background introduction
The original motivation of knowledge distillation is to "lightweight" a large model, because large models are very inconvenient in terms of training costs, actual use efficiency, and deployment on mobile terminals. Just imagine the poor memory in your mobile phone, which will be eroded by QQ and WeChat every month. If each download and installation package of those apps costs 4 or 5 G (except for games), the mobile phone must be cleaned up after a few months of use. The memory may be replaced (the merchant is ecstatic), and if the APP only has 1 or 2G, your mobile phone can hold 3 or 4 times more software.
So why not just use the lightweight model?
Generally speaking, the lightweight model has fewer parameters, and although its speed is increased, the detection accuracy will be greatly reduced, which may not meet the standards for practical applications. This leads to a dilemma, the large model and the small model cannot be deployed. So is it possible to use the large model to "teach" its powerful capabilities to the small model. In this regard, we can make an analogy between teachers and students. Teachers have a lot of knowledge, while students only have a small amount of knowledge. Teachers can pass on their knowledge to students through their own refinement, so that students can greatly reduce the cost of learning.
Analogy to this, we can "teach" ( distill ) the content ( knowledge ) learned by the large model ( teacher model ) to the small model ( student model ). It turns out that this leads to better results with smaller models.
Pre-knowledge
1. Softmax function
The softmax function is usually used as a multi-classification and normalization function, and its formula is as follows:
softmax ( x ) = exi ∑ i = 1 exi softmax(x)=\frac{e^{x_i}}{\sum_{i=1} e^{x_i}}softmax(x)=∑i=1exiexi
The softmax function has some key features:
- The sum of all softmax output values is 1 and greater than 0, which satisfies a probability distribution . This is easy to understand, because the denominator is a sum, and the denominator will be obtained by adding up all the fractional elements
- Widen the size gap . This is given by the exponential function exe^xeCaused by x , according to the exponential function image, the independent variable value xxThe larger x is, the dependent variableyyThe faster the y value increases. You can see the following example
| x | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| softmax(x) | 0.032 | 0.087 | 0.237 | 0.644 |
This further brings up a question, is it possible to use a method to make the gap between the numbers not so large? Here we use a hyperparameter temperature T to control the gap, the formula is as follows:
softmax ( x , T ) = exit ∑ i = 1 exit softmax(x,T)=\frac{e^\frac {x_i}t}{ \sum_{i=1} e^\frac {x_i}t}softmax(x,T)=∑i=1etxietxi
Then following the previous example, we set T=0.5, 1, 2, 4 to observe the changes in the data.
| T\x | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 0.5 | 0.002 | 0.016 | 0.117 | 0.865 |
| 1 | 0.032 | 0.087 | 0.237 | 0.644 |
| 2 | 0.101 | 0.167 | 0.276 | 0.455 |
| 4 | 0.165 | 0.212 | 0.272 | 0.350 |
It can be found that with TTWith the increase of T , the smaller the gap value between different categories (the more attention is paid to the negative label, that is, the incorrect label), but the size relationship does not change. The figure below is another graph of softmax value versus temperature.

2. log_softmax function
The log_softmax function is to use the output value obtained by softmax as the input value of the logarithmic function
log ( softmax ( x ) ) log(softmax(x))log(softmax(x))
3. NLL loss function
NLLloss is a measure of the gap between the two, the formula is as follows:
NLL loss ( p , q ) = − ∑ i = 1 qilogpi NLLloss(p,q)=-\sum_{i=1} q_ilogp_iNLLloss(p,q)=−i=1∑qilogpi
If the difference between the two is larger, the final value will be larger
4. CrossEntropy function
The CrossEntropy function is also known as the cross-entropy loss function. In fact, the expression of the formula is consistent with the NLL loss function, but p, qp, qThe specific meanings of p and q are different, herep, qp, qp and q are to go through log_softmax [in pytorch]
》》The difference between NLLloss and CrossEntropy
#NLLloss
def forward()
x=self.fc2(x)
x=F.log_softmax(x,dim=1)
return x
F.nll_loss()
#CrossEntropy
def forward()
x=self.fc2(x)
return x
F.cross_entropy()
The specific content of knowledge distillation
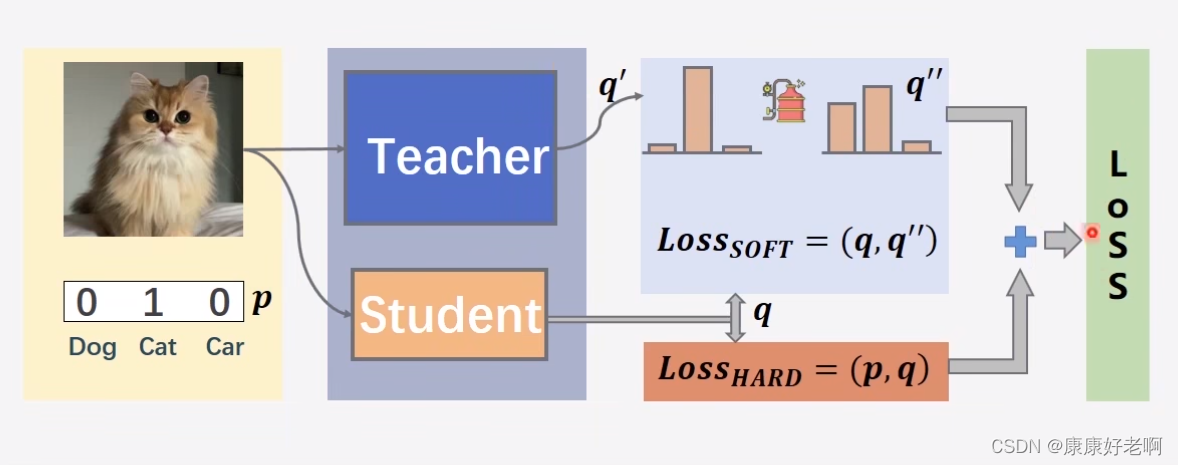
The above picture can be a good help to understand knowledge distillation. First look at the student model. Under normal circumstances, the training model will use the cross-entropy loss function, that is, L oss HARD ( p , q ) Loss_{HARD}(p,q)LossHARD(p,q ) , for example, now the model outputs aq = ( 0.4 , 0.2 , 0.4 ) q=(0.4,0.2,0.4)q=(0.4,0.2,0.4 ) triplet, while the target triplet isp = ( 1 , 0 , 0 ) p=(1,0,0)p=(1,0,0 ) (we call it Hard Label), then the cross-entropy loss of the two will be calculated, and then gradient descent and backpropagation will be performed. The same is true for the teacher model. After entering the model, it will output aq ′ q’q’ triplet.
This hard tag encoding method is also known as "one-hot" encoding
And the distillation part is that the q ′ q’ obtained from the teacher modelq’ will be distilled to getq ′ q’’q′′ (we call it Soft Label), this distillation process uses the temperature TTmentioned aboveT. _ Thenq ′ ′ q''q'' andqqAlso use the cross entropy loss function between q L oss SOFT ( q , q ′ ′ ) Loss_{SOFT}(q,q'')LossSOFT(q,q′′ ), the final total loss function isα L oss HARD ( p , q ) + β L oss SOFT ( q , q ′ ′ ) \alpha Loss_{HARD}(p,q)+\beta Loss_{SOFT}( q,q'')αLossHARD(p,q)+βLossSOFT(q,q′′)
Here you can not use the cross-entropy loss function L oss SOFT ( q , q ′ ) Loss_{SOFT}(q,q'')LossSOFT(q,q′′ ), instead use the KL divergence loss which measures how well two probability distributions match.
Here is a little more explanation on soft tags. Soft tags are not like hard tags, which only contain yes or no information, while soft tags will contain more information. For example, the triplet is now defined as (cat, dog, duck) (cat, dog, duck)( cat cat ,dog ,duck duck ) , then hard label( 1 , 0 , 0 ) (1,0,0)(1,0,0 ) can only indicate that the object is a cat, and soft labels( 0.6 , 0.3 , 0.1 ) (0.6,0.3,0.1)(0.6,0.3,0.1 ) can mean that while the object is a cat, it is also very cat-like and not quite duck-like.
Question 1: Why not retrain a new model?
The teacher model can help the student model to converge better without requiring the student model to re-converge based on the data, and the information provided by the teacher model is more effective than the original data set
Question 2: Why do we need to distill the output of the last step?
In fact, the intermediate network layer of the student model can also learn the output result of the intermediate network layer of the teacher model, so that the output result of the intermediate network layer of the student model can fit the output result of the intermediate network layer of the teacher model, as shown in the figure below. This is like a professor teaching a baby, and if he can't learn it, he will go to school separately.

Question 3: In theory, controlling other conditions, the larger the number of model parameters, the better the effect, so why is the effect of the model after knowledge distillation still very good?
In fact, the approximate relationship between the amount of model parameters and the total amount of "knowledge" contained in many models is as shown in the figure ②③. It is not difficult to find that even if the total amount of model parameters is slightly reduced, the amount of "knowledge" will not decrease much, and it can still reach a large amount. Good results.

Advantages of Knowledge Distillation
(1) Reduce overfitting, strong generalization ability
This is one of the papers proposed by knowledge distillation back then. It can be found that soft targets can reduce overfitting very well (compared to the baseline training accuracy is reduced, but the test accuracy is improved)

(2) Make the model more lightweight, improve speed and efficiency, and make it easier to deploy on the mobile terminal
(3) In some cases, the effect of the model can be improved
Development direction of knowledge distillation
(1) Teaching is mutually beneficial. The student model helps the teacher model. My personal understanding is that the student model can learn some areas that the teacher does not know and then improve the teacher's ability
(2) Multiple teachers and teaching assistants carry out knowledge distillation
(3) Combining comparative learning and transfer learning
(4) Knowledge distillation is performed between the middle layers of the network, not just the final result.