necessary to consider the complex code structure of OSS projects. To do this, we first decompose the OSS project into independent library modules, and build a mapping from source files to generated libraries by analyzing their compilation process. This is established by comparing matching sets of feature instances in the two OSS projects. As shown on the right side of Fig. 3, since the set of matched feature instances in OpenJPEG contains the set of matched feature instances in LibPNG, an inclusion edge from OpenJPEG to LibPNG is added. These two types of code structures help identify such reuse.
Selecting Code Features
In this section, we detail the design of B2SFINDER for detecting OSS multiplexing in COTS software.
Due to the significant differences between source code and binary code representations, the selected code features are expected to provide a unified way to achieve feature matching. There are two criteria for selecting code features. First, code features must appear in both the binary and source code. Second, no drastic changes should be made to code features in the source code during compilation. Table 1 lists a total of 10 candidate code features, covering all features used in existing binary similarity analysis techniques. All 10 features meet the first criterion, but only 7 of the 10 features meet the second criterion.
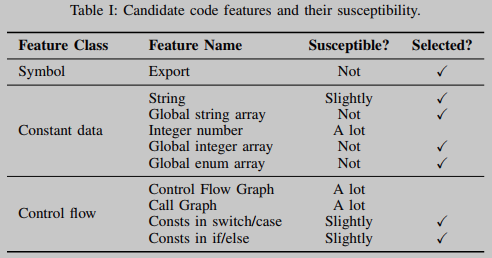
String literals and exported function names are traditional code features that also apply to COTS software. However, some OSS projects, such as UnRAR and bzip2, may not contain any useful strings for matching purposes, and moreover, COTS software applications often end up with string literal stripping to hide their software composition. In many OSS projects, when the code in the OSS project is called internally, the exported function names are often hidden. Therefore, new code features are required.
Numerical and control flow related functions can be invaluable. Constants are widely used in previous binary analysis work [3, 9, 10, 15, 17], but not all of them are suitable for our setting. We found that numeric constants in source code that appear as direct values in instructions in their compiled binaries are heavily influenced during compilation. In contrast, global integer arrays, global enumeration arrays, and global string arrays are generally unaffected. In addition, these global arrays usually contain some key information in OSS projects.
Compared to numerical features, control flow-related features can be changed more easily by compiler optimizations applied during compilation. Under different compiler flags, the binary code generated by the same source function may have completely different control flow structures. A program's call graph is also affected by function inlining. Therefore, control flow graphs (CFGs) and call graphs (CGs) between binary code and source code cannot be directly compared. Fortunately, complex branching sequences, such as complex switch/case and if/else statement structures, as shown in Listings 1 and 2, are relatively stable during compilation. Constants in these structures were also selected as code features.
Matching Code Features
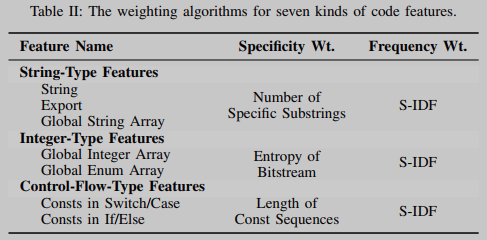
We classify the seven code features into three different types: string, integer, and control flow, as shown in column 1 of Table 2. Different methods will be used to match different types of code signatures.
An exact match for character string type . Since strings are always constant during the compilation phase, strings extracted from binary code and strings extracted from source code are considered equivalent if they are the same.
Search-based integer feature matching . Global integer/enum arrays are stored in the data segment of the binary as a seekable continuous bitstream.
Semantic-based control flow type feature matching . The semantics of switch/case constructs and if/else sequences are compared as follows. For switch/case features in OSS project source code, we represent it as an unordered list of case label sets with the default branch attached.
Determining the Importance-Weights of Feature Instances
As the size of OSS projects grows, the number of feature instances extracted from these OSS projects will increase rapidly. In fact, feature instances play different roles in feature matching. Therefore, we can reduce the time spent on feature matching by only considering relatively important feature instances. To distinguish the contribution of feature instances to feature matching, each feature instance is assigned a specificity weight and a frequency weight. These two weights measure the contribution of feature instances based on the information carried and their frequency of occurrence in OSS items, respectively. Take the S table ({0x8defc240, 0x25fa5d9f, ...}) in the CAST5 cipher as an example. It is unique and unlikely to be similar to other data. Therefore, this S-table will have a larger specificity weight. However, CAST5 is a popular cipher, and at least 15 OSS projects contain this S-table. Since such frequent occurrences do not help much in reuse detection, this S-table will be assigned a relatively small frequency weight.
As shown in Table 2 (columns 2 and 3), all code features rely on the same algorithm S-IDF (a variant of TF-IDF) to compute their frequency weights. For three different types of features, three different methods are used to calculate the specificity weights of features. For properties of type string, we use the number of its substrings, including url and copyright information (among others). For integer features, use the entropy of its bitstream. For a control-flow-type trait, use the length of its constant sequence.
1) Compute bitstream-specific weights as entropy: Although many global arrays (such as the S-table of CAST5 ciphers) are specific, there are still many other arrays that contain little useful information. For example, [0x0001, 0x0010, 0x0100, 0x1000] as a list of flag bits has the same bit stream as many irrelevant data, which may cause some incorrect matches. To this end, we propose a bitstream entropy algorithm for computing specificity weights for integer features.

During feature matching, an array of integers is converted into a bitstream, as shown in Table III. Specifically, a bitstream is partitioned into a list of bit fragments, where each fragment represents the largest sequence of the same bit value (0 or 1).
Computing S-IDF with frequency weights: The occurrence frequency of a feature instance is another factor that determines its contribution in the overall feature matching process. For example, the constant table in the UnRAR project exists in only one OSS project, while the constant table in the CAST5 cipher exists in at least 15 OSS projects. If the previous table is a match, we can easily determine that the UnRAR item has been reused. However, if the latter table is found, it is not so easy to make a decisive decision.
Computing Matching Scores
Matching scores are computed from matched weighted feature instances, increasing with the number of matching feature instances. We therefore qualify it from above with a threshold that is determined empirically for each feature. A target binary is considered to have a reuse relationship with the corresponding source code if the matching score of any feature is greater than its threshold. Algorithm 1 shows how to compute the matching score. Given a binary file b and a set of candidate OSS items S, our method determines a set of OSS reuse R based on seven code characteristics F.

Identifying Reuse Types
For a given feature instance, the presence of reuse relations is not always positively correlated with its matching score, as shown in Table 4. In all three examples, simple reuse performed consistently in terms of code similarity. Conversely, partial reuse represents true reuse but with a lower matching score; pseudopropagated reuse represents spurious reuse but with a higher matching score.

Identifying Partial Reuse: Partial reuse is common because COTS software applications typically share only part of an OSS project. To reduce the false positive rate caused by partial reuse due to low matching scores, we identify independent libraries by constructing Compilation Dependency Layer Graph (CDLG), and use individual libraries instead of entire OSS projects as code matching units.
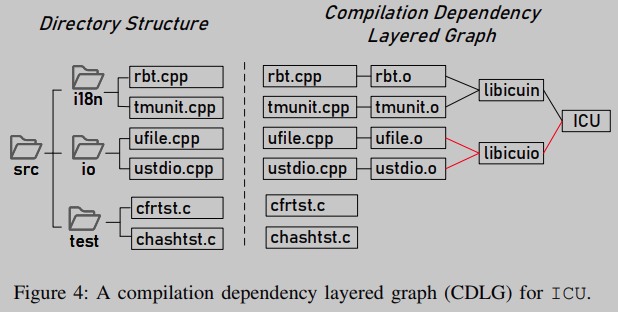
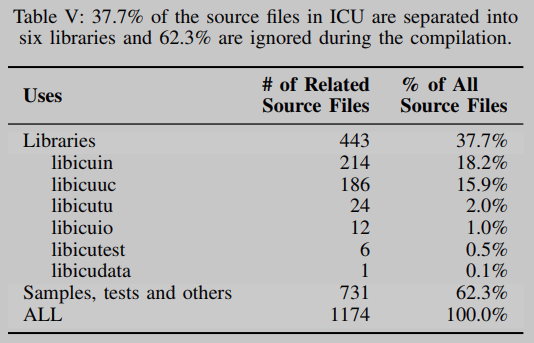
Taking the project ICU supporting unicode as an example, its CDLG is shown in Figure 4. Source files belonging to different libraries are separated in different groups. In addition, 62.3% of the source files that are not related to any library are no longer analyzed, as shown in Table 5.
Identify spurious propagating reuses: These are spurious reuses caused by the propagation of unrelated reuse relationships between candidate OSS projects. For example, libopenjp2-7.dll in GIMP reuses OpenJPEG, which includes LibPNG as a third-party library. The matching score between libopenjp2-7.dll and LibPNG is high, but the relationship between them is pseudo-propagated reuse.

experiment
IMPLEMENTATION
We implement a file-level matching framework, B2SFINDER, for OSS reuse detection in COTS software.
Figure 5 depicts the architecture of B2SFINDER. There are three modules, extractor, matcher and detector. Extractor extracts code features from binary code and source code, and then stores them using an efficient storage model to improve efficiency. Compiler and linker command lines are also parsed to increase the robustness of the extractor. Matcher is responsible for code feature matching between binary code and source code by applying our matching method and computing a matching score. The detector identifies reuses based on the matched set of feature instances and the CDLG of OSS items, and generates a list of reuse relationships for the target COTS software.
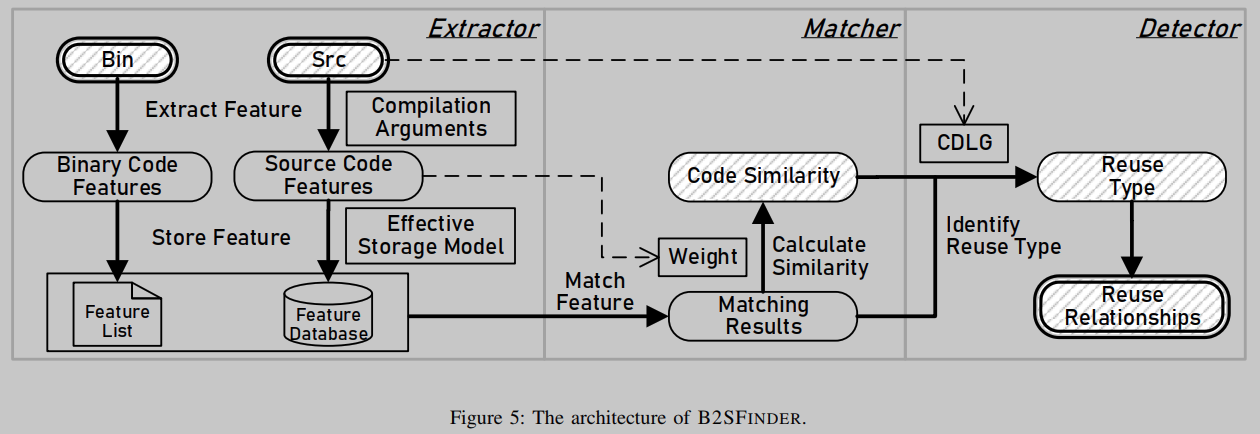
We extract code features from source code by developing some static analysis tools on LLVM and Clang. However, static analysis must be done with care. In many OSS projects, the header files are stored in some independent directories, instead of being stored in the directory where the OSS project is located, resulting in some header files being missing. Also, the specific version of macros used for conditional compilation may depend on the environment and specific compiler used, leading to missing or incorrect use of some macros.
To avoid these problems, we proceed in three steps. First, we search for files like CMAKELISTS.txt and autogen.sh in the OSS project to automatically detect the MAKEFILEs used. Second, we parse these MAKEFILEs for the gcc or libtool commands used without fully compiling the OSS project. Finally, we locate the include paths and macros used from the arguments supplied to the compiler flags -I and -D.
The time complexity of feature matching is closely related to the storage mode of code features. In a simple implementation, analyzing a single COTS product could take a day. To shorten this process, we use two data structures, an inverted index and a Trie.
inverted index . In order to speed up string search, we built an inverted index for string features in the key-value database Cassandra. Since Cassandra relies on hash trees, the average time complexity of retrieving a string has been effectively reduced from O(M) to O(1), where M is the number of string literals in the OSS project.
Word lookup tree . We build a Trie for two integer features (global integer array and global enum array). Trie is an ordered data structure based on the prefix of the target data. When searching for an array in a binary, if the prefix array does not exist, the Trie is traversed and its subtrees are pruned.
Datasets
We evaluated B2SFINDER in terms of accuracy and efficiency. We then present our findings on detecting OSS reuse vulnerabilities in a large number of real COTS software products. We use two binary code datasets and one source code dataset described below.
Dataset 1: Binaries (B1) with known reuse. This dataset contains 46 official (stripped) binaries compiled from 23 commonly used open source projects, covering different application domains, including video parsing (e.g., VLC), PDF rendering (e.g., SumatraPDF), and network protocols (e.g., OpenSSL).
Dataset 2: Real-world COTS software (B2). This dataset contains 21991 binaries from 1000 COTS software products obtained from a collection of Web sites. We give a hash list of these products on https://github. com/1dayto0day/B2SFinder/COTS list.txt.
Dataset 3: Public open source library(s). The dataset consists of 2189 open source libraries scraped from Ubuntu packages (Ubuntu's official package archive).
Precision
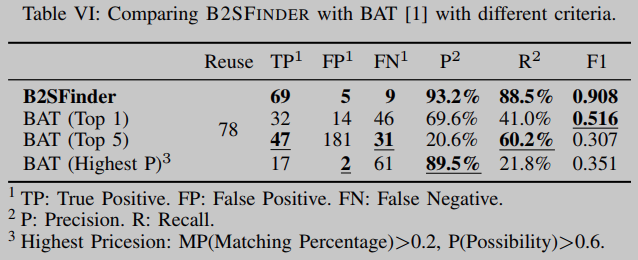
To measure the accuracy of B2SFINDER, a benchmark suite consisting of 46 official binaries (Dataset B1) and 2189 OSS items (Dataset S) is used. We manually marked a total of 78 genuine reuses in the benchmark suite, including simple reuses, partial reuses, and pseudo-propagated reuses. Based on tagged reuse, we compare B2SFINDER with BAT, the only binary-to-source matching tool that can handle both PE and elf format executables and dynamic libraries. We summarize the experimental results in Table VI.
Efficiency
We apply B2SFINDER to analyze 21991 binaries from 1000 real-world COTS software products (Dataset B2) and 2189 public open source libraries (Dataset S) on four virtual machines in the OpenStack cloud. Each virtual machine is equipped with two shared cores of Intel Xeon E5-2603 V4, 4GB memory and 128GB disk.
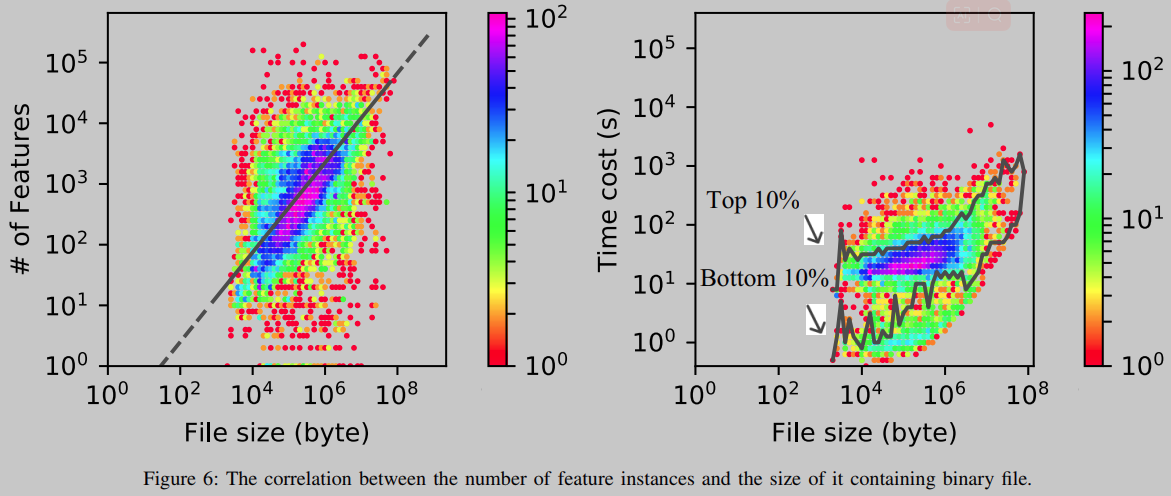
As shown in Figure 6, the number of feature instances scales roughly linearly with the size of the binary containing it. Analyzing 91.4% of all binaries takes less than 100 seconds, which is fast enough for offline deployment.
Large-Scale Analysis
We now describe our findings detecting OSS reuse vulnerabilities in large-scale real-world COTS software products.
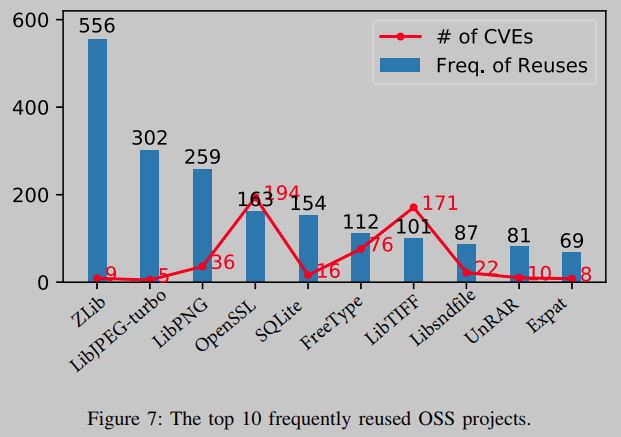
OSS Reuse: We found 10208 pairs of reuse relations between 21991 binaries in dataset B2 and 2189 OSS items in dataset s. As shown in Table VII, 19.2% of binaries (contained in 63.4% of all COTS software products) were found to reuse at least one open source library. This shows that OSS reuse is ubiquitous in COTS software.

Among the 2189 OSS items studied, 4.6% of the items were reused more than 10 times. However, the frequency with which these OSS items are reused varies from project to project. As shown in Figure 7
Summarize
RELATED WORK
Binary-to-Source Matching
There are relatively few studies on binary-to-source matching, including BAT [1], OSSPolice [2] and FIBER [13]. BAT [1] takes string literals as unique code features and generates a sorted list for potential OSS reuse. OSSPolice [2] not only considers string literals, but also takes exported function names as code features, and introduces a hierarchical indexing scheme to index features. FIBER [13] generates a semantic signature on the control flow of a function, assuming the target function is known, to identify the syntactic and semantic changes introduced by the patch.
References
[1] A. Hemel, K. T. Kalleberg, R. Vermaas, and E. Dolstra, “Finding software license violations through binary code clone detection,” in Proceedings of the 8th Working Conference on Mining Software Repositories. ACM, 2011, pp. 63–72.
[2] R. Duan, A. Bijlani, M. Xu, T. Kim, and W. Lee, “Identifying opensource license violation and 1-day security risk at large scale,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017, pp. 2169–2185.
[3] Z. Li, D. Zou, S. Xu, H. Jin, H. Qi, and J. Hu, “Vulpecker: an automated vulnerability detection system based on code similarity analysis,” in Proceedings of the 32nd Annual Conference on Computer Security Applications. ACM, 2016, pp. 201–213.
[6] Transforming Open Source to Open Access in Closed Applications: Finding Vulnerabilities in Adobe Reader’s XSLT Engine, Zero Day Initiative (ZDI) Std., May 2017. [Online]. Available: https://static1.squarespace.com/static/5894c269e4fcb5e65a1ed623/t/592493f140261d8c41ae30c1/1495569406556/ZDI-Adobe_XSLT_Report.pdf
[7] mpengine contains unrar code forked from unrar prior to 5.0, introduces new bug while fixing others. [Online]. Available: https://bugs.chromium.org/p/project-zero/issues/detail?id=1543&desc=2#maincol
[8] Synopsys 2018 open source security and risk analysis report. [Online]. Available: https://www.synopsys.com/content/dam/synopsys/sig-assets/reports/2018-ossra.pdf
[9] S. Eschweiler, K. Yakdan, and E. Gerhards-Padilla, “discovre: Efficient cross-architecture identification of bugs in binary code.” in NDSS, 2016.
[10] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural networkbased graph embedding for cross-platform binary code similarity detection,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017, pp. 363–376.
[11] B. Liu, W. Huo, C. Zhang, W. Li, F. Li, A. Piao, and W. Zou, “αdiff: cross-version binary code similarity detection with dnn,” in Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering. ACM, 2018, pp. 667–678.
[12] Ubuntu packages. [Online]. Available: https://packages.ubuntu.com/
[13] H. Zhang and Z. Qian, “Precise and accurate patch presence test for binaries,” in 27th {USENIX} Security Symposium ({USENIX} Security 18), 2018, pp. 887–902.
[14] Y. Xue, Z. Xu, M. Chandramohan, and Y. Liu, “Accurate and scalable cross-architecture cross-os binary code search with emulation,” IEEE Transactions on Software Engineering, 2018.
[15] Q. Feng, R. Zhou, C. Xu, Y. Cheng, B. Testa, and H. Yin, “Scalable graph-based bug search for firmware images,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016, pp. 480–491.
[17] W. M. Khoo, A. Mycroft, and R. Anderson, “Rendezvous: A search engine for binary code,” in Proceedings of the 10th Working Conference on Mining Software Repositories. IEEE Press, 2013, pp. 329–338.
Insights
(1) The jump branch sequence can be used as .textone of the characteristics of the segment