Article directory
- foreword
- Introduction to Network Protocol Stack
- Execute the correct protocol handler function
- Organization of protocol handler functions
- Registration of protocol handler functions
- Ethernet and IEEE 802.3 frames
- Tuning via the /proc filesystem
- Involved functions and variables
- Files and Directories Involved
foreword
A protocol is the architecture of all communication: instructing each communicator how to understand the other end of the conversation. In Linux, the understanding of communication is through the protocol processing functions of each layer in the network. This article explains how these handlers are installed, selected during execution, and enabled.
Introduction to Network Protocol Stack
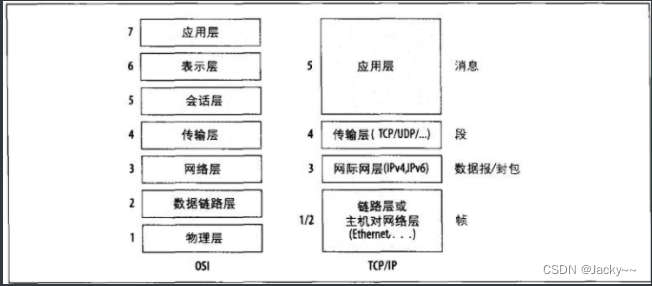
I think you should be familiar with TCP/IPthe protocol, however there are some protocols that are also common, such as LLC(Logical Link Control,逻辑链接控制)and SNAP(Sub network Access Protocol,子网访问协议), but you may not understand it yet. We will introduce some key agreements and the relationship between them. The two most famous models of network protocols are 七层的OSI模型以及五层的TCP/IP模型. As shown below. Even though it was not actually implemented for various reasons, the OSI model has always been an important reference point when discussing network links. The TCP/IP model encompasses most of the protocols used by computers today.
There are even many protocols available in each layer. Data is exchanged at the lowest layer interface, and the protocol used is predetermined. A protocol's driver is associated to that interface, and all data coming to that interface is assumed to conform to that protocol (that is, Ethernet). If not, an error will be reported and no communication will occur.
However, once the driver must hand over the data to the upper layer, the problem of protocol selection occurs. IPv4、IPv6、IPvX(Novell NetWare协议)、DECnet或其他网络层协议Which protocol should L3 data handle? Also, a similar selection needs to be made when going from L3 to L4; L4 is available TCP、UDP、ICMP以及其他协议.
We mainly introduce the lowest three layers here, and the fourth layer will be briefly mentioned:
Data transmitted in a single packet is usually called a frame at the link layer, a packet at the network layer, a port at the transport layer, and a message at the application layer.
These layers are often referred to as the network protocol stack, because communication travels down through the layers until it actually travels over the wire (or wireless channel) and back again. Headers are also LIFOadded and removed in the same way.
big picture
The image below is built on top of what is shown in the image above TCP/IP模式. Shows which chapter describes each interface between adjacent layers. Some interfaces involve communication from the top of the protocol stack to the bottom, while others are from the bottom to the top of the protocol stack.

-
Pass up in the protocol stack (for receiving information)
-
Pass down the protocol stack (used to transmit information)
We are not discussing the socket interface here. However, AF_PACKETone thing worth mentioning about the socket type is the way Linux captures frames at the link layer and injects them into the link layer: all intermediate protocol layers are skipped. Network sniffers (eg tcpdump和Ethereal) are AF_SOCKETthe most common users of sockets. It can be seen from the figure that AF_{ACKET}套接字the frame is handed over directly dev_queue_xmit, and the ingress frame is directly received from the network protocol dispatch function.
The figure above shows only two protocol families ( PF_INET, PF_PACKET), but the Linux kernel also implements a variety of other protocols. For example:
-
PF_NETLINK- good network interface
-
PF_KEY- Key interfaces of network security services
-
PF_LLC- See the section called "Logical Link Control (LLC)"
Ethernet link layer selection (LLC and SNAP)
Although the link layer protocol will be bound by the hardware used, the Ethernet standard allows us to make some choices between the protocols. The protocol that first attempted to standardize this choice is called LLC(逻辑链接控制). Because the options offered by an LLC are limited, they are rarely used. Subsequently, IEEE 802 committee members developed SNAP(子网络访问协议)protocol standards, which are now quite common. The implementation of these word protocols will be described later.
In LLC, the header contains a field that indicates SSAP(Source Service Access Point,来源地服务访问点)the protocol and DSAP(Destination Service Access Point,目的地服务访问点)the protocol. However, each field has only 8 bits, one of which indicates whether the multicast flag is used, and the other indicates whether the address is a regional address of a network or a globally recognized address. Therefore, only 6 bits are left to specify the protocol, because LLC can only support up to 64 protocols, making this technology difficult to popularize.
For the above reasons, the IEEE 802 committee SSAP和DSAPprovides a special value in the field, which in turn extends LLC. This special value indicates the protocol used by the source or destination is identified by another 5 bytes in the header. With this extension (renamed SNAP), there are 40 bits that can be assigned to various protocols.
How the network protocol stack operates
Let's briefly examine a communication paradigm to understand how to choose between communication points.
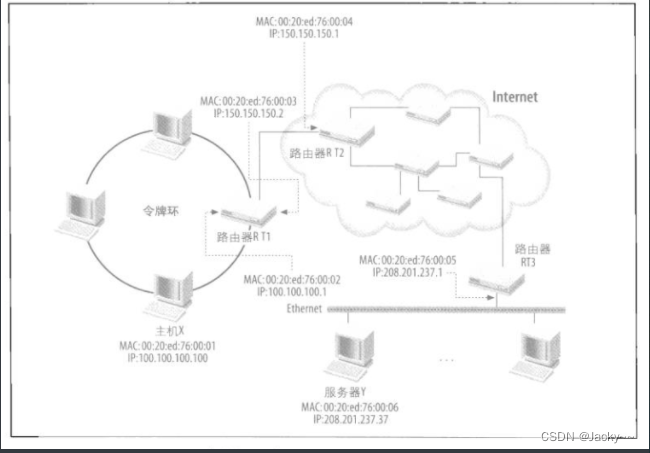
As shown in the figure below, suppose there is a user on host X who wants to use a web browser to download an HTML page from the web server on server Y. To answer the following questions:
-
Host X and server Y are on different LANs, how do they talk to each other?
-
Host X doesn't know where server Y is actually located, how does host X know where to send the request?
-
If server Y is running more than one application (not just a web server), how does its operating system determine which application should handle a request from host X?
-
If there is more than one application (not just a browser) running on host X, how does its operating system determine which application should receive the returned data?
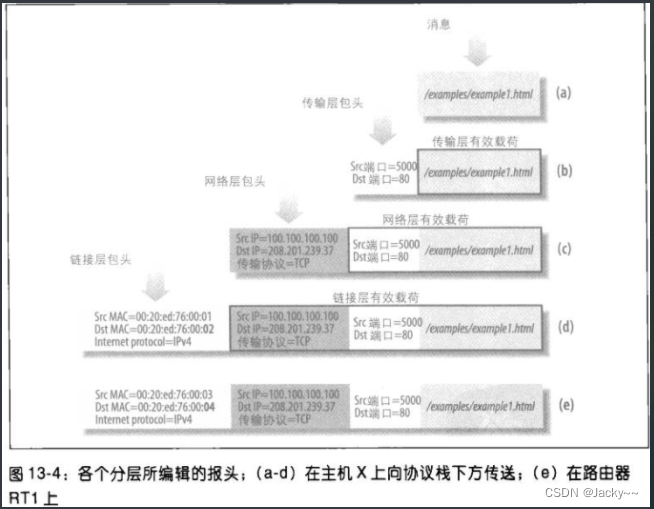
Let's follow the request of the web page and walk through the network protocol stack to see how these questions are answered. We use the picture above and the picture below as a reference
-
应用层、主机X- The browser reads the URL requested by the user, assuming it is
http://www.oreilly.com. The browser uses the Domain Name System (Domain Name System, not discussed) towww.oreilly.comresolve the URL into an IP address (assuming it is208.201.239.37). As for how to find out the path between the host X and the server Y using this address, it is the matter of the IP protocol (L3, network layer). Now, the browser208.201.239.37starts an HTTP session at the application layer, and then, the browser enables TCP to take the traffic to the remote web server (TCP is used instead of UDP because HTTP requires a reliable channel to transfer large amounts of data without causing corruption ). Now, requests are sent down the network protocol stack.
- The browser reads the URL requested by the user, assuming it is
-
传输层,主机X-
The TCP layer will divide the HTTP message request into several segments when necessary, and then add a TCP header to each segment. Additionally, TCP adds source and destination ports. The port number allows the operating system to direct requests to the correct application. Server Y's web server listens on the default HTTP port
80, unless explicitly configured to use another port number, and gets all traffic there. Server Y will direct the response to port 5000 of host X, which is the source port number, and the request received by the server is sent from this port of the host. -
The port number is an L4 concept, so each of TCP and UDP has a set of ports available.
-
The TCP layer at host X knows that the destination port is 80 because the browser uses the default port assigned to the HTTP protocol (unless a different port is provided in the URL). The source port assigned to the browser (designating the destination application when processing ingress traffic) is assigned by the OS (unless the application requires a specific port). We assume that the port is 5000. The two sessions can use different ports.
NAT(Network Address Translation,网络地址转换)and proxy firewalls (proxying firewall) complicate the topic, but the discussion here should provide a clear outline of how applications communicate with each other. The TCP layer doesn't know how to send those stages to the destination. Therefore, the TCP layer will enable the IP layer, passing the destination IP address in each transmission request.
-
-
网络层、主机X-
The IP layer doesn't care about applications or ports. All it does is check the packet's IP address and IP-related networking options. Its heavy responsibility is to query the routing table (a very complicated process, which will be analyzed later) to find out that the packet should pass through the router RT1. The IPv4 protocol will be explained later.
-
The packet has to pass down to another layer so that it can be delivered to the router, but the IP layer must find out the correct address of the router at this layer. Because L2 involves communication between adjacent hosts (such as hosts sharing a LAN or point-to-point links), the process used by the IP layer to find out the L2 address associated with a specific IP address is called the neighbor protocol (neighbor protocol). It will be explained later.
-
-
链路层,主机X和路由器RT1-
Part of this layer is implemented by device drivers. On a LAN, Ethernet is the most common protocol, but many
ATM、Token Ring、FDDIothers exist. Long-distance links use specialized copper or fiber-optic cables; the simplest links are the dial-up connections established by millions of home and small office users through their ISPs. LAN makes its own (L2) addressing scheme independent of TCP/IP. For Ethernet (and IEEE 802 networks in general), addresses are 6 octets and are often calledMAC地址. On dedicated lines (such as dial-up links) there is no need for L2 addressing because each side transmits directly to the other. -
Different links may use different types of headers, since each is hardware dependent. The information carried by these headers is meaningless to browsers and servers at the application layer.
-
-
路由器RT1、RT2等等-
Each router in the path (except the last) forwards the packet to its final destination through the following process:
-
remove link layer header
-
Due to specific subsections in the link layer header, it can be seen that the L3 layer protocol is IP.
-
Determined that the local system is not the packet's destination because the destination IP address in the IP header is not among its own IP addresses.
-
Forward the IP packet to the next router on the path to server Y. To do this, a router consults its routing table to choose a next-hop router, and then builds a new link-layer header.
-
-
Normally, the information on the L3 (IP header) does not change when the packet is transmitted between systems. Instead, a different L2 header is used on each link.
-
When the packet finally reaches router RT3, RT3 will find that server Y is directly connected to it, so there is no need to detour the packet to another hop.
-
Once the message reaches the destination server, it traverses the network protocol stack from bottom to top.
-
-
链路层,服务器Y- When stripping the L2 header, this layer checks a field to know which protocol should handle the L3 layer. Knowing that L3 is handled by IP, the link layer will enable the appropriate function to continue processing L3 packets (that is, L2 payload). Most of this chapter discusses how protocols are registered, and handles key fields that indicate which protocol to use.
-
网络层、服务器Y- This layer recognizes that its own system's IP address (
208.201.239.37) is the destination address in the packet, and therefore, the packet should be received and processed locally. The network layer strips off the L3 header and checks a field again to see which protocol handles L4.
- This layer recognizes that its own system's IP address (
We already know that each layer provides a variety of protocols, and each protocol is handled by a different set of kernel functions. Therefore, when the packet is sent back up the protocol, each protocol must figure out which protocol is used by the next higher layer, and then invoke the appropriate kernel function to process the packet.
At the lowest software layer L2, the hardware used determines the protocol used. If the frame is received on the Ethernet interface, the receiver knows it contains an Ethernet header, the Token Ring interface knows it contains a Token Ring header, and so on. No ambiguity here unless LLC or SNAP is specified. LLC and SNAP are introduced later.
As a packet travels up the network protocol stack, each protocol requires a field in its header indicating which protocol should be used for the next stage of processing. This process is as follows
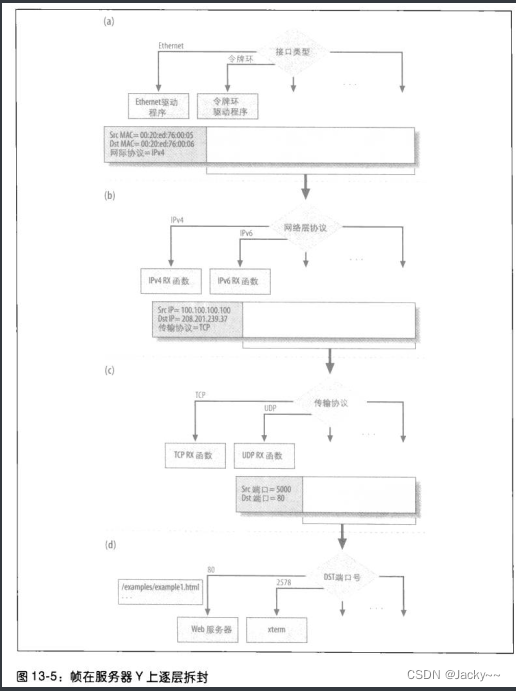
Therefore, when going from L2 in a to L3 in b in the figure, it depends on L2 to check the "upper layer protocol" field in the L2 header. Likewise, the L3 layer checks a field within its header to facilitate a transfer to L4, as shown in b and c. Finally, L4 uses the packet's "destination port" field to get the packet out of the kernel, and then finds out which process (such as a web server) is handling the packet on the local host.
Execute the correct protocol handler function
For every network protocol, no matter what layer it is in, there is an initialization function. These include L3 protocols (such as IPv4 and IPv6), link layer protocols (such as ARP) and so on. For protocols statically included in the kernel, the initialization function is executed during boot, for protocols compiled into a module, the initialization function is executed when the module is loaded. This function allocates internal data structures, notifies other subsystems about the existence of the protocol, /procregisters files in it, and so on. A key task is to register a handler function within the kernel to handle traffic for this protocol.
For brevity, we will illustrate how the device driver enables the L3 protocol, however, the same principle applies to any protocol at any layer.
When the device driver receives a frame, it saves it in a buffer data structure, and then initializes the fields sk_buffshown below :protocol
struct sk_buff
{
... ... ...
unsigned short protocol;
... ... ...
}
The value of this field can be whatever is used by the kernel to identify a particular protocol, or a field in a MAC header of an incoming frame. This field will netif_receive_skbbe queried by the kernel function to determine which function should be executed to process the L3 packet. Refer to the picture below:
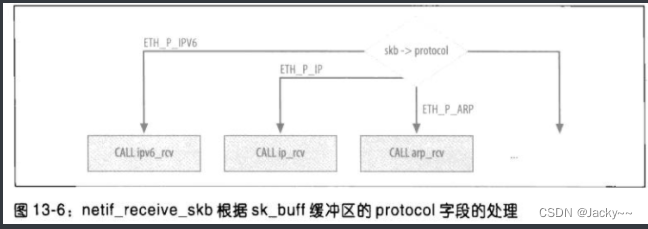
protocolMost of the protocol-related values used by the kernel in fields are listed include/linux/if_ether.hin , named ETH_P_XXX. Despite ETHthe prefix, not all names refer to Ethernet hardware. The following table lists the values used internally by the kernel, and these values are assigned directly by the device driver skb->protocolinstead of being stripped from the frame header (the values omitted in the table do not dispatch function handlers). For example, the first column in the table indicates that the kernel handler function ipx_rcvis used to process an input packet, and its skb->protocolfield is ETH_P_802_3.
| symbol | value | function processing function |
|---|---|---|
| ETH_P_802_3 | 0x0001 | ipx_rcv |
| ETH_P_AX25 | 0x0002 | ax25_kiss_rcv |
| ETH_P_ALL | 0x0003 | This is not a real protocol, but a wildcard as a handler, like a packet sniffer that listens for all protocols. |
| ETH_P_802_2 | 0x0004 | llc_rcv |
| ETH_P_TR_802_2 | 0x0011 | |
| ETH_P_WAN_PPP | 0x0007 | sppp_rcv |
| ETH_P_LOCALTALK | 0x0009 | ltalk_rcv |
| ETH_P_PPPTALK | 0x0010 | atalk_rcv |
| ETH_P_IRDA | 0x0017 | irlap_driver_rcv |
| ETH_P_ECONET | 0x0018 | econnet_rcv |
| ETH_P_HDLC | 0x0019 | hdlc_rcv |
Not all ETH_P_XXXvalues dispatch a handler function. It can be left unspecified in two cases:
-
This protocol has no handler function (that is, the kernel does not support it).
-
Another protocol handler function can handle the protocol indirectly, as in the case of SNAP. This situation is discussed in the sections "Logical Link Control (LLC)" and "Subnetwork Access Protocol (SNAP)".
Unfortunately, it is not possible to find out which processing function is enabled just by taking out the fields in the L2 header; skb->protocolthe association with the protocol processing function that processes the frame is not necessarily one-to-one. In some cases, a specific ETH_P_XXXprotocol handler function will actually just read other parameters from the frame header (no frame processing), and then hand off the frame to another protocol handler function that will process the frame. One example of this is ETH_P_802_2handler functions.
As described in the previous section, netif_receive_skbis the function that dispatches the incoming frame to the correct protocol handler. When no handler is available for a particular protocol, the frame is dropped.
In special cases, a single packet can be passed to multiple handler functions. This is the case, for example, when a packet sniffer is running. This mode of operation is sometimes called promiscuous mode, which is what is shown in the table ETH_P_ALL. Such handlers are usually not used to process packets for the receiver, but rather to spy on a specific device or group of devices for error correction or gathering statistics.
special media package
Ethernet is by far the most common mechanism for implementing shared and peer-to-peer networking. When discussing L2 in this book, always refer to Ethernetthe device driver. However, Linux allows you to use any of the most common media (mdia) to carry IP traffic (and sometimes any network protocol traffic) on a PC today. Examples of media that can be used to transport IP include serial and parallel ports ( SLIP/PLIP/PPP), FireWire(eth1394), USB, 蓝牙(Bluetooth)and IrDAothers.
Such media define network devices as an abstraction layer of generic ports, usually by extending generic media device drivers. These virtual devices look like real NICs to those upper layer devices.
Here's how receive and transmit are implemented on these virtual network devices:
-
传输net_device的hard_start_xmitThe virtual device function pointer is initialized by the device driver as a function capable of encapsulating an IP packet (assuming it is an IP packet) according to the protocol used by the medium.
-
接收- When a generic driver receives data from one of its ports, it strips off the media header (just as an Ethernet device strips off the Ethernet header),
skb->protocolinitializes it, and then callsnetif_rxto notify its upper layers. When these media are only used for point-to-point connections, there is no need to use the link layer header, so itskb->protocolwill be initialized staticallyETH_P_IP; in other cases, the media package may also include a hypothetical Ethernet header, soskb->protocolit will be initialized byeth_type_transthe function (as in the real Ethernet drivers do).
- When a generic driver receives data from one of its ports, it strips off the media header (just as an Ethernet device strips off the Ethernet header),
How to interface a generic device driver for a given media type with a virtual network device is an implementation detail. Depending on the medium, it may provide a synchronous or asynchronous interface, or use buffering mechanisms on the receive and transmit paths, etc.
Organization of protocol handler functions
The figure below shows how various protocol processing functions are organized in the kernel. Each protocol packet_typeis described by a data structure

For faster access, most protocols use a simple hashfunction. The 16 lists are organized into an array, which is what the global variable ptype_baserefers to. When a protocol is dev_add_packregistered with a function, the function executes hashthe function on the protocol type and dispatches packet_typethe structure to one of 16 lists. Later, to find a ptype_typestructure, the kernel simply re-runs hashthe function and iterates over the list of matches.
Those ETH_P_ALLprotocols are organized in the list they belong to, which is what the global variable ptype_allrefers to. The protocol numbers are stored in this list netdev_nit. And dev_queue_xmitthe sum qdisc_restartwill use netdev_nitcheck to see if a PF_PACKETsocket is open (i.e. a sniffer in listening) so that it can pass a copy of the incoming frame.
Registration of protocol handler functions
Whether it is system startup or other moments, when a protocol is registered, the kernel will call dev_add_packand pass in a data structure include/linux/netdevice.hdefined in the type :packet_type
struct packet_type
{
unsigend short type;
struct net_device *dev;
int (*func)(struct sk_buff *, struct net_device *,
struct packet_type *);
void *af_packet_priv;
struct list_head *list;
};
The meaning of these fields is as follows:
-
type- protocol code. This value can be one of any of the values listed in the table above, and the differences between protocols in different tables will be explained later
-
dev- A pointer to the device (eg
eth0) that the protocol is enabled for this device. When set to NULL, refers to "all devices". Due to this parameter, different devices may have different processing functions, or a specific processing function may be associated with a specific device. Usually this is not done, but helps with testing.PF_PACKETSockets are often used to listen to specific devices. For example,tcpdump -i eth0a command like this wouldPF_PACKETcreate anpacket_typeinstance over a socket and initialize dev asnet_devicethe instance associated with eth0.
- A pointer to the device (eg
-
func- This function is called when a
netif_receive_skbframeskb->protocol=type(eg ) has to be processed.ip_rcvNote thatfuncone of the input parameters to this is apacket_typepointer to a structure: this structure isPF_PACKETused by the socket to accessaf_packet_privfields.
- This function is called when a
-
af_packet_priv- Used by
PF_PCKETsockets. This is a pointer to the data structurepacket_typeassociated with the creator of the structuresock. This field allowsdev_queue_xmit_nitpassing no buffer to the sender andPF_PACKETpassing the input data to the correct socket by the receive function.
- Used by
-
list- Used to link this data structure with other
bucketconflicting instances in the same list.
- Used to link this data structure with other
When you have multiple packet_typeinstances associated with the same typeprotocol, then matching typeinput frames are forwarded functo all of those protocol handler instances by enabling them.
When registering for each protocol, the kernel packet_typeinitializes the structure and then calls it dev_add_pack. Here is an net/ipv4/ip_output.cexample taken from , showing how IPv4 key code registers IPv4 protocol handler functions.
ip_initThe function is executed when the IPv4 protocol is initialized during boot . One of the consequences is that packet_typefunctions in the IPv4 structure ip_rcvare registered as function handlers for this protocol. When all Ethernet frames are received, if ETH_P_IPthe value is Protocol Above, they will be processed by the function ip_rcv.
static struct packet_type ip_packet_type =
{
.type = __ocnstant_htons(ETH_P_IP),
.func = ip_rcv,
}
...
void __init ip_init(void)
{
dev_add_pack(&ip_packet_type);
...
}
dev_add_packetPretty simple: check if the handler to be added is a protocol sniffer ( pt->type == htons(ETH_P_ALL)). If so, the function adds it to ptype_allthe pointed-to list, then increments the number of registered protocol sniffers ( netdev_nit++). If the handler is not a sniffer, it will be inserted into ptype_baseone of the 16 lists indicated (depending on the hashed value). ptype_baseand ptype_allthe data structure referred to will be ptype_lockprotected by a spin lock.
void dev_add_pack(struct packet_type *pt)
{
int hash;
spin_lock_bh(&ptype_lock);
if(pt->type == htons(ETH_P_ALL)){
netdev_nit++;
list_add_rcu(&pt->list, &ptype_all);
}else{
hash = ntohs(pt->type) & 15;
list_add_rcu(&pt->list, &ptype_base[hash]);
}
spin_unlock(&ptype_lock);
}
Function dev_remove_pack, as its name implies and dev_add_packcomplementary.
void dev_remove_pack(struct packet_type *pt)
{
__dev_remove_pack(pt);
synchronize_net();
}
dev_remove_packwill delete the struct from the ptype_allor , but is used to ensure that no one still holds a reference to the deleted instance when it returns.ptype_basepacket_typesynchroize_netdev_remove_packpacket_type
If called within dev_add_packthe ambiguity responsible for module initialization , it is most likely called within (by the kernel when a module is about to be deleted) ( examples can be found in ). On the other hand, if the protocol is statically included in the kernel, it will be automatically registered during boot and will only be deleted when the system is shut down. The IPv4 protocol is never deleted during operation.init_moduledev_remove_packcleanup_modulenet/ax25/af_ax25.c
Ethernet and IEEE 802.3 frames
There are many protocols that fall under the broad term Ethernet. The 802.2 and 802.3 standards are represented by protocol ETH_P_802_2and respectively ETH_P_802_3, however, there are many other Ethernet protocols as shown in the table below, as well as the LLC and SNAP extension protocols. These standards constitute a means (about h_proto会在下一节讨论) sufficient to support all variant versions of the protocol.

Ethernet was designed before the IEEE established its 802.2 and 802.3 standards. The 802.2 and 802.3 standards are not pure Ethernet, but are commonly referred to as Ethernet standards. Fortunately, the IEEE 802 committee decided to make the protocols compatible. Each Ethernet card can receive 802 standard frame types as well as old-style Ethernet frames, and the kernel can provide a function to enable device drivers to recognize these frames.
The following is the definition of the Ethernet header:
struct ethhdr
{
unsigned char h_dest[ETH_ALEN]; /*目的地eth地址*/
unsigned char h_source[ETH_ALEN]; /*来源地eth地址*/
unsigned short h_proto; /*封包类型ID字段*/
}__ATTRIBUTE__ ((packed));
As we will see later when we discuss LLC and SNAP, other fields also focus on ethhdrstructure. The focus of our attention here is the protocol field h_proto. Nonetheless, it is actually possible to store the protocol being used or the length of the frame. This is because the size of this field is 2 octets, however, the maximum size of an Ethernet frame is 1500 bytes (actually, the size can be more if you include the SA, DA, checksum field and header content Type 1518 bytes. Frames using 802.1q have four extra encapsulation bytes, so the possible size is 1522 bytes).
In order to save space, IEEE decided to use a value greater than 1536 to represent the Ethernet protocol. Some pre-existing protocols (0x600 hexadecimal) that were still below 1536 after adding the identifier have also been updated to meet this criterion. However, the 802.2 and 802.3 protocols use this field to store the frame length. Values between 1501 and 1535 are illegal in this field.
The figure below shows several possible variants of the Ethernet header, 图athe simple Ethernet shown, and 图bthe 802.2 and 802.3 variants shown. As you can see, for the former, that field acts as a protocol field, while for the latter, it becomes the length field. In addition, 802 variants can also support LLC (图c)and SNAP (图d).
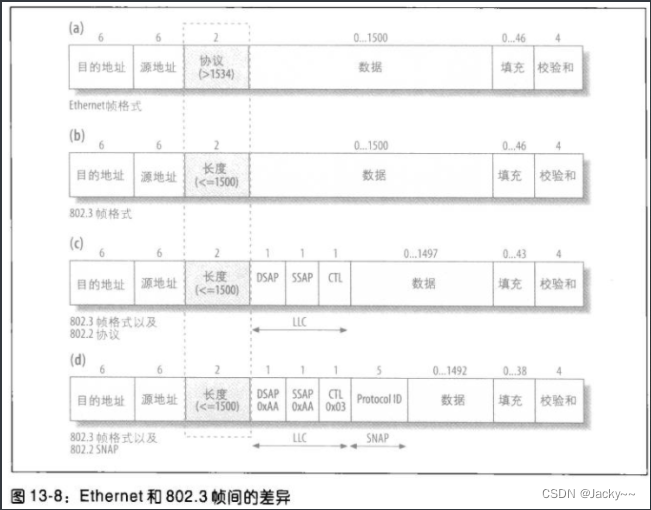
Linux eth_type_transcompletes this special distinction between protocol and length in functions. The following code snippets represent a typical environment. It is used when drivers/net/3c509.cthe Ethernet driver receives a frame. netif_rxThe function is responsible for copying the frame to the input queue, and then setting NET_RX_SOFTIRQthe flag to let the kernel know that there is a new frame in the queue. Before calling netif_rx, the caller must first call eth_type_transto do some important initialization work.
el3_rx(struct device *dev)
{
... ... ...
skb->protocol = eth_type_trans(skb, dev);
netif_rf(skb);
... ... ...
}
eth_type_transPerforms two main tasks: setting the packet type and setting the protocol. The work of setting up the protocol is done in its return value. Let’s explain the setting of the packet type first, and then return to the main topic of this section: the protocol.
Set packet type
eth_type_transThe function will skb->pkt_typeset to one of the values include/linux/if_packrt.hlisted in PACKET_XXX.
-
PACKET_BROADCAST- The frame is passed to the link layer broadcast address (for Ethernet
FF:FF:FF:FF:FF:FF)
- The frame is passed to the link layer broadcast address (for Ethernet
-
PACKET_MULTICAST- The frame is passed to the link-layer multicast address. Details are covered later in this section
-
PACKET_OTHERHOST- The frame is not intended to be delivered to the receiving interface. However, the frame is not discarded immediately, but passed to the next highest layer. As mentioned, there may be a protocol sniffer or other nosy protocol that wants to take a look at this frame.
When eth_type_transnot explicitly set skb->pkt_type, its value will be 0, ie PACKET_HOST. This means that the receiving interface is the receiver of the frame (from the link layer point of view, that is, the MAC address matches).
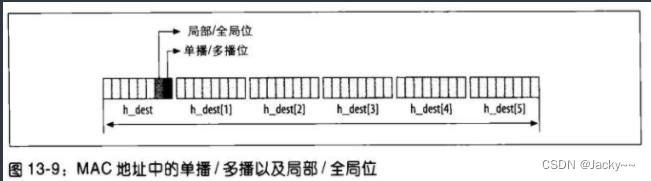
Most of the information needed to set the correct packet type is explicitly specified in the header. Ethernet addresses are 48 bits or 6 bytes long. The highest two bits of the first byte (the end of the network byte) have a special meaning: refer to the figure below
-
Bit 0 differentiates between multicast and unicast addresses. Broadcast addresses are a special case of multicast. When set to 1, this bit refers to multicast; when set to 0, it refers to unicast. After
if(*eth->h_dest & 1)checking this bit, this function will continue tomemcmp(eth->h_dest, dev->broadcast, ETH_ALEN)compare the broadcast address of this address device to know whether the frame is a broadcast address. -
Bit 1 differentiates between local and global addresses. Global addresses are globally unique, while local addresses are not: it is up to the system administrator to decide how to properly assign local addresses. When set to 1, this bit refers to the global address; when it is 0, it refers to the local address.
Therefore, eth_type_transthe beginning part of the following:
unsigned short eth_type_trans(struct sk_buff *skb, struct net_device *dev)
{
struct ethhdr *eth;
unsigned char *rawp;
skb->mac.raw=skb->data;
skb_pull(skb,ETH_HLEN);
eth=eth_hdr(skb);
skb->input_dev = dev ;
if(*eth->h_dest&1)
{
if(memcmp(eth->h_dest, dev->broadcast, ETH_ALEN)==0)
skb->pkt_type=PACKET_BROADCAST;
else
skb->pkt_type=PACKET_MULTICAST
}
else if(1/*dev->falgs & IFF_PROMISC*/)
{
if(memcmp(eth->h_dest, dev->dev_addr, ETH_ALEN))
skb->pkt_type=PACKET_OTHERHOST;
}
}
dev->falgsThe flag in IFF_PROMISCis set when the interface enters promiscuous mode . As shown in the preceding code snippet, when the destination MAC address does not match the address of the interface (whether it IFF_PROMISCis set or not), eth_type_transit is skb->pkt_typeset to PACKET_OTHERHOST. This will allow PF_SOCKETShandlers to receive copies, but upper layer protocol handlers must discard PACKET_OTHEHOSTbuffers of type. (see, for example, arp_rcvand ip_rcv).
Set Ethernet protocol and length
eth_type_transThe second part of is to get the identifier of the protocol used at the higher layer. The protocol value is also known as Ethertype, and the list of valid types is kept up-to-date at http://standards.ieee.org/regauth/ethertype. The difference between the older Ethernet protocols higher than 1536 and the 802 protocol is done by the following code snippet:
if(ntohs(eth->h_proto) >= 1536)
return eth->h_proto;
rawp = skb->data;
if(*(unsigned short *)rawp == 0xFFFF)
return htons(ETH_P_802_3);
/*
* 真实802.2 LLC
*/
return htons(ETH_P_802_2);
}
If a value greater than 1536 is interpreted as a protocol ID, how does a device driver find out the size of the frame it receives? When the protocol/length value is less than 1500 or greater than 1536, the device itself stores the frame size in one of its registers so that the device driver can read it. The device can figure out the size of each frame thanks to a well-known bit pattern for this purpose. The following code snippet, taken drivers/net/3c59x.cfrom vortex_rx, shows how the driver first reads the size from the device and then allocates a buffer accordingly:
/*封包长度:多达4.5k*/
int pkt_len = rx_status & 0x1fff;
struct sk_buff *skb;
skb = dev_alloc_skb(pkt_len + 5);
Don't be confused by the comments in the above code. This particular device can accept frame sizes up to 4.5K because this device also handles FDDI NICs.
We already know what host and network endianness are. eth_type_transThe value returned by, and the skb->protocolvalue assigned to is end-of-network: when stripped from the Ethernet header, it is already at end-of-network, and when eth_type_transa local symbol is used ETH_P_XXX, it must be htonsmacro-removed from the host Endianness is converted to network endianness. That is, when the kernel later accesses it skb->protocoland uses it to ETH_P_XXXcompare with the value, it must be ETH_P_XXXconverted to a network endian, or skb->protocalconverted to a host endian: it doesn't matter which endian is used, what matters is the comparison are expressed with the same tail. In other words, the following two lines of code are equivalent:
ntohs(skb->protocol) == ETH_P_802_2
skb->protocol == htons(ETH_P_802_2)
Because eth_type_transthey are only called for Ethernet frames, similar functions exist for other media types, some with names ending in _type_trans, and some with different names. For example, the following example, taken from some code in the IBM Token Ring driver ( ), is set up before drivers/net/tokenring/ibmtr.cthe familiar netif_rxcall , as is done for Ethernet devices:skb->protocoltr_type_transeth_type_trans
static void tr_rx(struct device *dev)
{
...
skb->protocol=tr_type_trans(skb, dev);
...
netif_rx(skb);
...
}
If you net/802/tr.cfancy it tr_type_trans, you will see eth_type_transa similar logic, but the object is the Token Ring device.
There are also some media types that will be set directly skb->protocolwithout any __type_transauxiliary functions, because these media types can only carry one protocol (such as IrDA, AX25).
Logical Link Control (LLC)
The LLC layer was designed by the IEEE 802 committee when it standardized specifications for LANs. The idea is that instead of just using a higher layer protocol identifier, there is more flexibility to specify a protocol identifier for the source ( SSAP) and a protocol identifier for the destination ( DSAP). In most cases, SSAP and DSAP are the same for any given connection—in fact, when the global flag is set, SSAP and DSAP are the same—however, having two values makes the system It is flexible and can use different protocols.
An LLC can provide various types of services to its upper layer:
-
类型I- Connectionless (such as datagram protocol), does not support acknowledgment mechanism, flow control and error recovery
-
类型II- Connection-oriented, supports acknowledgment mechanism, flow control and error recovery.
-
类型III- No connection, but with some advantages of Type II.
The header format of the LLC frame. In contrast there are three new fields:
-
SSAP
-
DSAP
- These are 8-bit fields that specify the protocol used.
-
Control (CTL)
- The size of this field is dependent on the type of LLC used (Type I or Type II). We won't go deep into the LLC layer, but will assume that this field is 1 byte long and has a value of 0x03 (type I, CTL=UI). That should be enough to understand what follows in this chapter.
There are several reasons why the LLC header is not popular. Perhaps the main reason is the 8-bit limit for SSAP and DSAP identifiers, and to make matters worse two of these bits are reserved for unicast/multicast and local/global identification. Only 64 protocols can be specified in the remaining 6 bits, which is too restrictive.
When using a local SAP (specified by the local/global flag in the protocol field), the network administrator must ensure that all systems agree on the local SAP they are using, thus complicating matters and reducing usability. A global SAP cannot be ambiguous, but none of the new protocols use a global SAP. In the next section you'll see how this limitation is resolved by extending the header using the concept of SNAP.
The following table is the SAP registered with the Linux kernel. Compared to the registered protocols listed in the table above dev_add_pack, LLC causes the kernel to use an extra layer when obtaining handlers.
| protocol | SAP | function processing |
|---|---|---|
| SNAP | 0xAA | snap_rcv |
| IPX | 0xE0 | ipx_rcv |
The case of IPX
You might wonder if you can use a pure 802.3 frame format, since it has no place for a protocol ID. In fact, pure 802.3 frames are usually not used. The only well-known exception involves IPX, where IPX packets can be sent in raw 802.3 frames (that is, frames without the LLC header). The recipient will identify these packets by a means. The first field of the IPX header is a 16-bit checksum field, which is normally turned off by simply setting it to 0xFFFF. Because 0xFF/0xFF is an invalid SSAP/DSAP combination, and no Ethertype has this value, IPX packets using raw 802.3 can be easily identified. When these packets are detected, skb->protocolthey are set to ETH_p_802_3, and their processing function is the IPX processing function.
Linux LLC implementation
The 802.2LLC layer has not only been extended but also rewritten. The kernel's LLC implementation supports Type I and Type II and consists of the following main components:
-
Two state machines. Used to record the state of the local SAP and the connections established on it.
-
The LLC receiving function feeds back the correct input data to the two state machines according to the input frame it receives.
-
AF_LLC socket interface. Can be used to build protocols or services on top of the LLC layer in user space.
We will not delve into the details of the Linux kernel's LLC implementation. Here we only talk about the data structure used to define the local SAP, and briefly explain how some input frames are processed.
A local SAP is defined using include/net/llc.hthe data structures defined in . llc_sapSome of these fields are as follows:
-
struct llc_addr laddr- SAP identifier
-
int (*rcv_func)(struct sk_buff*, struct net_device *, struct packet_type *)- function processing. This field is NULL when a SAP is opened via a PF_LLC socket. When SAP is started by the kernel, this field provides the function to the kernel.
Partial SAPs are llc_sap_opencreated by and inserted into llc_sap_listthe list. When invoked llc_sap_open, two types of SAPs can be established:
-
SAP installed by the kernel itself, installs kernel-level handlers
-
SAPs managed by PF_LLC sockets (for example, when a server uses a system call on a PF_LLC socket
bindto bind it to a given SAP).
Handle ingress LLC frames
Whenever an incoming frame is eth_type_transclassified as using an LLC header (because its type/length field is less than 1536, and no special IPX case is detected), skb->protocolthe initialization to ETH_P_802_2 causes llc_rcvthe handler to be selected. This handler selects the correct protocol handler based on the DSAP field in the LLC header: to do so, it calls the registered handler for those SAPs opened by the kernel, and then when the SAP is opened by the socket, llc_sap_openit rcv_funccalls PF_LLCthe The correct input data is fed into the correct state machine. (Refer to the picture below)

A given SAP is sent by a frame when required by one of the two state machines (for example, to notify the receipt of a frame). PF_LLC sockets can be transported using standard interfaces such as sendmsg. In both cases, the frame is fed directly into the link layer after the appropriate link layer headers have been properly initialized dev_queue_xmit.
Subnetwork Access Protocol (SNAP)
Due to the limitations of the LLC header, the 802 committee further expanded the data link header. In order to make the scope of the agreement larger, the concept of SNAP is also introduced. Basically, when SSAP/DSAP assigns 0xAA/0xAAa value, it has a special meaning: the 5 bytes following the CTL field of the LLC header represent a protocol identifier. The unicast/multicast and local/global bits are no longer used. Therefore, the size of the protocol identifier jumps from 8 bits to 40 bits. The reason the committee decided to use 5 bytes has to do with how many protocol numbers can be deduced from a MAC address. Unlike SSAP/DSAP, the use of SNAP codes is quite common.
Because the SNAP identifier 0xAA/0xAA is a special case of SSAP/DSAP, therefore, llc_sap_openone of the clients used by SNAP (see net/802/psnap.cin snap_init). This means that the protocol encoded using SNAP will have one more layer of indirection, that is, three layers!
Before understanding how the SNAP client registers with the kernel, let's briefly describe how to define the SNAP protocol ID. As you probably already know, MAC addresses are managed by the IEEE, which sells them in 2^24 batches. Because a MAC address is 48 bits long (6 bytes), IEEE gives each client a 24-bit long number (that is, the first 3 bytes of the MAC address), and then allows the client to put any value in The remaining 24 bits. Suppose I want to buy a batch of MAC addresses because I want to sell network cards. Let's call the numbers assigned to me XX:YY:ZZ. At this point, I will be the owner of all addresses between XX:YY:ZZ:00:00:00 and XX:YY:ZZ:FF:FF:FF. In addition to these MAC addresses, I will also assign SNAP codes between XX:YY:ZZ:00:00 and XX:YY:ZZ:FF:FF.
When you get a 24-bit long number from IEEE, you are actually given 4 24-bit long numbers due to the four possible combinations of local/global and unicast/multicast bits.
Using a similar registration and delisting method to the SAP protocol, the SNAP layer also provides register_snap_clientand unregister_snap_clientfunctions, and also uses a global list ( snap_list) to link all SNAP protocols registered with the kernel. The following table is the registered customers using the Linux kernel.
| protocol | Snap ID | function processing routine |
|---|---|---|
| AppleTalk Address Resolution Protocol | 00:00:00:80:F3 | aarp_rcv |
| AppleTalk Data Segment Transfer Protocol | 08:00:07:80:9B | atalk_rcv |
| IPX | 00:00:00:81:37 | ipx_rcv |
include/net/datalink.hThe data structures defined in datalink_protoare used to define the SNAP protocol. Some of these fields are as follows:
-
unsigned short header_length- This is the length of the data link header. In
register_snap_client, its initialization is set to 8
- This is the length of the data link header. In
-
unsigned_char type[8]- protocol identifier. Only 5 bytes are used
-
void (*request)(struct datalink_proto *, struct sk_buff *, unsigned char *)- In
register_snap_client, its initial value is set tosnap_request. This field initializes the SNAP header (protocol ID only) and passes the frame to the 802.2 code. The function of this field is enabled before the data used to fill in the datalink header is transmitted.
- In
-
void (*rcvfunc)(struct sk_buff*, struct net_device *, struct packet_type *)- Function handlers required for ingress traffic
Here we only briefly discuss IPX. It is worth pointing out that the protocol registers with the kernel with the same handler on three different occasions:
-
When there is Ethertype
-
As 802.3 SSAP/DSAP protocol
-
as a SNAP protocol
The figure below summarizes how the kernel recognizes and processes Ethernet, 802.2, 802.3, and SNAP frames.
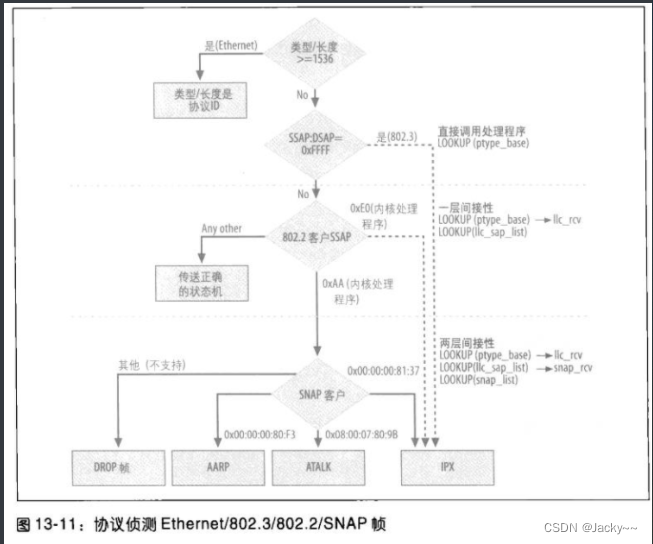
Tuning via the /proc filesystem
As Ethernet和802far as , /proc/sys/netthere is a directory in , /proc/sys/net/ethernet/(空的)and , /proc/sys/net/token-ring/(只有一个文件)respectively net/core/sysctl_net_ethernet.c和net/802/sysctl_net_802.c, are registered in . Only when the kernel is compiled to support Ethernet and Token Ring, these two directories will be included.
Involved functions and variables
| function | illustrate |
|---|---|
dev_add_pack |
Add/remove protocol handlers |
dev_remove_pack |
|
register_8022_client |
Register/delist for 802.2 protocol. These functions are defined as wrapper functions containing llc_sap_openandllc_sap_close |
unresgiter_8022_client |
|
register_snap_client |
Enroll/Delist for SNAP Customers |
unregister_snap_client |
|
llc_sap_open |
Create/remove SAP |
llc_sap_close |
|
eth_type_trans |
Used by Ethernet devices to strip higher layer protocol identifiers and then classify frames as unicast/multicast/broadcast |
| variable | illustrate |
|---|---|
netdev_nit |
Number of registered protocol sniffers |
ptype_base |
pointer to a data structure containing registered protocol handler routines |
ptype_all |
Same ptype_base, but for protocol sniffers |
sanap_list |
SNAP customer list |
| data structure type | illustrate |
|---|---|
struct packet_type |
Used to store information about ETH_P_XXX protocol processing functions |
struct datalink_proto |
Used to represent the SNAP protocol |
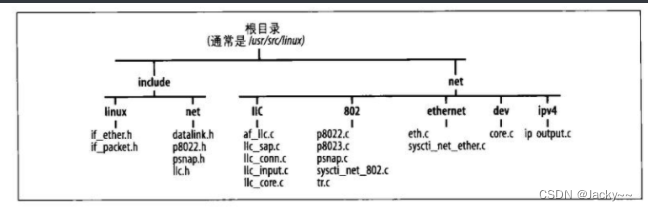
Files and Directories Involved
The picture below shows the location of the files involved in this blog. In the directory, header files include/linuxfor other media types can be found . The directory contains multiple files.if_xxx.hnet/llc